Stratified Analysis of `Probabilities of Causation
This paper proposes new formulas for the probabilities of causation difined by Pearl (2000). Tian and Pearl (2000a, 2000b) showed how to bound the quantities of the probabilities of causation from experimental and observational data, under the minima…
Authors: Manabu Kuroki, Zhihong Cai
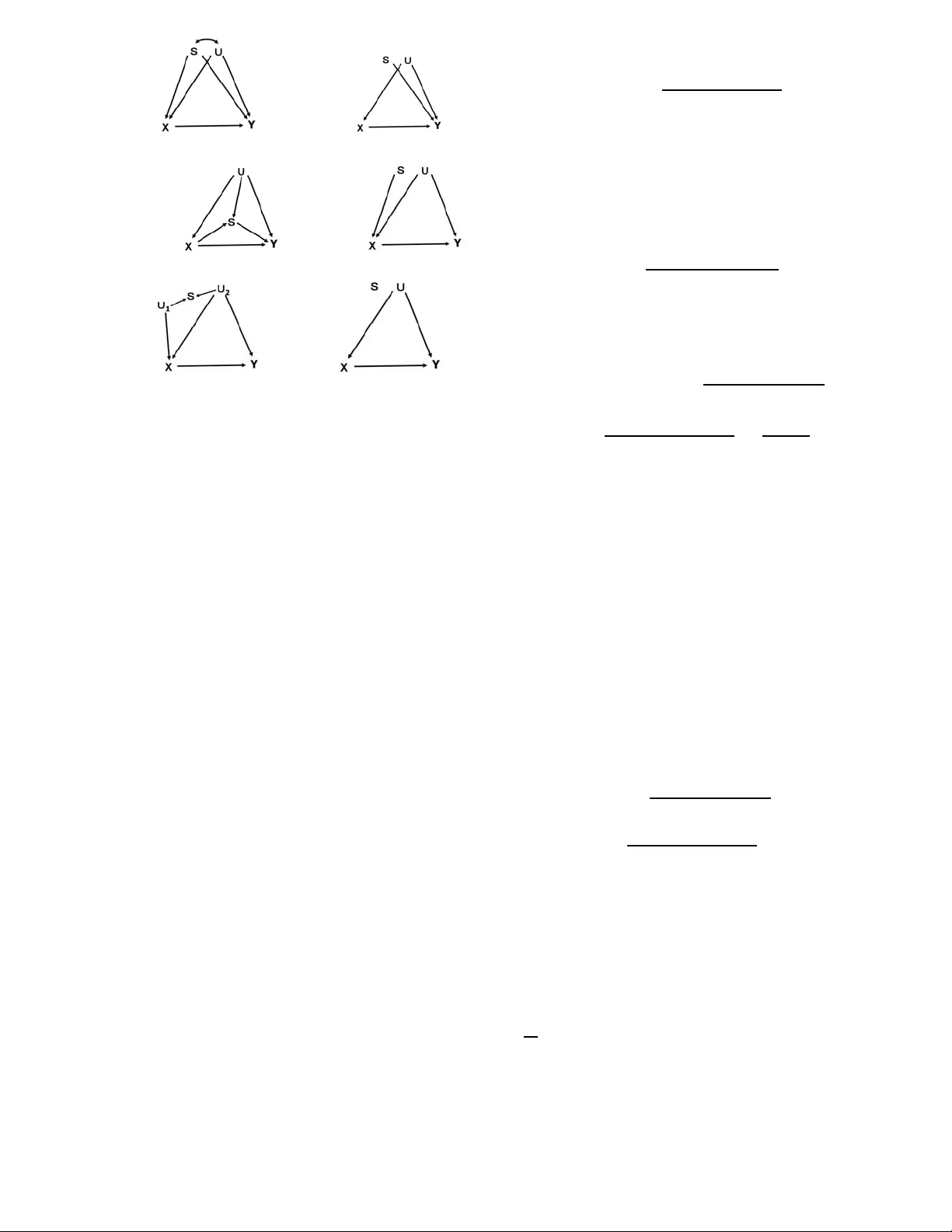
Stratified Analysis of ”Probabilities of Causation” Manabu Kuroki Systems Inno v ation Dept. Osak a Universit y T oy onak a, Osak a, Japan mkuroki@sigmath.es.osaka-u.ac.jp Zhihong Cai Biostatistics Dept. Kyoto Universit y Sakyo-ku, Kyoto, Japan cai@pbh.med.kyoto-u.ac.jp Abstract This paper derives new bounds for the prob- abilities of causation defined by P earl (2000), namely , the probability that one observed even t w as a necessary (or sufficient, or b oth) cause of another. Tian and P earl (2000a, 2000b) sho wed how to b ound these prob- abilities using information from exp erimen- tal and observ ational studies,with minimal assumptions about the data-generating pro- cess. W e deriv e narro wer b ounds using co- v ariates measuremen ts that migh t be a v ail- able in the studies. In addition, we pro- vide iden tifiable case under no-prev ention as- sumption and discuss the cov ariate selection problem from the viewpoint of estimation ac- curacy . These results provides more accurate information for public p olicy , legal determi- nation of resp onsibility and p ersonal decision making. 1 In tro duction It is an imp ortant issue to ev aluate the lik eliho od that one even t was the cause of another in practical sci- ence. F or example, epidemiologists are interested in the likelihoo d that a particular exposure is the cause of a particular disease. In order to assess this lik eliho o d from statistical data, the probabilities of causation hav e b een developed, whic h can be divided in to neces- sary causation, sufficient causation and necessary-and- sufficient causation. These probabilities of causation are used in epidemiology , legal reasoning, artificial in- telligence, policy analysis and psyc hology . Pearl (2000) and Tian and P earl (2000a, 2000b) devel- oped formal seman tics for probabilities of causation based on structural mo dels of counterfactuals. They presented the formal definitions for probability of ne- cessity ( PN ), probability of sufficiency ( PS ) and prob- ability of necessit y and sufficiency ( PNS ). In addi- tion, they showed how to bound these quan tities from data obtained in exp erimental and observational stud- ies. Their b ounds are sharp under the minimal as- sumptions concerning the data-generating pro cess. In this pap er, w e call their bounds Tian-Pearl bounds. When w e examine man y exp erimen tal and observ a- tional studies, we find that there is some extra infor- mation that w e can use in order to b ound the quan- tities of the probabilities of causation. F or example, in epidemiological studies, not only the exp osure and the outcome are measured, but also some cov ariates such as age, gender are measured. How ever, Tian- Pearl bounds do not pro vide formulas for making full use of these information. Therefore, the aim of this paper is to pro vide narro wer b ounds for probabilities of causation by using as muc h as information av ailable from experimental and observ ational studies. Our main idea is to use stratified analysis in order to obtain narro wer bounds. When we get the statistical data ab out the exp osure, outcome and some cov ari- ates, we first stratify the data according to the co- v ariates, then we calculate the bounds of probabilities of causation in each stratum, finally we derive sum- marized b ounds on the probabilities of causation. By making use of the co v ariate information, w e can pro- vide narrow er b ounds than Tian-Pearl bounds without making additional assumptions. This pap er is organized as follows. Section 2 giv es some preliminary knowledge that will b e used through- out the paper. In Section 3, w e introduce the proba- bilities of causation and giv e a new definition of con- ditional probabilities of causation. Then we prop ose the nonparametric b ounds for probabilities of causa- tion based on stratified analysis, and investigate some properties of the prop osed b ounds. In addition, w e provide identifiable cases under no-preven tion assump- tion and discuss the co v ariate selection problem from the viewp oin t of estimation accuracy . W e do simula- tion exp eriments to v erify our results in section 4. In section 5, we giv e an example to illustrate ho w the pro- posed formulas can narrow the bounds so as to pro vide more evidence for health care policy making. Finally , section 6 concludes this paper. 2 Preliminary In this section, we introduce the potential outcome v ariables that will b e used to define the probabilities of causation. W e consider the case where an exp osure v ariable and an outcome v ariable are dichotomous. W e denote X as an exposure v ariable ( x : true; x : false) and Y as an outcome v ariable ( y : true; y : false). In addition, let P( x, y ) b e a strictly p ositive join t prob- ability of ( X, Y )=( x, y ) and P( y | x ) the conditional probability of Y = y given X = x . Similar notations are used for other distributions. In principle, the i th of the N sub jects has b oth a po- tential outcome Y x ( i ) that hav e resulted if X had b een x , and a potential outcome Y x ( i ) that hav e resulted if X had b een x . Then Y x ( i ) − Y x ( i ) is called the unit-level causal effect (Rubin, 2005). When the N sub jects in the study are considered as a random sam- ple from some p opulation, since Y x ( i ) and Y x ( i ) can b e referred as the v alues of random v ariables Y x and Y x respectively , the av erage causal effect can b e defined as P( y x ) − P( y x ) , (1) where y x indicates the counterfactual sentence ”V ari- able Y would hav e the v alue y , had X b een x ”. Similar notations are used for other potential outcomes. The outcome Y x is observed only if X is x , and Y x is observed only if X is x . This prop erty is called the consistency (Robins, 1989), whic h is formulated as follows: ( X = x ) ⇒ ( Y x = Y ) . (2) Thus, when a randomized exp erimen t is conducted and compliance is perfect, the average causal effect is P( y x | x ) − P( y x | x )=P ( y | x ) − P( y | x ) , (3) which is equal to equation (1). On the other hand, when a randomized exp eriment is difficult to conduct and only observ ational data is av ailable, we can still estimate the av erage causal effect according to the strong-ignorable-treatment-assignmen t (SIT A) condi- tion (Rosenbaum and Rubin, 1983). That is, for the treatment v ariable X , if there exists such a set S of observed cov ariates that X is conditionally indepen- dent of ( Y x ,Y x ) giv en S , denoted as X || ( Y x ,Y x ) | S , we shall say treatment assignment is strongly ignor- able giv en S ,o r S satisfies the SIT A condition. Thus, equation (1) is estimable by using S E s { P( y | x, s ) − P( y | x ,s ) } . (4) 3 Nonparametric b ounds based on stratification 3.1 F ormulation The PN is defined as the expression PN =P r ( y x | x, y ) , (5) which stands for the probability that even t y would not hav e o ccurred in the absence of x , given that x and y did in fact o ccur. In this pap er, w e define a conditional PN given S = s as PN ( s ) = Pr( y x | x, y , s ) , which stands for the probability that even t y would not hav e o ccurred in the absence of x , given that x and y did in fact occur in stratum s . The PS is defined as the expression PS = P ( y x | x ,y ), which stands for the probability that even t y would hav e occurred in the presence of x , given that x and y did in fact o ccur. In addition, we define a condi- tional PS given S = s as PS ( s )= P ( y x | x ,y ,s ) which stands for the probability in stratum s that even t y would ha ve occurred in the presence of x , given that x and y did in fact o ccur in stratum s . In this pa- per, we do not discuss the PS since it has the same properties as the PN by changing ( x, y )t o ( x ,y ). The PNS is defined as the expression PN S = P ( y x ,y x ) , (6) which measures both the sufficiency and necessity of x to pro duce y . In this pap er, the conditional PN S given S = s is defined as PN S ( s )= P ( y x ,y x | s ) , which measures both the sufficiency and necessity of x to pro duce y in stratum s . When an exp erimental study or an observ ational study is conducted, it is the usual case that not only the ex- posure and the outcome v ariables are measured, but also some information on background factors and in- termediate factors are av ailable. Then, making full use of these av ailable information will give narrow er bounds on the PN and the PN S , which is the aim of this section. The bounds can b e obtained by apply- ing the linear programming technique (Tian and P earl, 2000a, 2000b) to conditional causal effects (Tian, 2004). In this pap er, w e provide a simple proof by using equation (2) and recursiv e factorizations of prob- abilities. Letting S b e a set of observ ed v ariables, when we strat- ify the sub jects according to the levels of S , we can de- rive new bounds on the PN and the PNS b y (i) calcu- lating the lo wer and upper b ounds of the conditional PN and the conditional PNS within each stratum, and (ii) summarizing the low er and upp er bounds in all the strata. First, regarding the PN , P( y x | s )= z ∈{ y, y } w ∈{ x,x } P( y x | w, z, s )P( w, z | s ) , (7) P( y x | x ,y ,s ) = 0 and P( y x | x ,y ,s ) = 1 hold true from equation (2). Thus, the b ounds of the conditional PN given S = s can be given as max ⎧ ⎨ ⎩ 0 P( y x | s ) − P( y | s ) P( x, y | s ) ⎫ ⎬ ⎭ ≤ PN ( s ) ≤ min ⎧ ⎨ ⎩ 1 P( y x | s ) − P( x ,y | s ) P( x, y | s ) ⎫ ⎬ ⎭ . Here, letting PN s be the PN when a v ariable S is used to ev aluate it, by noting PN s = s PN ( s )P( s | x, y ), we can derive the new b ounds based on stratification s max ⎧ ⎨ ⎩ 0 P( y x | s ) − P( y | s ) P( x, y ) ⎫ ⎬ ⎭ P( s ) ≤ PN s ≤ s min ⎧ ⎪ ⎨ ⎪ ⎩ P( x, y | s ) P( x, y ) P( y x | s ) − P( x ,y | s ) P( x, y ) ⎫ ⎪ ⎬ ⎪ ⎭ P( s ) . (8) Regarding the PN S , it is trivial that P ( y x ,y x | s ) ≤ min { P ( y x | s ) ,P ( y x | s ) } holds true. In addition, we can obtain P ( y x ,y x | s )= z ∈{ y, y } w ∈{ x,x } P ( y x ,y x | z, w, s ) P ( z, w | s ) , P ( y x ,y x | s )= P ( y x | s ) − P ( y x ,y x | s )= P ( y x | s ) − z ∈{ y, y } w ∈{ x,x } P ( y x ,y x | z, w, s ) P ( z, w | s ) , P ( y x ,y x | s )= P ( y x | s ) − P ( y x ,y x | s )= P ( y x | s ) − z ∈{ y, y } w ∈{ x,x } P ( y x ,y x | z, w, s ) P ( z, w | s ) , and P ( y x ,y x | s )= P ( y x | s ) − P ( y x | s )+ P ( y x ,y x | s ) = P ( y x | s ) − P ( y x | s ) + z ∈{ y,y } w ∈{ x,x } P ( y x ,y x | z, w, s ) P ( z, w | s ) . Thus, by using P( y x | x ,y ,s ) = 0 and P( y x | x ,y ,s )= 1, the b ounds of the conditional PNS given S = s can be giv en as max ⎧ ⎪ ⎪ ⎨ ⎪ ⎪ ⎩ 0 P ( y x | s ) − P ( y | s ) P ( y x | s ) − P ( y | s ) P ( y x | s ) − P ( y x | s ) ⎫ ⎪ ⎪ ⎬ ⎪ ⎪ ⎭ ≤ PN S ( s ) ≤ min ⎧ ⎪ ⎪ ⎨ ⎪ ⎪ ⎩ P ( y x | s ) P ( y x | s ) P ( x, y | s )+ P ( x ,y | s ) P ( y x | s ) − P ( y x | s )+ P ( x ,y | s )+ P ( x, y | s ) ⎫ ⎪ ⎪ ⎬ ⎪ ⎪ ⎭ . Thus, letting PN S s be the PNS when a v ari- able S is used to ev aluate it, b y noting PNS s = s PN S ( s )P( s ), w e can obtain s max ⎧ ⎪ ⎪ ⎨ ⎪ ⎪ ⎩ 0 P ( y x | s ) − P ( y | s ) P ( y x | s ) − P ( y | s ) P ( y x | s ) − P ( y x | s ) ⎫ ⎪ ⎪ ⎬ ⎪ ⎪ ⎭ P ( s ) ≤ PN S s ≤ s min ⎧ ⎪ ⎪ ⎨ ⎪ ⎪ ⎩ P ( y x | s ) P ( y x | s ) P ( x, y | s )+ P ( x ,y | s ) P ( y x | s ) − P ( y x | s )+ P ( x ,y | s )+ P ( x, y | s ) ⎫ ⎪ ⎪ ⎬ ⎪ ⎪ ⎭ × P ( s ) . (9) The prop osed b ounds (8) and (9) are narrow er than Tian-Pearl b ounds (Tian and Pearl, 2000a, 2000b). An intuitive explanation is that the proposed b ounds alwa ys select the maximal v alue in low er b ound and minimal v alue in upp er b ound within every stratum of S , while Tian-Pearl bounds always select a fixed one from all the probabilities across every stratum of S . In addition, it is obvious that the prop osed b ounds re- duce to the Tian-P earl bounds if there is no stratified analysis on S . 3.2 Prop ert y of the prop osed b ounds An interesting prop erty of the prop osed b ounds is that the observed v ariables S need not b e confounders be- tw een an exp osure v ariable X and an outcome v ariable Y . Fig.1 shows six cases that the observed v ariables S may b e. Here, U , U 1 and U 2 in Fig.1 indicate sets of unobserved v ariables. An arrow ( → ) indicates that a v ariable of its tail has an effect on another v ariable of its head, and a bidirected arc ( ↔ ) indicates that tw o v ariables connected by the arc hav e an asso cia- tion with each other. Fig.1 (a) shows that the v ari- ables S are confounders that ha ve an effect on both X and Y ; Fig.1 (b) sho ws that the v ariables S are prog- nostic factors that hav e an effect only on Y ; Fig.1 (c) shows that the v ariables S are intermediate v ariables that are affected by X and hav e an effect on Y ; Fig.1 (d) shows that the v ariables S are v ariables that satisfy the instrumental v ariable conditions (e.g. Bowden and T urkington, 1984; Greenland, 2000); Fig.1 (e) shows (a): Confounders (b): Prognostic F actors (c): Intermediate V ariable (d): Instrumental V ariable (e): M-structure (f ): No-asso ciation Fig.1. Six Cases of Observed V ariable S that the cov ariates S are in a M-structure (Greenland et al., 1999; Greenland, 2003); Fig.1 (f ) shows that the v ariables S are asso ciated with neither X nor Y . When data are av ailable from b oth an exp erimen tal study and an observational study , equations (8) and (9) are applicable to the former fiv e cases, that is, we can obtain narrow er bounds than Tian-Pearl b ounds under these cases. Hence, when we obtain information on observed v ariables, they ma y b elong to case (a), (b), (c), (d) or (e). Whichev er they b elong to, if w e stratify the p opulation according to the lev els of S , w e can obtain narro wer bounds on probabilities of causation. 3.3 Iden tification under the ”no-prev en tion” In the discussion ab ov e, w e prop osed narrow er b ounds on the probabilities of causation. When the mono- tonicity assumption ”P( y x ,y x ) = 0” is added, we can derive the p oin t estimators based on cov ariate adjust- ments. In epidemiology , this assumption is often ex- pressed as ”no-preven tion”, which means that no in- dividual in the population can be helped b y exp osure to a risk factor, that is, a hazardous exposure is either harmful or indifferent to every member of the popula- tion. The generalization of monotonicity assumption is of- fered through the use of the conditional monotonicit y assumption ”P( y x ,y x | s ) = 0”. This assumption im- plies that both P( y x | y x ,x ,s )= P ( y x | y, x ,s )= 0 and P( y x | y x ,x ,s )= P( y x | y ,x ,s )= 0 hold true. Then, from equation (7), by noting that P( y x | y ,x ,s )= 1 − P( y x | y ,x ,s ) = 1, w e can obtain PN ( s )= P( y x | s ) − P( y | s ) P( x, y | s ) . Thus, the PN can b e identified as PN s = s PN ( s )P( s ), whic h requires b oth observational data and exp erimental data. When only observ ational data is av ailable, if we can observe some co v ariates that satisfy the SIT A condition (Rosen baum and Ru- bin, 1983), we can still iden tify the PN : PN s = s P( y | x ,s ) − P( y | s ) P( x, y ) P( s ) . (10) The asymptotic v ariance of the PN is given b y a.v ar ( ˆ PN s ) = s (1 − PN s ) 2 P( y | x, s )P( y | x, s ) N P( x, s ) + P( y | x ,s )P( y | x ,s ) N P( x ,s ) P( x, s ) P( x, y ) 2 . (Cai and Kuroki, 2005). By the similar procedure, since we can obtain PNS ( s )= P ( y x | s ) − P( y x | s ), the PN S can b e identified as PNS s = s PN S ( s )P( s ), which requires observ ational data or experimental data. When only observ ational data is av ailable, if we can observe some co v ariates that satisfy the SIT A condition (Rosenbaum and Rubin, 1983), we can still identify PNS : PN S s = s (P( y | x, s ) − P( y | x ,s ))P( s ) , (11) which is consistent with the av erage causal effect pro- vided in equation (4). The asymptotic v ariance of the PN S is giv en by a.v ar ( ˆ PN S s ) = s P( y | x, s )P( y | x, s ) N P( x, s ) + P( y | x ,s )P( y | x ,s ) N P( x ,s ) P( s ) 2 . (Cai and Kuroki, 2005). Moreov er, when t wo different subsets S and T of the cov ariates satisfy the SIT A condition, the cov ariate se- lection problem occurs: whether it is b etter to use both of them than to use one of them in order to obtain a p oint estimator with smaller v ariance. Regarding this problem, we provide the following results: (1) if Y || T |{ X, S } holds true from data, we can obtain a.v ar ( ˆ PN s ) ≤ a.v ar ( ˆ PN s,t ) , and a.v ar ( ˆ PN S s ) ≤ a.v ar ( ˆ PN S s,t ); (2) if X || S | T holds true from data, we can obtain a.v ar ( ˆ PN s,t ) ≤ a.v ar ( ˆ PN t ) and a.v ar ( ˆ PN S s,t ) ≤ a.v ar ( ˆ PN S t ) . The pro of is pro vided in Appendix. W e can describ e such situations as the graph shown in Fig.2, which indicates that both X || S | T and Y || T |{ X, S } hold true. These conditional indep en- dence relationships can b e read off from the graph b y the d-separation criterion (Pearl, 2000). Since b oth Fig. 2: Graphical represen tation of cov ariate selection T and S satisfy the SIT A condition relativ e to ( X, Y ) and b oth Y || T |{ X, S } and X || S | T hold true, we can obtain a.v ar ( ˆ PN s ) ≤ a.v ar ( ˆ PN t,s ) ≤ a.v ar ( ˆ PN t ) and a.v ar ( ˆ PN S s ) ≤ a.v ar ( ˆ PN S t,s ) ≤ a.v ar ( ˆ PN S t ) . That is, the asymptotic v ariance when S is used is smaller than that when T is used under the conditions above. These results provide qualitative relationships between different co v ariates that satisfy the SIT A con- dition, whic h indicates that it is not alwa ys b etter to use as m uch as cov ariate information in order to esti- mate the probabilities of causation. 4 Sim ulation exp eriment W e compare the v ariances in section 3.3 through sim- ulation experiments. F or simplicity , we only consider the case in Fig. 2, where there are tw o observed di- chotomous co v ariates S and T . W e consider four sce- narios of the o dds ratios b etw een X and T and b et ween S and T , whic h is shown in T able 1. The v alue in each cell represen ts the probability P ( x, s, t ), which satisfies X || S | T . Setting 1 represents the case where b oth the odds ratios b et ween X and T and b etw een S and T are larger than 1. Setting 2 represents the case where the odds ratio b etw een X and T is larger than 1 but that between S and T is close to 1. Setting 3 represen ts the case where the o dds ratio betw een X and T is close to 1 but that b etw een S and T is larger than 1. Setting 4 represents the case where b oth the o dds ratios be- tw een X and T and b et ween S and T are close to 1. In addition, the setting of conditional probabilities of Y given X and S are fixed at (P( y | x, s 1 ), P( y | x, s 2 ), P( y | x ,s 1 ), P( y | x ,s 2 )) = (0 . 7 , 0 . 3 , 0 . 8 , 0 . 4). In order T able 1: F our Parameter Settings Setting 1 Setting 2 t 1 t 2 t 1 t 2 s 1 s 2 s 1 s 2 s 1 s 2 s 1 s 2 x 0.32 0.08 0.02 0.08 0.2 0.05 0.04 0.16 x 0.08 0.02 0.08 0.32 0.2 0.05 0.06 0.24 Setting 3 Setting 4 t 1 t 2 t 1 t 2 s 1 s 2 s 1 s 2 s 1 s 2 s 1 s 2 x 0.2 0.2 0.04 0.06 0.1 0.1 0.1 0.15 x 0.05 0.05 0.16 0.24 0.15 0.15 0.1 0.15 to verify the prop erties of the v ariances in Section 3.3, we did sim ulation experiments based on the four set- tings in sample sizes N = 500 , 1000 , 1500 and 2000, re- spectively . T able 2 rep orts the v ariance estimates from 5000 replications in v arious sample sizes. ” S ” means the v ariance when a cov ariate S is used to ev aluate the PN and the PNS ,” T ” means the v ariance when a co- v ariate T is used to ev aluate the PN and the PNS , and ” { S, T } ” means the v ariance when b oth S and T are used to ev aluate the PN and the PN S . The first line shows the v alue of v ariance obtained from sim- ulation exp eriments, denoted as va r , and the second line shows the v alue of asymptotic v ariances calculated from the form ulas in Section 3, denoted as a.v ar . F rom T able 2, we dra w the following conclusions. (1) The ratio of v ariance to asymptotic v ariance is close to 1.0, whic h sho ws that the asymptotic v ariances are sufficient appro ximations of the v ariances. (2) In all cases, the v ariance when S is selected is smaller than the v ariance when T or { S, T } is selected, which is consistent with the results in section 3.3. In addition, the v ariance when T is selected is larger than the v ariance when { S, T } is selected, which is also con- sistent with the results in section 3.3. (3) The v ariances v ary in eac h case, which ma y result from the differen t parameter settings. 5 Example The ab ov e results are applicable to analyze the data from the Northern Alb erta Breast Cancer Registry (Newman, 2001). This data, which is sho wn in T able 3, w as collected to inv estigate the effect of receptor level on breast cancer surviv al. It was also reanalyzed by Greenland (2004), with the purp ose of discussing the attributable fraction and risk ratios. The size of T able 2: Simulation Results on the V ariances PN Setting 1 Setting 2 S T { S, T } S T { S, T } N = 500 va r 0.0071 0.0122 0.0113 0.0081 0.0092 0.0082 a.v ar 0.0068 0.0120 0.0106 0.0078 0.0088 0.0078 N = 1000 va r 0.0035 0.0061 0.0054 0.0039 0.0044 0.0039 a.v ar 0.0034 0.0060 0.0053 0.0039 0.0044 0.0039 N = 1500 va r 0.0023 0.0040 0.0035 0.0026 0.0029 0.0026 a.v ar 0.0023 0.0040 0.0035 0.0026 0.0029 0.0026 N = 2000 va r 0.0017 0.0031 0.0027 0.0019 0.0022 0.0020 a.v ar 0.0017 0.0030 0.0026 0.0019 0.0022 0.0020 PN Setting 3 Setting 4 S T { S, T } S T { S, T } N = 500 va r 0.0087 0.0195 0.0168 0.0096 0.0114 0.0098 a.v ar 0.0083 0.0189 0.0158 0.0093 0.0111 0.0094 N = 1000 va r 0.0043 0.0095 0.0081 0.0048 0.0056 0.0049 a.v ar 0.0042 0.0094 0.0079 0.0046 0.0056 0.0047 N = 1500 va r 0.0028 0.0063 0.0053 0.0031 0.0037 0.0031 a.v ar 0.0028 0.0063 0.0053 0.0031 0.0037 0.0031 N = 2000 va r 0.0021 0.0048 0.0040 0.0023 0.0028 0.0024 a.v ar 0.0021 0.0047 0.0039 0.0023 0.0028 0.0023 PNS Setting 1 Setting 2 S T { S, T } S T { S, T } N = 500 va r 0.0019 0.0029 0.0026 0.0017 0.0019 0.0017 a.v ar 0.0018 0.0028 0.0025 0.0017 0.0019 0.0017 N = 1000 va r 0.0009 0.0014 0.0012 0.0008 0.0009 0.0008 a.v ar 0.0009 0.0014 0.0012 0.0008 0.0009 0.0008 N = 1500 va r 0.0006 0.0009 0.0008 0.0006 0.0006 0.0006 a.v ar 0.0006 0.0009 0.0008 0.0006 0.0006 0.0006 N = 2000 va r 0.0005 0.0007 0.0006 0.0004 0.0005 0.0004 a.v ar 0.0005 0.0007 0.0006 0.0004 0.0005 0.0004 PNS Setting 3 Setting 4 S T { S, T } S T { S, T } N = 500 va r 0.0017 0.0031 0.0027 0.0017 0.0020 0.0017 a.v ar 0.0017 0.0031 0.0026 0.0017 0.0020 0.0017 N = 1000 va r 0.0008 0.0015 0.0013 0.0009 0.0010 0.0009 a.v ar 0.0008 0.0015 0.0013 0.0008 0.0010 0.0008 N = 1500 va r 0.0006 0.0010 0.0009 0.0006 0.0007 0.0006 a.v ar 0.0006 0.0010 0.0009 0.0006 0.0007 0.0006 N = 2000 va r 0.0004 0.0008 0.0007 0.0004 0.0005 0.0004 a.v ar 0.0004 0.0008 0.0006 0.0004 0.0005 0.0004 the sample is 192 and the v ariables of interest are the following: X : Receptor Level ( x : high; x : low). Y : Surviv al Indicator ( y : death; y : survive). S : Stage at Diagnosis ( s 1 : stage 1; s 2 : stage 2; s 3 : stage 3). T able 3: Receptor Level-Breast Cancer Study (Newman, 2001) s 1 s 2 s 3 x x x x x x y 2 5 9 17 12 9 y 10 50 13 57 2 6 In this example, we assume that S satisfies the SIT A condition. Since only observ ational data is av ailable, the prop osed b ounds of equation (8) and (9) can b e written as s max ⎧ ⎨ ⎩ 0 P ( y | x ,s ) − P ( y | s ) P ( x, y ) ⎫ ⎬ ⎭ P ( s ) ≤ PN s ≤ s min ⎧ ⎪ ⎨ ⎪ ⎩ P ( x, y | s ) P ( x, y ) P ( y | x ,s ) − P ( x ,y | s ) P ( x, y ) ⎫ ⎪ ⎬ ⎪ ⎭ P ( s ) and s max 0 P ( y | x, s ) − P ( y | x ,s ) P ( s ) ≤ PN S s ≤ s min P ( y | x, s ) P ( y | x ,s ) P ( s ) . Regarding the lo wer bounds of the PN and the PN S , the conditional risk differences take the same signs in all the strata (stage 1: − 0 . 076; stage 2: − 0 . 179; stage 3: − 0 . 257), whic h indicates that the prop osed low er bound is equal to Tian-P earl low er b ound. On the other hand, regarding the upper bounds of the PN and the PN S , in stage 1 and stage 2, the signs of P( y | x, s ) − P( y | x ,s ) are the same (stage 1: − 0 . 742; stage 2: − 0 . 361), but are different from that in stage 3 (stage 3: 0.457), which indicates that the proposed upper b ound is smaller than Tian-Pearl upp er bound. By calculation, the prop osed bounds of the PN is (0 . 000 , 0 . 778), and Tian-P earl bounds is (0 . 000 , 1 . 000), which shows that the proposed b ounds can provide more information for judging probabilit y of causa- tion. In addition, the prop osed b ounds of the PN S is (0 . 000 , 0 . 168), which is also narrow er than Tian-P earl bounds (0 . 000 , 0 . 237). 6 Conclusion Probabilities of causation are widely used in epidemi- ology , artificial in telligence and public policy analysis. Therefore, b ounding and iden tifying the probabilities of causation is an imp ortan t problem. In many ex- perimental and observ ational studies, usually not only the exposure and outcome v ariables are measured, but also some co v ariates and in termediate v ariables are measured. This information enables us to narrow the bounds of the probabilities of causation. In this pap er, we defined conditional probabilities of causation, and used this definition to propose narrow er bounds than Tian-Pearl b ounds by stratifying on some measured cov ariates and intermediate v ariables. W e also con- sider the iden tification of the probabilities of causation based on stratified analysis. Since co v ariate selection problems occur in this situation, we further compared different cases of co v ariate selection from the viewp oint of estimation accuracy . Finally , we gav e simulation re- sults and analyzed an empirical data by using our for- mulas. With these new results added to the framework of Tian and P earl (2000a, 2000b), the probabilities of causation should find wider use in more and more ar- eas that require the ev aluation of causal effects. App endix Regarding the PN , when Y || T |{ X, S } holds true, we can obtain P( y | x, s )P( y | x, s ) P( x, s ) P( x, s ) 2 − t P( y | x, s, t )P( y | x, s, t ) P( x, s, t ) P( x, s, t ) 2 =0 . In addition, since we can obtain P( x | s ) t P( x | t, s ) 2 P( t | s ) P( x | t, s ) = t P( x | t, s )P( t | s ) t P( x | t, s ) 2 P( t | s ) P( x | t, s ) ≥ P( x | s ) 2 by the Cauch y-Sch warz Inequalit y , P( y | x ,s )P( y | x ,s ) P( x ,s ) P( x, s ) 2 − t P( y | x ,s ,t )P( y | x ,s ,t ) P( x ,s ,t ) P( x, s, t ) 2 =P ( y | x ,s )P( y | x ,s )P( s ) × P( x | s ) 2 P( x | s ) − t P( x | t, s ) 2 P( t | s ) P( x | t, s ) ≤ 0 . Thus, by noting that PN s = PN s,t holds true, we can obtain a.v ar ( ˆ PN s ) ≤ a.v ar ( ˆ PN s,t ). Next, when X || S | T holds true, by the v ariance basic formula, w e can obtain P( y | x, t )P( y | x, t ) P( x, t ) P( x, t ) 2 − s P( y | x, s, t )P( y | x, s, t ) P( x, s, t ) P( x, s, t ) 2 ≥ s P( y | x, s, t )P( y | x, s, t ) P( x, s, t ) (P( x, t )P( x, s, t ) − P( x, s, t ) 2 ) ≥ 0 and P( y | x ,t )P( y | x ,t ) P( x ,t ) P( x, t ) 2 − s P( y | x ,s ,t )P( y | x ,s ,t ) P( x ,s ,t ) P( x, s, t ) 2 ≥ s P( y | x ,s ,t )P( y | x ,s ,t ) P( x ,s ,t ) (P( x, t )P( x, s, t ) − P( x, s, t ) 2 ≥ 0 . Thus, by noting that PN t = PN s,t holds true, w e can obtain a.v ar ( ˆ PN s,t ) ≤ a.v ar ( ˆ PN t ). Regarding the PN S , when Y || T |{ X, S } holds true, we can obtain a.v ar ( ˆ PN S t,s ) − a.v ar ( ˆ PN S s ) = x s P( y | x, s )P( y | x, s ) N P( s ) P( x | s ) × P( x | s ) t P( t | s ) P( x | t, s ) − 1 . Here, b y the Cauch y-Sch warz Inequality , P( x | s ) t P( t | s ) P( x | t, s ) = t P( x | t, s )P( t | s ) t P( t | s ) P( x | t, s ) ≥ 1 . Thus, we can obtain a.v ar ( ˆ PN S s ) ≤ a.v ar ( ˆ PN S t,s ). When X || S | T holds true, by comparing a.v ar ( ˆ PN S t ) with a.v ar ( ˆ PN S t,s ), we can obtain a.v ar ( ˆ PN S t ) − a.v ar ( ˆ PN S t,s ) = x t P( t ) N P( x | t ) P( y | x, t )P( y | x, t ) − s P( y | x, s, t )P( y | x, s, t )P( s | t ) . By using the v ariance basic form ula, we can obtain a.v ar ( ˆ PN S s,t ) ≤ a.v ar ( ˆ PN S t ). Ac knowledgemen ts The authors w ould like to thank Judea Pearl of UCLA for his helpful discussion ab out the pap er. This re- search was supp orted by the Ministry of Education, Culture, Sp orts, Science and T echnology of Japan, the Sumitomo F oundation, the Murata Ov erseas Sc holar- ship F oundation, the Kay amori F oundation of Infor- mation Science Adv ancement, the College W omen’s Association of Japan and the Japan So ciet y for the Promotion of Science. REFERENCES Bowden, R. J. , and T urkington, D. A. (1984). Instru- mental V ariables , Cambridge Univ ersity Press. Cai, Z. and Kuroki, M. (2005). V ariance Estimators for three Probabilities of Causation , Risk Analysis , 25 , 1611-1620. Greenland, S. (1987). V ariance estimators for at- tributable fraction estimates consistent in b oth large strata and sparse data. Statistics in Medicine , 6 , 701- 708. Greenland, S. (2000). An introduction to instrumental v ariables for epidemiologists. International Journal of Epidemiolo gy , 29 : 722-729. Greenland, S. (2003). Quantifying biases in causal mo dels: Classical confounding versus collider- stratification bias. Epidemiolo gy , 14 , 300-306. Greenland, S. (2004). Model-based Estimation of Relative Risks and Other Epidemiologic Measures in Studies of Common Outcomes and in Case-Con trol Studies. Americ an Journal of Epidemiolo gy , 160 , 301- 305. Greenland S., Pearl J. and Robins J. M. (1999). Causal diagrams for epidemiologic research. Epidemi- olo gy , 10 , 37-48. Newman, S. C. (2001). Biostatistic al metho ds in epi- demiolo gy , Wiley . Pearl, J. (2000). Causality: Mo dels, R e asoning, and Infer enc e , Cambridge Univ ersity Press. Robins, J. M. (1989). The analysis of randomized and non-randomized AIDS treatment trials using a new approach to causal inference in longitudinal stud- ies. He alth Servic e R esear ch Metho dolo gy: A F o cus on AIDS . Eds: Sechrest L., F reeman H., Mulley A. W ashington, D.C.: U.S. Public Health Service, Na- tional Cen ter for Health Services Research., 113-159. Robins, J. M. and Greenland, S. (1989). The probabil- ity of causation under a sto c hastic model for individual risk. Biometrics , 45 , 1125-1138. Rosenbaum, P . and Rubin, D. (1983). The central role of prop ensity score in observ ational studies for causal effects. Biometrika , 70 , 41-55. Rubin, D. B. (2005). Causal Inference Using Poten tial Outcomes: Design, Mo deling, Decisions. Journal of the A meric an Statistic al Association , 100 , 322-331. Tian, J. and Pearl, J. (2000a). Probabilities of causa- tion: Bounds and identification. Annals of Mathemat- ics and Artificial Intel ligenc e , 28 , 287-313. Tian, J. and P earl, J. (2000b). Probabilities of causa- tion: Bounds and identification. P rocee dings of 16th Confer enc e on Unc ertainty in A rtificial Intel ligenc e , 589-598. Tian, J. (2004). Identifying conditional causal Effects. P rocee ding of 20th Confer enc e on Unc ertainty in Ar- tificial Intel ligenc e , 561-568.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment