GPU-Based Heuristic Solver for Linear Sum Assignment Problems Under Real-time Constraints
In this paper we modify a fast heuristic solver for the Linear Sum Assignment Problem (LSAP) for use on Graphical Processing Units (GPUs). The motivating scenario is an industrial application for P2P live streaming that is moderated by a central node…
Authors: Roberto Roverso, Amgad Naiem, Mohammed El-Beltagy
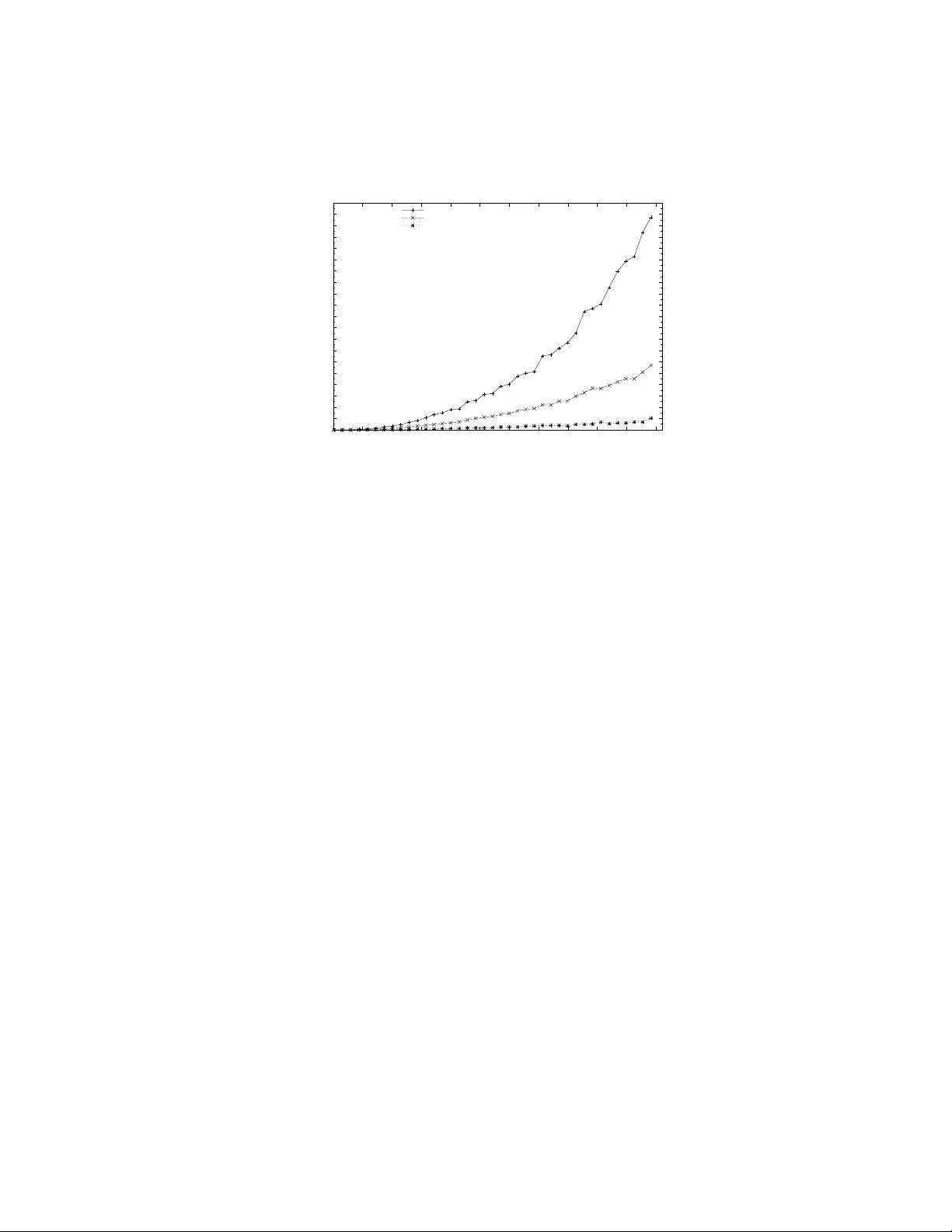
GPU-Based Heuristic Solv er for Linear Sum Assignmen t Problems Under Real-time Constrain ts Rob erto Ro verso 1 , 2 , Amgad Naiem 1 , 3 , Mohammed El-Beltagy 1 , 3 , and Sameh El-Ansary 1 , 4 1 P eerialism Inc., Sw eden 2 KTH-Ro yal Institute of T ec hnology , Sweden 3 Cairo Universit y , Egypt 4 Nile Universit y , Egypt { roberto,amgad,mohammed,sameh } @peerialism.com Abstract. In this paper we mo dify a fast heuristic solver for the Linear Sum Assignmen t Problem (LSAP) for use on Graphical Processing Units (GPUs). The motiv ating scenario is an industrial application for P2P liv e streaming that is moderated by a cen tral node which is perio dically solv- ing LSAP instances for assigning p eers to one another. The central node needs to handle LSAP instances inv olving thousands of p eers in as near to real-time as possible. Our findings are generic enough to be applied in other con texts. Our main result is a parallel version of a heuristic algo- rithm called Deep Greedy Switching (DGS) on GPUs using the CUDA programming language. DGS sacrifices absolute optimality in fav or of lo w computation time and w as designed as an alternative to classical LSAP solv ers such as the Hungarian and auctioning methods. The contribution of the pap er is threefold: First, we present the process of trial-and-error w e wen t through, in the hop e that our exp erience will b e b eneficial to adopters of GPU programming for similar problems. Second, we show the mo difications needed to parallelize the DGS algorithm. Third, w e sho w the p erformance gains of our approach compared to b oth a se- quen tial CPU-based implementation of DGS and a parallel GPU-based implemen tation of the auctioning algorithm. 1 In tro duction In order to deal with hard optimization or combinatorial problems in time- constrained environmen ts, it is often necessary to sacrifice optimality in order to meet the imp osed deadlines. In our w ork, w e ha ve dealt with a large scale p eer-to-p eer live-streaming platform where the task of assigning n providers to m receivers is carried out by a cen tralized optimization engine. The problem of assigning p eers to one-another is mo delled as a line ar sum assignment pr oblem (LSAP). Ho wev er, in our p2p system, the computational o v erhead of minimizing the cost of assigning n jobs (receiv ers) to n agen ts (senders) is usually quite high b ecause w e are often dealing with tens of thousands of agents and jobs (peers in the system). W e ha ve seen our implementation of classical LSAP solvers take sev eral hours to pro vide an optimal solution to a problem of this magnitude. In the con text of live streaming w e could only afford a few seconds to carry out this optimization. It was also important for us not to sacrifice optimalit y to o m uch in the pursuit of a practical optimization solution. W e hence opted for a strategy of trying to discov er a fast heuristic near-optimal solver for LSAP that is also am enable to parallelization in such a w ay that can exploit the massiv e computational p otential of mo dern GPUs. After structured exp erimentation on a num b er of ideas for a heuristic optimizer, w e found a simple and effectiv e heuristic w e called Deep Greedy Switching [1] (DGS). It was shown to w ork extremely well on the instances of LSAP we were interested in, and we never observ ed it deviate from the optimal solution b y more than 0 . 6%, (c.f. [1, p. 5]). Seeing that DGS has parallelization p otential, we mo dified and adapted it to b e run on an y parallel architecture and consequently also on GPUs. In this work, we chose CUD A [2] to b e our choice as a GPU programming language to implemen t the DGS solv er. CUDA is a sufficiently general C-lik e lan- guage whic h allows for execution of any kind of user-defined algorithms on the highly parallel architecture of NVIDIA GPUs. GPU programming has b ecome increasingly p opular in the scientific communit y during the last few years. Ho w- ev er, the task of dev eloping whatso ever mathematical pro cess in a GPU-sp ecific language still inv olves a fair amoun t of effort in understanding the hardware arc hitecture of the target platform. In addition, implementation efforts m ust tak e in to consideration a set of b est practices to achiev e b est p erformance. This is the reason wh y in this pap er we will provide an in tro duction to CUDA in Section 2, in order to better understand its adv antages, b est practices and limi- tations, so that it will later b e easier to appreciate the solver implementation’s design choices in Section 5. W e will also detail the inner functioning of the DGS heuristic in Section 3 and show results obtained b y comparing b oth differen t v ersions of the DGS solv er and the final version of the GPU DGS solv er with an implemen tation of the auction algorithm running on GPUs in Section 6. W e will conclude the pap er with few considerations on the achiev emen ts of this w ork and our future plans in Section 7. 2 GPUs and the CUDA language Graphical Processing Units are mainly accelerators for graphical applications, suc h as games and 3D mo delling softw are, which mak e use of the Op enGL and DirectX programming interfaces. Giv en that many of calculations inv olv ed in those applications are amenable to parallelization, GPUs hav e hence b een arc hi- tected as massiv e parallel machines. In the last few years GPUs hav e ceased to b e exclusively fixed-function devices and hav e evolv ed to b ecome flexible par- allel pro cessors accessible through programming languages [2][3]. In fact, mo d- ern GPUs as NVIDIA’s T esla and GTX are fundamentally fully programmable man y-core c hips, each one of them ha ving a large num b er of parallel pro cessors. Multicore chips are called Streaming Multipro cessors (SMs) and their num b er can v ary from one, for low-end GPUs, to as many as thirt y . Each SM con tains in turn 8 Scalar Pro cessors (SPs), each equipp ed with a set of registers, and 16KB on-c hip memory called Shared Memory . This memory has low er access latency and higher bandwidth compared to off-chip memory , called Global Memory , whic h is usually of the DDR3/DDR5 type and of size of 512MB to 4GB. W e c hose CUDA as GPU Computing language for implementing our solv er b ecause it b est accomplishes a trade-off b et ween ease-of-use and required kno wl- edge of the hardware platform’s architecture. Other GPU specific languages, suc h as AMD’s Stream [4] and Kronos’ Op enCL standard [3] lo ok promising but fall short of C UD A either for the lack of supp ort and do cumen tation or for the qualit y of the dev elopment platform in terms of stability of the provided to ols, suc h as compilers and debuggers. Even though CUD A provides a sufficient de- gree of abstraction from the GPU arc hitecture to ease the task of implementing parallel algorithms, one m ust still understand the basics of the functioning of NVIDIA GPUs to b e able to fully utilize the p ow er of the language. The CUD A programming mo del imposes the application to be organized in a se quential p art running on a host , usually the machine’s CPU, and parallel parts called kernels that execute co de on a parallel devic e , the GPU(s). Kernels are blo c ks of instructions which are executed across a n umber of parallel threads. Those are then logically group ed b y CUDA in a grid whose sub-parts are the thread blocks. The size of the grid and thread blo cks are defined b y the pro- grammer. This organization of threads derives from the legacy purp ose of GPUs where the rendering of a texture (see grid) needs to b e parallelized by assigning one thread to every pixel, whic h are then executed in batches (see thread blo cks). A thread block is a set of threads which can co op erate among themselves ex- clusiv ely using barrier synchronization, no other synchronization primitiv es are pro vided. Each block has access to an amount of Shared Memory which is exclu- siv e for its group of threads to utilize. The blo cks are therefore a w ay for CUDA to abstract the physical architecture of Scalar Multipro cessors and Pro cessors a wa y from the programmer. Management of Global and Shared Memory m ust be enforced explicitly by the programmer through primitives pro vided by CUD A. Although Global memory is sufficient to run any CUD A program, it is advisable to use Shared Memory in order to obtain efficient coop eration and comm unica- tion b etw een threads in a blo ck. It is particularly adv antageous to let threads in a blo c k load data from global memory to shared on-chip memory , execute the k ernel instructions and later copy the result back in global memory . 3 DGS Heuristic In LSAP we try to attain the optimal assignment of n agen ts to n jobs, where there is a certain b enefit a ij to b e realized when assigning agent i to job j . The optimal assignmen t of agents to jobs is the one that yields the maxim um total b enefit, while resp ecting the constrain t that each agent can only b e assigned to only one job, and that no job is assigned to more than one agent. The assignmen t problem can b e formally describ ed as follo ws max n X i =1 n X j =1 a ij x ij n X i =1 x ij = 1 ∀ j ∈ { 1 . . . n } n X j =1 x ij = 1 ∀ i ∈ { 1 . . . n } x ij ∈ { 0 , 1 } ∀ i, j ∈ { 1 . . . n } There are man y applications that inv olv e LSAP , ranging from image pro cessing to inv en tory management. The tw o most p opular algorithms for LSAP are the Hungarian metho d [5] and the auction algorithm [6]. The auction algorithm has b een shown to b e very effective in practice, for most instances of the assignment problem, and it is considered to b e one of the fastest algorithms that guarantees a very near optimal solution (in the limit of n ). The algorithm works lik e a real auction where agents are bidding for jobs. Initially , the price for each job is set to zeros and all agen ts are unassigned. At each iteration, unassigned agents bid simultaneously for their “b est” jobs which causes the jobs’ prices ( p j ) to rise according. The prices w ork to diminish the net benefit ( a ij − p j ) an agen t attains when b eing assigned a given job. Each job is aw arded to the highest bidder, and the algorithm k eeps iterating until all agents are assigned. Although the auction algorithm is quite fast and can b e easily parallelized, it is not w ell suited to situations where large instances of the assignment problem are inv olv ed and there is deadline after which a solution would b e useless. Re- cen tly , a nov el heuristic approach called De ep Gr e e dy Switching (DGS) [1] w as in tro duced for solving the assignmen t problem. It sacrifies very little in terms of optimality , for a h uge gain in the running time of the algorithm ov er other metho ds. The DGS algorithm provides no guarantees 5 for attaining an optimal solution, but in practice we hav e seen it deviate with less than 0.6% from the optimal solutions, that are rep orted by the auction algorithm, at its w orst p er- formance. Such a minor sacrifice in optimality is acceptable in man y dynamic systems where sp eed is the most imp ortant factor as an optimal solution that is deliv ered to o late is practically useless. Compared with the auction algorithm, DGS has the added adv antage that it starts out with a full assignment of jobs to agen ts and k eeps improving that assignment during the course of its execution. The auction algorithm, how ev er, attains full assignment only at termination. Hence, if a deadline has b een reached where an assignment mu st b e pro duced, DGS can interrupted to get the best assignment solution it has attained thus far. The DGS algorithm, shown in Algorithm 1, starts with a random initial solu- tion, and then k eeps on moving in a restricted 2-exchange neighborho o d of this solution according to certain criteria until no further improv ements are possible. 5 The authors are still working on a formal analysis of DGS that would help explain its surprising success. 3.1 Initial Solution The simplest wa y to obtain an initial solution is by randomly assigning jobs to agen ts. An alternativ e is to do a greedy initial assignment where the b enefit a ij is tak en in to accoun t. In our exp eriments with DGS w e found that there w as not clear adv antage to adopt either approach. Since greedy initial assignment tak es a bit longer, we opted to use random agent/job assignment for the initial solution. 3.2 Difference Ev aluation Starting from a full job/agent assignment σ , eac h agen t tries to find the b est 2-exc hange in the neigh b orho o d of σ . F or eac h agent i w e consider ho w the ob jectiv e function f ( σ ) would change if it were to swap jobs with another agent i 0 (i.e. a 2-exc hange). W e select the 2-exchange that yields the best improv ement δ i and sav e it as agent i ’s b est configuration N A i . The pro cedure is called the agent differ enc e evaluation (ADE) and is desc ribed formally in Algorithm 2. Similarly , a job differ enc e evaluation (JDE) is carried out for each job, but in this case w e consider swapping agents. 3.3 Switc hing Here we select the 2-exc hange that yields the greatest improv ement in ob jectiv e function v alue and mo dify the job/agent assignment accordingly . W e then carry out JDE and ADE for the jobs and agen ts inv olved in that 2-exchange. W e rep eat the switc hing step until no further improv ements are attainable. W e define an assignment as a mapping σ : J → I , where J is the set of jobs and I is the set of agen ts. Here σ ( j ) = i means that job j is assigned to agen t i . Similarly another assignment mapping τ : I → J is for mapping jobs to agent where τ ( i ) = j means that agent i is assigned to job j . There is also an assignmen t mapping function to construct τ from σ defined as τ = M ( σ ) and the ob jectiv e function v alue of an assignment σ is given b y f ( σ ). W e make use of a switching function switc h ( i, j, σ ) which returns a mo dified version the assignmen t σ after agen t i has b een assigned to job j ; i.e. a 2-exchange has o ccurred b etw een agents i and σ ( j ). F or agent i , the job j i is the job that yields the largest increase in ob jectiv e function when assigned to agent i and it can b e expressed as j i = arg max j =1 ,...,n,j 6 = τ ( i ) f ( switc h ( i, j, σ )) − f ( σ ) , and the corresp onding impro vemen t in ob jectiv e function v alue is expressed as δ i = max j =1 ,...,n,j 6 = τ ( i ) f ( switc h ( i, j, σ )) − f ( σ ) . W e similarly define for each job j the b est agent that it can b e assigned to i j and the corresp onding improv ement δ j . Using this terminology , the algorithm is formally describ ed in Algorithm 1. Algorithm 1: DGS Algorithm DGS ( σ, f ) rep eat σ start ← σ , τ = M ( σ ), δ ← ∅ , δ ← ∅ AD E ( i, f , τ , σ, N A, δ ) ∀ i ∈ I . Difference Evaluation J D E ( j, f , τ , σ, N J, δ ) ∀ j ∈ J . Difference Evaluation while ∃ δ i > 0 ∨ ∃ δ j > 0 do . Switching phase i ∗ ← arg max i =1 ...n δ i , j ∗ ← arg max j =1 ...n δ j if δ i ∗ > δ j ∗ then δ i ∗ = 0 σ 0 ← switch ( i ∗ , j i ∗ , σ ), τ 0 ← M ( σ 0 ) ag ents ← { i ∗ , σ 0 ( τ ( i ∗ )) } , j obs ← { τ ( i ∗ ) , τ 0 ( i ∗ ) } else δ j ∗ = 0 σ 0 ← switch ( i j ∗ , j ∗ , σ ) ag ents ← { σ ( j ∗ ) , σ 0 ( j ∗ )) } , j obs ← { j ∗ , τ ( σ 0 ( j ∗ )) } if f ( σ 0 ) > f ( σ ) then σ ← σ 0 , τ = M ( σ ) AD E ( j, f , τ , σ, N A, δ ) ∀ i ∈ ag ents J D E ( j, f , τ , σ, N J, δ ) ∀ j ∈ j obs un til f ( σ start ) = f ( σ 0 ) output σ 0 4 Ev aluation While explaining the process of realization of the CUD A solver in the next section, w e also show results of the impact of the v arious steps that we wen t through to implement it and enhance its p erformance. The exp erimen tal setup for the tests consists of a c onsumer mac hine with a 2.4Ghz Core 2 Duo processor equipp ed with 4GB of DDR3 RAM and NVIDIA GTX 295 graphic card with 1GB of DDR5 on-b oard memory . The NVIDIA GTX 295 is currently NVIDIA’s top-of-the-line consumer video card and boasts a total num b er of 30 Scalar Multipro cessors and 240 Pro cessors, 8 for each SM, whic h run at a clo c k rate of 1.24 GHz. In the exp eriments, we use a thread blo ck size 256 when executing k ernels which do not make use of Shared Memory , and 16 in the case they do. Concerning the DGS input scenarios, we use dense instances of the GEOM type defined by Bus and Tvrdık [7], and generated as follows: first w e generate n p oin ts randomly in a 2D square of dimensions [0 , C ] × [0 , C ], then each a ij v alue is set as the Euclidean distance b etw een p oints i and j from the ge nerated n p oin ts. W e define the problem size to b e equal to the num ber of agents/jobs. F or the sak e of simplicity , we make use of problem sizes which are multiples of the thread blo ck size. Note that ev ery exp eriment is the result of the av eraging of a n umber of runs executed using differently seeded DGS instances. Algorithm 2: ADE Algorithm ADE ( i, f , τ , σ, N A, δ ) j ← τ ( i ), σ ∗ i ← σ , δ i ← 0 foreac h j 0 ∈ { J | j 0 6 = j } do i 0 ← σ ( j 0 ) σ 0 i ← σ , σ 0 i ( j ) ← i 0 , σ 0 i ( j 0 ) ← i if f ( σ 0 i ) > f ( σ ∗ i ) then σ ∗ i ← σ 0 i if σ ∗ i 6 = σ then N A i ← σ ∗ i δ i ← f ( σ ∗ i ) − f ( σ ) else N A i ← 0 0 5000 10000 15000 20000 25000 30000 35000 40000 45000 50000 55000 60000 0 900 1800 2700 3600 4500 5400 6300 7200 8100 9000 9900 Time (ms) Problem Size Difference Evaluation Phase CPU GPU Global Memory GPU Shared Memory Fig. 1. Computational time comparison b etw een Difference Ev aluation implemen ta- tions 5 The DGS CUDA Solv er The first prototype of the DGS solv er was implemen ted in the Ja v a language. Ho wev er, its performance did not meet the demands of our target real-time system. W e therefore p orted the same algorithm to the C language in the hop e that w e obtain b etter p erformance. The outcome of this effort was the first pro duction-qualit y implemen tation of the DGS which w as sufficien tly fast up to problem sizes of 5000 peers. The Difference Ev aluation step of the algorithm, as describ ed in Section 3.2 amounted to as m uch as 70% of the total computational time of the solver. Luckily , all JDE and ADE ev alution for jobs and agents can b e done in parallel as they are completely orthogonal and they do not need to b e executed in a sequential fashion. Hence, our first p oin t of inv estigation was to implemen t a CUDA ADE/JDE kernel which could execute both ADE and JDE algorithms on the GPU. W e dev elop ed tw o versions of the ADE/JDE k ernel: the first runs exclusively on the GPU’s Global memory and the second makes use of the GPU’s Shared memory to obtain b etter performance. F or ease of exp osition w e will only discuss ADE going forward. This is without any loss of generalit y as ev erything that applies to ADE also applies to JDE, with the proviso the talk of jobs instead of agen ts. Difference Ev aluation on Global Memory As mentioned earlier, Global memory is fully addressable by an y thread running on the GPU and no sp ecial op eration is needed to access data on it. Therefore, in the first version of the kernel, w e decided to simply upload the full A ij matrix to the GPU memory together with the current agent to job assignmen ts and all the data we needed to run the ADE algorithm on the GPU. Then we let the GPU spa wn a thread for each of the agen ts in volv ed. Consequen tly , a CUD A thread ct i asso ciated with agent i executes the ADE algorithm only for agent i b y ev aluating all its p ossible 2-exchanges. The agen t-to-thread allo cation on the GPU is trivial and is made b y assigning the thread identifier ct i to agen t i . Difference Ev aluation on Shared Memory Difference Ev aluation using Shared Memory assigns one thread to each 2-exchange ev aluation for agen t i and job j . That implies that the n umber of created threads equals the num b er of cells of the A ij matrix. Each thread ct ij then pro ceeds to load in shared memory the data which is needed for the single ev aluation be- t ween agent i and job j . Once the 2-exchange ev aluation is computed, every thread ct ij stores the resulting v alue in a matrix lo cated in global memory in p osition ( i , j ). After that, another small kernel is executed whic h causes a thread for each row i of the resulting matrix to find the b est 2-exc hange v alue along that same row for all indexes j . The outcome of this operation represen ts the b est 2-exc hange v alue for agent i . In Figure 1, w e compare the results obtained b y running the t wo aforementioned Shared Memory GPU kernel implementa- tions and its Global Memory counterpart against the pure C implementation of the Difference Ev aluation for different problem sizes. F or ev aluation purp ose, we used a CUDA-enabled version of the DGS where only the Difference Ev aluation phase of the algorithm runs on the GPU and can b e ev aluated separately from the other phase. This implies that we need to upload the input data for the ADE/JDE phase to the GPU at every iteration of the DGS algorithm, as w ell as we need to do wnload its output in order to provide input for the Switching phase. The aforementioned memory tranfers are accounted for in the measure- men ts. As we can observe, there’s a dramatic improv emen t when passing from the CPU implementation of the difference ev aluation to b oth GPU implemen- tations, even though m ultiple memory tranfers o ccur. In addition, the Shared Memory v ersion b ehav es consistently b etter than the Global Memory one. F ur- thermore, the trend for increasing problem sizes is linear for b oth GPU v ersions of the Difference Ev aluation, opp osed to the exp onential growth of the CPU v ersion curve. Switc hing Considering the Switc hing phase of the DGS algorithm describ ed in Subsection Algorithm 3: Parallel DGS Algorithm DGS ( σ, f ) rep eat σ start ← σ , τ = M ( σ ), δ ← ∅ , δ ← ∅ start parallel ∀ i ∈ I , ∀ j ∈ J . Difference Evaluation Phase starts AD E ( i, f , τ , σ, N A, δ ) J D E ( j, f , τ , σ, N J, δ ) stop parallel . Difference Evaluation Phase ends while ∃ δ i > 0 ∨ ∃ δ j > 0 do . Switching phase CC ( I , J, N A, N J, C ) δ i ← 0 ∀ i ∈ I , δ n + j ← 0 ∀ j ∈ J δ i ← { δ i | i / ∈ C } ∀ i ∈ I δ n + j ← { δ j | σ ( j ) / ∈ C } ∀ j ∈ J start parallel ∀ δ t > 0 if t ≤ n then i ← t , σ 0 ← switch ( i, j i , σ ) else j ← ( t − n ) , σ 0 ← switch ( i j , j, σ ) if f ( σ 0 ) > f ( σ ) then σ ← σ 0 , τ = M ( σ ) stop parallel start parallel ∀ i ∈ { I | i / ∈ C } , ∀ j ∈ { J | σ ( j ) / ∈ C } AD E ( i, f , τ , σ, N A, δ ) J D E ( j, f , τ , σ, N J, δ ) stop parallel un til f ( σ start ) = f ( σ 0 ) output σ 0 3.3 we found out that in many cases the computational time necessary to apply the b est 2-exc hanges is fairly high. Our exp erience is that the switching phase migh t ha ve a relative impact of b etw een 35% and 60% of the total computation time of the solver. In order to impro ve the performance of this phase, we mo dified the Switching algorithm so that a subset of the b est 2-exc hanges computed in the Difference Ev aluation section might b e applied concurrently . The mo dified DGS algorithm is sho wn in Algorithm 3. In order to execute some of the switc hes in parallel, we need to identify which among them are not conflicting. F or that, w e designed a function called CC , shown in Algorithm 4, which serves the afore- men tioned purp ose. Once the non-conflicted 2-exchanges are determined by CC, w e identify the corresp onding agents and jobs and w e apply the exchanges in a parallel fashion. After this op eration completes, we pro ceed to re-ev aluate the differences for the agents and jobs whose 2-exchanges were identified as conflict- ing, for there might b e p ossible b etter improv ements for those which were not applied. At the next iteration of the DGS algorithm, conflicted tw o-exchanges ma y b e resolv ed and applied in parallel. In order to execute the parallel Switch- ing phase on the GPU, we simply let the GPU spa wn a num b er of threads which Algorithm 4: Check Conflicts Algorithm CC ( I , J, N A, N J, C ) C R ← ∅ , C ← ∅ foreac h i ∈ { I | N A i 6 = 0 } do σ ← N A i i 0 ← σ ( j i ) if i ∈ C R or i 0 ∈ C R then C ← { C , i } else C R ← { C R, i, i 0 } foreac h j ∈ { J | N J j 6 = 0 } do σ ← N J j i ← σ ( j ) if i ∈ C R or i j ∈ C R then C ← { C , i } else C R ← { C R, i, i j } is equal to the num b er of non-conflicting 2-exchanges and let them p erform the switc h. 6 Results In Figure 2 we show the results obtained by comparing three differen t imple- men tations of the DGS heuristic: a pure C implementation lab elled “CPU”, the “Mixed GPU-CPU” implementation, where only the Difference Ev aluation sec- tion of the algorithm is executed on the GPU using Shared Memory , and the “GPU” implementation, where all three main phases of the DGS including the Switc hing are executed on the GPU. As we can observ e, the gain in p erformance when considering the “GPU” compared to the t wo other implemen tations is paramoun t. There are tw o fundamental reasons for that. The first is the sp eed- up obtained by applying all non-conflicting 2-exchanges in parallel. The second reason is a direct consequence of the fact that most of the operations are ex- ecuted directly on the GPU and few host–device op erations are needed. Such op erations, e.g. memory transfers, can b e exp ensive and certainly contribute to the absolute time needed for the solver to reach an outcome. In fact, it’s inter- esting to observ e that the total termination time needed for big problem sizes is less than the total time needed for executing just the ADE/JDE phase, as sho wn in Figure 1, where multiple memory tranfers o ccur at ev ery iteration of the algorithm. In order to assess the improv ement in p erformance of our GPU DGS solv er with resp ect to other LSAP solvers, we compare our solver to an implemen tation of the Auction algorithm published by V asconcelos et al. [8], whic h is implemented on GPUs using the CUDA language. Figure 3 shows the outcome of this analysis. As we can observe, the sp eed–up obtained can b e as 0 3000 6000 9000 12000 15000 18000 21000 24000 27000 30000 33000 36000 39000 42000 45000 48000 51000 54000 57000 60000 0 900 1800 2700 3600 4500 5400 6300 7200 8100 9000 9900 Time (ms) Problem Size DGS Implementations Comparison CPU Mixed GPU-CPU GPU Fig. 2. Computational time comparison betw een DGS’s implemen tations. high as 400 times faster. F urthermore, we can note that even the CPU version of the sequential DGS algorithm p erforms considerably b etter than the GPU auctioning solv er, as muc h as 20 times faster for large problem sizes. 7 Conclusion & F uture W ork In this pap er we presen ted the realization of a GPU-enabled LSAP solver based on the Deep Greedy Switching heuristic algorithm and implemented using the CUD A programming language. W e detailed the pro cess of implemen tation and enhancemen t of the tw o main phases of the algorithm: Difference Ev aluation and Switching, and we provided results showing the impact of eac h iteration on the performance. In particular, w e show ed how parallelizing some parts of the solver with CUDA can lead to substan tial sp eed–ups. W e also suggested a mo dification to the DGS algorithm, in the Switching phase, which enables the solv er to run en tirely on the GPU. In the last part of the paper, we also sho w the p erformance of the final v ersion of the solver compared to a pure C language DGS implementation and to an auction algorithm implementation on GPUs, concluding that the time needed for the DGS solver to reach an outcome is one order of magnitude lo wer compared to the “C” implemen tation for big scenarios and three orders of magnitude low er on a verage compared to the GPU auction solver in almost all problem sizes. F or future work, w e would lik e to formally analyze the modified v ersion of the DGS algorithm to theoretically assess its low er bound on optimality . W e would also lik e to see our solver applied in different con texts and explore p ossible a pplications inv olving LSAP that ha ve y et to b e inv estigated due to computational limitations. 0 25 50 75 100 125 150 175 200 225 250 275 300 325 350 375 400 0 300 600 900 1200 1500 1800 2100 2400 2700 3000 3300 3600 3900 4200 Speedup (times) Problem Size Speedup Comparison GPU Auctioning / GPU DGS GPU Auctioning / CPU DGS Fig. 3. Sp eed-up comparison betw een DGS’s implemen tations compared to GPU Auc- tioning References [1] A. Naiem and M. El-Beltagy , “Deep greedy switching: A fast and simple approach for linear assignmen t problems,” in 7th International Confer enc e of Numerical Analysis and Applie d Mathematics , 2009. [2] M. Garland, S. Le Grand, J. Nick olls, J. Anderson, J. Hardwic k, S. Morton, E. Phillips, Y. Zhang, and V. V olk ov, “Parallel computing experiences with cuda,” Micr o, IEEE , v ol. 28, no. 4, pp. 13–27, 2008. [Online]. Av ailable: h ttp://dx.doi.org/10.1109/MM.2008.57 [3] K. Group. Op encl: The op en standard for parallel programming of heterogeneous systems. [Online]. Av ailable: http://www.khronos.org/opencl/ [4] A. Bay oumi, M. Chu, Y. Hanafy , P . Harrell, and G. Refai-Ahmed, “Scientific and engineering computing using ati stream tec hnology ,” Computing in Scienc e and Engine ering , vol. 11, pp. 92–97, 2009. [5] H. W. Kuhn, “The h ungarian method for the assignment problem,” Naval R ese ar ch L o gistics Quarterly , v ol. 2, pp. 83–97, 1955. [6] D. Bertsek as, “The auction algorithm: A distributed relaxation metho d for the assignmen t problem,” Annals of Op er ations R ese ar ch , vol. 14, no. 1, pp. 105–123, 1988. [7] L. Bus and P . Tvrdık, “Distributed Memory Auction Algorithms for the Linear Assignmen t Problem,” in Pr o c e e dings of 14th IASTED International Confer enc e of Par al lel and Distribute d Computing and Systems , 2002, pp. 137–142. [8] C. N. V asconcelos and B. Rosenhahn, “Bipartite graph matching com- putation on gpu.” in EMMCVPR , ser. Lecture Notes in Computer Sci- ence, D. Cremers, Y. Bo yko v, A. Blake, and F. R. Schmidt, Eds., v ol. 5681. Springer, 2009, pp. 42–55. [Online]. Av ailable: h ttp://dblp.uni- trier.de/db/conf/emmcvpr/emmcvpr2009.h tml#V asconcelosR09
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment