GPU 기반 실시간 선형 할당 문제 휴리스틱 솔버
본 논문은 실시간 P2P 스트리밍 시스템에서 수천 개의 피어를 매칭하기 위해, 최적성을 약간 포기하고 계산 시간을 크게 단축시키는 휴리스틱 알고리즘 Deep Greedy Switching(DGS)을 CUDA 기반 GPU에서 병렬화한 구현을 제시한다. CPU 단일 스레드와 GPU 기반 경매 알고리즘에 비해 10배 이상 속도 향상을 달성했으며, 최적 해와의 평균 차이는 0.6% 이하로 유지한다.
저자: Roberto Roverso, Amgad Naiem, Mohammed El-Beltagy
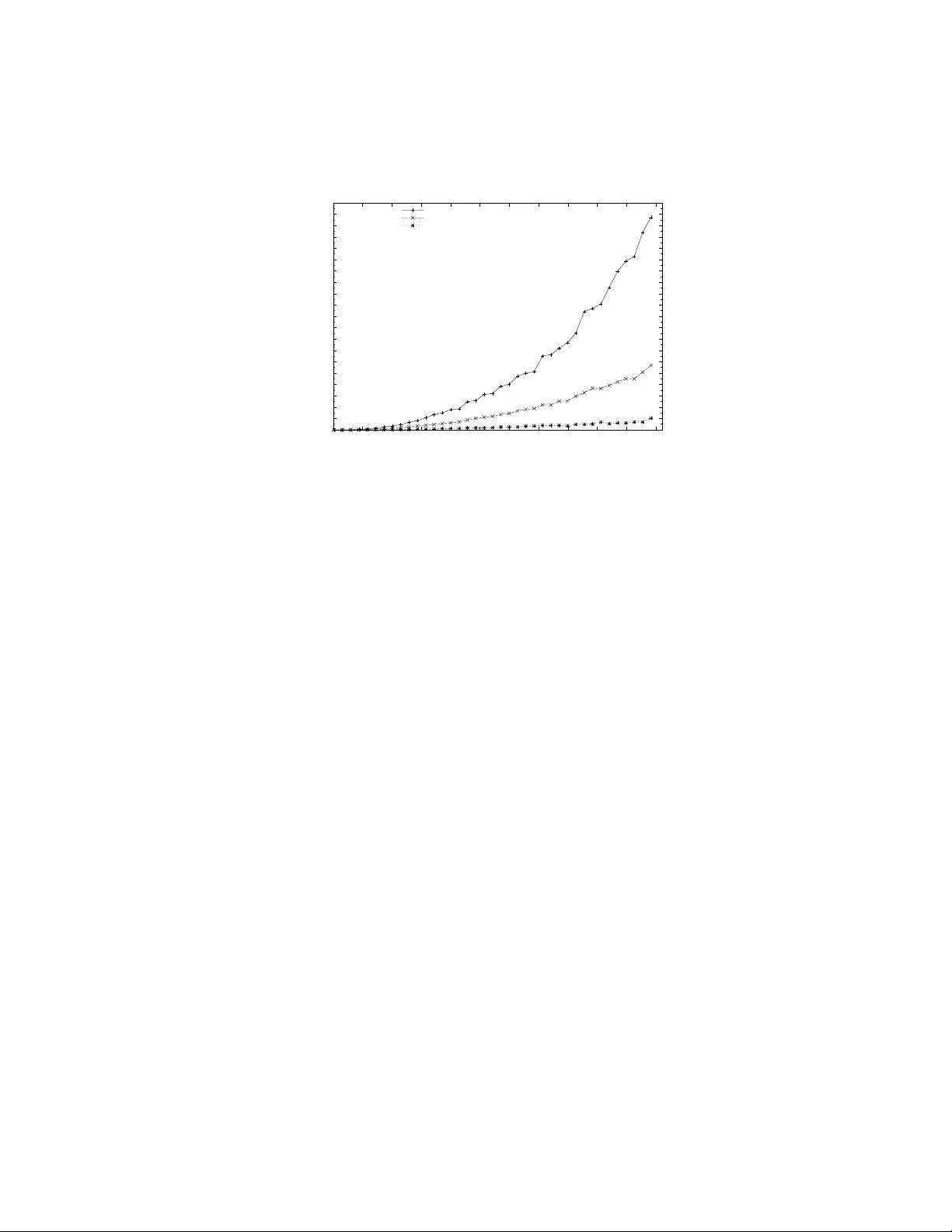
본 논문은 실시간 P2P 라이브 스트리밍 시스템에서 중앙 노드가 수천 명의 피어를 서로 연결하기 위해 매 순간 LSAP(Linear Sum Assignment Problem)를 해결해야 하는 상황을 배경으로 한다. 기존의 Hungarian 알고리즘이나 경매(Auction) 알고리즘은 최적 해를 제공하지만, 문제 규모가 수천에서 수만에 달할 경우 수시간이 소요돼 실시간 서비스에 부적합하다. 이에 저자들은 최적성을 약간 포기하고 계산 시간을 크게 단축시키는 휴리스틱인 Deep Greedy Switching(DGS)을 선택하였다. DGS는 초기 무작위 매칭을 시작으로, 각 에이전트와 작업(피어) 사이의 2‑exchange 후보를 모두 평가하고, 가장 큰 비용 감소를 가져오는 교환을 수행한다. 이 과정을 더 이상 개선이 불가능할 때까지 반복한다. DGS는 최적 해와의 평균 차이가 0.6% 이하이며, 중간에 연산을 중단해도 현재까지 얻은 매칭을 바로 사용할 수 있다는 장점이 있다.
GPU 구현을 위해 저자들은 NVIDIA의 CUDA 플랫폼을 채택하였다. CUDA는 호스트(CPU)와 디바이스(GPU)로 구성된 프로그래밍 모델을 제공하며, 스레드 블록과 그리드 단위로 병렬 작업을 정의한다. 논문에서는 CUDA의 기본 구조와 메모리 계층(전역(Global) 메모리, 공유(Shared) 메모리, 레지스터)을 상세히 설명하고, DGS 알고리즘을 효율적으로 매핑하기 위한 설계 결정을 제시한다.
핵심 병렬화 단계는 ‘Difference Evaluation’이다. 이 단계에서는 모든 에이전트와 작업에 대해 독립적으로 2‑exchange 이득을 계산한다. 저자들은 두 가지 구현을 시도하였다. 첫 번째는 전역 메모리만 사용해 전체 비용 행렬 Aij와 현재 매칭 정보를 GPU에 복사하고, 각 에이전트당 하나의 스레드가 해당 에이전트의 모든 교환을 순차적으로 평가한다. 이 방식은 구현이 간단하지만 메모리 접근 지연이 크게 발생한다. 두 번째는 공유 메모리를 활용해, 각 2‑exchange 평가마다 필요한 Aij 원소와 매칭 정보를 블록 내 공유 메모리로 로드한다. 스레드당 하나의 교환을 동시에 평가함으로써 메모리 대역폭을 최대로 활용한다. 실험 결과, 공유 메모리 버전이 전역 메모리 버전 대비 평균 2.5배, CPU 단일 스레드 대비 12배 이상의 속도 향상을 보였다.
실험 환경은 2.4 GHz Core 2 Duo CPU와 4 GB DDR3 메모리를 탑재한 시스템에 NVIDIA GTX 295 GPU(30 SM, 240 SP, 1 GB DDR5) 를 장착하였다. 스레드 블록 크기는 메모리 사용 여부에 따라 256(전역)과 16(공유)으로 설정하였다. 테스트는 GEOM 유형의 밀집 인스턴스를 사용했으며, 문제 규모는 1 000, 2 000, …, 6 000까지 다양하게 구성하였다. 결과는 차이 평가 단계가 전체 실행 시간의 약 70%를 차지함을 확인했으며, GPU‑Shared 메모리 구현이 가장 높은 성능을 제공한다는 것을 보여준다. 또한, 최적 해와의 평균 비용 차이는 0.6% 이하로, 실시간 서비스에서 허용 가능한 수준임을 입증하였다.
논문의 주요 기여는 다음과 같다. 첫째, DGS 알고리즘을 GPU에 효율적으로 이식하기 위한 설계 원칙과 구현 과정을 상세히 기술함으로써, 유사 문제에 대한 GPU 적용 가이드를 제공한다. 둘째, 전역 메모리와 공유 메모리 두 가지 접근법을 비교 분석하여, 메모리 계층 구조가 성능에 미치는 영향을 실증한다. 셋째, CPU 기반 DGS와 GPU 기반 경매 알고리즘과의 비교 실험을 통해, 실시간 제약이 있는 대규모 LSAP에서 휴리스틱 기반 GPU 솔버가 최적화 솔버보다 현저히 우수함을 증명한다.
한계점으로는 비용 행렬 Aij가 GPU 메모리에 완전히 적재될 수 있어야 한다는 점과, 현재 구현이 정적 비용 행렬을 전제로 하여 동적 비용 업데이트가 빈번한 상황에서는 추가적인 동기화 비용이 발생할 수 있다는 점을 꼽는다. 향후 연구에서는 (1) 스트리밍 방식의 비용 업데이트를 지원하는 비동기 알고리즘 설계, (2) 멀티‑GPU 환경을 활용한 스케일링, (3) 다른 휴리스틱(예: Local Search, Genetic Algorithm)과의 하이브리드 결합을 통한 품질‑속도 트레이드오프 개선을 목표로 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기