Fast MCMC sampling for Markov jump processes and extensions
Markov jump processes (or continuous-time Markov chains) are a simple and important class of continuous-time dynamical systems. In this paper, we tackle the problem of simulating from the posterior distribution over paths in these models, given parti…
Authors: Vinayak Rao, Yee Whye Teh
Journal of Machine Learning Resear ch 1 (2013) 1-26 Submitted 9/12; Re vised 7/13; Published F ast MCMC Samplin g for Mark o v J ump Processes and Extensions V inayak Rao ∗ V R AO @ G A T S B Y . U C L . AC . U K Department of Statistical Science Duke University Durham, NC, 27708- 0251, USA Y ee Why e T eh Y . W . T E H @ S TA T S . OX . A C . U K Department of Statistics 1 South P arks Roa d Oxfor d O X1 3TG, UK Accepted f or publication in the Jo urnal of Machine Lear ning Resear ch (JMLR) Editor: Christopher Meek Abstract Markov jump pro cesses (or contin uous-time Marko v chains) are a simple and impor tant class of continuo us-time dyna mical system s . In this pa per , we tackle th e problem of simulating from th e posterior distribution over p aths in the s e mo dels, given partial and n oisy observations. Our ap- proach is an auxiliary v ar iable Gibb s samp ler , and is ba s ed on the idea of uniformization . This sets up a Markov chain ov er paths by alternately sampling a finite set of virtual jump times given th e current path, and then sampling a n e w path given the set of extant and v irtual jump times. The first step in v olves simu lating a piece wise- constant inhom ogeneous Poisson proce s s, while for the second, we use a standard hidden Markov mo del for w ard filtering-backward samp ling algo rithm. Our method is exact and does not in volve ap proximations like time-discretization. W e demon st rate how our sampler extends natur ally to MJP-based mod els like Markov-modu lated P oisson pr ocesses and co ntinuous-time Bayesian networks, and show sign ificant co mputational benefits o ver state-o f- the-art MCMC samplers for these models. Keywords: Markov jump process, MCMC, Gibbs sampler , u niformization, Mar k ov-modu lated Poisson process, continu ous-time Bayesian network 1. Intr oduction The Marko v jump proces s (MJP) extend s the discrete-t ime Marko v chain to continu ous time, and forms a simple and popul ar class of continuo us-time dynamical systems. In B a yesian modellin g applic ations , the MJP is widely used as a prior distrib ution ove r the piece wise-constan t e voluti on of the state of a sys tem. The Mark ov prop erty of the MJP makes it both a realistic m o del for v ariou s physical and chemical systems, as well as a con venient approximation for more comple x pheno mena in biology , finance, queuing systems etc. In chemistry and biology , stochastic kinetic models use the state of an MJP to represent the sizes of va rious interac ting species (e.g., Gillespie, 1977; Goligh tly and W ilkin son , 2011). In queuing applicat ions, the state may repre sent the number of pendin g jobs in a queue (Breuer, 2003; T ijms, 1986), with the arriv al and proces sing of jobs treated as memoryles s ev ents. MJPs find wide applicati on in genet ics, for example, an MJP tra- ∗ . Correspo nding author c 2013 V inayak Rao, Y ee Whye T eh. R AO A N D T E H jectory is sometimes used to represent a segmentati on of a strand of genetic matter . Here ‘time’ repres ents position along the strand, with partic ular motifs occurr ing with dif ferent rates in dif fer- ent region s (Fearnhea d and S h erlock, 2006). MJPs are also w id ely used in finance, for example, Elliott and Osakwe (2006) use an MJP to model switches in the parameters that go vern the dyn am- ics of stock prices (the latter being modelled with a L ´ evy pro cess). In the Bayesian setting, th e challenge is to characterize the posterio r distrib ution over MJP traject ories gi ve n noi sy obser v ations ; this typica lly cannot be performed anal yticall y . V arious sampling -based (Fearnhead and Sherlock, 2006; Boys et al., 2008; El-Hay et al., 2008; Fan and Shelton, 2008; Hobolth and Stone, 2009) and determinist ic (Nodelman et al., 2002, 2005; O p per and Sanguine tti, 2007; Cohn et al., 2010) approxi mations hav e been propose d in the literatu re, b ut come w it h prob- lems: they are often generic metho ds that do not e xplo it the str ucture of the MJP , and when th ey do, in v olv e expensi ve computatio ns like matrix exp onent iation , matrix diago nalizat ion or root-findi ng, or are biased, in vol ving some form of time-disc retizat ion or independen ce assumptions. Moreov er , these methods do not exten d easily to more complicated likelih ood functions which require spe- cialize d algorithms (for instanc e, the contrib ution of Fearnhead and Sherlock (2006) is to de vel op an e xact s ampler for Ma rko v-modulated Poisson processe s (MMPPs), where an MJP modulates the rate of a Poisson proce ss). In this work, an extensio n of Rao and T eh (2011a), we describe a nov el Marko v chain Monte Carlo (MCMC) samplin g algorithm for MJPs that av oids the need for the expensi ve computati ons descri bed pre vious ly , and does not in vo lve any form of approx imation (i.e., our MCMC sampler con ver ges to the true posteri or). Importan tly , our sampler is easily adapted to complicated exten- sions o f MJPs s uch as MMPPs and continuo us-time Bayesian networ ks (CTBNs) (Nodel man et al., 2002), and is significantly more efficien t than the specialized samplers de veloped for these models. Like many exis ting methods, our sampler introduce s aux iliary vari ables which simplify the structur e of the MJP , using an idea called uniformization . Importa ntly , unlike some existin g methods which produ ce indepe ndent posterior samples of these auxili ary v ariab les, our method samples these con- dition ed on the current sample trajecto ry . While the former approach depends on the observ ation proces s, and can be hard for complicated likelih ood functi ons, ours results in a simple distri b ution ov er the a uxilia ry v ariabl es that is indepe ndent of the ob serv ations. The observ ations are accoun ted for during a straightforw ard discrete- time forward-filter ing backward-sa mpling step to resample a ne w traj ectory . The o vera ll struc ture of our al gorith m is that of an auxiliary v ariable Gibbs sampler , alterna tely resampling the auxilia ry vari ables gi ve n the MJP trajectory , and the trajectory giv en the auxili ary v ariab les. In Section 2 we briefly re vie w M a rko v jump proces ses. In Section 3 w e introd uce the idea of unifor mization and describ e our MCMC sampler for the simple case of a discretel y observe d MJP . In Section 4, we apply our sampler to the Markov- modulat ed Poisson process, while in Section 5, we describe continuous -time Bayesian networks, and extend our algorith m to that setting. In both sectio ns, we report exper iments comparing our algorith m to state-of-th e-art sampling algorithms de v eloped for these models. W e end with a discu ssion in Section 6. 2. Marko v Jump Pr ocesses (MJPs) A Marko v jump proces s ( S ( t ) , t ∈ R + ) is a stoch astic proces s with right-con tinuo us, piece w is e- consta nt paths (see for example C ¸ inlar, 1975). The paths themselv es take va lues in some countable space ( S , Σ S ) , where Σ S is the discrete σ -algebra . As in typica l application s, we assume S is finite 2 F A S T M C M C S A M P L I N G F O R M J P S A N D E X T E N S I O N S Figure 1: (left) An MJP path ( s 0 , S , T ) , (right ) a uniformized representat ion ( v 0 , V , W ) . (say S = { 1 , 2 , ... N } ). W e also assume the process is homogene ous, implyin g (togeth er with the Marko v proper ty) that for all times t , t ′ ∈ R + and states s , s ′ ∈ S , p S ( t ′ + t ) = s | S ( t ′ ) = s ′ , ( S ( u ) , u < t ′ ) = [ P t ] ss ′ for s ome stoch astic matrix P t that dep ends only o n t . The famil y of tr ansitio n matrices ( P t , t ≥ 0 ) is defined by a matrix A ∈ R N × N called the rate matrix or gener ator of the MJP . A is the time-deri vati ve of P t at t = 0, with P t = exp ( At ) , (1) p ( S ( t ′ + d t ) = s | S ( t ′ ) = s ′ ) = A ss ′ d t ( for s 6 = s ′ ) , where E q uation (1) is the matrix expon ential. The of f-diagonal elements of A are non neg ati ve, and represe nt the rates of transiting from one state to anoth er . Its diagonal entries are A s ≡ A ss = − ∑ s ′ 6 = s A s ′ s for each s , so that its columns sum to 0, w it h − A s = | A s | charact erizing the total rate of lea ving state s . Consider a time interv al T ≡ [ t st art , t end ] , with the Borel σ -algebra Σ T . L e t π 0 be a density with respec t to th e cou nting measu re µ S on ( S , Σ S ) ; thi s define s the initial distrib ution ove r sta tes at t st art . Then an MJP is described by the fo llo w in g generati ve proces s o ve r paths on this in terv al, commonly called Gillespie ’ s algorithm (Gillespie, 1977): Algorithm 1 Gillespie ’ s algorit hm to sample an MJP path on the inte rv al [ t st art , t end ] Input: The rate matrix A and the initia l distrib ution ov er states π 0 . Output: An MJP trajec tory S ( t ) ≡ ( s 0 , S , T ) . 1: Assign the MJP a state s 0 ∼ π 0 . Set t 0 = t st art and i = 0. 2: loop 3: Draw z ∼ exp ( | A s i | ) . 4: If t i + z > t end then re turn ( s 0 , . . . , s i , t 1 , . . . , t i ) and stop . 5: Incre ment i and let t i = t i − 1 + z . 6: The MJP jumps to a ne w state s i = s at time t i , for an s 6 = s i − 1 , 7: with proba bility proportiona l to A ss i − 1 . 8: end loop 3 R AO A N D T E H If all eve nt rates are finite, an MJP trajecto ry will almost surely ha ve only a finite number of jumps. Let there be n jumps, and let these occur at the orde red times ( t 1 , · · · , t n ) . Define T ≡ ( t 1 , · · · , t n ) , and let S ≡ ( s 1 , · · · , s n ) be the correspondi ng sequence of states, w he re s i = S ( t i ) . The triplet ( s 0 , S , T ) comple tely character izes the MJP trajectory ove r T (Figure 1 (left)). From Gillespie’ s algorit hm, we see that sampling an MJP trajectory in v olves sequenti ally sam- pling n + 1 waiting times from exponen tial densities with one of N rates, and n new states from one of N discrete distrib utions, each dependi ng on the prev ious state. The i th waiting time equals ( t i − t i − 1 ) and is drawn from a n expon ential wit h rate | A s i − 1 | , while the probability the i th state equals s i is A s i s i − 1 / | A s i − 1 | . The last waitin g time can take any v alue greate r than t end − t n . Thus, under an MJP , a rand om element ( s 0 , S , T ) has densi ty p ( s 0 , S , T ) = π 0 ( s 0 ) n ∏ i = 1 | A s i − 1 | e −| A s i − 1 | ( t i − t i − 1 ) A s i s i − 1 | A s i − 1 | ! · e −| A s n | ( t end − t n ) = π 0 ( s 0 ) n ∏ i = 1 A s i s i − 1 ! exp − Z t end t start | A S ( t ) | d t . (2) T o be precise, w e must state the base measure with respect to which the density abov e is defined. The reader might wish to s kip thes e details (and for more deta ils, we rec ommend Daley a nd V ere-Jon es , 2008). Let µ T be Lebesgue measure on T . Recal ling that the state space of the MJP is S , we can vie w ( S , T ) as a sequence of elements in the product space M ≡ S × T . Let Σ M and µ M = µ S × µ T be the corres pondin g produ ct σ -algebra and product measure. Define M n as the n -fold produ ct space with the usual prod uct σ -algebra Σ n M and prod uct measure µ n M . No w let M ∪ ≡ S ∞ i = 0 M i be a union space, elements of which represent finite length pure-jump paths 1 . Let Σ ∪ M be the correspo nding union σ -algebra, where each measur able set B ∈ Σ ∪ M can be express ed as B = ∪ ∞ i = 0 B i with B i = B ∩ M i ∈ Σ i M . Assign this space the measure µ ∪ M defined as: µ ∪ M ( B ) = ∞ ∑ i = 0 µ i M ( B i ) . Then, any element ( s 0 , S , T ) ∈ S × M ∪ sampled from Gillespie ’ s algori thm has density w .r .t. µ S × µ ∪ M gi ve n by Equation (2). 3. MCMC Infer ence via Uniformization In this paper , we are concerned with the problem of sampling MJP paths over the interv al T ≡ [ t st art , t end ] giv en noisy observ ation s of the state of the MJP . In the simplest case, we observ e the proces s at the bounda ries t st art and t end . More generally , we are giv en the initial distrib ution ov er states π 0 as well as a set of O noisy observ ation s X = { X t o 1 , ... X t o O } at times T o = { t o 1 , . . . , t o O } with like lihoo ds p ( X t o i | S ( t o i )) , and we w is h to sample from the posterior p ( s 0 , S , T | X ) . Here we ha ve implicitl y assumed that the observ ation times T o are fixed. Sometimes the observ atio n times them- selv es can depend on the state of the MJP , result ing effec ti ve ly in continuous- time observ ations. This is the case for th e Marko v-modu lated Poisson process and CTBNs. As we will sho w later , our method hand les these case s quite natura lly as w e ll. 1. Define M 0 as a point satisfying M 0 × M = M × M 0 = M (Daley and V ere-Jones, 2008). 4 F A S T M C M C S A M P L I N G F O R M J P S A N D E X T E N S I O N S A simple ap proac h to inference is to dis cretiz e time and work wit h the resu lting approx imation. The time-discretiz ed MJP correspon ds to the familiar discrete- time Markov chain, and its Mark ov structu re can be exploi ted to construct dynamic programming algorith ms like the forward -filtering backw ard-sa mpling (FFBS ) algorithm (Fr ¨ uwirth-Schn atter (1994); Carter and Ko hn (1996); see also Appendix A) to sample poste rior trajecto ries ef ficiently . Howe ver , time-discretiz ation intro- duces a bias into our inference s, as the system can change state only at a fixed set of times, and as the maximum number of state changes is limited to a fi n ite number . T o control this bias, one needs to discreti ze time at a fi n e granularity , resulting in long Marko v chains, and expen si ve computa tions. Recently , there ha s been g ro wing i nteres t in constru cting e xact MC MC samplers for MJPs with- out any appro ximation s such as time-discret izatio n. W e revie w these in Section 3.3. One class of methods exploit s the fact an MJP can be exac tly repres ented by a discrete-ti me Marko v chain on a rando m time-discr etizati on. Unlike discret ization on a regula r grid, a random grid can be quite coarse without introduc ing any bias. Gi v en this discretiz ation, we can use the FF BS algori thm to perfor m ef ficient sampling. Howe ver , we do not observe the random discre tizatio n, and thus also need to sample this from its posterior distrib ution. This posteri or no w depend s on the likeliho od proces s, and a number of algori thms attempt to solve this prob lem for specific observ ation pro- cesses . Our approach is to resample the discretiz ation conditioned on the system trajectory . As w e will see this is indepen dent of the likel ihood process, resul ting in a simple, fl e xible and efficient MCMC sampler . 3.1 Uniformiz ation W e first introdu ce th e idea of u niformiz ation (J ensen, 1953; C ¸ inlar, 1975; Hobolth and Stone, 2009), which forms the basis of our sampling algorith m. For an M J P with rate-matrix A , choose some Ω ≥ m a x s | A s | . L e t W = ( w 1 , . . . , w | W | ) be an ordered set of times on the interv al [ t st art , t end ] dra wn from a h omogene ous Poisson p rocess with int ensity Ω . W constitutes a rando m discr etizati on of the time-inte rv al [ t st art , t end ] . Next, letting I be the identity matrix, observe that B = I + 1 Ω A is a stochastic matrix (it has nonne gativ e elements, and its columns sum to one). Run a discrete- time Marko v chain with initial distrib ution π 0 and t ransit ion matrix B on the times in W ; this is a Mar ko v c hain su bor dinated to th e Poisson process W . The Markov chain will assign a set of states ( v 0 , V ) ; v 0 at the initial time t st art , and V = ( v 1 , . . . , v | V | ) at the discretiza tion times W (so that | V | = | W | ). In particular , v 0 is drawn from π 0 , while v i is drawn from the probability vector giv en by the v i − 1 th column of B . Just as ( s 0 , S , T ) charac terizes an M J P path, ( v 0 , V , W ) also charac terizes a sample path of some piecewis e-cons tant, right-c ontin uous stochastic proces s on [ t st art , t end ] . Observe tha t the matrix B allo ws self-t ransiti ons, so that unlike S , V can jump from a state back to the same state. W e treat these as virtual jumps, and regard ( v 0 , V , W ) as a redunda nt represe ntation of a pure-jump process that alwa ys jumps to a ne w stat e (see Figur e 1 (righ t)). T h e vir tual jumps pro vide a mechanism to ‘ thin’ the set W , thereby rejecti ng some of its ev ents. This correc ts for the fact that since the P o isson rate Ω dominates the lea ving rates of all s tates of th e MJP , W w i ll on av erag e contain more e vents than there are jumps in the MJP path. As the parameter Ω incre ases, the number of ev ents in W incre ases; at the same time the diagonal entries of B start to dominat e, so that the number of self-tran sition s (thinned ev ents) also increa ses. The nex t propos ition sho ws that these two ef fects exac tly compensa te each other , so that the proces s characterize d by ( v 0 , V , W ) is precise ly the desired MJP . 5 R AO A N D T E H Pro position 1 (Jens en, 1953) F or any Ω ≥ m a x s | A s | , ( s 0 , S , T ) and ( v 0 , V , W ) define the same Marko v jump pr ocess S ( t ) . Pro of W e follo w Hobolth and Stone (2009). F r om Equation (1), the margina l distrib ution of the MJP at time t is gi ve n by π t = exp ( At ) π 0 = exp ( Ω ( B − I ) t ) π 0 = exp ( − Ω t ) exp ( Ω t B ) π 0 = ∞ ∑ n = 0 exp ( − Ω t ) ( Ω t ) n n ! ( B n π 0 ) . The first term in the summation is the probability that a rate Ω Poisson produce s n e ve nts in an interv al of length t , i.e., that | W | = n . The second term giv es the margina l distrib ution over states for a discret e-time Markov chain after n steps, gi ve n that the initial state is drawn from π 0 , and subseq uent states are assigned according to a transition matrix B . Summing ov er n , w e obtain the mar ginal distrib ution ove r states at time t . Since the transiti on kernels induce d by the uniformiza- tion procedure agree with those of the Marko v jump process (exp ( A t ) ) for all t , and since the two proces ses also share the same initial distrib utio n of states, π 0 , all finite dimensional distri b ution s agree. Fol lo wing Kolmogo rov ’ s extens ion theorem (Kallenber g , 2002), both define versions of the same stochas tic proces s. A more direct b ut cumbersome approach is note that ( v 0 , V , W ) is also an element of the space S × M ∪ . W e can then write do wn its d ensity p ( v 0 , V , W ) w .r .t. µ S × µ ∪ , an d show t hat mar ginalizin g out the number and locati ons of self-trans itions recov ers Equation (2). While we do not do this, we will deri ve the density p ( v 0 , V , W ) for later use. As in Section 2, let T ∪ and S ∪ denote the measure spaces consis ting of finite sequen ces of times and states respecti vely , and let µ ∪ T and µ ∪ S be the correspondi ng base measures. The Poisson realiza tion W is determine d by waiting times sampled from a rate Ω exp onenti al distrib ution, so that follo wing Equation (2), W has density w . r .t. µ ∪ T gi ve n by p ( W ) = Ω | W | e − Ω ( t end − t start ) . (3) Similarly , from the c onstru ction of the Mark o v cha in, it follo ws that the state assignment ( v 0 , V ) has probab ility density w .r .t. µ S × µ ∪ S gi ve n by p ( v 0 , V | W ) = π 0 ( v 0 ) | V | ∏ i = 1 1 + A v i Ω 1 ( v i = v i − 1 ) A v i v i − 1 Ω 1 ( v i 6 = v i − 1 ) . Since under unifo rmizatio n | V | = | W | , it follo ws that µ ∪ S ( d V ) × µ ∪ T ( d W ) = µ | V | S ( d V ) × µ | W | T ( d W ) = ( µ T × µ S ) | V | ( d ( V , W )) = µ ∪ M ( d ( V , W )) . (4) 6 F A S T M C M C S A M P L I N G F O R M J P S A N D E X T E N S I O N S Thus, from Equations (3) and (4), ( v 0 , V , W ) has density w . r .t. µ S × µ ∪ M gi ve n by p ( v 0 , V , W ) = e − Ω ( t end − t start ) π 0 ( v 0 ) | V | ∏ i = 1 ( Ω + A v i ) 1 ( v i = v i − 1 ) A v i v i − 1 1 ( v i 6 = v i − 1 ) . (5) 3.2 The MCMC Algorithm W e adapt the uniformizati on scheme described abo ve to const ruct an auxili ary v ariab le Gibbs sam- pler . Recall that the only dif ference between ( s 0 , S , T ) and ( v 0 , V , W ) is the presenc e of an auxiliary set of virtua l jumps in the latter . Call the virtual jump times U T ; associated w i th U T is a seque nce of states U S . U S is uniquely determin ed by ( s 0 , S , T ) and U T (see Figure 1 (r ight)) , and we say this configurat ion is compatible . Let U = ( U S , U T ) , and observe that for compatibl e v alues of U S , ( s 0 , S , T , U ) and ( v 0 , V , W ) represen t the same point in S × M ∪ . Figure 2: Uniformizatio n-bas ed Gibbs sampler: starting with an MJP trajectory (left), resample the thinne d eve nts (middle) and then resample the traject ory giv en all Poisson ev ents (right). Disca rd the thinne d eve nts and repeat. Giv en an MJP trajec tory ( s 0 , S , T ) (Figure 2 (left)) , we proceed by first sampli ng the set of virtua l jumps U T gi ve n ( s 0 , S , T ) , as a result recov ering the uniformized charac terizat ion ( s 0 , V , W ) (Figure 2 (middle)). T h is correspo nds to a random discretiza tion of [ t st art , t end ] at times W . W e no w discar d the state sequence V , and perform a simple HMM forw ard-filte ring backw ard-sa mpling step to resampl e a ne w state sequence ˜ V . Finally , dropping the virtual jumps in ( s 0 , ˜ V , W ) giv es a new MJP path ( s 0 , ˜ S , ˜ T ) . F i gure 2 descr ibes an iterati on of the M CMC algorithm. The next propositio n shows that condi tioned on ( s 0 , S , T ) , the virtual jump times U T are dis- trib uted as an in homo gen eous Poisson process with i ntensi ty R ( t ) = Ω + A S ( t ) (we remind the rea der that A has a negati ve diagonal, so that R ( t ) ≤ Ω ). This intensity is piece wise-constan t, takin g the v alue r i = Ω + A s i on the interv al [ t i , t i + 1 ) (with t 0 = t st art and t n + 1 = t end ), so it is eas y to sa mple U T and thus U . Pro position 2 F or any Ω ≥ max s ( | A s | ) , both ( s 0 , S , T , U ) and ( v 0 , V , W ) have the same density w .r .t. µ S × µ ∪ M . In other word s, the Markov jump pr ocess ( s 0 , S , T ) along with virtual jumps U dra wn fr om the inhomo ge neous P oisson pr ocess as above is equivalent to the times W being drawn fr om a P oisson pr ocess w i th rate Ω , followed by the states ( v 0 , V ) being drawn fr om the subor dinated Marko v chain. Pro of Let n = | T | be the numbe r of jumps in the current MJP trajector y . Define | U i | as the numb er of auxilia ry times in interv al ( t i , t i + 1 ) . Then, | U T | = ∑ n i = 0 | U i | . If U T is sampled from a piece wise- consta nt inhomoge neous Poisson proce ss, its d ensity is the pr oduct of the densi ties of a sequenc e of 7 R AO A N D T E H homogen eous Poisson proc esses, and from Equation (3) is p ( U T | s 0 , S , T ) = n ∏ i = 0 ( Ω + A s i ) | U i | ! exp − Z t end t start ( Ω + A S ( t ) ) d t (6) w . r .t. µ ∪ T . Ha ving realized the times U T , the associated states U S are determine d too (elements of U S in the interv al ( t i − 1 , t i ) equal s i − 1 ). Thus U = ( U S , U T ) gi ven ( s 0 , S , T ) has the same density as Equation ( 6), but now w .r .t. µ ∪ M , an d no w restri cted to elements o f M ∪ where U S is compatible with ( S , T , U T ) . Multiplyi ng Equation s (2) and (6), we see that ( s 0 , S , T , U ) has dens ity p ( s 0 , S , T , U ) = e − Ω ( t end − t start ) π 0 ( s 0 ) n ∏ i = 0 ( Ω + A s i ) | U i | n ∏ i = 1 A s i s i − 1 w . r .t. µ S × µ ∪ M × µ ∪ M . Howe ver , by definition , µ ∪ M ( d ( S , T )) × µ ∪ M ( d U ) = µ | T | M ( d ( S , T )) × µ | U | M ( d U ) = µ | T | + | U | M ( d ( S , T , U )) = µ ∪ M ( d ( S , T , U )) . Comparing with Equation (5), and noting that | U i | is the number of self-tran sition s in interv al ( t i − 1 , t i ) , we see both are equa l whenev er U S is compatib le w it h ( s 0 , S , T , U T ) . The probabili ty densit y at any i ncompat ible setting of U S is zero, gi ving us the desire d result. W e can now incorpor ate the likel ihoods coming from the observ ations X . Firstly , note that by assumpti on, X depends only on the MJP trajecto ry ( s 0 , S , T ) and not on t he auxiliary jumps U . Thus, the cond itional distrib ution of U T gi ve n ( s 0 , S , T , X ) is still the inhomogene ous Poisson proce ss gi ve n abov e. Let X [ w i , w i + 1 ) repres ent the observ ation s in the in terv al [ w i , w i + 1 ) (taking w | W | + 1 = t end ). Through out this interv al, the MJP is in state v i , gi ving a likel ihood term: L i ( v i ) = p ( X [ w i , w i + 1 ) | S ( t ) = v i for t ∈ [ w i , w i + 1 )) . (7) For the c ase of noisy observ ations of the MJP state at a discrete set of times T o , this simplifies to L i ( v i ) = ∏ j : t o j ∈ [ w i , w i + 1 ) p ( X t o j | S ( t o j ) = v i ) . Conditio ned on the times W , ( s 0 , V ) is a Markov chain with initial distrib ution π 0 , transition ma- trix B an d likelih oods gi v en by Equation (7). W e can ef ficiently resample ( s 0 , V ) us ing the standa rd forwar d fi l tering- backw ard sampling (FFB S) algorithm. W e provid e a descrip tion of this algorithm in Appendix A. This cost of such a resamplin g step is O ( N 2 | V | ) , quadratic in the number of states and line ar in the length of the chain. Further , any stru cture in A (e.g., spa rsity) is inheri ted by B and can be exploit ed easily . Let ( ˜ s 0 , ˜ V ) be the new state sequen ce. Then ( ˜ s 0 , ˜ V , W ) will correspond to a new MJP path ˜ S ( t ) ≡ ( ˜ s 0 , ˜ S , ˜ T ) , obtained by discarding virtual jumps from ( ˜ V , W ) . Eff ecti vely , gi ve n an MJP path, an iteration of our algorith m corres ponds to introdu cing thinne d ev ents, rela- bellin g the thinned and actual transitio ns using FFBS, and then discarding the new thinned ev ents to obtai n a ne w MJP . W e summariz e this in Algorithm 2. 8 F A S T M C M C S A M P L I N G F O R M J P S A N D E X T E N S I O N S Algorithm 2 Block ed Gibbs sampler for an MJP on the interv al [ t st art , t end ] Input: A set of obser v ation s X , and paramet ers A (the rate matrix), π 0 (the initial distrib ution ov er states) and Ω > m a x s ( | A s | ) . The pre vious MJP path, S ( t ) ≡ ( s 0 , S , T ) . Output: A ne w MJP trajecto ry ˜ S ( t ) ≡ ( ˜ s 0 , ˜ S , ˜ T ) . 1: Sample U T ⊂ [ t st art , t end ] from a Poisson proces s w it h piece w i se-con stant rate R ( t ) = ( Ω + A S ( t ) ) . Define W = T ∪ U T (in increas ing order). 2: Sample a pa th ( ˜ s 0 , ˜ V ) from a dis crete-t ime M a rko v chain with 1 + | W | steps using the FFBS a l- gorith m. T h e tran sition matrix of th e Mark ov chai n is B = I + A Ω while the in itial distri b ution ov er sta tes is π 0 . The likeli hood of state s at step i is L i ( s ) = p ( X [ w i , w i + 1 ) | S ( t ) = s fo r t ∈ [ w i , w i + 1 )) . 3: Let ˜ T be the set of times in W when the Marko v chain changes state. Define ˜ S as the corre- spond ing set of state value s. R et urn ( ˜ s 0 , ˜ S , ˜ T ) . Pro position 3 T h e auxiliar y varia ble Gibbs sampler des cribed above h as the p osteri or distr ib utio n p ( s 0 , S , T | X ) as its statio nary distrib ution. Mor eov er , if Ω > max s | A s | , the r esulting Markov chain is irr educible . Pro of The fi rs t statement follo ws since the algorit hm simply introduces auxiliar y vari ables U , and then conditio nally samples V giv en X and W . For the second, note that if Ω > max s ( | A s | ) , then the intens ity of the subordin ating Poisson proc ess is strictl y positi ve. Thus, there is posit i ve prob abilit y densit y of sampling app ropriat e auxiliary jump times U and mov ing f rom any MJP trajecto ry to any other . Note that it is essen tial for Ω to be strictl y greater than max s | A s | ; equality is not suf ficient for irredu cibilit y . For ex ample, if all diagonal elements of A are equal to Ω , then the Poisson process for U T will ha ve intensity 0, so that the set of jump times T will nev er increas e. Since FFB S return s a ne w state sequence ˜ V that is indepen dent of V giv en W , the only depen- dence between su ccessi ve MCMC samples aris es b ecause t he ne w c andida te jump times incl ude the old jump times i.e., T ⊂ W . This means that the ne w MJP trajector y has non-zero probabi lity of making a jump at a same time as the old traject ory . Increasi ng Ω introdu ces more virtual jumps, and as T becomes a smaller subset of W , we get faster mixing. Of course, increasing Ω makes the HMM chain grow longer , leading to a linear increase in the computational cost per iteration. Thus the parameter Ω allo ws a trade-of f between mixing rate and computati onal cost. W e w i ll study this trade-o f f in Section 3.5. In all other expe riments, we set Ω = max s ( 2 | A s | ) as we find this works quite well, with the samplers typical ly con ver ging after fewer th an 5 iteration s. 3.3 Pre vious Po sterio r Sampling Schemes A simple approach when the MJP state is obser ved at the ends of an interv al is rejection sampling : sample paths giv en the observed start state via G il lespie ’ s algorit hm, and reject those that do not 9 R AO A N D T E H end in the observe d end state (Nielsen, 2002). W e can exten d this to noisy observ ations by im- portan ce sampling or particle fi l tering (Fan and Shelton, 2008). Recently , Golightly and W ilkin son (2011) hav e applied particle MCMC methods to correc t the bias introduc ed by standard particle filtering methods. Howe ver , these methods are ef ficient only in situati ons where the data ex erts a relati vely weak influence on the unobs erv ed trajectory (compared to the prior): a large state-sp ace or an unlike ly end state can result in a larg e number of rejections or small ef fecti ve sample sizes (Hobolth and Stone, 2009). A second approach, m o re specific to MJPs, integr ates out the infinitel y many paths of the MJP in between observ ations usi ng matrix exp onent iation (Equ ation (1)), and uses forwar d-back ward d y- namic programmin g to sum ov er the states at the finitely many observ ation times (see H o bolth and Stone (2009) for a re vie w). Unfortunatel y , matrix expon entiat ion is an expe nsi ve operatio n that scales as O ( N 3 ) , cubically in the number of states. Moreov er , the ma trix resulting from matrix expo nentia tion is dense and any stru cture (like sparsi ty), in the rate matrix A cann ot be exploited . A third appro ach is, like ours, based on the idea of uniformizat ion (Hobolth and Stone, 2009). This proceed s by produci ng indepen dent posterio r samples of the P o isson ev ents W in the interv al between observ ations, and then (like our sampler) running a discrete-t ime Markov cha in on this set of times to sample a ne w trajector y . Howe ver , sampling from the posterior distrib utio n ov er W is not easy , dependin g crucially on the observ ation process, and usuall y requires a random number of O ( N 3 ) matrix multiplic ations (as the sampler iterates over the possib le number of Poisson ev ents) . By contra st, instea d of producing in depen dent samples , ours is an MCMC algorithm. At the price o f produ cing dependen t samples, our m e thod scales as O ( N 2 ) giv en a random discret ization of time, does not require matrix expo nentia tions, easily exploit s structu re in the rate matrix and naturally ext ends to v arious exte nsions of MJPs. Moreo ver , we demonstrate that our sampler mixes very rapidl y . W e point out here that as th e nu mber of states N increases, if the transition rates A ss ′ , s 6 = s ′ , remain O ( 1 ) , then the uniformiza tion rate Ω and the total number of state transitions are O ( N ) . Thus, our algori thm no w scales overa ll as O ( N 3 ) , while the matrix expon entiati on-ba sed approach is O ( N 4 ) . In either case, w h ether A ss ′ is O ( 1 ) or O ( 1 / N ) , our algorithm is an order of magnitud e fast er . 3.4 Bayesia n Inference on the MJP Paramet ers In this secti on we briefly describe ho w full Bayesia n analys is can be perfo rmed by placing pri- ors on the MJP parameters A and π 0 and sampling them as part of the MCMC algori thm. Like Fearnhea d and S h erlock (2006), we place independe nt gamma priors on the (negati ve) diagonal el- ements of A and independ ent Dirichlet priors on the transition probabi lities. In particu lar , for all s let p s ′ s = A s ′ s / | A s | and define the prior: | A s | ∼ Gamma ( α 1 , α 2 ) , ( p s ′ s , s ′ 6 = s ) ∼ Dirichlet ( β ) . This prior is conju gate, w it h suf fi c ient statistics for the posterior distrib utio n giv en a trajector y S ( t ) being the to tal amoun t of time T s spent in each state s and the n umber of tra nsitio ns n s ′ s from ea ch s to s ′ . In particular , | A s | | ( s 0 , S , T ) ∼ Gamma ( α 1 + ∑ s ′ 6 = s n s ′ s , α 2 + T s ) , and (8) ( p s ′ s , s ′ 6 = s ) | ( s 0 , S , T ) ∼ Dirichlet ( β + ( n s ′ s , s ′ 6 = s )) (9) 10 F A S T M C M C S A M P L I N G F O R M J P S A N D E X T E N S I O N S It is important to note that we resample the rate matrix A conditione d on ( s 0 , S , T ) , a nd not ( v 0 , V , W ) . A ne w rate matrix ˜ A implie s a new uniformization rate ˜ Ω , and in the latter case, we must also accoun t for the probabil ity of the Poisson ev ents W under ˜ Ω . B e sides being more complicated , this coupli ng between W an d Ω can slo w down m i xing of the MCMC sampler . T hu s, we first discard the thinne d ev ents U , updat e A condition ed only on the MJP trajecto ry , and then reintrodu ce the thinne d ev ents under the ne w parameters. W e can vie w the sampler of A lg orithm 2 as a transiti on ker nel K A (( s 0 , S , T ) , ( ˜ s 0 , ˜ S , ˜ T )) that pres erv es the posterio r distrib ution under the r ate matrix A . O u r ov erall s ampler th en al ternate ly updates ( s 0 , S , T ) via th e tra nsitio n kernel K A ( · , · ) , and the n up dates A gi ven ( s 0 , S , T ) . Finally , we can either fix π 0 or (as is sometime s appropria te) set it equal to th e stationar y distri- b ution of the MJP with rate matrix A . In th e latter case, Equation s (8) and (9) serv e as a Met ropoli s- Hastings pro posal. W e accept a pr opose d ˜ A samp led from thi s distri b ution with proba bility equal to the p robab ility of th e cu rrent ini tial sta te un der t he st ationa ry distrib ution of ˜ A . Note that comput ing this stationary distri b ution require s solving an O ( N 3 ) eigen vector problem, so that in this case, the ov erall Gibbs sampl er scales cubically eve n thoug h Algorithm 2 scale s quadratical ly . 3.5 Experiments W e first look at the ef fect of the parameter Ω on the mixing on the MCMC sampler . W e generated a random 5-by-5 matrix A (with hyperpar ameters α 1 = α 2 = β = 1), and used this to generate an MJP trajectory with a uniform initial distrib ution ov er states. The state of this MJP trajectory was observ ed via a Poisson process like lihood m o del (see Section 4 ), and posterio r samples giv en the observ ations and A were produc ed by a C++ implementation of our algorithm. 1000 MCMC runs were perf ormed, each run consistin g of 10000 iteratio ns after a burn -in of 1000 iterations. For each run, the number of transition s as well as the time spent in each state was calcula ted, and ef fecti ve sample sizes (ESSs) of these statisti cs (the number of indepe ndent samples with the same ‘informa tion’ as the correlated MCM C samples) were calcul ated using R-COD A (Plummer et al., 2006). The ov erall ESS of a run is defined to be the median ESS across all these ESSs. Figure 3 (left) plots the over all ESS against computation time per run , for dif ferent scalings k , where Ω = k max s | A s | . W e see that increasing Ω does increase the m i xing rate, howe ver the added computation al cost quickly swamps out any benefit this might afford . F ig ure 3 (right) is a similar plot for the case where we also performed Bayesian inference for the M J P paramete r A as descri bed in Section 3.4. No w we estimated the ESS of all of f-diag onal elements of the matrix A , and the overa ll ESS of an MCMC run is defined as the median E SS. Interes tingly , in this scenari o, the ESS is fair ly insensiti ve to Ω , suggestin g an ‘MCMC within Gibbs’ update as proposed here using dependen t trajector ies is as effect i ve as one using independe nt trajectories . W e found this to be true in general: when embedded within an outer MCMC sampler , our sampler produced similar ef fecti ve ESS s as an MJP sampler that produces indepen dent traj ectorie s. The latter is typically more expensi ve, and in any case, we will show that the computati onal sav ings prov ided by our sampler far ou tweigh the cost of dependent trajectori es. In light of Figure 3, for all subsequen t exp eriments we set Ω = 2 m a x s | A s | . Figure 4 sho ws the initial b urn-in of a sampler with this setting for diff erent initializati ons. The vertical axis sho ws the number of state transi tions in the MJP traje ctory of each iteration. This quan tity quickly reaches its equili brium v alue within a fe w itera tions. 11 R AO A N D T E H 0 1 2 3 4 2000 4000 6000 8000 10000 12000 1.1 1.5 2 5 10 20 Time (seconds) Effective sample size 0 2 4 6 8 4000 5000 6000 7000 8000 1.1 1.5 2 5 10 20 Time (seconds) Effective sample size Figure 3: Effe cti ve sample sizes vs computation times for dif ferent scaling s of Ω for (left) a fixed rate matrix A and (righ t) B a yesian inferen ce on A . Whisk ers are qua rtiles over 100 0 runs. 2 4 6 8 0 200 400 600 800 1000 MCMC iteration number Number of transitions in MJP path Figure 4: Tra ce plot of the number of MJP transit ions for diff erent initializ ations . Black lines are the maximum and minimum number of MJP transit ions for each iteratio n, over all init ializat ions. 4. Marko v-Modulated P oisson Pr ocesses A Markov modulated Pois son process (MMPP) is a doubl y-stoc hastic P oi sson process whose inten- sity functio n is piece wise-co nstant and distrib uted accordi ng to a Marko v jump process. Suppose the MJP ( S ( t ) , t ∈ [ t st art , t end ]) has N states, and is paramet rized by an initial distrib ution over state s π 0 and a rate matrix A . Assoc iate with each state s a nonneg ati ve constant λ s called the emission rate of state s . Let O be a set of points drawn from a Poisson process with piece wise-co nstant rate R ( t ) = λ S ( t ) . Note that O is unre lated to the subord inatin g Poisson process from the unifo rmization - based constru ction of the MJP , and w e call it the output Poisson process. The Poisson observ ations O ef fecti vely form a continuous- time observ ation of the latent MJP , with the absenc e of P o isson e ven ts also informat i ve about the MJP state. MMPPs hav e been used to model pheno menon like the distrib ution of rare DN A motif s along a gene (Fearnhe ad and Sherlock , 2006), photon arri v al in 12 F A S T M C M C S A M P L I N G F O R M J P S A N D E X T E N S I O N S single molecule fl u oresce nce experiments (Burzyko wski et al., 2003), and requests to web serve rs (Scott and Smyth, 2003). Fearnhea d and S h erlock (2006) dev eloped an exact sampler for MMPPs based on a dynamic progra m for calculatin g the proba bility of O margina lizing out the MJP trajecto ry . The dynamic progra m keeps track of the probabili ty of the M MPP emitting all Poisson ev ents prior to a time t and ending in MJP state s . T h e dynamic pro gram then procee ds by itera ting ove r all Poisso n ev ents in O in increasi ng order , at each iteration updatin g prob abilit ies using m a trix exponen tiation . A backw ard sampling step then draws an exa ct posterior sample of the MJP trajecto ry ( S ( t ) , t ∈ O ) e v aluat ed at the times in O . Finally a uniformiz ation-b ased endpoint condi tioned MJP sampler is used to fill in the MJP trajec tory between eve ry pair of times in O . The main adv antag e of this method is that it produces independe nt poster ior samples. It does this at the price of being fai rly complic ated and computatio nally intensi ve . Moreov er , it has the disadv antage of operati ng at the time scale of the Poisson observ ation s rather than the dynamics of the latent MJP . For high Poisson rates, the number of matrix expon entiat ions will be high e ven if the underl ying MJP has ver y low tra nsitio n rates. This can lead to an inef ficient algorithm. Our MCM C sampler outline d in the pre vious section can be straightforw ardly ext ended to the MMPP without any of these disadv antag es. Resampling the auxiliary jump eve nts (step 1 in algo- rithm 2) remains unaf fected, since conditioned on the current MJP trajecto ry , they are indepen dent of the observ ations O . Step 2 require s calculati ng the emission likelihoo ds L i ( s ) , which is simply gi ve n by: L i ( s ) = ( λ s ) | O i | exp ( − λ s ( w i + 1 − w i )) , | O i | being the number of ev ents of O in the interv al [ w i , w i + 1 ) . Note that ev aluating this like lihoo d only require s counti ng the number of observe d Poisso n e vents between ev ery successi ve pair of times in W . C omp ared to our algorith m, the approach of Fearnhe ad and Sherlock (2006) is much more in vo lved and inef ficient. 4.1 Experiments In the follo wing, we compar e a C++ implementat ion of our algori thm with an implementat ion 2 of the algorithm of Fearnhead and S he rlock (2006), coded in C. W e performed fully Bayesian in- ferenc e, sampling both the MJP parameters (as describe d in Section 3.4) and the Poisson rates λ s (conju gate gamma priors were placed on these). In all instan ces, our algorith m did significant ly better , the performance improve ment increasing with the complex ity of the prob lem. In the first set of experimen ts, the dimensio n of the latent M J P was fixed to 5. T he prio r on the rate matrix A had par ameters α 1 = α 2 = β = 1 (se e Sec tion 3.4). The s hape parameter of the gamma prior on the emission rate of state s , λ s , was set to s (thereb y breakin g symmetry across states); the scale parameter was fixed at 1. 10 draws of O were simulated using the M MPP . F or each obser ved O , both MCMC algorithms were run for 1000 b urn-in iteratio ns follo wed by 10 000 ite rations where samples w e re collected. For each run, the ESS for each paramete r was estimated using R-CO D A , and the ov erall ESS was de fined to be the median ESS ove r all parameter s. Figure 5 reports the av erage co mputatio n ti mes required by each algorithm to produce 100 effec- ti ve samples, under differ ent scen arios. The leftmost plo t shows the computation ti mes as a functio n 2. Code was do wnloaded from Chris Sherlock’ s webpage. 13 R AO A N D T E H 10 0 10 1 10 2 10 −2 10 −1 10 0 10 1 CPU time (seconds) Fearnhead Our sampler 10 0 10 1 10 2 10 3 10 −3 10 −2 10 −1 10 0 10 1 10 0 10 1 10 2 10 −4 10 −2 10 0 10 2 Figure 5: CPU time to produce 100 effe cti ve samples as we observ e (left) increasing number of Poisson e vents in an interv al of lengt h 10, (centre) 10 Pois son e ve nts o ver i ncreas ing time interv als, and (right) increa sing interv als with the number of e ve nts increa sing on a ve rage. of the numbers of P o isson e ven ts observed in an interv al of fixed length 10. For our sampler , in- creasin g the number of observ ed ev ents lea ves the computati on time lar gely unaff ected, while for the sampler of Fearnhea d and Sherlock (2006), this increases quite significantly . This reiterate s the point that our sampler works at the time scale of the latent MJP , while Fearnhea d and Sherlock (2006) work at the time scale of the observ ed P o isson process. In the middle plot, we fix the num- ber o f observed P o isson ev ents to 10, while inc reasin g the len gth of the observ ation interv al instead , while in the rig htmost plot, w e increase bo th the interv al length a nd the av erage numbe r of observ a- tions in tha t inte rv al. In both case s, our sampler ag ain o f fers increased ef ficienc y of u p to two orders of magnitude . In fact, t he only problems where we observ ed the sampler of F ea rnhea d and Sherlock (2006) to outp erform ours were lo w-dimensional problems with only a fe w Poisson obse rv ation s in a long interv al, and w i th one very unsta ble state. A fe w very stable MJP states and a fe w very unstab le ones results in a high uniformizatio n rate Ω bu t only a fe w state transitio ns. The result ing lar ge number of virtual jumps can make our sample r inefficien t. 10 0 10 1 10 2 10 −2 10 −1 10 0 10 1 10 2 10 3 10 4 CPU time (seconds) dimension Fearnhead Our sampler Fearnhead (fixed prior) Our sampler (fixed prior) Figure 6: CPU time to produc e 100 ef fecti ve samples as the MJP dimension increases In F i gure 6, w e plot the time to produce 100 eff ecti ve samples as the number of states of the latent MJP increases. Here, we fixed the number of Poisson observ ations to 10 ove r an interv al 14 F A S T M C M C S A M P L I N G F O R M J P S A N D E X T E N S I O N S Figure 7: The predator -prey network (left) and the drug- ef fect CT BN (right) of length 10. W e see that our sampler (plotted with squares) of fers substantial speed-up ove r the sampler of Fearnhead and Sherlock (2006) (plotted with circles). W e see that for both samplers computa tion time scale s cubically with th e latent d imension . Howe ver , recall tha t this cub ic scali ng is not a prope rty of our M J P trajectory sampler; rather it is a consequen ce of using the equilibri um distrib ution of a sa mpled rate matrix as the initial distrib ution ove r s tates, which req uires calculatin g an eigen vector of a propos ed rate matrix. If we fix the initial distrib ution ov er state s (to the dis crete unifor m distrib ution), giv ing the line plotted with in verted triangles in the figure, we observ e that our sampler scale s quadraticall y . 5. Continuous-T ime Bayesian Network s (CTBNs) Continuo us-time Bayesian network s (CTBN s ) are compact, multi-componen t representati ons of MJPs with structured rate matrices (Nodelman et al., 20 02). Special instanc es of these models ha ve long existed in the literat ure, particula rly stoch astic kinetic models like the Lotka-V olterra equa- tions, which describ e interac ting popula tions of animal specie s, chemica l reactants or gene regu - latory netwo rks (W ilkinson, 2009). There hav e also been a number of related dev elopmen ts, see for example Bolch et al. (1998) or Didelez (2008). For concret eness howe ver , w e shall focus on CTBNs, a formalis m introduced in Nodelman et al. (2002) to harnes s the representati onal power o f Bayesian netwo rks to characterize structure d MJPs. Just as the familiar Bayesian netwo rk uses a product of conditio nal probab ility tables to repre- sent a much larg er probab ility table, so too a CTB N represen ts a structur ed rate matrix with smaller condit ional rate matrices. A n m -component CT BN represen ts the state of an MJP at time t with the states of m nodes S 1 ( t ) , . . . , S m ( t ) in a directed (and possibly cyclic) graph G . F ig ure 7 sho ws two C TBNs, the ‘predato r -pre y network ’ and the ‘drug-ef fect network’. The former is a CTBN gov erned by the Lotka-V olter ra equatio ns (see subsection 5.3.1), while the latter is used to model the d epend encies in e vents leading to and follo wing a p atient takin g a drug (Node lman et al., 200 2). Intuiti vely , each node of the CTB N acts as an MJP with an instan taneou s rate matrix that de- pends on the curr ent configu ration of its parents (and not its chil dren, althou gh the pres ence of directe d cycles means a child can be a parent as well). The trajec tories of all nodes are piece w is e consta nt, and when a node ch anges stat e, the e vent rat es of all its ch ildren chan ge. The graph G and 15 R AO A N D T E H Figure 8: Expanded CTBN the s et of r ate matrice s (one fo r eac h node and for each configu ration of it s par ents) chara cterize the dynamic s of the CTBN, the former describing the structu re of the dependenc ies between variou s compone nts, and the latter quantify ing this. Completing the specificati on of the CTBN is an initia l distrib ution π 0 ov er the state of nod es, possibly specified via a Bayesian netwo rk. It is con ven ient to think of a C TBN as a compact repres entatio n of an exp anded (and now acy clic) graph, consis ting of the nodes of G repeated infinitely along a continu um (viz. time). In this graph, arro ws lead from a node at a time t to instan ces of its children at time t + d t . Figure 8 displa ys this for a sectio n of the drug-ef fect CTB N. The rates associ ated w it h a particular node at time t + d t are determined by the configuration of its parents at time t . F ig ure 8 is the continuo us- time limit of a class of discr ete-time m o dels called dynamic B a yesian networks (DBN s) (Murphy, 2002). In a DBN, the sta te of a node at stage i + 1 is depend ent upon the configuration of its parents at stage i . Just as MJPs are continu ous-t ime limits of discrete-ti me Markov cha ins, CTBNs are also contin uous- time limits of DBNs. It is poss ible to combine all local rate matrices of a CT BN into one global rate matrix (see Nodelman et al., 2002), res ulting i n a si mple MJP whose state -space i s the pro duct st ate-spa ce of all compone nt nodes. Consequen tly , it possib le, conceptual ly at least, to directl y sample a trajecto ry ov er an interv al [ t st art , t end ] using Gillespie’ s algorithm. Ho weve r , with an eye to wards inferen ce, Algorith m 3 describe s a generati ve process that explo its the structure in the graph G . Like Section 2, we represen t the trajector y of the CTBN , S ( t ) , w it h the initial state s 0 and the pair of seque nces ( S , T ) . L et the CTBN hav e m nodes. N o w , s i , the i th element of S , is an m -componen t vecto r repres enting the states of all nodes at t i , the time of the i th state change of the CTBN . W e write this as s i = ( s 1 i , · · · , s m i ) . Let k i identi fy the component of the CTBN that changed state at t i . T h e rate matrix of a node n v aries ove r t ime as th e configuration of its parents ch anges , and we will write A n , t for the re le v ant matrix at time t . Followin g Equation (2), we ca n write do wn the probabil ity densi ty of ( s 0 , S , T ) as p ( s 0 , S , T ) = π 0 ( s 0 ) | T | ∏ i = 1 A k i , t i − 1 s k i i s k i i − 1 ! exp − m ∑ k = 1 Z t end t start | A k , t S k ( t ) | d t ! . (10) 16 F A S T M C M C S A M P L I N G F O R M J P S A N D E X T E N S I O N S Algorithm 3 Algorithm to sample a CTBN trajec tory on the interv al [ t st art , t end ] Input: The CTBN graph G , a set of rate matrices { A } for all nodes and for all parent configura tions and an initial distr ib ution ov er state s π 0 . Output: A CTBN trajecto ry S ( t ) ≡ ( s 0 , S , T ) . 1: Draw an ini tial configuratio n s 0 ≡ ( s 1 0 , s 2 0 , ... ) ∼ π 0 . Set t 0 = t st art and i = 0. 2: loop 3: For ea ch node k , draw z k ∼ exp ( | A k , t i s k i | ) . 4: Let k i + 1 = argmin k z k be the first node to change state. 5: If t i + z k i + 1 > t end then r etur n ( s 0 , . . . , s i , t 1 , . . . , t i ) and stop . 6: Incre ment i and let t i = t i − 1 + z k i be the ne xt jump time. 7: Let s ′ = s k i i − 1 be the pre vious state of node k i . 8: Set s k i i = s with probabili ty proportio nal to A k i , t i − 1 ss ′ for each s 6 = s ′ . 9: Set s k i = s k i − 1 for all k 6 = k i . 10: end loop 5.1 Infer ence in CTBN s W e now consid er the problem of posterio r inference ov er trajecto ries giv en some observ ations . Write the parents and children of a node k as P ( k ) and C ( k ) respecti vely . Let M B ( k ) be the Markov blank et of node k , which consist s of its parents, children, and the parents of its children. Giv en the entire trajectories of all nodes in M B ( k ) , node k is independent of all other nodes in the network (Nodelman et al., 2002) (see also Equation (12) belo w). T h is suggest s a Gibbs sampling scheme where the trajectory of each node is resampled gi ve n the configuration of its Marko v blank et. T h is approa ch was fol lo wed by El-Hay et al. (2008). Ho wev er , e ve n without any assoc iated observ ations, sampling a node trajec tory conditi oned on the c omplete trajectory of its Mark o v bla nke t is not st raight forwar d. T o see this , rearra nge the terms of Equatio n (10 ) to g i ve p ( s 0 , S , T ) = π 0 ( s 0 ) m ∏ k = 1 φ ( S k , T k | s 0 , S P ( k ) , T P ( k ) ) , and φ ( S k , T k | s 0 , S P ( k ) , T P ( k ) ) = ∏ i : k i = k A k , t i − 1 s k i s k i − 1 ! exp − Z t end t start | A k , t S k ( t ) | d t , (11) where for any set of nodes B , ( s B 0 , S B , T B ) represents the associated trajecto ries. Note that the φ ( · ) terms are not condition al densities giv en parent trajectorie s, since the graph G can be cyclic. W e must also account for the trajectories of node k ’ s children , so that the condit ional density of ( s k 0 , S k , T k ) is actually p ( s k 0 , S k , T k | s ¬ k 0 , S ¬ k , T ¬ k ) ∝π 0 ( s k 0 | s ¬ k 0 ) φ ( S k , T k | s 0 , S P ( k ) , T P ( k ) ) · ∏ c ∈ C ( k ) φ ( S c , T c | s 0 , S P ( c ) , T P ( c ) ) . (12) Here ¬ k denotes all nodes other than k . Thus, e ven ove r an interv al of time where the parent configu- ration remains constan t, the conditi onal di strib ution of the trajecto ry of a n ode is not a homogeneou s 17 R AO A N D T E H MJP because of the ef fect of the node’ s children , which act as ‘observ ations’ that are contin uously observ ed. For any child c , if A c , t is constan t over t , the corresp ondin g φ ( · ) is the density of an MJP gi ve n the initial state. Since A c , t v aries in a piece wise-co nstan t manner according to the state of k , the φ ( · ) term is actually the densit y of a piecewis e-inho mogeneous MJP . Effec ti ve ly , we hav e a ‘MJP-modulat ed MJP’, so that the inferenc e problem here is a general ization of that for the MMPP of Section 4. El-Hay et al. (200 8) describ ed a matrix-e xpon entiat ion-based algori thm to update the tr ajector y of node k . At a high-le vel their algorithm is similar to Fearnhead and Sherlock (2006) for MMPPs, with the Poisson observ ation s of the M MPP generali zed to transitions in the trajectorie s of child nodes . Consequent ly , it uses an expens i ve forwa rd-bac kward algorithm in volv ing matrix exponen - tiation s. In ad dition , El-Hay et al. (2 008) resor t to discretizin g time via a binary se arch to obtain the transit ion times upto machin e accuracy . 5.2 A uxiliary V ariable Gibbs Sampling f or CTBNs W e no w sho w ho w our uniformiza tion-b ased sampler can eas ily be ad apted to con dition ally sample a trajectory for n ode k without resorti ng to approximatio ns. In the fo llo w i ng, for n otatio nal simplic- ity . we will drop the superscript k whenev er it is clear from context. For node k , the MJP trajector y ( s 0 , S , T ) has a unif ormized constru ction from a subordina ting Poisson proce ss. T h e pie ce w is e con- stant trajectorie s of the parents of k imply that the MJP is piece wise homoge neous , and we will use a piecewis e constant rate Ω t which dominates the associ ated transiti on rates, i.e., Ω t > | A k , t s | for all s . This allo ws the dominatin g rate to ‘adapt’ to the local transition rates, and is more ef- ficient when, e.g., the transi tion rates associat ed with diffe rent parent configura tions are mark edly dif ferent. Recall also that our algori thm first recons tructs the thinned Poisson e ve nts U T using a piece wise homogen eous Poisson proces s with rate ( Ω t + A k , t S ( t ) ) , and then update s the trajectory us- ing the forward-ba ckwar d algorith m (so that W = T ∪ U T forms the candid ate transiti ons times of the MJP). In the presen t CTBN context, just as the subordinat ing Poi sson process is inhomogene ous, so too the Markov chain used for the forward- backw ard algorithm will hav e diff erent transitio n matrices at dif ferent times. In particula r , the transition matrix at a time w i (where W = ( w 1 , . . . , w | W | ) ) is B i = I + A k , w i Ω w i . Finally , we need also to specify the likeliho od function L i ( s ) accounting for the trajecto ries of the childre n in addition to actual observ ations in each time interv al [ w i , w i + 1 ) . From Equatio ns (11) and (12), this is gi ven by L i ( s ) = L O i ( s ) ∏ c ∈ C ( k ) ∏ j : k j = k , t j ∈ [ w i , w i + 1 ) A k , t j − 1 s k j s k j − 1 ! exp − Z w i + 1 w i | A k , t S k ( t ) | d t , where L O i ( s ) is the likeliho od coming from actual observ ation s depende nt on the state of node k in the time interv al. Note that the likeliho od abov e depends only on the number of transitio ns each of the chil dren make a s well as how much time the y sp end in ea ch state, for each parent con figuratio n. The new trajectory ˜ S k ( t ) is now obtained using the forwa rd-filteri ng backw ard-samp ling algo- rithm, with the giv en inhomog eneou s transiti on matrices and likel ihood functio ns. The follo wing propo sition no w follo ws directly from our pre vious result s in Section 3: 18 F A S T M C M C S A M P L I N G F O R M J P S A N D E X T E N S I O N S 0 500 1000 1500 2000 2500 3000 0 5 10 15 20 True path Mean−field approx. MCMC approx. 0 500 1000 1500 2000 2500 3000 0 5 10 15 20 25 30 Figure 9: Posterior (mean and 90% credible interv als) ov er (left) prey and (right) predat or paths (obser v ation s (circles) w er e a v ailab le only until 1500). Pro position 4 T h e auxiliar y vari able Gibbs sampler described above con verg es to the posterior distrib ution over the CTBN sample paths. Note that our algorithm produce s a new trajecto ry that is depen dent, through T , on the previ- ous trajecto ry (unlik e a true Gibbs update as in E l-Hay et al . (2008) where they are independ ent). Ho wev er , we find that since the update is part of an ove rall Gibbs cycle over nodes of the C TBN, the mixing rate is actually dominated by dependen ce across nodes. Thus, a true Gibbs update has neg ligibl e benefit to wards mixing, while bein g more expensi ve computationa lly . 5.3 Experiments In the follo wing, we e v aluat e a C++ implement ation of our algorit hm on a number of CTBNs. As before , the domina ting rate Ω t was set to max s 2 | A k , t s | . 5 . 3 . 1 T H E L O TK A - V O L T E R R A P R O C E S S W e first apply our sampler to the Lotka-V olte rra process (W ilkinson, 2009; Opper and Sanguinetti, 2007). C o mmonly referred to as the predator -prey model, this describ es the ev olution of two in- teracti ng populati ons of ‘prey’ and ‘predator’ species. The two species form the two nodes of a cyc lic CTBN (Figure 7 (left)), whose states x and y represent the sizes of the prey and predator popul ations . The proces s rates are gi ve n by A ( { x , y } → { x + 1 , y } ) = α x , A ( { x , y } → { x − 1 , y } ) = β xy , A ( { x , y } → { x , y + 1 } ) = δ xy , A ( { x , y } → { x , y − 1 } ) = γ y , where we set the parameter s as follo w s : α = 5 × 10 − 4 , β = 1 × 10 − 4 , γ = 5 × 10 − 4 , δ = 1 × 10 − 4 . All oth er rates are 0. This de fines two in finite sets of in finite-dimen siona l conditiona l rate matrice s. In its presen t form, our sampler canno t handle this infinite state-s pace (but see Rao and T eh, 20 12). Like Opper and Sanguinett i (2007), we limit the maximum number of indi vidu als of each spec ies to 200, leav ing us with 400 rate matrices of si ze 200 × 200. N o te that these mat rices are tridiagonal an d ver y sparse: at any time the size of each populat ion can change by at most one. Consequent ly , the comple xity of our algorith m sc ales linearly with the number of states (we did not modify our code to 19 R AO A N D T E H 10 100 1000 10000 Number of samples 10 −1 10 0 10 1 Uniformization El Hay et al. Average Relative Error Figure 10: A vera ge relati ve error vs number of samples for 1000 independ ent runs; burn -in = 200. Note that in this scenari o, unifor mization was about 12 times faster , so that for the same computa- tional ef fort, it produ ces significantly lower errors. exp loit this str ucture , though this i s straightf orward ). A ‘t rue’ path of pred ator -prey popul ation si zes was sampled from th is proce ss, and its state at ti me t = 0 was observ ed noisel essly . Additionall y 15 noisy observ ations were generat ed, spaced unifor mly at interv als of 100. The noise process was: p ( X ( t ) | S ( t )) ∝ 1 2 | X ( t ) − S ( t ) | + 10 − 6 . Giv en these observ ations (as well as the true paramet er v alues) , we approxi mated the posterio r dis- trib ution ov er paths by tw o method s: using 1000 samples from our MCMC samp ler (with a b urn- in period o f 10 0) and using the mean- field (MF) approximation of Opp er and Sanguinett i (2007) 3 . W e could not apply the implementation of the Gibbs sampler of (El-Hay et al., 2008) (see Section 5.4) to a state- space and time-interv al this lar ge. Figure 9 sho w s the true paths (in black), the obser - v ation s (as circles) as well as the posterior means and 90% credibl e interv als produ ced by the two algori thms for the prey (left) and preda tor (right) populatio ns. As can be seen, both algorith ms do well over the first half of th e interv al where data is presen t. In the sec ond ha lf, the MF a lgorit hm ap- pears to u ndere stimate the predicted size of the predato r population. On the other hand , the MCMC poster ior reflects the true trajector y better . In general , we found the MF algorithm to underestimate the posteri or v arianc e in the MJP trajec tories , especially ov er regio ns with few obs erv ations. 5.4 A verage Relativ e Error vs Number of Samples For the remaining experimen ts, w e compared our sampler w i th the G ib bs sampler of El-Hay et al. (2008). For this compariso n, we used the CTB N-RLE package of Shelton et al. (2010) (also im- plemente d in C++). In all our expe riments, as with the MMPP , we found our algorithm to be significa ntly faster , especially for large r problems. T o pre ve nt details of the two implementa tions from clouding the picture and to reiter ate the benefit af forde d by av oiding matrix exponen tiatio ns, we also measured the amount of time CTBN-RLE spent exponen tiatin g m a trices. This constit uted between 10% to 70 % of the tota l running time of their algo rithm. In the plo ts we refer to this as ‘El Hay et al. (Matrix Exp.)’. W e found that our algorithm took less time than ev en this. 3. W e thank Guido Sanguinetti for provid ing us with his code. 20 F A S T M C M C S A M P L I N G F O R M J P S A N D E X T E N S I O N S In our first expe riment, we follo wed El-Hay et al. (2008) in studying ho w av erage relati ve error v aries with the number of samples from the Mark ov chain. A vera ge relati ve error is define d by ∑ j | ˆ θ j − θ j | θ j , and m e asures the total normaliz ed diff erence between empirical ( ˆ θ j ) and true ( θ j ) av- erages of sufficie nt statistic s of the posterior . The statistics in quest ion are the time spent by each node in dif feren t states as well as the number of transiti ons from each state to the others. The exact v alues were calculated by numerical integrat ion when possi ble, otherwise from a very long run of CTBN-RL E. As in El-Hay et al. (2008), we conside r a CTBN with the topology of a chain, consisti ng of 5 nodes , each with 5 states. The states of t he no des were ob serv ed at times 0 and 20 and we produc ed endpo int-co nditio ned post erior samples of paths over the time interv al [ 0 , 20 ] . W e calculate the a ver age relati ve error a s a function of the number o f sampl es, with a burn -in of 20 0 samp les. Figure 10 sh o ws the results from runn ing 1000 in depen dent chains for bo th sampler s. Not surpris ingly , the sampler of El-Hay et al. (2008), which produces conditiona lly indepen dent sample s, has slight ly lo wer errors. Ho wev er the dif ference in relativ e errors is m in or , and is neglig ible when conside ring the dramatic (sometimes up to two orders of magnitude ; see below) speed improv ements of our algori thm. For i nstanc e, to produce the 10000 samples, the El-Hay et al . (2008) sample r took about 6 minutes , while our sampler ran in about 30 seco nds. 5.5 Time Requir ements f or the Chain-Shaped CTBN 10 0 10 1 10 2 10 −2 10 0 10 2 CPU time in seconds Length of CTBN chain Uniformization El−Hay El−Hay (exp) 10 0 10 1 10 2 10 −2 10 −1 10 0 10 1 10 2 CPU time in seconds Dimensionality of nodes in CTBN chain Our sampler El−Hay El−Hay (exp) 10 0 10 1 10 2 10 0 10 2 10 4 CPU time in seconds Length of CTBN time−interval Our sampler El−Hay El−Hay (exp) Figure 11: CPU time vs (left) leng th of C TBN chain (cent re) number of states of C TBN nodes (right) time interv al of CTBN paths. In the next two experimen ts, we compare the times requir ed by CTB N-RLE and our unifor mization - based sampler to produce 100 ef fecti ve samples as the size of the chain-sh aped CTB N increased in dif ferent ways. In the first cases , we inc reased the length of the chain , and in t he se cond, th e dimen - sional ity of each node. In both ca ses, we produ ced posterior samples from an en dpoin t-cond itioned CTBN with random gamma distri b uted paramete rs. The time requirements were estimated from runs of 100 00 samples after a burn -in period of 1000 iteratio ns. Since CTBN - RLE does not support B ay esian infere nce for CT BN para meters, we kep t these fixed to the truth. T o produce ESS estimates, we counted the number of transiti ons of each node and the amount of time spent in each state, and for each MCMC run, we estimated the ESS of these quan tities. Like in Section 4.1, the ov erall ES S i s the median of these estimat es. E ac h point in the figures is an a ver age ove r 10 simulatio ns. 21 R AO A N D T E H In the fi rs t of these exp eriments , we measured the times to produce 100 ef fecti ve samples for the chain-sh aped CTBN describe d above , as the number of nodes in the chain (i.e., its length) increa ses. T h e lef tmost plot in Figure 11 sho ws the res ults. As might be exp ected, th e time required by our algorithm gro ws linearly with the number of nodes. For El-Hay et al. (2008), the cost of the algori thm gro ws f aster th an linear , and quickly be coming unmanageabl e. The time spent calculating matrix expone ntials does gro w linearly , ho wev er our unifo rmization -based samp ler always takes less time than ev en this. Next, w e kept the length o f the chain fixed at 5, in stead increasin g the number of s tates per node. As seen in the middle plot, once again, ou r sampler is always f aster . Asymptotically , we exp ect our sampler to scale as O ( N 2 ) and El-Hay et al. (2008) as O ( N 3 ) . While we ha ve not hit that regime yet, we can see that the cost of our sampler gro w s more sl o wly with the number of states. 5.6 Time Requir ements f or the Drug-Effect CTBN Our final expe riment, reported in the rightmost plot of Figure 11, measures the time required as the interv al length ( t end − t st art ) increases. For this experimen t, we used the drug-ef fect network sho wn in Figure 7, where the parameters were set to standa rd val ues (obtaine d from CT BN-RLE) and the state of the network was fully observ ed at the begi nning and end times. Again, our algorithm is the fast er of the two, sho w in g a linear increas es in computati onal costs with the length of the interv al. It is worth pointing out here that the algorithm of El-Hay et al. (2008) has a ‘precision’ parameter , and that by reducing the desire d temporal precision, faste r performan ce can be obtained. Ho wev er , since our sample r pro duces e xact samples (up to nu merical pr ecision ), our compa rison is fair . In the abo ve ex perimen ts, we left this paramet er at its def ault valu e. 6. Discussion W e proposed a nov el Mark ov chain Monte Carlo sampling method for Marko v jump processes. Our method exploi ts the simplification of the structure of the MJP result ing from the introduct ion of auxiliary v ariabl es via the idea of uniformiz ation. T hi s constructs a Markov jump process by subord inatin g a Markov chain to a P o isson process, and amounts to running a Marko v chain on a random discr etizati on of time. O u r sampl er is a b lock ed Gibbs sampler in t his aug mented represen - tation and proceeds by alternately resampling the discret izatio n gi ven the Markov chain and vice ver sa. E x periment ally , w e fi n d that this auxiliary variab le Gibbs sampler is computationa lly very ef ficient. The sampler e asily generalize s to ot her MJP-b ased mode ls, an d w e presented sample rs fo r Marko v-modulated Poisson proce sses and continuous -time Bayesian net works . In our e xperiments, we sho w ed sig nificant speed-u p compared to state-of- the-ar t samplers for both. Our method open s a number of a ve nues worth e xplor ing. One conce rns the subordina ting Pois- son rate Ω w h ich acts as a free- paramete r of the sampl er . While our heuristic of settin g this to max s 2 | A s | work ed w el l in our exper iments, this may not be the case for rate m a trices w i th widely v aryin g transi tion rates. A possible approa ch is to ‘learn’ a good setting of this parameter via adapti ve MCMC methods . M o re fundamentall y , it would be intere sting to in vesti gate if theoretical claims can be made ab out the ‘b est’ set ting of this parameter under some measures of mixin g speed and computa tional cost. Next, there are a number of immediate generalizat ions of our sampler . First, our algorithm is easily applicabl e to inhomogen eous M a rko v jump proces ses where techniques based on matrix ex- ponen tiation cannot be applie d. Fo llo w i ng recent work (Rao and T eh, 2011b), we can also look at 22 F A S T M C M C S A M P L I N G F O R M J P S A N D E X T E N S I O N S genera lizing our sampler to semi-Marko v processes w h ere the holding times of the states follo w non-e xponential distrib utions. These models fi n d applica tions in fields like biost atistic s, neuro- scienc e and queuin g theory (Mode and Pick ens, 1988). By combining our techniqu e with slice sampling ideas (Neal, 2003), we can exp lore Marko v jump processe s with countably infinite state spaces . Another generalizat ion concerns MJPs with unbou nded rate matr ices. For the p redato r -pre y model, we av oided this problem by bo undin g the maximum popu lation sizes; otherwise it is impos- sible to choose a dominating Ω . Of course, in practical settings, any trajecto ry from this process is bound ed with probabili ty 1, and we ca n ex tend our method to this case by treating Ω as a tr ajecto ry depen dent random v ariab le. For some wor k in this directio n, w e r efer to Rao and T eh (201 2). Acknowledgmen ts This work was done whil e both autho rs were at th e Gatsby Computati onal Neuroscien ce Unit, Uni- ver sity College London. W e would like to acknowle dge the Gatsby Charitable Foundation for gen- erous funding . W e thank the associate editor and the anon ymous revie wers for usefu l comments. Ap pendix A. The Forward-Filtering Backward-Samp ling (FFBS) Algorithm For completeness , we include a descripti on of the forwa rd-filterin g backward- sampling algorithm for discrete -time Marko v chain s. The earliest referen ces for this that we are awa re of are Fr ¨ uwirth-Schn atter (1994) and Carter and K ohn (199 6). Let S t , t ∈ { 0 , · · · T } be a di screte- time Marko v chain with a discret e state space S ≡ { 1 , · · · N } . W e allo w the chain to be inhomogen eous, with B t being the state transit ion m at rix at time t (so that p ( S t + 1 = s ′ | S t = s ) = B t s ′ s ). Let π 0 be the initial distrib ution over states at t = 0. Let O t be a noisy observ ation of the state at time t , with the likel ihood giv en by L t ( s ) = p ( O t | S t = s ) . Giv en a set of observ ations O = ( O 0 , · · · , O T ) , FFBS returns an indepen dent posteri or sample of the state vect or . Define α t ( s ) = p ( O 0 , · · · , O t − 1 , S t = s ) . From the Marko v property , we ha ve the follo w in g re- cursio n: α t + 1 ( s ′ ) = N ∑ s = 1 α t ( s ) L t ( s ) B t s ′ s . Calculati ng this for all N values of s ′ tak es O ( N 2 ) computation , and a forward pass through all T times is O ( T N 2 ) . At the end of the forward pass, we ha ve a v ector β T ( s ) : = L T ( s ) α T ( s ) = p ( O , S T = s ) ∝ p ( S T = s | O ) . It is easy to sample a realizat ion of S T from this. Next, note that p ( S t = s | S t + 1 = s ′ , O ) ∝ p ( S t = s , S t + 1 = s ′ , O ) = α t ( s ) B t s ′ s L t ( s ) p ( O t + 1 , · · · , O T | S t + 1 = s ′ ) ∝ α t ( s ) B t s ′ s L t ( s ) , where the second equality follo w s from the Marko v prope rty . This too is easy to sample from, and the backwar d pass of FF BS success i vel y samples S T − 1 to S 0 . W e thus hav e a sample ( S 0 , · · · , S T ) . The ov erall algorith m is gi ven belo w: 23 R AO A N D T E H Algorithm 4 The forwar d-filterin g backward -samplin g algori thm Input: An initial distrib ution over states π 0 , a sequenc e of transition matri- ces B t , a sequ ence of observ ations O = ( O 1 , · · · O T ) with lik elihoo ds L t ( s ) = p ( O t | S t = s ) . Output: A realizati on of the Mark ov chai n ( S 0 , · · · , S T ) . 1: Set α 0 ( s ) = π 0 ( s ) . 2: for t = 1 → T do 3: α t ( s ′ ) = ∑ N s = 1 α t − 1 ( s ) L t − 1 ( s ) B t − 1 s ′ s for s ′ ∈ { 1 , · · · , N } . 4: end for 5: Sample S T ∼ β T ( · ) , where β T ( s ) : = L T ( s ) α T ( s ) . 6: for t = T → 0 do 7: Define β t ( s ) = α t ( s ) B t S t + 1 s L t ( s ) . 8: Sample S t ∼ β t ( · ) . 9: end for 10: ret urn ( S 0 , · · · , S T ) . Refer ences G. Bolch, S. Greiner , H. de Meer , and K. S. Tri vedi. Queueing Networks and Marko v Chains : Modeling and P erformance Evalu ation with Computer Science App licati ons . W iley-Int erscien ce, New Y ork, NY , USA , 1998. ISB N 0 -471- 19366 -6. R. J. Boys, D. J. W ilkin son, and T . B. L. Kirkwood. Bayesian inferenc e for a discretely observ ed stocha stic kinetic model. Stati stics and Computing , 18(2):125– 135, 2008. L. Breuer . F r om Mark ov Ju mp Pr oces ses to Spatial Queues . Springer , 2003. ISBN 978-1-4020 - 1104- 7. T . Burzyko wski, J. Szubiako wski, and T . Ryd ´ en. Analysi s of photo n cou nt data fro m single- molecule fluoresce nce experiments . Chemical Physics , 288(2-3 ):291– 307, 2003. C. K. Carte r a nd R. K ohn. Marko v cha in Mon te Carlo in condition ally Gaussian s tate space model s. Biometrika , 83:5 89–60 1, 1996. E. C ¸ inlar . Intr oduction to Stoc hast ic Pr ocesses . Prentice H al l, 1975. I. Cohn, T . El-Hay , N. Friedman , and R. Kupferman. Mean field variat ional appro ximation for contin uous- time Bayesian network s. J. Mach. L e arn. Res. , 11:2745 –2783 , December 2010. ISSN 1532- 4435. D. J. Daley a nd D. V ere-Jon es. An Intr oduction to the Theory of P oint Pr ocess es . Spring er , 2008. V . D i delez. Graphical m o dels for m a rke d point processe s based on local independ ence. Journ al of the Royal Statisti cal Society: Series B , 70(1):2 45–26 4, 2008. ISSN 1467-98 68. T . El-Hay , N . F r iedman, and R. Ku pferman. Gibbs sampling in factori zed continuous- time Marko v proces ses. In Pr oceed ings of the T w en ty-fou rth Confer ence on Uncertain ty in Artificial Intelli- gen ce (U AI) , pages 169– 178, 2008. 24 F A S T M C M C S A M P L I N G F O R M J P S A N D E X T E N S I O N S R. Elliott and C. Osakwe. Option pricin g for pure jump proce sses with Marko v switching compen- sators . F inance and Stoc hastic s , 10:250– 275, 2006. Y . Fan and C. R. Shelton. Sampling for approximate inference in continuou s time Bayesian net- works . In T enth Internatio nal Symposium on Artificial Intellig ence and Mathemati cs , 2008. P . Fearn head and C. Sherloc k. An ex act Gibbs sample r for the Mark ov -modula ted Poisson proces s. J ourna l O f The Roy al Statisti cal Society Series B , 68(5):767– 784, 2006. S. F r ¨ uwirth-Schnatte r . Data augmentati on and dynamic linear m o dels. J . T ime Ser . Anal. , 15:183– 202, 1994. D. T . Gillespie. Exact stoch astic simulation of coupled chemical reactions . J . Phys. Chem. , 81 (25): 2340– 2361, 1977. ISSN 002 2-365 4. A. Golightly an d D. J. W ilkinson. Bayesian pa rameter inference fo r stochastic bioch emical ne twork models using partic le Marko v chain Monte Carlo. Inter face F ocus , 1(6):807–8 20, Decembe r 2011. A. Hobolth a nd E. A Stone. Simulation from endpoint- condi tioned, continuo us-time Mark ov chains on a finite state space, with applicatio ns to molecular ev olution. A nn . Appl. Stat. , 3(3):12 04, 2 009. ISSN 1941-7 330. A. Jensen . Mark of f chains as an aid in the study of Marko f f processe s. Skand. Aktuarie tiedskr . , 36: 87–91 , 1953. O. Kallenber g. F oundati ons of Modern Pr obabili ty . Probability and its Applica tions. Spring er - V erlag, Ne w Y ork, Second edition, 2002. IS BN 0-387-95 313-2 . C. J. Mode and G. T . Pickens. Computational methods for rene wal theory and semi-Marko v pro- cesses with illustr ati v e examples. The American Statist ician , 42(2):p p. 143–15 2, 1988. ISSN 00031 305. K. P . Murphy . Dynamic Bayesian Networks: Repr esentation , Infer ence and Learning . PhD thesis , Uni ver sity of California , Berke ley , 2002. R. M. Neal. Slice sampling. Annals of Statistics , 31:705– 767, 2003. R. Nielsen. Mapping mutations on phylog enies. Syst Biol , 51(5) :729–7 39, 2002. U. Nodelman, C.R. Shelto n, and D. K oller . Continuous time Bayesian networ ks. In Pr oceed ings of the Eighteent h Confer ence on Uncertain ty in Artificial Intellig ence (UAI) , pa ges 378–3 87, 2002. U. N o delman, D . K olle r , and C.R. Shelton. Expectatio n propa gation for continuous time Bayesian netwo rks. In Pr oceedings of the T w en ty-fir st Confer ence on Uncert ainty in Artificial Intellig ence (U AI) , pages 431–440 , July 2005. M. O p per and G. Sanguinett i. V ariationa l inference for Marko v jump processes. In A dv ances in Neura l Information Pr ocessing Syste ms 20 , 2007. 25 R AO A N D T E H M. P l ummer , N. Best, K. Co wles, and K. V ines. C OD A: Con ver gence diagnosi s and output an alysis for MCMC. R News , 6(1 ):7–1 1, March 2006. V . Rao and Y . W . T eh. Fast M CMC sampling for Mark ov jump proce sses and conti nuous time Bayesian networks . In Pr oceedin gs of the T wenty-se venth Con fer ence on Uncertai nty in A rt ificial Intelli gen ce (U AI) , 2011 a. V . Rao and Y . W . T eh. G a ussian process modulated renew al processe s. In Advances in Neural Informat ion P r ocessing Systems 23 , 2011b. V . Rao and Y . W . T eh. MCMC for contin uous- time discrete -state systems. In Advances in Neural Informat ion P r ocessing Systems, 24 , 2012. S. L. S c ott and P . Smyth. T h e Marko v m o dulate d Poisson process and Marko v P o isson cascade with appli cation s to w eb traffic modelin g. Bayesian Statistics , 7:1–10, 2003. C. Shelton, Y . Fan, W . Lam, J. L e e, and J. Xu. Continuous time Bayesian network reason ing and learnin g engine , 2010. http: //mlo ss.or g/software/view/216/ . H. C. T ijms. Stochast ic Modelling and Analysis : a Computational A p pr oac h . W iley series in probab ility and mathematical statistics: Applied probab ility and statistics . Wi ley , 1986 . ISBN 97804 71909 118. D. J. W ilkin son. Stochastic modelling for quantitati ve description of hetero geneo us biologic al sys- tems. Natur e R e vie ws Genetics , 10:122–1 33, 2009. 26
Original Paper
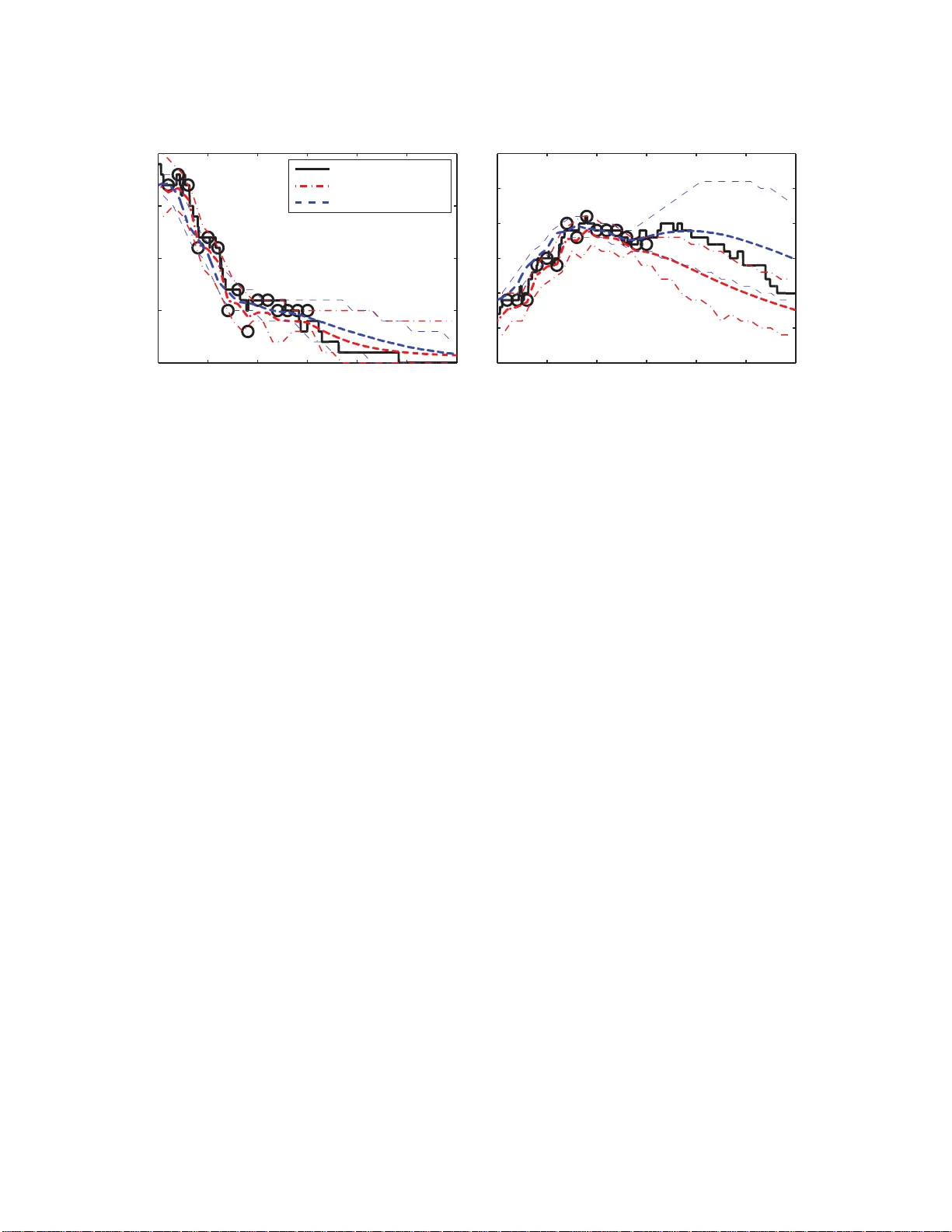
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment