가치 기반 사전으로 배우는 모방 학습
본 논문은 멘토의 시연을 통해 정책을 학습하는 모방 학습 문제에, 멘토 행동에 대한 사전 지식으로 “가치 기반 사전”을 도입한다. 사전 지식은 멘토가 높은 가치의 정책을 따를 것이라는 가정 하에, 별도의 MDP 모델의 정책 가치 값을 로그 사전 확률로 변환한다. 베이즈 추론과 효율적인 최적화 알고리즘을 결합해 로그 사후 확률의 정지점을 찾으며, 실험을 통해 기존 방법 대비 학습 속도와 정확도가 향상됨을 보인다.
저자: Umar Syed, Robert E. Schapire
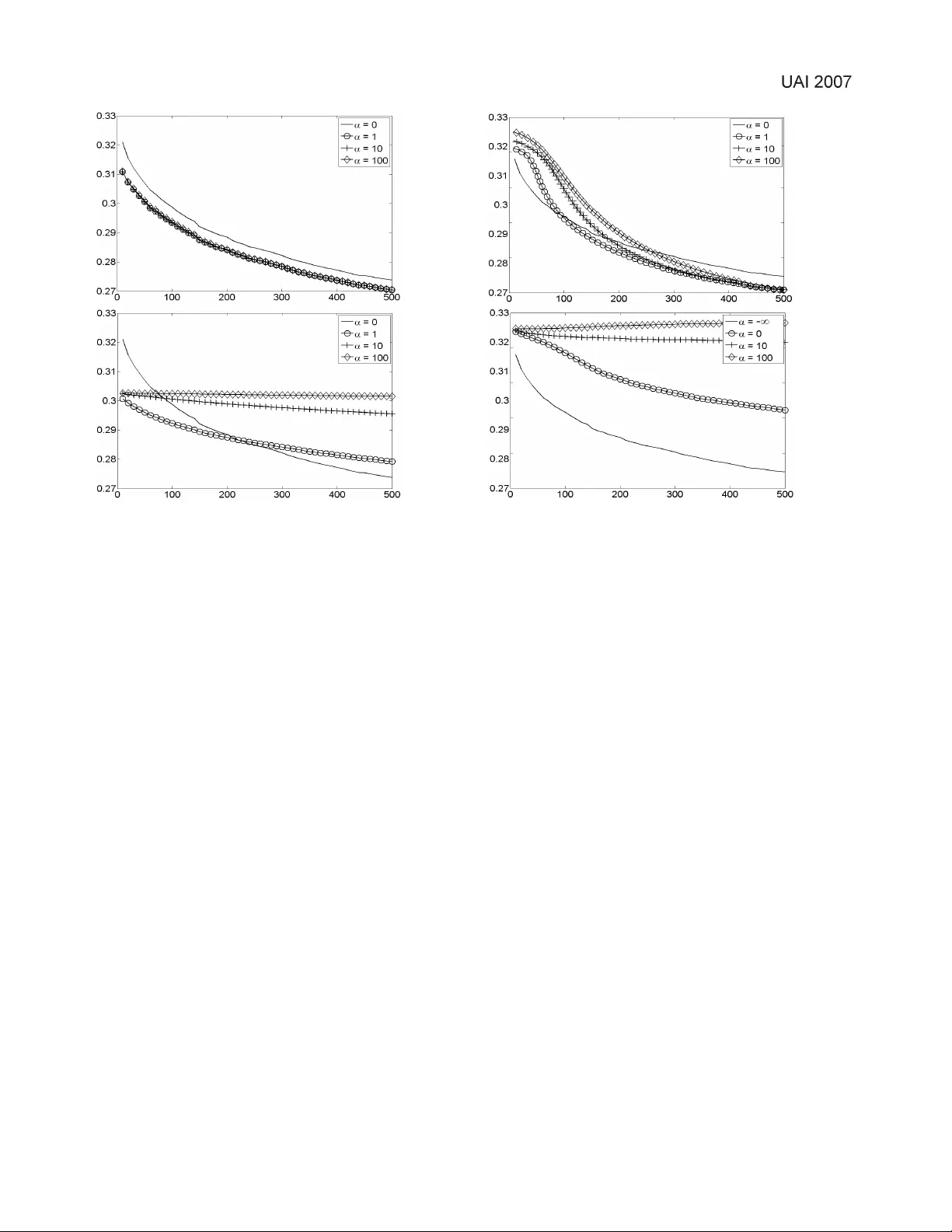
**1. 서론 및 배경**
모방 학습(Imitation Learning, IL)은 멘토의 시연을 통해 에이전트가 정책을 학습하도록 하는 프레임워크이다. 전통적인 IL은 데모가 충분히 많을 때 좋은 성능을 보이지만, 실제 로봇이나 자율주행 등에서는 시연 획득 비용이 높아 사전 지식 활용이 필수적이다. 기존 연구는 (a) 행동 분포를 직접 사전 확률로 설정하거나, (b) 멘토의 보상 함수를 추정하는 베이즈 IRL, (c) 최대 엔트로피 원칙을 적용한 확률적 모델링 등을 제안했다. 그러나 이러한 방법들은 사전이 “보상 형태”로 명시될 때만 효과적이며, 멘토가 최적이 아닌 근사 정책을 따를 경우 사전과 실제 행동 사이의 불일치가 크게 나타난다.
**2. 가치 기반 사전(Value‑Based Prior) 정의**
저자들은 멘토 행동에 대한 사전 지식을 “멘토가 높은 가치를 갖는 정책을 따를 것”이라는 형태로 가정한다. 이를 위해 **모델링 MDP** \( \hat{M} = (\mathcal{S}, \mathcal{A}, \hat{P}, \hat{R}, \gamma) \) 를 정의한다. 이 MDP는 실제 환경과 차이가 있을 수 있지만, 멘토가 합리적인 판단을 할 수 있는 근사 모델이다. 정책 \(\pi\) 의 기대 가치
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기