Imitation Learning with a Value-Based Prior
The goal of imitation learning is for an apprentice to learn how to behave in a stochastic environment by observing a mentor demonstrating the correct behavior. Accurate prior knowledge about the correct behavior can reduce the need for demonstration…
Authors: Umar Syed, Robert E. Schapire
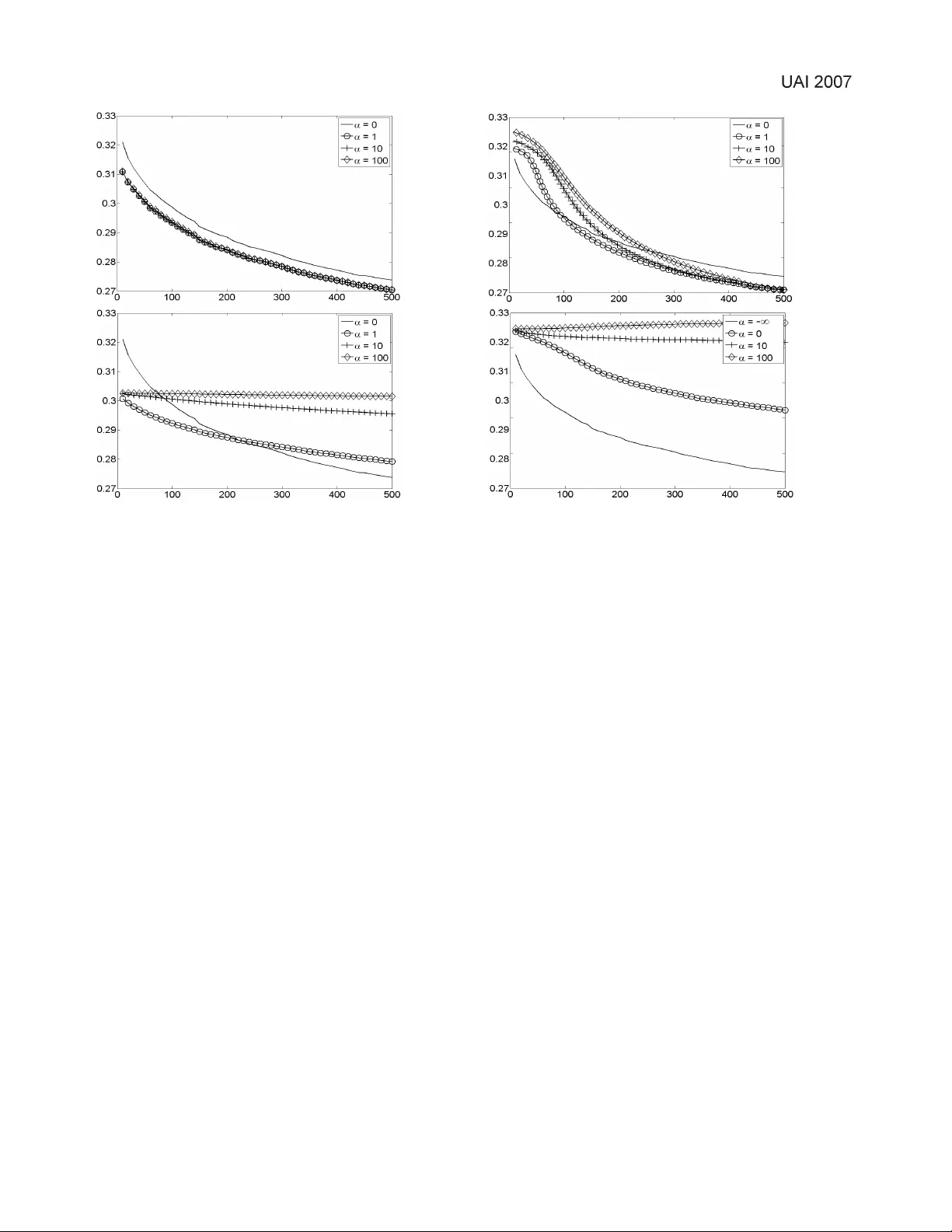
Imitation Learning with a V alue-Based Prior Umar Syed Computer Science Department Princeton Univ ersity 35 Olden St. Princeton, NJ 08540-5233 usyed@cs.princeton.edu Robert E. Schapire Computer Science Department Princeton Univ ersity 35 Olden St. Princeton, NJ 08540-5233 schapire@cs.princeton.edu Abstract The goal of imitation learning is for an appren- tice to learn ho w to behave in a stochastic en- vironment by observing a mentor demonstrating the correct behavior . Accurate prior knowledge about the correct beha vior can reduce the need for demonstrations from the mentor . W e present a novel approach to encoding prior knowledge about the correct behavior , where we assume that this prior knowledge takes the form of a Markov Decision Process (MDP) that is used by the apprentice as a rough and imperfect model of the mentor’ s beha vior . Specifically , taking a Bayesian approach, we treat the value of a policy in this modeling MDP as the log prior probability of the polic y . In other words, we assume a priori that the mentor’ s behavior is likely to be a high- value policy in the modeling MDP , though quite possibly different from the optimal policy . W e describe an efficient algorithm that, giv en a mod- eling MDP and a set of demonstrations by a men- tor , prov ably conv erges to a stationary point of the log posterior of the mentor’ s policy , where the posterior is computed with respect to the “value- based” prior . W e also present empirical e vidence that this prior does in fact speed learning of the mentor’ s policy , and is an improvement in our ex- periments ov er similar previous methods. 1 Introduction Imitation learning and reinforcement learning can be viewed as two approaches to solving the same problem: learning how to behave in a stochastic environment. In each, the goal is to learn the best policy , i.e., a function mapping each of the en vironment’ s possible states to a dis- tribution ov er actions that can be taken in that state. The two approaches dif fer in how they define the “best” pol- icy , and in what they assume is av ailable to a learning al- gorithm. In imitation learning, one assumes an apprentice has access to a set of examples (trajectories of state-action pairs) from a mentor’ s policy , which is also defined to be the best polic y . Imitation learning can therefore be suc- cinctly described as “supervised learning of behavior”. In reinforcement learning, one instead assumes the existence of a r ewar d function , i.e., a mapping from each of the en vi- ronment’ s states to a numerical re ward. The best policy is defined to be the one that maximizes expected cumulativ e (and possibly discounted) rew ard. Each of these approaches has its drawbacks. In imitation learning, as in any supervised learning problem, data from the mentor will typically be limited, particularly if the state space is large. In such cases, incorporating prior knowledge about the best policy (sometimes called r egularization ) can effecti vely compensate for a lack of data. Reinforcement learning suffers from a more subtle (and usually unmentioned) disadvantage: it requires a way to ac- cess the true rew ard function. In principle, the re ward func- tion is provided by “nature”, and is specified as part of the problem description. One either assumes that the rewards are av ailable to the learning algorithm in explicit functional form, or assumes that they can be estimated from experi- ence. In practice, ho we ver , rewards are usually specified by hand, and often need to be tweaked and tuned to elicit the desired beha vior . Whenev er this happens, it is mislead- ing to treat the rew ard function as necessarily correct. In this paper, we take a middle approach based on a value- based prior . W e define the best policy to be the men- tor’ s policy , and we use a modeling MDP to encode the apprentice’ s prior belief about the mentor’ s policy . W e as- sume that the prior probability of any policy being th e men- tor’ s increases with the v alue of that policy in the modeling MDP . In this way , instead of relying solely on rew ards or soley on evidence, the apprentice smoothly integrates both prior knowledge and observed information about the best policy . For examples of when this may be a good idea, consider the problem of dialog management , the motiv ating appli- cation for our work. A dialog manager is a program that controls the actions of an automated telephone agent, such as the kind one encounters when calling a company’ s cus- tomer service number . Instead of asking the caller to nav- igate menus by pressing b uttons, these agents encourage customers to speak freely , and attempt to of fer an experi- ence comparable to that of speaking to a liv e operator . The dialog manager makes decisions about which questions to SYED & SCHAPIRE 384 ask, ho w to deal with unexpected responses, what to do when the customer is misunderstood (ask them to clarify? make a best guess and mo ve on?), and when to giv e up and transfer the customer to an actual person. There has been success in training dialog managers from data using reinforcement learning [6, 10]. Howe ver , this approach requires the assertion of a re ward function that is based largely on intuition, since customers rarely giv e a clear indication about whether they are satisfied with a di- alog. Indeed, W alker et al [12] ha ve shown that ev aluating the performance of a dialog manager is itself a challeng- ing task, which calls into question whether reinforcement learning is sufficient to solve this problem, and suggests that some form of imitation may be needed. Another challenge is the scarcity of suitable training oppor- tunities. Observe that new dialog management strate gies cannot be tested on a static corpus. They have to be tried in real dialogs with actual users, which is, needless to say , an expensi ve proposition. As a result, there has been much interest in b uilding user models, i.e., simulators that mimic the behavior of customers. Schatzman et al [9] provide a surve y and comparison of some attempts at learning user models from data. A common theme in recent w ork has been to lev erage prior know ledge, and restrict the space of models to those that encode realistic user behavior , in the hope that less data will be needed for training. The work in this paper has been developed with these is- sues in mind. At the same time, the framework and algo- rithms presented here are intended to be completely gen- eral, and not specific to dialog management. W e assume that an apprentice is observing a mentor acting in a stochas- tic environment, and that the apprentice wants to estimate a model of the mentor’ s behavior . W e furthur assume that the mentor is behaving in a roughly re ward-seeking man- ner . The apprentice uses the value function of a modeling MDP to help guide its estimate to wards the correct policy . For e xample, in the domain of dialog management, we can assign higher re wards in the modeling MDP to states that are closer to the end of the con versation. In this way , we can leverage our knowledge that customers and operators are both trying to complete their con versations as soon as possible, without needing to specify exactly how they are trying to accomplish that goal. The paper proceeds as follows. After revie wing related work, we propose a formal definition of a prior distrib u- tion for the mentor’ s policy based on the value function of the modeling MDP . W e next giv e our main theoretical con- tribution of this paper, which is an efficient algorithm for finding a stationary point of the log posterior distribution that is computed with respect to our nov el prior . Finally we present experimental evidence, which we use to compare to previous methods, indicating that a value-based prior does speed the estimation of the mentor’ s policy . 2 Related W ork A number of authors have suggested methods to incorpo- rate prior knowledge of the mentor’ s behavior into imita- tion learning. Price et al [7] described an approach based on the Dirichlet distribution. Henderson et al [4] dev el- oped a modified temporal difference learning algorithm in which the usual Q v alues are adjusted so that the resulting optimal policy is forced to more closely match the mentor’ s behavior . V ery recently , Fern et al [3] proposed a similar yet simpler method that uses a Boltzmann distribution to assign greater prior probability to mentor actions that hav e higher Q values. In Section 5, we will empirically com- pare the methods of Price et al and Henderson et al to our algorithm. T wo recent papers by Abbeel et al [1] and Ratliff et al [8] hav e used in verse r einfor cement learning (IRL) as a way to extract information from a mentor’ s demonstrations. In IRL, we are giv en a policy , or demonstrations from a pol- icy , and the goal is find a rew ard function for which that policy is (near) optimal. Ratliff et al introduced a variant that fa vors those rew ard functions for which the optimal policy is similar to the observed policy , making their algo- rithm a type of imitation learning. Both papers assumed that the true reward function can be expressed as a linear combination of a set of known features, and le verage this assumption. Our work, by contrast, allows for arbitrary re- wards, which we assume are given, but uses those rew ards only to bias the inference of the mentor’ s policy . 3 Problem F ormulation W e assume that the apprentice is giv en a finite-horizon MDP , which we call the modeling MDP , consisting of a finite set of states S , a finite set of actions A , a horizon H , and a rew ard function R : S → R . W e chose a finite horizon because our applications of interest are all episodic tasks. W e also assume that we know the initial state distribution 1 p 0 = p 0 s s and the transition probabili- ties θ = ( θ t sas 0 ) tsas 0 , where θ t sas 0 is the probability that the en vironment transitions from state s to state s 0 under action a at time t (this assumption can be relaxed; see Section 4.1). It is important to note that it is not the apprentice’ s objec- tiv e to compute an optimal policy for the modeling MDP . Rather , the goal is to estimate the mentor’ s policy , and the modeling MDP is used to encode the apprentice’ s prior be- liefs about that policy . W e further assume that we are given a data set D of state- action trajectories of the mentor acting in this en vironment. Concretely , D = { x i } m i =1 , where x i is a sequence of H state-action pairs; i.e., x i = ( s i 0 , a i 0 ) , . . . ( s i H , a i H ) . Our objectiv e is to estimate the policy π = ( π t sa ) tsa that gov- erns the mentor’ s beha vior , where π t sa is the probability the mentor takes action a in state s at time t . The MAP esti- mate for the mentor’ s policy is giv en by ˆ π = arg max π log P ( D | π ) + log P ( π ) = arg max π X s,a,t K sat log π t sa + log P ( π ) , 1 The notation x = ( x ij ) ij denotes a vector x whose compo- nents are index ed by i and j . SYED & SCHAPIRE 385 where K sat is the number of times in D that action a is taken in state s at time t . If the prior distribution P ( π ) is uniform, then ˆ π can be calculated analytically; the solution is just ˆ π t sa = K sat P a K sat . In this paper , we show how to assert a prior distribution P ( π ) that gi ves greater weight to policies that ha ve greater value in the MDP . Define the value of π to be V ( π ) = E " H X t =0 R ( s t ) π , θ , s 0 ∼ p 0 # . If we let P ( π ) = exp( αV ( π )) , then the MAP estimate is now gi ven by ˆ π = arg max π X s,a,t K sat log π t sa + αV ( π ) (1) , arg max π L ( π ) . Here, α can be vie wed as a trade-of f parameter that de- termines how much relativ e weight P ( π ) assigns to high- value policies. Also note that P ( π ) in this case is an unnor- malized prior , as it does not necessarily intergrate to 1, and so (1) is perhaps more appropriately termed the estimate which maximizes a penalized likelihood . In Section 4 we show how to ef ficiently find a ˆ π that is prov ably a stationary point of L ( π ) . 4 Algorithm and Analysis In this section, we present an outline of an iterati ve algo- rithm that con ver ges to a stationary point L ( π ) , the func- tion in Equation (1). In Section 4.2 we provide a detailed description of each iteration of the algorithm, and in Sec- tion 4.3 we sketch a proof of its con vergence. The trouble with finding the maximum of L ( π ) directly is that the expression for V ( π ) , when e xpanded nai vely , contains N H terms. W e can e xpress V ( π ) more compactly by using Bellman’ s equations, which yields the following optimization problem: max π , V X s,a,t K sat log π t sa + α X s p 0 s V 0 s subject to: ∀ s, ∀ t < H V t s = R ( s ) + γ X a,s 0 π t sa θ t sas 0 V t +1 s 0 (2) ∀ s V H s = R ( s ) ∀ s, t X a π t sa = 1 ∀ s, a, t π t sa ≥ 0 where V = ( V t s ) ts and V t s is the value of the policy in state s at time t . This problem is still difficult, howe ver , since it in volv es noncon ve x constraints — note that Bell- man’ s equations (2) are bilinear in π and V . T o circum- vent this, we will perform an alternating maximization in- stead. Let π τ = ( π τ sa ) sa and V τ = ( V τ s ) s . In other words, π = π 0 , . . . , π H and V = V 0 , . . . , V H . W e will maximize L ( π ) over just π 0 , then π 1 , and so on until π H , and then repeat the cycle until con ver gence (see Algorithm 1). In the iteration for π τ , the values for π 0 , . . . , π τ − 1 , π τ +1 , . . . , π H are carried ov er from previ- ous iterations and are held fixed while π τ is optimized. T aking this alternating approach has the effect of lineariz- ing the constraints in (2), since V τ +1 , V τ +2 , . . . , V H are not affected by changes to π τ , and therefore can also be held fixed without impacting the maximization o ver π τ . Due to the linearization of the constraints in (2), each iteration of Algorithm 1 is just a con vex optimization problem, and hence can be solved by any of a num- ber of standard techniques, such as interior point meth- ods. Howe ver , general-purpose methods are quite com- plex; fortunately they turn out to be unnecessary in this case. In Section 4.2, we describe a relatively simple pro- cedure that solves this particular optimization problem in O ( |S | 2 |A| H + |S ||A| (log |A| + log |D | )) time. Algorithm 1 Find a stationary point of the log posterior . Let π τ = ( π τ sa ) sa and π = π 0 , . . . , π H . Let L ( π ) = P s,a,t K sat log π t sa + αV ( π ) . Initialize ˜ π at random. τ ← 0 . repeat π ← ˜ π ˜ π τ = arg max π τ L ( π ) ˜ π = π 0 , . . . , π τ − 1 , ˜ π τ , π τ +1 , . . . , π H if τ = H then τ ← 0 else τ ← τ + 1 end if until | L ( ˜ π ) − L ( π ) | is as small as desired 4.1 When transition probabilities ar e unknown So far , we ha ve assumed that the transition probabilities θ of the modeling MDP are given. Remo ving this assumption presents no special dif ficulty , since it is possible for our al- gorithm to jointly estimate θ and π within the framew ork already presented. The idea will be to define ne w state and action spaces ˜ S and ˜ A , and a new set of transition proba- bilities ˜ θ , in such a way that each parameter in the new set of unknowns ˜ π corresponds either to a parameter in π or a parameter in θ . Essentially , we fold the transition proba- bilities into the policy , and then replace them with a set of “dummy” transition probabilities. This reduction allows us to assume without loss of generality in our algorithm that θ is known, and that ev erything unkno wn about the MDP is embodied in the policy π . Concretely , let ˜ S = S ∪ ( S × A ) and ˜ A = A ∪ S . W e SYED & SCHAPIRE 386 define ˜ θ as ˜ θ t ˜ s ˜ a ˜ s 0 = 1 if ˜ s ∈ S , ˜ a ∈ A , and ˜ s 0 = ( ˜ s, ˜ a ); or if ˜ s ∈ ( S × A ) , ˜ a ∈ S , and ˜ s 0 = ˜ a 0 otherwise. Put differently , when we are in state ˜ s = s and take ac- tion ˜ a = a , the en vironment deterministically transitions to “state” ˜ s 0 = ( s, a ) . And when we are in “state” ˜ s = ( s, a ) and take “action” ˜ a = s 0 , the environment deterministically transitions to state ˜ s 0 = s 0 . One last modification is needed: we define a new state ˜ s ∗ , with R ( ˜ s ∗ ) = −∞ , and set ˜ θ t ˜ s ˜ a ˜ s ∗ = 1 whenev er ˜ s and ˜ a do not make sense together , i.e., when ˜ s ∈ S and ˜ a ∈ S , or when ˜ s ∈ ( S × A ) and ˜ a ∈ A . This will force ˜ π t ˜ s ˜ a = 0 in these cases. So we hav e the follo wing equivalences between the old and new parameters: ˜ π t ˜ s ˜ a ⇔ π t sa if ˜ s = s and ˜ a = a ˜ π t ˜ s ˜ a ⇔ θ t sas 0 if ˜ s = ( s, a ) and ˜ a = s 0 Note that, when applying this reduction, the prior P ( ˜ π ) = P ( π , θ ) assigns greater weight to policies and transition probabilities that jointly hav e high value. 4.2 Optimization procedur e Recall that V τ = ( V τ s ) s , π τ = ( π τ sa ) sa , and π = π 0 , . . . , π H . In each iteration of Algorithm 1, we max- imize L ( π ) over π τ , for some τ ∈ { 0 , . . . , H } . When τ 6 = H , the corresponding con vex optimization (after drop- ping constant terms) is 2 max π τ , V 0 ,..., V τ X s,a K saτ log π τ sa + α X s p 0 s V 0 s subject to: ∀ s, ∀ t ≤ τ V t s = R ( s ) + γ X a,s 0 π t sa θ t sas 0 V t +1 s 0 ∀ s X a π τ sa = 1 ∀ s, a π τ sa ≥ 0 . Recall that π 0 , . . . , π τ − 1 , π τ +1 , . . . , π H and V τ +1 , . . . , V H are constants in this problem; their values are carried o ver from pre vious iterations. T o solve the optimization, we need to find a solution to the KKT conditions , i.e., a solution π τ , V 0 , . . . , V τ , λ that is both feasible and also satifies ∇L π τ , V 0 , . . . , V τ , λ = 0 ∀ s, a λ π sa ≥ 0 ∀ s, a λ π sa · π τ sa = 0 2 The solution for the τ = H case is similar to the procedure described in this section, except it is ev en simpler , so we omit its discussion. where λ = { λ V st , λ π s , λ π sa | s ∈ S , a ∈ A , t ≤ τ } , the Lagrangian L π τ , V 0 , . . . , V τ , λ is giv en by L π τ , V 0 , . . . , V τ , λ = X s,a K saτ log π τ sa + α X s p 0 s V 0 s + X s t ≤ τ λ V st R s + γ X a,s 0 π t sa θ t sas 0 V t +1 s 0 − V t s + X s λ π s " 1 − X a π τ sa # + X s,a λ π sa · π τ sa and the gradient of L is taken with respect to π τ , V 0 , . . . , V τ . Below we outline a three-step procedure for finding π τ , V 0 , . . . , V τ , λ that satisfies the KKT conditions. 4.2.1 Step 1: Find the λ V st ’ s From the KKT conditions, we must hav e that ∂ L ∂ V t s = 0 ∀ s, ∀ t ≤ τ . This yields λ V s 0 = αp 0 s λ V st = γ X s 0 ,a λ V s 0 t − 1 π t − 1 s 0 a θ t s 0 as for 0 < t ≤ τ which allows us to inducti vely compute all the λ V st ’ s. W e can see from this expression that λ V st = αγ t Pr[ s t = s | π ] , i.e., λ V st is equal to the occupancy probability of state s at time t under policy π , but scaled by αγ t . 4.2.2 Step 2: Find the λ π s ’ s, λ π sa ’ s and π τ sa ’ s T o simplify notation, define B saτ , γ λ V sτ X s 0 θ τ sas 0 V τ +1 s 0 A 0 s , { a ∈ A | K saτ = 0 } A ¬ 0 s , A \ A 0 s . Let us focus on a particular state s . W e kno w that P a π τ sa = 0 and π τ sa ≥ 0 for all a . Suppose we can find a value of λ π s such that X a ∈A ¬ 0 s K saτ λ π s − B saτ = 1 (3) K saτ λ π s − B saτ ≥ 0 ∀ a ∈ A ¬ 0 s . (4) SYED & SCHAPIRE 387 If it happens that λ π s ≥ max a ∈A B saτ , then we can satisfy all the relev ant KKT conditions by setting λ π sa = 0 ∀ a ∈ A ¬ 0 s λ π sa = λ π s − B saτ ∀ a ∈ A 0 s π τ sa = K saτ λ π s − B saτ ∀ a ∈ A ¬ 0 s π τ sa = 0 ∀ a ∈ A 0 s . On the other hand, if λ π s < max a ∈A B saτ for the value of λ π s that solves (3) and (4), then we can satisfy the relev ant KKT conditions by first letting λ π s = max a ∈A B saτ , and then setting λ π sa = 0 ∀ a ∈ A ¬ 0 s λ π sa = λ π s − B saτ ∀ a ∈ A 0 s π τ sa = K saτ λ π s − B saτ ∀ a ∈ A ¬ 0 s π τ sa = 0 ∀ a ∈ A 0 s \ { a ∗ } π τ sa ∗ = 1 − P a ∈A ¬ 0 s π τ sa . where a ∗ = arg max a ∈A B saτ . So it remains to sho w that we can easily find a λ π s that solves (3) and (4). Define B max , max a ∈A ¬ 0 s B saτ K max , max a ∈A ¬ 0 s K saτ K min , min a ∈A ¬ 0 s K saτ and observe that λ π s = K min + B max ⇒ X a K saτ λ π s − B saτ ≥ 1 and λ π s = |A| · K max + B max ⇒ X a K saτ λ π s − B saτ ≤ 1 . Moreov er , the left-hand side of (3) is strictly monotone in λ π s , and λ π s ∈ [ K min + B max , |A| · K max + B max ] satisfies (4). Putting all this together with the Intermedi- ate V alue Theorem, we conclude that there exists a unique λ π s ∈ [ K min + B max , |A| · K max + B max ] that satisfies (3) and (4), so we can use a simple root-finding algorithm such as the bisection method to approximate it within a constant . 4.2.3 Step 3: Find the V t s ’ s Since we know the π τ sa ’ s now , all the V 0 s , . . . , V τ s ’ s can be computed inductiv ely . V t s = R ( s ) + γ X a,s 0 π t sa θ t sas 0 V t +1 s 0 ∀ s ∈ S , ∀ t ≤ τ . 4.2.4 Running time Recall that S and A are state and action spaces, respec- tiv ely , D is the data set of state-action trajectories, H is the length of the horizon, and is the approximation error of the root-finding algorithm used in Step 2. Steps 1 and 3 both take O ( |S | 2 |A| H ) time, and step 2 takes O ( |S ||A| (log |A| + log |D | + log 1 )) time (the log factors are from the root-finding algorithm, e.g. the bisec- tion method, for which the running time is logarithmic in the size of the interval being searched). This yields a total running time of O ( |S | 2 |A| H + |S ||A| (log |A| + log |D | + log 1 ) for each iteration of Algorithm 1. In practice, we hav e observed that only a handful of iterations are required for con ver gence. By comparison, determining the optimal policy takes O ( |S | 2 |A| H ) time. 4.3 Analysis In this section, we sketch a proof that the sequence of es- timates produced by Algorithm 1 conv erges to a limit that is a stationary point of L ( π ) , the function in Equation (1). This guarantee is similar to the one typically cited for the EM algorithm [2]; in f act, the con ver gence theorem used in the proof sketch below is the same tool used by W u [13] in his analysis of EM. A complete proof of Theorem 1 is av ailable in the supplement for this paper [11]. Theorem 4.1. Algorithm 1 con verges to a stationary point of L ( π ) . Pr oof sketc h. Let Ω be the set of all policies. W e will need to assume that each maximization in Algorithm 1 finds a point in the interior of Ω (a similar assumption is made in W u’ s proof of the conv ergence of the EM algorithm [13]). W e can vie w Algorithm 1 as defining H distinct point-to- set maps { M τ } H τ =0 on Ω , each corresponding to an opti- mization o ver a different π τ . In other words, ˜ π ∈ M τ ( π ) if ˜ π is a solution to the problem of maximizing L ( π ) ov er just the variables in π τ (recall that π = π 0 , . . . , π H ). Let M A = M H ◦ M H − 1 · · · ◦ M 0 , i.e., M A is the point-to- set map defined by one complete cycle of optimizations. By Con ver gence Theorem A of Zangwill [14], Algorithm 1 con verges to a stationary point of L if: (a) Ω is compact, (b) for all ˜ π ∈ M A ( π ) , L ( ˜ π ) ≥ L ( π ) , (c) whene ver π is not a stationary point of L , then for all ˜ π ∈ M A ( π ) , we hav e L ( ˜ π ) > L ( π ) , and (d) M A is a closed map. Conditions (a), (b) and (c) are fairly straightforward to es- tablish. The last condition (d) is mor e difficult, but this can be prov ed by observing that L is continuous, and then ap- plying Proposition 7 and Theorem 8 of Hogan [5]. 5 Experiments Using synthetic en vironments, we compared the value- based prior to two similar algorithms proposed by other authors. W e also inv estigated our algorithm’ s sensiti vity to the value of the mentor’ s policy . W e revie w the other SYED & SCHAPIRE 388 methods belo w , the synthetic en vironments in Section 5.1, and our e xperiments in Sections 5.2 and 5.3. Additional experiments are presented in the supplement for this paper [11]. Recall that Price et al [7] proposed to model the men- tor’ s policy using a Dirichlet distribution. In their scheme, the policy at each state is assigned a prior distribution P s ( a ; β ) = Dir ( β ) , where β is a |A| -length v ector of pos- itiv e reals. Let A o s be the set of optimal actions at state s . W e define each P s ( a ; β ) so that β a = α |A o s | . This amounts to asserting a prior belief that the mentor’ s policy is an op- timal polic y . Note that α plays a similar role here as it does in Equation (1), in that it reflects the degree to which the prior is concentrated on high-v alue policies. Similarly , recall the temporal-dif ference-like algorithm de- veloped by Henderson et al [4], in which the usual Q values are modified so that the optimal policy is more similar to the polic y that generated the data. Although it is difficult to describe succinctly , their algorithm employs a tunable pa- rameter α , which controls the trade-of f between optimality and imitation, just as it does in our algorithm. Since TD techniques do not assume that transition probabilities are giv en, we use the reduction described in Section 4.1 when comparing with our method. 5.1 Maze en vironments W e used maze en vironments for all of our experiments. Each maze was a 30-by-30 grid, with the start state in one corner and the goal state, containing a lar ge positiv e re- ward, in the opposite corner . Movement in a maze was in the four compass directions, b ut taking a move action risked a 30% chance of landing in a random adjacent cell. Also, obstacles (negati ve rewards) were randomly placed in 15% of the cells in each maze, with each having a mag- nitude that was, on av erage, 2/3 as large as the goal state’ s positiv e reward. Finally , the time horizon was set to 90, which was sufficient to allow even meandering policies to ev entually reach the goal state. Our environments had one additional feature that was in- troduced to mak e the comparison between the v arious algo- rithms more interesting. W e found that the optimal action in each state typically had substantially larger v alue than any other action. So a prior that assigned greatest weight to the highest value policies essentially assigned greatest weight to a single policy , i.e., the policy that takes the op- timal action in every state. In such circumstances, we did not expect to observe an adv antage to using a v alue-based prior ov er a Dirichlet prior . T o simulate a scenario where there are many div erse high-v alue policies, we introduced a “twin” action for e very original action, i.e., a separate ac- tion that has exactly the same ef fect on the en vironment. 5.2 Comparison to other methods 5.2.1 Experimental setup For each maze en vironment, we generated data sets of state-action trajectories from an optimal policy for the maze. 3 Howe ver , when estimating that policy from data, we supplied each algorithm with just the location and size of the goal re ward, and not the locations or sizes of the obstacles. Effecti vely , each algorithm assigned the highest prior probability to a policy that mov ed directly towards the goal, ignoring obstacles altogether . So, from the perspec- tiv e of each algorithm, the mentor’ s policy had high value, but w as suboptimal. 5.2.2 Results Figure 1 compares the value-based prior to the Dirichlet prior suggested by Price et al [7]. First, note that our al- gorithm is much more robust to the value of the trade-off parameter α ; we varied α over three orders of magnitude, and the value-based prior impro ved the accuracy of esti- mated policy throughout that range. This is important, as we are not proposing a principled way to set the v alue of α , except to point out that it should generally increase with the value of the mentor’ s policy . Second, although the Dirich- let prior provided a more accurate estimate for smaller data sets for certain values of α , that advantage soon became a disadvantage as the amount of data was increased. T o un- derstand why , recall that in our maze environment, there are many div erse policies that each have high value. The value-based prior assigns the same weight to e very policy that has the same value, e ven if the policies themselves are quite dif ferent. But a Dirichlet prior is forced to encode the belief that a particular policy is most probable. If this pol- icy differs from the mentor’ s policy , then it will ske w the estimation, ev en if both are high v alue polices. Figure 2 compares the v alue-based prior to the hybrid rein- forcement/supervised learning algorithm proposed by Hen- derson et al [4]. For the value-based prior , the reduction described in Section 4.1 was applied, since the hybrid al- gorithm does not assume that the transition probabilities giv en. Note that the value-based prior initially provides an inferior estimate than the nai ve method that uses no prior; we suspect this is because the algorithm at that stage is us- ing poor approximations of the transition probabilities to compute value function in the modeling MDP . Neverthe- less, as the number of samples increases, the value-based prior ev entually provides an advantage. The performance of the hybrid algorithm is perhaps not indicati ve of its gen- eral usefulness, as it may not ha ve been designed with this particular application in mind. 5.3 Sensitivity to policy value W e also in vestigated ho w sensitiv e our algorithm is to the value of the mentor’ s policy . 3 Since there were always at least two optimal actions in each state, per Section 5.1, we randomly chose one of them to always take. SYED & SCHAPIRE 389 Figure 1: T op: Performance of the value-based prior . Bot- tom: Performance of the Dirichlet prior . The x-axis indi- cates the number of state-action trajectories in the data set, and the y-axis indicates the RMS error of the estimated pol- icy with respect to the mentor’ s policy . Each line in each graph is the average estimation error for 50 mazes. α is a trade-off parameter; α = 0 corresponds to not using any prior at all. 5.3.1 Experimental setup T o create policies with a variety of values, we used the following procedure. In each maze en vironment, we com- puted an optimal policy π ∗ . W e then randomly selected δ fraction of the states, and in each state swapped the opti- mal action in π ∗ with a randomly chosen action. W e also added a small Gaussian perturbation (mean 0.5, v ariance σ 2 ) to each state-action probability , and renormalized ap- propriately . By carefully varying δ and σ 2 , we were able to produce policies whose values were distributed in a range of 70% to 100% of the optimal v alue. 5.3.2 Results Figure 3 depicts the performance of our method for esti- mating policies with various v alues. As one might expect, performance de graded as the mentor’ s policy’ s value de- creased. Nonetheless, we found that the v alue-based prior improv es estimation ev en when the mentor’ s polic y’ s v alue is reasonably far from optimal — as low as 80% of the op- timal value. 6 Summary and Future W ork W e ha ve presented a nov el approach to imitation learning, where an apprentice uses the v alue function of an MDP to Figure 2: T op: Performance of the value-based prior . Bot- tom: Performance of the hybrid reinforcement/supervised learning algorithm. Details are the same as for Figure 1, ex- cept that for the value-based prior, the reduction described in Section 4.1 has been applied, and in the case of the hy- brid algorithm, α = −∞ corresponds to ignoring re wards and simply imitating the behavior in the data. assert a prior belief on a mentor’ s polic y , and hav e provided both theoretical and empirical evidence that our algorithm is sound and useful. Our analysis suggests that our algo- rithm, similar to the EM algorithm, will often find a local maximum of the log posterior distribution L ( π ) (Equation (1)). Our experiments indicate that a value-based prior is robust in at least tw o senses: it is effecti ve over a wide range of values for the trade-off parameter α , and it is ef- fectiv e ev en when the mentor’ s policy is suboptimal. The v alue-based prior described here differs from the prior distrib utions used in pre vious approaches to imitation learning [3, 4, 7] in se veral significant w ays. Unlike in ear - lier methods, the value-based prior was not chosen for the sake of mathematical con venience (it is in fact quite incon- venient to work with), but rather to allow an apprentice to assert a very natural belief about the mentor’ s beha vior — that the mentor is reward-seeking. Additionally , unlike the Dirichlet prior , the value-based prior is not separable over states. In other words, evidence for the mentor’ s policy at one state can af fect the maximum likelihood estimate of the mentor’ s policy at other states, a useful “coupling” prop- erty . Also, the value-based prior assigns high probability to all mentor policies that lead to high v alue, allowing the apprentice to remain agnostic about which particular distri- bution o ver actions the mentor takes in each state. W e are currently extending this work in sev eral directions. First, we are de veloping an algorithm that can be applied to SYED & SCHAPIRE 390 Figure 3: Performance of the value-based prior for policies with v alues approximately 70-90% of the optimal v alue. Axes and legend are the same as for Figure 1. Each line in each graph is the average estimation error for 50 policies (10 policies each from 5 maze en vironments). T op: Poli- cies that ha ve av erage value 89.6% of the optimal value, with std dev 1.3%. Middle: Policies that have average value 80.9% of the optimal v alue, with std de v 3.2%. Bot- tom: Policies that hav e a verage v alue 72.9% of the optimal value, with std de v 1.1%. infinite horizon problems, a well-studied setting with many applications. Second, we are attempting to strengthen our con ver gence result to prov e that Algorithm 1 will always find the global optimum of the posterior defined in Equa- tion (1). Finally , we would like to introduce function ap- proximation into this framew ork, so that we can apply our method to larger state spaces. Acknowledgements The authors were supported by the NSF under grant IIS- 0325500. This work benefited greatly from discussions with Esther Le vin, Michael Littman, and Mazin Gilbert. W e would also like to thank Sriniv as Bangalore and Jason W illiams for their suggestions for applications and other helpful comments. Finally , we thank the anonymous refer- ees for their feedback. References [1] P . Abbeel, A. Ng (2004). Apprenticeship Learning V ia Inv erse Reinforcement Learning. Intl. Conf. on Machine Learning 21 . [2] A. Dempster, N. Laird, D. Rubin (1977). Maximum Likelihood from Incomplete Data via the EM Algo- rithm. J ournal of the Royal Statistical Society 39 , 1- 38. [3] A. Fern, S. Natarajan, K. Judah, P . T adepalli (2007). A Decision-Theoretic Model of Assistance Intl. Joint Conf. on AI 20 . [4] J. Henderson, O. Lemon, K. Georgila (2005). Hybrid Reinforcement/Supervised Learning for Dialog Poli- cies from COMMUNICA TOR Data. IJCAI Wksp on Knowledge and Reasoning in Practical Dialogue Sys- tems Edinbur gh, UK. [5] W . Hogan (1973). Point-to-set Maps in Mathematical Programming. SIAM Revie w 15 , 591-603. [6] E. Levin, R. Pieraccini, W . Eckert (2000). A Stochas- tic Model of Human-Machine Interaction for Learn- ing Dialog Strategies. IEEE T rans. on Speech and A u- dio Pr ocessing 8 , 11-23. [7] B. Price, C. Boutilier (2003). A Bayesian Approach to Imitation in Reinforcement Learning. Intl. Joint Conf. on AI 18 . [8] N. Ratlif f, J. Bagnell, M. Zinke vich (2006). Maxi- mum Margin Planning. Intl. Conf. on Machine Learn- ing 23 . [9] J. Schatzmann, K. Georgila, S. Y oung (2005). Quan- titativ e Ev aluation of User Simulation T echniques for Spoken Dialogue Systems. 6th SIGdial W orkshop on Discourse and Dialogue Sept 2-3, Lisbon, Portug al. [10] S. Singh, M. Kearns, D. Litman, M. W alker (2000). Reinforcement Learning for Spoken Dialogue Sys- tems. Advances in Neural Information Pr ocessing Systems 12 . [11] U. Syed, R. E. Schapire (2007). “Imitation Learn- ing with a V alue-Based Prior – Supplement”. http://www .cs.princeton.edu/ ∼ usyed/uai2007/ [12] M. W alker , D. Litman, C. Kamm, A. Abella (1998). Evaluating Spoken Dialogue Agents with P AR- ADISE: T wo Case Studies. Computer Speech and Language 12 , 3. [13] J. W u (1983). On the Con vergence Properties of the EM Algorithm. The Annals of Statistics 11 , 95-103. [14] W . Zangwill (1969). “Nonlinear Programming: A Unified Approach”. Prentice Hall, Inc., Englewood Cliffs, NJ. SYED & SCHAPIRE 391
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment