No Strong Parallel Repetition with Entangled and Non-signaling Provers
We consider one-round games between a classical verifier and two provers. One of the main questions in this area is the \emph{parallel repetition question}: If the game is played $\ell$ times in parallel, does the maximum winning probability decay ex…
Authors: Julia Kempe, Oded Regev
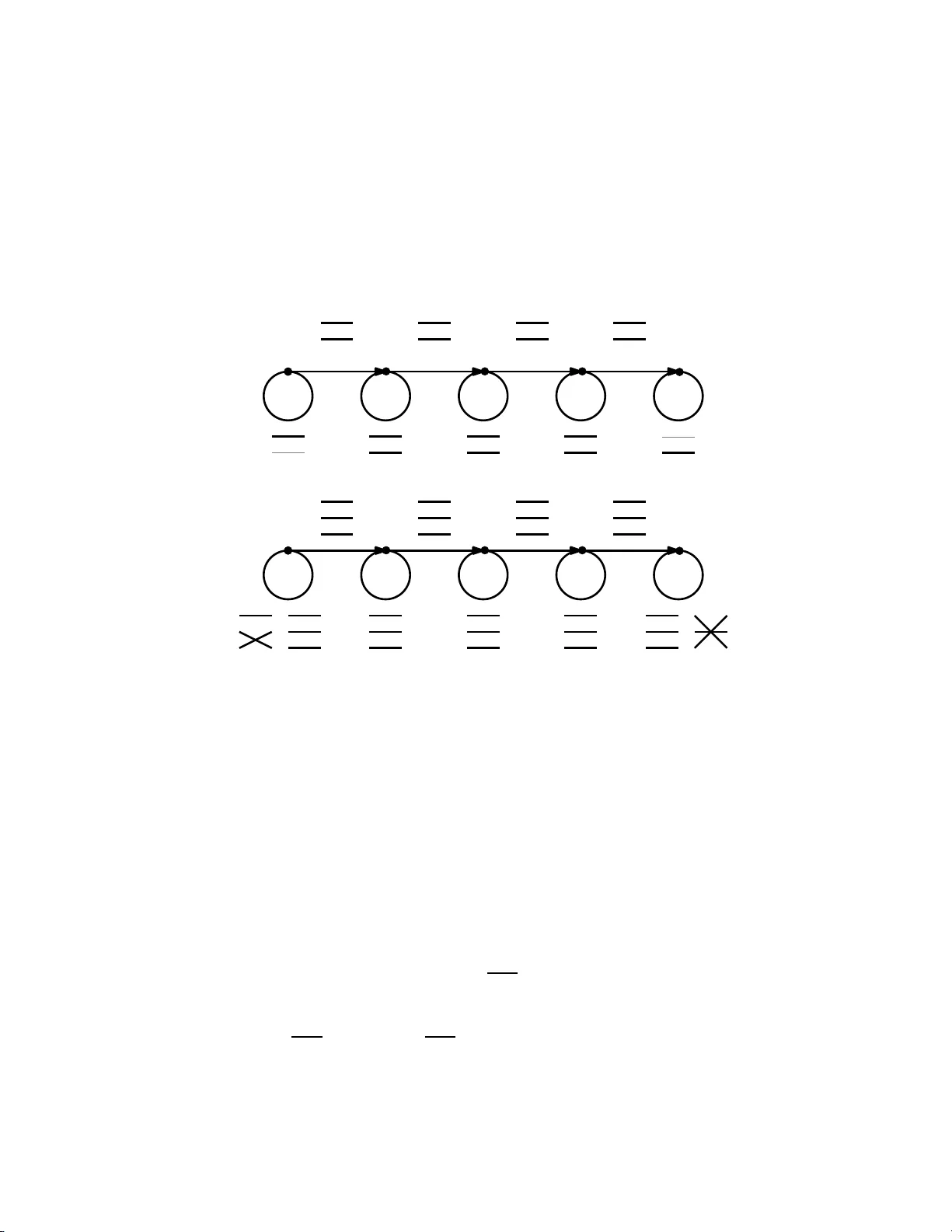
No Strong Parallel Repetition with Ent angled an d Non-sign aling Provers Julia Kempe ∗ Oded Regev † Abstract W e consider one-r ound games between a classical verifier a nd two provers. One of the main questions in this area is the parallel repetition q uestion : If the game is played ℓ times in parallel, does the maximum winning probability deca y exponentially in ℓ ? In the classical setting, this question was answered in the affirmative by Raz. More recently the question a rose whether the decay is of the form ( 1 − Θ ( ε ) ) ℓ where 1 − ε is the value of the game a nd ℓ is the number of repetitions. This question is known as the st rong p arallel repetition question and wa s motivated by its connections to the unique ga mes conjecture. It wa s resolved by Raz who showed tha t strong para llel repetition d oes not hold, even in the very special case of games known as XOR games. This opens the question whether strong parallel repetition holds in the ca se when the provers share entanglement. Evidence for this is provided by the behavior of XOR ga mes, which have strong (in fa ct perfect ) para llel repetition, and by the recently proved strong par- allel repetition of linear unique ga mes. A similar question was open f or games with so-ca lled non-signaling provers. Here the best known parallel repetition theorem is due to Holenstein, and is of the form ( 1 − Θ ( ε 2 ) ) ℓ . W e show tha t strong parallel repetition holds neither with entangled provers nor with non- signaling p rovers. In p articular we obtain that Holenstein’s bound is tight. Along the way we also provide a tight chara cterization of the asymptotic behavior of the entangled value under parallel repetition of unique games in ter ms of a semidefinite program. ∗ Blavatnik School of Computer Science, T el A viv University , T el A viv 69978, Isr ael. Supported by the European Commission under the Integrated Project Qubit Applications (QAP) funded by the IST directorate as Contract Number 015848 , by an Alon F ellowship of the Is r aeli Higher Council of Academic Research, by an Individual Research Grant of the Israeli Science Foundation, by a E uropean Re search Council (ERC) Starting Gr ant and by a Raymond and Beverl y Sackler Career Develop m e nt Chair . † Blavatnik School of Computer Science, T el A viv University , T el A viv 69978, Is rael. Supported by the Binational Science Foundation, by the Is r ael Science Foundation, by the European Commission under the Integrated Project Q AP funded by the IST directorate as Co ntract Number 015848 , and by a European Research Council (E RC) Starting Grant. 1 1 Introduction Games: T wo-prover games p lay a major role both in theoretical computer s cience, where the y led to many breakthroughs such as the discovery of tight inappr oximabili ty results [H ˚ as01], and in quantum phys ics, where already for more than half a century they are used as a way to unders t and and experimentally verify quantum mechanics. In such games, a verifier (or r eferee) choose s two questions , and s ends one qu e stion t o each of two non-communicating and computationally unbounded p rovers (or players) who then respond with answers taken from { 1, . . . , k } for some k ≥ 1. The verifier decides whet her to accept (or in other words, wheth e r th e players win the game). The quest ion we ask is: given the verifier ’s be havior as spe cified by the g ame, what is the maximum winning probabil ity of the provers? It turns out that the answer to this question depends on the e xact power we give to the provers. In the mode l most commonly u s ed in t h e oretical compu ter science (the classical model), the provers are simply deterministic functions of their inputs. W e call the maximum winning probab ility in this case the (classical) value of the game and de note it by ω . W e could also allow the provers to share randomness, but it is easy to see that this cannot increase their winning probabil- ity . Cons ide r , for ins t ance, the CHSH g ame [CHSH69]: Here the verifier choos es t wo random bits x and y , and sends one to each prover; he then receives as an answ e r one bit from each prover (so k = 2 here), call them a and b . The verifier accepts if f a ⊕ b = x ∧ y . It is no t hard t o see that the value of this game is ω ( C H S H ) = 3/4. The second mode l we consider is that of entangled pro vers in which the t wo provers, w h o still cannot communicate, are allowed to use shared entanglement. The se g ames, which are s ometimes called nonlocal games in the physics literature, have their origins in the s eminal papers by Einst ein, Podolsky , and Rose n [EPR35] and Bell [Bel64]. W e d e fine the entangled value of a game as t he maximum succes s probabil ity achievable by provers that s har e entanglement, and denot e it by ω ∗ . Notice that by de finition, for any g ame we have ω ∗ ≥ ω . One of th e most ast onishing features of quantum mechanics is that sharing entanglement gives the p rovers t he remarkabl e ability to create correla tions that ar e impossible to obtain classically , and hence increase t heir winning probabil ity . For inst ance, it can be shown that ω ∗ ( C H S H ) = ( 2 + √ 2 ) / 4 ≈ 0.85. This gap bet ween the classical val ue and the entangled value has fascinated physicists for decades, and is used as an experimental way to validate quantum mechanics. Another example of such a gap appears in the so-called odd-cycle game , in which, roughly sp e aking, the provers ar e asked to color t he vertices of a cycle of length n for s o me odd n ≥ 1 with two colors in such a way that the two colors adjacent to each e dge ar e dif ferent. The value of t h is game is 1 − 1/ 2 n , whereas its entangled value is 1 − Θ ( 1/ n 2 ) . The third model we conside r in this paper is that of non-signaling pro vers . This mod el is of in- terest mainly as a t h e oretical tool to unde rstand the other two models (see, e .g., [IKM09, T on09]), as well as two-prover games in g e neral phy s ical theor ies [LPS W07] (see also [BBL + 06]). H ere, the pr overs can choose for any ques tion pair an arbitrary distribution on t he answ ers, with the only constraint being the non-signaling constrai nt — namely , that the marginal distribution of each prover ’s answer must only depe nd on th e que stion to that prover (and not on the other prover ’s question). This constraint captures th e phys ical requir ement that the p rovers are unable to com- 2 municate, and leads t o the de finition o f the non-signaling value o f a game, which we deno te by ω ns . Notice that for any game, ω ns ≥ ω ∗ ≥ ω . For instance, it is not hard to se e that ω ns ( C H S H ) = 1, since we can arrange the distributions on th e answers in such a way that the marginal distributions ar e always uniform, and at the s ame time only winning answers are returned. An important special case of two -prover games is that of u nique games . Here, the verifier ’s decision is restricted to be o f the fo r m b = σ ( a ) for some permutation σ on [ k ] . I f, moreover , k = 2, the n the game is called an X OR game . An example of such a game is t he CHSH game. It is very common for the answer set [ k ] in a unique game to be identified with some group structure (e.g., Z k ) and for the verifier to check whe ther the dif ference of the two answers a − b is equal to some value. If this is the case, then we refer to the g ame as a linear game . In recent years, unique games became one of the most heavily stud ied topics in theoretical comput er science due to Khot’s unique g ames conje cture [Kho02] and its strong implications for hardness of approximation (see, e.g., [KKMO07]). Parallel repet ition: One of the main questions in the ar ea of two -prover games is t he parallel r epetit ion question . He re we conside r the game G ℓ obtained by playing t he game G in parallel ℓ times . Mor e precisely , in G ℓ the verifier sends ℓ independe ntly chosen ques tion pairs to the provers, and expects as answers elemen t s of [ k ] ℓ . He accepts if f all ℓ answe r s are accepted in the o riginal g ame. It is easy to see t hat ω ( G ℓ ) ≥ ω ( G ) ℓ since the provers can play their optimal strategy for G on e ach of the ℓ que stion pairs. S imilarly , ω ∗ ( G ℓ ) ≥ ω ∗ ( G ) ℓ and ω ns ( G ℓ ) ≥ ω ns ( G ) ℓ . Although at first it might seem that equality sho uld hold he re, the surprising fact is t hat in mos t cases the inequality is st rict. E ven for a simple game like CHSH w e have that ω ( C H S H 2 ) = 5/8 (which is bigger than the 9 / 16 one might exp ect). The parallel repetition question asks for upp er bound s on the value of repeated games. This fundamental question has many important implications, most notably to t ight hardness of approx- imabil ity results (e.g., [H ˚ as01]). The first dramatic progr ess in this area was made by Raz [Raz98 ], with mor e recent work by Holenst ein [Hol07] and Rao [Rao08]. The following theorem s umma- rizes the state of the art in this ar ea. Theorem 1.1. Let G be a two-pr over game with answer size k and value ω ( G ) = 1 − ε . Then for all ℓ ≥ 1 , 1. [Hol07] ω ( G ℓ ) ≤ ( 1 − ε 3 ) Ω ( ℓ / l og k ) ; 2. [Rao08] If G is a pr ojection game (which is a more general class than un ique games) then ω ( G ℓ ) ≤ ( 1 − ε 2 ) Ω ( ℓ ) . In an att empt to better underst and the unique games conjecture, Feige, Kindler , and O’Donnell [FKO07] asked wheth e r the bound on ω ( G ℓ ) above can be improved t o ( 1 − ε ) Ω ( ℓ ) , a result called str ong parall el re petitio n . Given t he improved boun d by Rao, it is only natural to hope that the exponent could be lowered all the way down to 1. They observed that if such a result holds, even just for unique games, the n we would get an equivalence of the unique games conjecture to other better studied problems like MAX -CUT . Somewhat surprisingly , Raz [Raz08] showed that strong parallel repetition does not hold in general. He s howed an example of an XOR game (which is no other th an the odd -cycle g ame 3 mentioned above) who se value is 1 − 1/ 2 n y e t even after n 2 repetitions, its value is still at least some pos itive constant. Raz’s example was further clarified and generalized in [BHH + 08] by showing a conne ction between ω ( G ℓ ) and the value of a certain S DP relaxation of the game. W e mention that strong parallel repetition is known to hold in t he case of p rojection games t hat are fr ee , i.e. , the dist ribution o n the questions t o the provers is a product distribution [BRR + 09]. See also [AKK + 08] for an “almost strong” parallel repetition statement for unique games played on expander graphs. Parallel repetition is much less w ell under s tood in the case of entangled provers. In fact, no parallel r epetition result is kno w n for the entangled value of general g ames, and this is currently one of the main open ques tions in the ar e a. However , parallel repetition r esults are known for several classes of g ames with entangled p rovers, as de scribed in the fo llowing theorem, in which we also mention Holenst ein’s [Hol07] p arallel r epetition result for t he non-signaling value. Theorem 1.2. Let G be a two-pr over game with answer size k, entangled value ω ∗ ( G ) = 1 − ε ∗ , and non-signaling value ω ns ( G ) = 1 − ε ns . Then for all ℓ ≥ 1 , 1. [CSUU07] If G is an XOR game, then ω ∗ ( G ℓ ) = ( 1 − ε ∗ ) ℓ ; 2. [KR T08] If G is a un iqu e game, then ω ∗ ( G ℓ ) ≤ ( 1 − ( ε ∗ ) 2 16 ) ℓ ; 3. [KR T08] If G is a linear game, then ω ∗ ( G ℓ ) ≤ ( 1 − ε ∗ 4 ) ℓ ; 4. [Hol07] ω ns ( G ℓ ) ≤ ( 1 − ( ε ns ) 2 ) Ω ( ℓ ) . Hence, we see that strong parallel repetition holds for the entangled value of linear games. In fact, in the case of XOR games , we have perfect parallel repetition. All the above results involving the e ntangled value are d erived by (i) showing that ω ∗ is close (or in fact equal in the case o f X OR games) to a certain SDP relaxation (which appears as SDP1 below), and (ii) showing that t his SDP relaxation “tensorizes”, i.e., that the value of the SDP cor- responding to G ℓ is exactly the ℓ th powe r of the value of the SDP corresponding to G . The above naturally raises the ques tion of whether the entangled value obe y s strong parallel repetition, if not in the general case, th e n at least in the case of unique games. The nearly tight characterization of the entangled value of u n ique games using semidefinite programs [KRT08 ] (see Lemma 2.6 below) is one reason to hop e that such a strong parallel r epetition wo uld hold. Raz’s counterexample do es not provide a negative answer t o this quest ion, since it is an X OR game, for which pe r fe ct parallel r epetition holds in the entangled case. Similarly , in the case of non-signaling provers t here has bee n no evidence that s trong p arallel repetition do es not hold. In fact, because the non-signaling value is exactly given by a linear program (LP) (se e, e.g ., [T on09]), one might conjecture that strong parallel r epetition s h o uld hold since “all” one has to do is und erstand th e tensorization properties of the cor respond ing LP . Our results: W e answe r the above question in the ne gative, by giving a counte rexample to s t rong parallel repetition for games with entangled provers. Mor e precisely , we give a game with entan- gled value 1 − Ω ( 1/ n ) such that after n 2 repetitions the entang led value of the repeated game is 4 still a positive constant. Our ex ample (after a minor modification) is a unique game with three possible answers , the smallest poss ible alphabet size for such a counte rexample, because unique games with two answers are by definition XOR games for which perfect parallel repetition holds. Hence we obtain an interesting ‘phase transition’ in the entangled value of unique games: whereas for alphabet size 2 we have perfect p arallel repetition, already for alphabet s ize 3 we do n o t even have strong parallel r epetition. Our result shows that t he u pper boun d for unique games in The- orem 1.2.2 is e ssentially tight. W e also s how that our game has a non-signaling value of 1 − Ω ( 1/ n ) . This implies that strong parallel r epetition fails also for the no n-signaling value and that Ho lenstein’s r esult (Theo - rem 1.2.4) is in fact tight. As part of th e proof we observe (see The orem 4.1) us ing results from [KR T08] th at the asymp- totic behavior of the e ntangled value of r epeated unique games is almost precisely captu red by a certain SDP (SDP1 in Se c. 2). This is a pleasing state of af fairs, since we now have a nearly tight SDP characterization both of the value of a unique g ame (SDP2 in Sec. 2) and of its asymp- totic value (SDP1). Inciden t ally , SDP1 w as also show n to characterize the asympt otic behavior of the classical value of repeated unique games, although the bounds there were considerably less tight, as they include some logarithmic factors (which are conjectured to be unn e cessary) and also depend on the alphabet size (see Le mma 2.5). Combining the above obse rvation with o ur counte rexampl e, w e obtain a separation between SDP1 and SDP2. N amely , for the game described in our counterexample, SDP2 is 1 − Θ ( 1/ n ) (since it is very close to the value of the game) whereas SDP1 is 1 − Θ ( 1/ n 2 ) (since it describes th e asymptotic behavior). B oth SDPs have been used before in the literature (e.g ., [KV05, AKK + 08, KR T08, BHH + 08]) and to t he best of our knowledge no gap betwee n them was known be fo re. Perhaps more interestingly , our e x ample also impli es that SDP2 does not tensorize, s ince for the basic game S DP2 is 1 − Θ ( 1/ n ) ye t after n 2 repetition its value is still some positive constant (since it is a relaxation o f the entangled value). Our construction: Our counterexample is inspired by the odd -cycle game (yet it is neither a cycle nor is it odd). W e call it the line game . Recall t hat the odd-cycle g ame was used by Raz [Raz08] as a counterexample to s trong parallel r epetition in the classical case. However , since it is an XOR game, it obeys pe rfect parallel r epetition in t he entangled case, and mor eover , its non-signaling value is 1, so it cannot provide a counterexample in our setting. Roughly s peaking, in the line game t h e players are asked t o color a p ath of length n with two colors in such a way t hat any t wo adjacent vertices have the same color , ye t the leftmost vertex must be color ed in color 1 and th e rightmost verte x must be colored with color 2 (see Fig. 1a). More precisely , the verifier randomly choo ses to send to the provers either two adjacent vertices or the same tw o vertices. He expects the t w o answers to be t he same, unless both vertices are the leftmost ve r t ex, in which case both answers must be 1, or both vertices are the rightmost vertex, in which case both answers must be 2. It is not hard to se e that t he classical value of this game is 1 − Θ ( 1 n ) , as is the case for the o d d- cycle game. However , unlike the o dd-cycle game, it t urns out that the entangled value and e ve n the non-sign aling value of th is game are also 1 − Θ ( 1 n ) . An intuitive way to see this is to argue 5 about t he mar ginals on Alice’s and Bo b’s answe r to each quest ion. Forcing the ends of the line into a fixed answer forces th e corresponding mar ginals to be close to distributions th at always output 1 on the left and 2 on the right. The marginals for que s tions in between t he en d s must therefor e move fr om the all-1 to the all-2 distr ibution, which can only be done at the expe nse of losing with probab ility Ω ( 1/ n ) . For comparison, in the odd-cycle game we can manage w ith a strate g y whe re all mar ginals are uniform, and hence its non-signaling value is actually e xactly 1! As we will show in Section 4, after repeating t he line game n 2 times, its ent angled value (and even classical value) are still bounded from below by some positive const ant. In particular , this im- plies that strong parallel repetition d oes n o t hold for the entangled value nor fo r the non-signaling value. This lower bound can be sho wn dir ectly by exp licitly demonstrating the provers’ strate gy . Instead, we will follow a slightly indir ect route, using SDP1 to ar g ue about the behavior of t he game (or in fact of its unique game variant described below) unde r parallel repetition, as we feel this gives more insight into t h e be h avior of parallel repetition o f unique games. As described above, the line game is not a u nique game, d ue to the no n -p e rmutation con- straints on both e n d s. I n order to pr ovide a counte rexampl e for strong parallel r epetition even for unique games, we present a simple modification o f the game t hat leads t o wh at we call the unique line game . Roughly speaking, this is do ne by incr easing the ans w er s ize to 3, replacing the constraint on the leftmost vertex with a p e rmutation that switches 2 and 3, and s imilarly replacing the constraint o n the rightmost vertex with a p ermutation that switche s 1 and 3. This has a similar eff ect to the non-permutation constraints in the original line game, and as a r esult, the classical , entangled, and non-signaling values of this game are more or less th e s ame as in the line g ame, both for the basic game and its repetition. 2 Preliminaries Games: W e st udy one-r ound two-prov er cooperati ve games of incomplete information , also k n o wn in the quantum information literatur e as nonlocal games . In such a game, a referee (also called the verifier) interacts with two provers, Alice and Bob, w h o se joint goal is to maximize t he proba bility that the ver ifier output s ACCEPT . In more detail, we r epresent a game G as a distribution over triples ( s , t , π ) where s and t are element s of some ques tion set Q , and π : [ k ] × [ k ] → { 0, 1 } is a predicate o ver pairs of answers take n from some alphabet [ k ] . The game des cribed by such a G is as follows. • The verifier samples ( s , t , π ) accor ding to G . • He s e nds s t o Alice and receives an answer a ∈ [ k ] . • He s e nds t t o Bob and receives an answer b ∈ [ k ] . • He th e n accepts if f π ( a , b ) = 1. This d efinition o f games is the one us ed by [BHH + 08] and is slightly more general than the one commonly used in the literature, which requir e s that each pair ( s , t ) is associated with exactly one predicate π . Our d efinition allows t he verifier to associate more th an one p redicate π (in fact, 6 a distribution over predicates) to each que s tion pair ( s , t ) . Such games ar e somet imes k n o wn as games w ith probabili stic predicates. W e use this definition mostly for convenience, since as we shall s e e later , our counte rexam ples either do no t use probab ilistic predica tes, or can be modified to avoid the m (but see Re mark 3.6 for o ne instance in wh ich p roba bilistic p redicates are p rovably necessary). Moreover , the results in [CSUU07, KR T08, BHH + 08] hold for g ames with p robabilistic predicates, and t his is in particular true for Lemmas 2.3, 2.4, and 2.6, which w e nee d for our construction. Finally , Raz [Raz98] briefly d iscusses how to extend his parallel repetition theorem to games with probab ilistic predicates, whereas the results in [Hol07, Rao08] most likely also extend to this case, although th is remains to be verified; in any case, these results are not need ed for our construction. W e define t he (classical) value of a game, denot e d by ω ( G ) , to be the maximum probabili ty with which the provers can win the game, assuming they behave classically , namely , the y are simply functions from Q to [ k ] . W e can also allow the provers to share randomness, but it is easy to se e that this do es not incr ease their winning probabili ty . W e define t he entangled value of a game, ω ∗ ( G ) , to be the maximum winning probability assuming the provers are allowed to share ent anglement. The precise definition of entangled strategies can be found in, e.g., [KR T08], but will not be neede d in this paper . W e ess entially just have to know that the entangled value is bounded from above by the non-signaling value , which is define d as follows. Definition 2.1. A non-signaling stra tegy for a game G is a set of pr obabilit y distri butions { p s , t } over [ k ] × [ k ] for all s , t ∈ Q such that ∀ s , s ′ , t , t ′ ∈ Q A s , t = A s , t ′ = : A s and B s , t = B s ′ , t = : B t , wher e A s , t ( a ) , B s , t ( b ) ar e the mar ginals of p s , t on the first and second answer r espe ctively . The n on - signaling value of the game is ω ns ( G ) = max Exp ( s , t , π ) ∼ G h k ∑ a , b = 1 p s , t ( a , b ) π ( a , b ) i wher e the maximum is taken over all non-signaling strategi es { p s , t } . Definition 2.2. A game is called unique if the third component of the triples ( s , t , π ) is always a permuta- tion constraint, n amely , it is 1 iff σ ( a ) = b for some permutation σ . We will sometimes think of such games as distributions over triples ( s , t , σ ) . Furthermor e, a unique game is called linear if we can identify [ k ] with some Abelian gr oup of size k and the third component of ( s , t , σ ) is always of the form σ ( a ) = a + r for some element r of the group. Parallel Repetition: Given a game G 1 with quest ions Q 1 and answers in [ k 1 ] and the g ame G 2 with quest ions Q 2 and answers in [ k 2 ] , we d e fine t he pr oduct G 1 × G 2 to be a game with que s tions Q 1 × Q 2 and answers in [ k 1 ] × [ k 2 ] define d by the distribution obtained by s ampling ( s 1 , t 1 , π 1 ) fr om G 1 and ( s 2 , t 2 , π 2 ) from G 2 and output ting ( ( s 1 , s 2 ) , ( t 1 , t 2 ) , π 1 × π 2 ) where π 1 × π 2 : [ k ] 2 × [ k ] 2 → { 0, 1 } is given by ( π 1 × π 2 ) ( ( a 1 , a 2 ) , ( b 1 , b 2 ) ) = π 1 ( a 1 , b 1 ) π 2 ( a 2 , b 2 ) . W e d enote the ℓ -fold product o f G with itself by G ℓ . Clearly , ω ( G ℓ ) ≥ ω ( G ) ℓ and simila rly for ω ∗ and ω ns , since the p rovers can play each instance of t he game independently , using an 7 optimal s trategy . Parallel r epetition t h e orems attempt to provide upper bounds on the value of repeated games . It is oft e n convenient to s p eak about the amortized value of a game, de fin e d as ω ( G ) = lim ℓ → ∞ ω ( G ℓ ) 1 ℓ ≥ ω ( G ) , and similarly for ω ∗ ( G ) and ω ns ( G ) . SDP Relaxations: Th e main S DP relaxation we consider in this paper is SDP1 , which is d efined for any game G . The maximiza tion is over the real vectors { u s a } , { v t b } . SDP 1 Maximize : Exp ( s , t , π ) ∼ G ∑ ab π ( a , b ) u s a , v t b Subject to: ∀ s , ∀ a 6 = b , u s a , u s b = 0 and ∀ t , ∀ a 6 = b , v t a , v t b = 0 ∀ s , ∑ a h u s a , u s a i = 1 and ∀ t , ∑ b v t b , v t b = 1 It follows from The o rem 5.5 and R emark 5.8 of [KR T08] that SDP1 has the tens orization prop- erty . Lemma 2.3. For any game G and any ℓ ≥ 1 , ω S D P 1 ( G ℓ ) = ( ω S D P 1 ( G ) ) ℓ , wher e ω S D P 1 denotes the optimum value of S D P 1 for a particular game. The proof of th is lemma is based on ideas from [FL92, MS07]. Ignoring some subtle issue s, the esse n t ial reason t hat L emma 2.3 holds is because SDP1 is bipartite , i.e. , its goal function only involves inner products between u variables and v variab les, and its constraints ar e all equality constraints and involve either only u variables o r only v variabl es (see [KR T 08] for details). The value o f S DP1 is an upper bound for t he e ntangled value of the game, and in [KRT08] it is shown that its value is not too far from the entangled value of un ique g ames. Lemma 2.4 ([KRT08]) . Let G be a unique game w ith ω S D P 1 ( G ) = 1 − δ . Then 1 − 8 √ δ ≤ ω ∗ ( G ) ≤ 1 − δ . Moreover , in a recent result by Barak et al. [BHH + 08] it w as s hown t hat SDP1 e ssentially characterizes the amortized (classical ) value of unique games, up to a factor that depend s on the alphabet size and logarithmic corrections. Lemma 2.5 ([BHH + 08]) . For any un ique game G with ω S D P 1 ( G ) = 1 − δ and ℓ ≥ 1 , ω ( G ℓ ) ≥ 1 − O ( p ℓ δ log ( k / δ ) ) , and m or eove r , 1 − O ( δ log ( k / δ ) ) ≤ ω ( G ℓ ) ≤ 1 − δ . SDP 2 Maximize : Exp ( s , t , π ) ∼ G ∑ ab π ( a , b ) u s a , v t b Subject to: k z k = 1 ∀ s , t , ∑ a u s a = ∑ b v t b = z ∀ s , t , ∀ a 6 = b , u s a , u s b = 0 and v t a , v t b = 0 ∀ s , t , a , b , u s a , v t b ≥ 0 W e now conside r SDP2. Not ice the e xtra variabl e z , the extra non-ne gativity constraints, and the extra z constraints. W e clearl y have that for any game G , ω S D P 2 ( G ) ≤ ω S D P 1 ( G ) . Y et, as mentioned in [KR T08], SDP2 still provi des an upp er bound o n the entangled value. Moreover , for unique games, this upper bound is almost t igh t . 8 Lemma 2.6 ([KRT0 8]) . Let G be a un ique game with ω S D P 2 ( G ) = 1 − δ . T hen 1 − 6 δ ≤ ω ∗ ( G ) ≤ 1 − δ . It was not kno w n whet her S DP2 s atisfies the tenso rization property . 3 The line game and its non-signaling value W e now de scribe and analyze our first count erexample, the line game (see Figure 1a for an illus- tration). 1 1 2 3 4 5 1 1 2 3 4 5 a) b) Figure 1: The line g ame (t o p) and the unique line game (bott om) for n = 5. Definition 3.1 (Line game) . Consider a path with vertices { 1, . . . , n } with edg es connecting any two successive nodes, as well as a loop on each vertex (so the total nu mber of edges is 2 n − 1 ). The line game G L of length n is a game w ith question set Q = [ n ] , and answer size k = 2 , in which the verifier choose s a triple ( s , t , π ) as follo ws. He first chooses an edg e with endpoints s ≤ t uniformly among the 2 n − 1 edges. The constraint π is set to be equality for all edges , excep t for the two loops at the ends, i.e., exce pt s = t = 1 or s = t = n. In the former case, the constraint π for ces a = b = 1 and in the latter case it for ces a = b = 2 . Note t hat the line g ame G L is not a unique game d ue to the non-unique constraints on both ends of the line. Theorem 3.2. ω ( G L ) = ω ∗ ( G L ) = ω ns ( G L ) = 1 − 1 2 n − 1 . Proof: F irs t , notice that the success probabil ity of th e classical s trategy in which Alice and Bob always answer 1 is 1 − 1 2 n − 1 . He nce, 1 − 1 2 n − 1 ≤ ω ( G L ) ≤ ω ∗ ( G L ) ≤ ω ns ( G L ) and it remains to bound ω ns ( G L ) from above. For this, we use t he following s imple claim. 9 Claim 3.3. For any k ≥ 1 , a , b ∈ [ k ] , an y permutation σ on [ k ] and any pr obability distr ibution p on [ k ] × [ k ] w ith marg inal distributions A ( a ) and B ( b ) , Pr ( a , b ) ∼ p [ a = σ ( b ) ] ≤ 1 − ∆ ( A , σ ( B )) , wher e ∆ ( A , σ ( B ) ) = 1 2 ∑ a ∈ [ k ] | A ( a ) − B ( σ ( a ) ) | is the total variation distance between A and σ ( B ) . More- over , for any m ar ginal distributions A and B there exists a distribution p for which equality is achieved. Proof: F o r simplicity assu me that σ is the identity permutation; the general case follows by per- muting the answers. N o te that p ( a , a ) ≤ min ( A ( a ) , B ( a ) ) = 1 2 ( A ( a ) + B ( a ) − | A ( a ) − B ( a ) | ) . Hence Pr ( a , b ) ∼ p [ a = b ] = ∑ a ∈ [ k ] p ( a , a ) ≤ 1 2 ∑ a ∈ [ k ] A ( a ) + B ( a ) − | A ( a ) − B ( a ) | = 1 − ∆ ( A , B ) . T o construct a p such that equality holds, we can simply set p ( a , a ) = min ( A ( a ) , B ( a ) ) . It is easy to see that it is pos s ible to complet e this to a probabi lity distr ibution. W e now bound the non-signaling value of G L by ar guing about the mar ginal distr ibutions of the provers’ s t rategy . Let { p s , t | s , t ∈ [ n ] } be an arbitrary non-signaling strategy , let A 1 , . . . , A n be the mar ginal distributions on Alice’s answers and B 1 , . . . , B n the marginal dist ributions for Bob, as in Def. 2.1. N ote that excep t for question pairs ( 1, 1 ) , ( n , n ) all cons t raints ar e equality cons traints. Hence, using Clai m 3.3 and deno ting the number of ed ges by m = 2 n − 1, the winning p roba bility for this strateg y is at mos t 1 − 2 m − 1 m n − 1 ∑ s = 2 ∆ ( A s , B s ) + n − 1 ∑ s = 1 ∆ ( A s , B s + 1 ) ! + 1 m ( p 1,1 ( 1, 1 ) + p n , n ( 2, 2 ) ) ≤ 1 − 2 m − 1 m ∆ ( A 1 , B n ) + 1 m ( p 1,1 ( 1, 1 ) + p n , n ( 2, 2 ) ) = 1 − 2 m + 1 m p 1,1 ( 1, 1 ) + p n , n ( 2, 2 ) − ∆ ( A 1 , B n ) , (1) where in the first inequality we use d the t r iangle inequality for tot al variation distance ∆ . W e complete the proof by noting that ∆ ( A 1 , B n ) ≥ A 1 ( 1 ) + B n ( 2 ) − 1, and recalling that by de finition A 1 ( 1 ) ≥ p 1,1 ( 1, 1 ) and B n ( 2 ) ≥ p n , n ( 2, 2 ) . In order to s how that the line game viola tes st rong parallel repetition we will modify it to a unique game G u L by increasing the alphabet size t o 3 and slightly changing the constraints. W e will short ly see that G L and G u L have ess entially t he same non-sign aling value and behave similarly under parallel repetition. Definition 3.4 (Unique line game) . C onsider a path with vertices { 1, . . . , n } w ith edges connecting any two successive n odes, as well as a loop on each vertex (so the total number of edges is 2 n − 1 ). The unique line game G u L of length n is a game with question set Q = [ n ] , and answer size k = 3 , in which the verifier chooses a triple ( s , t , σ ) as follows. He first chooses an edge with endpoints s ≤ t u niformly among 10 the 2 n − 1 edges. The permutation σ is set to be the identity for all edges, unless s = t = 1 or s = t = n. In the former case, σ is chosen to be the identity with pr obabili ty half and the permutation that switches 2 and 3 with probab ility half; in the latter case, σ is chosen to be the identity with pr obability half and the permutation that switches 1 and 3 with probabil ity half. Theorem 3.5. ω ( G u L ) = ω ∗ ( G u L ) = ω ns ( G u L ) = 1 − 1 2 ( 2 n − 1 ) . Proof: F irs t , the str ate gy that assigns answer 1 to all ques tions achieves winning proba bility 1 − 1 2 ( 2 n − 1 ) . The upp e r bound can be sho w n by repeating the proof of Thm. 3.2 with minor mod- ifications. Inst e ad, let us s how how t o obtain the upper bound as a cor ollary to T hm. 3.2. L et { p s , t | s , t ∈ [ n ] } be an arbitrary non-signaling s trategy for G u L , and cons ider the strategy obtained by mapping answer 3 to 2. More precisely , d efine { ˜ p s , t | s , t ∈ [ n ] } as the st rategy w ith alphabet size 2 define d by ˜ p s , t ( 1, 1 ) = p s , t ( 1, 1 ) , ˜ p s , t ( 1, 2 ) = p s , t ( 1, 2 ) + p s , t ( 1, 3 ) , ˜ p s , t ( 2, 1 ) = p s , t ( 2, 1 ) + p s , t ( 3, 1 ) , and ˜ p s , t ( 2, 2 ) = p s , t ( 2, 2 ) + p s , t ( 3, 2 ) + p s , t ( 2, 3 ) + p s , t ( 3, 3 ) . Then it is e asy to check t hat ˜ p is also a no n-signaling s trategy and that mor eover , its value under the game G L is at least the average between 1 and the value of p under G u L . Hence ω ns ( G u L ) ≤ 2 ω ns ( G L ) − 1, as desired. Remark 3.6. Notice that the u nique line game uses proba bilistic pr edicate s, i.e., there ar e questions (namely , the two end loops) to which mor e than one pred icate is associa ted. It is not difficult to avoid these pro babilisti c pr edicat es by r eplacing the end loops w ith small gadgets, while keeping the classical and entangled values of the game as w ell as those of the re peated game more or less the same, hence leading to a counter example to strong paralle l rep etition using unique games with deter ministic pr edica tes (namely , just add one extra vertex at each end, call it 1 ′ and n ′ and add equality constraints fr om 1 to 1 ′ and fr om 1 ′ to 1 ′ , as well as a constraint that switches 2 and 3 from 1 ′ to 1 , and analogous modification for n ′ ). However , n ote that it is impossibl e to obtain a counterexa mple to str ong parallel repe tition for the non-signaling value that is both unique and uses deterministi c pr edicates . The reas on is that any un ique game with deterministic pr edica tes has n on-signaling value 1 : simply choose for each qu estion pair ( s , t ) the distr ibution p s , t ( a , b ) = 1 k if a = σ s t ( b ) and p s , t ( a , b ) = 0 otherwise , wher e σ s t is the unique permutation associ ated with ( s , t ) . T his strateg y is n on -signaling, as all its mar ginal distributio ns ar e uniform. Hence any unique game that gives a counter example to strong para llel r epetit ion in the non-signaling case mu st u se pr obabil istic pre dicates . 4 Parallel repetition of the line game W e n o w p roceed to show that strong parallel repetition holds neither for G u L nor fo r G L . W e will show this by first provi ng a general connection for unique games between the value of SDP1 and the repeated e ntangled value of the game. W e emphasize t hat the following construction can also be presented more e xplicitly without resorting to SDPs; w e fee l, however , that the connection to SDPs gives much more insight into the nature of parallel repetition, and might also make it e asier to extend our result t o other settings. Theorem 4.1. F or any unique game G , if ω S D P 1 ( G ) = 1 − δ then (i) for all ℓ ≥ 1 we have 1 − 8 √ ℓ δ ≤ ω ∗ ( G ℓ ) ≤ ( 1 − δ ) ℓ and (ii) for all ℓ > 1 δ we have ( 1 − c δ ) ℓ ≤ ω ∗ ( G ℓ ) ≤ ( 1 − δ ) ℓ for some universal constant c > 0 . In particular , the amortized entangled value is ω ∗ ( G ) = 1 − Θ ( δ ) . 11 Compar e this to the classical case (Le mma 2.5), where we have a de p endence on the alphabet size (as w ell as an extra log factor). In the entangled case, SDP1 gives a tight estimate on the amortized entangled value up to a univers al constant. Proof: W e combine several statements from [KR T08]. By Lemma 2.3, ω S D P 1 ( G ℓ ) = ω S D P 1 ( G ) ℓ = ( 1 − δ ) ℓ ≥ 1 − ℓ δ . W e now use the quantum r ounding o f [KR T08], Lemma 2.4 to obtain an entan- gled strate gy for G ℓ with value at least 1 − 8 √ ℓ δ , showing p art (i). Part (ii) follows by partitioning the ℓ repetitions into blocks of size 1 100 δ and p laying the strateg y of (i) on e ach block independe ntly . Hence, in o rder to analyze th e repeated entangled value of G u L it suffices to analyze its SDP1 value. Lemma 4.2. ω S D P 1 ( G u L ) ≥ 1 − 2 n 2 . Proof: W e construct a solution { u s a } , { v t b } ∈ R 2 for SDP1 ( G u L ) in the following way , as illustrated in Fig. 2a. 1 1 2 3 4 5 b) a) Figure 2: T wo SDP s olutions ∀ s ∈ { 1, . . . , n } u s 1 = v s 1 = 0 cos s − 1 n − 1 π 2 ! , u s 2 = v s 2 = sin s − 1 n − 1 π 2 0 ! , u s 3 = v s 3 = 0 (2) Clearly u s a , u s b = 0 for a 6 = b and ∑ a h u s a , u s a i = 1 and similarly for the v vecto rs, so our so lution for SDP1( G u L ) is feasible . Since the u vectors are equal t o t he v vectors, it is easy t o comput e its 12 value Exp ( s , t , π ) ∼ G ∑ ab π ( a , b ) u s a , v t b = 1 2 n − 1 D u 1 1 , v 1 1 E + h u n 2 , v n 2 i + n − 1 ∑ s = 2 h u s 1 , v s 1 i + h u s 2 , v s 2 i + 1 2 n − 1 n − 1 ∑ s = 1 D u s 1 , v s + 1 1 E + D u s 2 , v s + 1 2 E = n 2 n − 1 + 1 2 n − 1 n − 1 ∑ s = 1 cos π 2 s − 1 n − 1 cos π 2 s n − 1 + sin π 2 s − 1 n − 1 sin π 2 s n − 1 = n 2 n − 1 + n − 1 2 n − 1 cos π 2 ( n − 1 ) ≥ n 2 n − 1 + n − 1 2 n − 1 ( 1 − π 2 8 ( n − 1 ) 2 ) = 1 − π 2 8 ( n − 1 ) ( 2 n − 1 ) , which proves the lemma for all n ≥ 2. Combining the above lemma with Le mma 2.4, we se e that in fact ω S D P 1 ( G u L ) = 1 − Θ ( 1 n 2 ) . Moreover , Lemma 2.6 shows that ω S D P 2 ( G u L ) = 1 − Θ ( 1 n ) . Hen ce we obtain a quadratic gap between SDP1 and SDP2. Also n o te t hat the SDP1 solution above obey s th e non-neg ativity con- straint in SDP2: th e inner products of any t wo vectors is non-negative. In fact we can modify the solution to a solution with similar value, so that it obeys the z -constraint of SDP2, at the expense of violating the non-negativity con s traint, as shown in Fig. 2b. Hence our quadratic gap also h o lds between SDP2 and the two poss ible st rengthenings of SDP1. Combining Theorem 4.1 with the above lemma, we obtain that for all ℓ ≥ n 2 , ω ∗ ( G ℓ u L ) ≥ ( 1 − O ( 1/ n 2 ) ) ℓ . In fact, the same lowe r bound also h o lds for the classical value. The reason for this is that the strategy constructed in Lemma 2.4 uses a sh ared maximally e ntangled state, and performs a measurement on it in an orthonormal basis derived fr om t he S DP vectors. Since all the vectors in the SDP solution of Lemma 4.2 are in the same ortho normal basis (and th e same is true for t he resulting SDP solut ion of G ℓ u L ), we obtain that t he s trategy constructed in Lemma 2.4 is in fact a classical st r ate gy . A final te chnical r emark is that even though we obtained the above strategy by using a tenso red SDP solution, the strategy itse lf is not a product s t rategy due to a “corr elated sampling” step performed as part of the proof of Lemma 2.4. W e summarize this discussion in the following theorem. Theorem 4.3. F or ℓ ≥ n 2 , ω ns ( G ℓ u L ) ≥ ω ∗ ( G ℓ u L ) ≥ ω ( G ℓ u L ) ≥ ( 1 − O ( 1 / n 2 ) ) ℓ . This shows that Holenstein’s p arallel r epetition for the non-signaling value (Theorem 1.2.4) as well as the parallel repetition theorem for the en t angled value o f unique games (Theorem 1.2.2) ar e both tight up to a cons t ant. 1 W e complet e this section by ext e nding the above analysis to the line game, as shown in th e following t heorem. This shows that alphabet size 2 is sufficient to obtain a counterexample to strong parallel repetition for both the entangled val ue and the non-signaling value, and in p ar - ticular shows that Theorem 1.2.4 is tight also for this case. The counterexample is not a unique game, but t his is actually necess ary: X OR games obey perfect parallel r epetition both in t erms of 1 Strictly speaking, Holenstein’s proof does not deal with probabilistic predicates, although it can most likely be extended to deal with this case [Hol09], as was done in [Raz98]. In any case, the line game (which we consider next) gives an alternative tight example for Holenstein’s theorem with determi nis tic predicates. 13 the entangled value (Thm. 1.2.1) and in terms of the non-sign aling value (even with probabi listic predicates, as is no t dif ficult to see). Theorem 4.4. F or ℓ ≥ n 2 , ω ns ( G ℓ L ) ≥ ω ∗ ( G ℓ L ) ≥ ω ( G ℓ L ) ≥ ( 1 − O ( 1 / n 2 ) ) ℓ . Proof: W e firs t observe that the classical st r ate gy for G ℓ u L constructed above has the p roperty that both provers always answ er 1 on a coordinate containing the question 1, and s imila rly , t hey always answer 2 on a coordinate containing the quest ion n . Mo reover , the provers never use the answer 3. This follows fr om the fact t hat the vectors constructed in Lemma 4.2 satisfy u 1 2 = v 1 2 = 0, u n 1 = v n 1 = 0, and fo r all s , u s 3 = v s 3 = 0. As a result, when taking t he t ensor product of these vecto r and applying L emma 2.4 (as was d o ne in The orem 4.1), w e obtain the aforementioned property o f the classical strategy . Since the strate gy d o es not use the answer 3, it is also a valid st r ate gy for G ℓ L . Moreover , it is easy to check that the winning proba bility of the strateg y in G ℓ L is equal to that in G ℓ u L ; t h is is because the strateg y always answers 1 on 1 and 2 o n n , and due to the way the games ar e constructed. Acknowledgments: W e thank Thomas Holenst ein for answe r ing ou r queries regarding his par- allel repetition t heorem, and Nisheeth V ishnoi fo r us eful d iscussions. References [AKK + 08] S. Arora, S. Khot, A. Kolla, D. Ste urer , M. T ulsiani, and N. K. V ishnoi. Unique games on expanding constraint graphs ar e easy: extend ed abstract. In Proc. 40th ACM S ymp. on Theory of Computing , pages 21–28. 2008. [BBL + 06] G. Brassard, H. Buhrman, N. Lind e n, A. A. M ´ ethot, A. T app, and F . U n g er . Limit on Nonlocality in Any World in W h ich Communication Complexity Is No t Trivial. Phys. Rev . Lett. , 96(25):250 401, 2006. [Bel64] J. S. Bell. On the Einstein-Pod o lsky-Rose n paradox. Physics , 1:195–2 00, 1964. [BHH + 08] B. Barak, M. Hardt, I. Haviv , A. Rao, O. Rege v , and D. St eurer . R ounding parallel rep- etitions of un ique games. In Proc. 49th Annual IEEE S ymp. on Foun dations of Computer Science (FOCS) , pages 374–383 . 2008. [BRR + 09] B. Barak, A. Rao, R. Raz, R. Rosen, and R. Shaltiel. Strong parallel repetition theorem for free projection games. In P roc. 13th RAND OM , p ages 352–365. 2009. [CHSH69] J. F . Clauser , M. A. Horne, A. Shimony , and R. A. Holt. Proposed experiment to tes t local hidden-variable theories . Phys. Rev . Lett. , 23:880–884, 1969. [CSUU07] R. Cleve, W . Slofstra, F . Unger , and S. U padhyay . Pe r fe ct parallel repetition theorem for quantum X OR proof systems. In Proc. 22nd IEEE Confer ence on Computational Com- plexit y , pages 109–114 . 2007. 14 [EPR35] A. Einstein, P . Pod olsky , and N. Rosen. Can quantum-mechanical de scription of phys- ical reality be cons ide red complete ? Phys. Rev . , 47:777–78 0, 1935. [FKO07] U. F eige, G. Kindler , and R. O’Donnell. Unde rstanding parallel repetition requir es underst and ing foams. In IEE E Conference on Computational Complexity , p age s 179–192 . 2007. [FL92] U. Feige and L. L ov ´ asz. T wo-prover one-round proof syste ms: The ir p ower and their problems. In Proc. 24th ACM Symp. on Theory of Computing , page s 733–741. 1992. [H ˚ as01 ] J. H ˚ astad. Some op timal inapproximabili ty results. J. AC M , 48(4):798– 859, 2001. [Hol07] T . Holens tein. Paral lel repetition: simplifications and the no-signaling case. In Pro c. 39th ACM Symp. on Theory of Computing , p ages 411–41 9. 2007 . [Hol09] T . H olenstein, 2009. P r ivate communication. [IKM09] T . It o, H. Kobayashi, and K. Matsumoto. Oracularization and t wo-prover one-round interactive proofs against nonlocal st r ate gies. In Pro c. 24th IEE E Confer ence on Compu- tational Complexity , page s 217–228 . 2009. [Kho02] S. Khot. On the p ower o f unique 2-prover 1-round games. In Proc. 34th ACM Symp. on Theory of Computing , pages 767–775. 2002. [KKMO07] S. Khot, G. Kindler , E. Mosse l, and R. O’Donnell. Optimal inapproxima bility results for max-cut and othe r 2-variable CSPs? SIAM J. C omput. , 37(1):319–3 57, 2007. [KR T08] J. Kempe, O. Rege v , and B . T one r . Unique games with entang led p rovers are easy . In Pro c. 49th IEE E Symp. on Foundations of Computer Science , pages 457–466. 2008. [KV05] S. Khot and N. K. V ishnoi. T he unique g ames conjecture, integrality g ap for cut prob- lems and embed dability of ne gative type metrics into l 1 . I n Pro c. 46th IEE E Symp. on Foundations of Computer Science , pages 53–62. 2005. [LPSW07] N. Linden, S. Popes cu, A. J. S hort, and A. W inter . Quantum N onlocality and Beyo nd: Limits from N o nlocal Compu tation. P hys. Rev . Lett. , 99(18):1 80502 , 2007. [MS07] R. Mittal and M. Szegedy . Product rules in semidefinite programming. In Pr oc. 16th Fund. Computation Theory (FCT ) , pages 435–445. 2007. [Rao08] A. R ao. Parallel r epetition in projection games and a concentration bound. In Pr oc. 40th ACM Symp. on Theory of Computing , p ages 1–10. 2008. [Raz98] R. Raz. A parallel r epetition theo rem. SIAM J. Comput. , 27(3):7 63–80 3, 1998. [Raz08] R. Raz. A count erexample to strong parallel repetition. In 49th Annual IEEE Symposium on Foundations of Computer Science , p ages 369–373. 2008. [T on09] B. T oner . Monogamy of non-local quantum correlations. Pr oc. Roy . Soc. A , 465(2 101):59 –69, 2009. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment