k-means requires exponentially many iterations even in the plane
The k-means algorithm is a well-known method for partitioning n points that lie in the d-dimensional space into k clusters. Its main features are simplicity and speed in practice. Theoretically, however, the best known upper bound on its running time…
Authors: Andrea Vattani
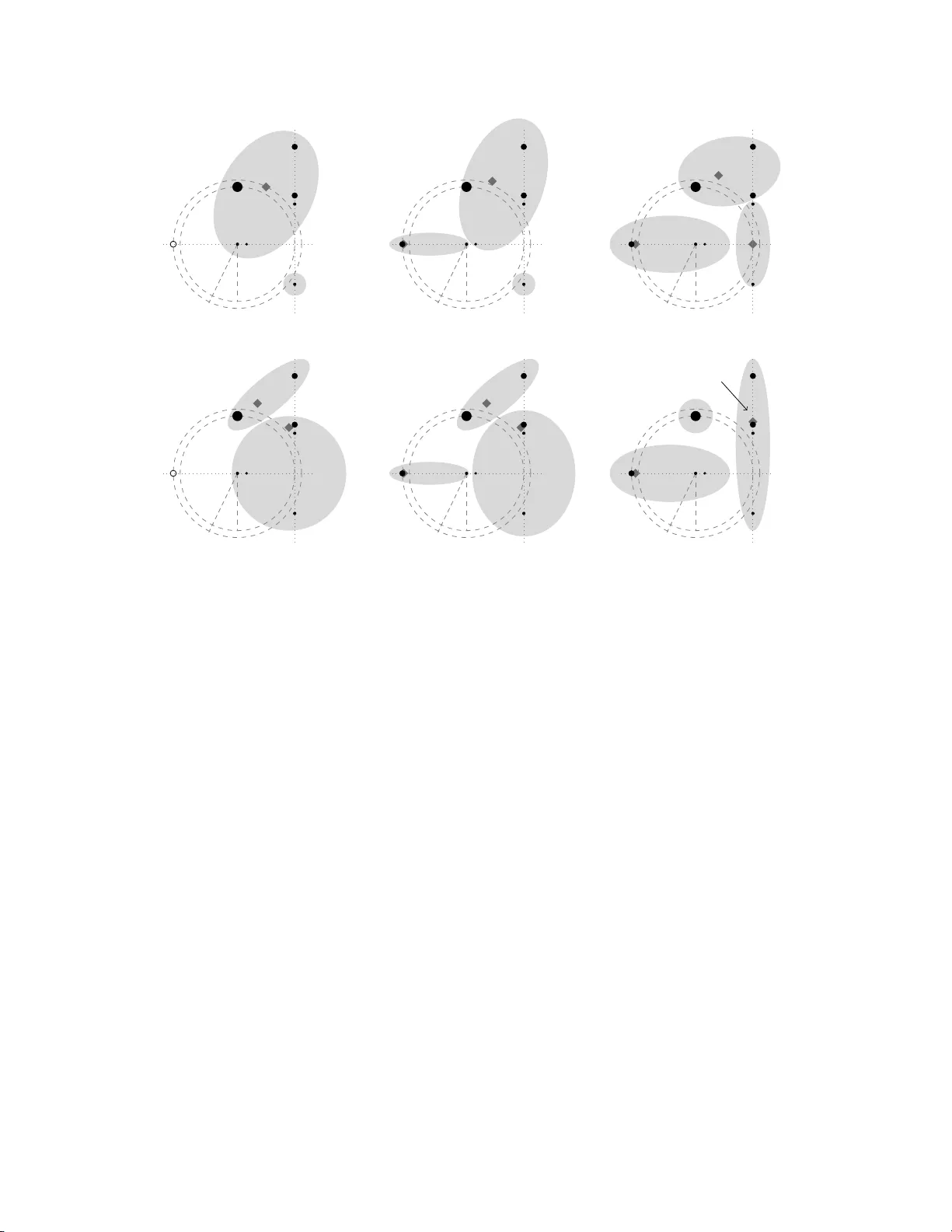
k -means requires exp onen tially man y iterations ev en in the plane Andrea V attani Univ ersity of California, San Diego avatta ni@ucs d.edu Abstract The k -means algor ithm is a w ell-known method for partitioning n po in ts that lie in the d -dimensional space into k cluster s. Its main features are simplicity and sp eed in pra ctice. Theoretically , how ever, the b est kno wn u pper bo und on its running time (i.e. O ( n kd )) can b e exp onential in the num b er of points. Recently , Arthur and V assilvitskii [2] sho wed a super- po lynomial worst-case analy s is, improving the best known low er b ound from Ω( n ) to 2 Ω( √ n ) with a construction in d = Ω( √ n ) dimensions. In [2 ] they also conjectured the existence of sup e r-p olynomial lower bounds for any d ≥ 2. Our co n tribution is tw o fo ld: we prov e this conjecture and we improve the low er b ound, by presenting a simple constructio n in the plane that leads to the exp onential low er b ound 2 Ω( n ) . 1 In tro d uction The k -means metho d is one of the most widely used a lgorithms for geometric clus tering. It was o riginally prop osed by F orgy in 1965 [7] and McQ ueen in 1 967 [13], and is often known as Lloyd’s algorithm [12]. It is a lo ca l search algorithm and partitions n data po int s into k clusters in this wa y: seeded with k initial c lus ter centers, it assigns every data point to its clos e st cen ter, and then recomputes the new cen ters as the means (or cent ers of mass) of their assigned p oints. This pro ces s of assigning da ta p oints and readjusting centers is rep eated until it stabilizes. Despite its age, k - mea ns is still very p opular to day and is considered “by far the mo st po pular clus tering algorithm used in scientific a nd industrial applications”, as Berkhin remarks in his survey on data mining [4]. Its wides pread usage extends ov er a v ar iet y of different areas, such as artificia l intelligence, computatio na l bio lo gy , c omputer graphics , just to name a few (see [1, 8]). It is par ticula rly p opular b eca us e of its simplicity a nd observed sp eed: as Duda et al. say in their text on pattern classifica tion [6], “In pr actice the num b er of itera tions is muc h les s than the num b er of s amples”. Even if, in pra ctice, speed is recognized as o ne of k -means’ main qualities (see [1 1] for empirical studies), on the o ther hand there are a few theoretical bounds on its worst-case running time and they do no t co rrob ora te this featur e. An upp e r bo und of O ( k n ) can be trivially established since it can b e s hown that no clustering o ccurs twice during the cour se of the algorithm. In [10], Inaba et al. improved this b ound to O ( n kd ) by counting the num b er of V o ronoi pa r titions of n p oints in R d int o k classe s. Other bo unds are known for some s pecia l cases . Namely , Dasgupta [5] a nalyzed the case d = 1, proving an uppe r bo und of O ( n ) when k < 5, and a worst-case lower bo und of Ω( n ). Later, Har -Peled and Sadr i [9], again for the one-dimensio nal case, showed a n upp er b ound of O ( n ∆ 2 ) whe r e ∆ is the s pread of the p oint s et (i.e. the ratio b etw een the largest and the smallest pairwise distance), and co njectured that k -means might run in time p olynomial in n and ∆ for any d . The upp er b ound O ( n kd ) for the general case has not b een improved s ince mo re than a decade, and this s uggests that it might be no t far fro m the tr uth. Arthu r a nd V as silvitskii [2] show ed that k - mea ns ca n run for sup er- po lynomially many iterations, improving the b est known low er b ound fr om Ω( n ) [5] to 2 Ω( √ n ) . Their co nt ruction lies in a space with d = Θ(log n ) dimensions, and they leave an op en q ue s tion ab out the p erformance of k -means for a sma ller nu m ber of dimensions d , conjecturing the existence o f sup e rp o lynomial lower bo unds when d > 1. Also they show that their construction ca n b e mo dified to hav e low spr e a d, disproving the a forementioned co njecture in [9] for d = Ω(lo g n ). A more recent line o f work that aims to close the gap b et w een pr actical and theoreti- cal p erformance makes use o f the smo othed a nalysis introduced by Spielman a nd T eng [15]. Arthu r and V assilvitskii [3] proved a smo othed upp er b ound o f p oly( n O ( k ) ), r ecent ly improved to p oly( n O ( √ k ) ) by Manthey and R¨ oglin [14]. 1.1 Our r esult In this work we are interested in the p erformance of k - means in a low dimensiona l space. W e said it is conjectured [2] that ther e exist instances in d dimensio ns for any d ≥ 2 , fo r which k -means runs for a sup er-p olynomia l n um b er of iteratio ns. Our main re sult is a constr uctio n in the plane ( d = 2 ) for which k -mea ns requires exp o- nent ially many iteratio ns to s tabilize. Sp ecifically , we present a set of n data p oints lying in R 2 , and a set of k = Θ( n ) a dversarially chosen cluster centers in R 2 , for which the a lgorithm runs for 2 Ω( n ) iterations. This proves the aforementioned conjecture and, at the same time, it also improv es the b est known low er b ound from 2 Ω( √ n ) to 2 Ω( n ) . Notice that the exp onent is optimal disr egarding logar ithmic facto r, since the b ound for the gene r al case O ( n kd ) ca n b e rewritten as 2 O ( n log n ) when d = 2 and k = Θ( n ). F or any k = o ( n ), our low er b ound e a sily translates to 2 Ω( k ) , which, analo gously , is almost optimal since the upper bo und is 2 O ( k log n ) . A common practice for seeding k - mea ns is to cho ose the initial ce nters as a s ubset of the data p oints. W e show that even in this ca se (i.e. cluster centers a dversarially chosen a mong the 1 data p oints), the running time of k -mea ns is still exp onential. Also, using a result in [2], our construction can be mo dified to a n instanc e in d = 3 dimensions having low spr e ad for which k -mea ns requir es 2 Ω( n ) iterations, which dispr ov es the conjecture of Har- Peled and Sadri [9] for any d ≥ 3. Finally , we observe that o ur result implies that the smoo thed analysis helps even for a small nu m ber of dimensions , since the b est smo othed upp er b ound is n O ( √ k ) , while o ur low er b ound is 2 Ω( k ) which is lar ger for k = ω (log 2 n ). In other words, per turbing each data p oint and then running k - means would improv e the p erfo r mance of the algor ithm. 2 The k -means algorithm The k -mea ns a lgorithm allows to partition a set X of n p oints in R d int o k clusters . It is seeded with any initial set of k cluster ce nters in R d , and given the cluster centers, ev e ry data po int is assigned to the cluster whose center is closer to it. The name “ k -mea ns ” refer s to the fact that the new p os ition of a c e n ter is co mputed as the center of mass (or mean p oint) of the p oints assigned to it. A for mal definition of the a lgorithm is the following: 0. Ar bitrarily choo se k initial centers c 1 , c 2 , . . . , c k . 1. F or each 1 ≤ i ≤ k , set the clus ter C i be the set of p oints in X that are clo ser to c i than to any c j with j 6 = i . 2. F or each 1 ≤ i ≤ k , set c i = 1 | C i | P x ∈ C i x , i.e the center of mass of the p oints in C i . 3. Rep ea t steps 1 and 2 until the clusters C i and the cen ter s c i do not change a n ymore. The partition o f X is the set of clusters C 1 , C 2 , . . . , C k . Note that the alg orithm might incur in tw o p ossibile “degener ate” situa tions: the firs t one is when no p o int s are ass ig ned to a center, and in this ca se that center is removed and we will obtain a partition with less than k clus ters. The o ther degenera cy is when a p oint is equally close to more than o ne c e n ter, and in this c ase the tie is broken arbitrarily . W e stres s that when k - mea ns runs on o ur co nstructions, it do es not fall in to a n y of these situations, s o the low er b ound do es not exploit these degenera cies. Our co nstruction use p oints that hav e co nstant integer weigh ts. This means that the da ta set that k - means will take in input is actually a mult iset, and the center of mass of a cluster C i (step 2 of k -means) is computed as P x ∈ C i w x x/ P x ∈ C i w x , wher e w x is the weigh t of x . This is not a restric tion since integer w eig h ts in the range [1 , C ] ca n be simulated b y blowing up the size of the data set by at mos t C : it is enough to r e pla ce each p oint x of weigh t w with a set of w distinct p oints (of unitary weigh t) who se center of mass is x , and so close each other that the b ehavior of k -means (as well a s its num ber of itera tio ns) is not a ffected. 3 Lo w er b ound In this section we pr esent a construction in the plane for whic h k -means requires 2 Ω( n ) iterations. W e sta rt with s ome high level intuition of the construction, then we g ive some definitions explaining the idea b ehind the construction, and finally we pro ceed to the for mal pro of. In the end of the se c tio n, we show a couple of ex tensions: the first one is a mo dification of our construc tio n so that the initial set of centers is a subset o f the data p oints, and the second one descr ibe s how to o btain low spread. A simple implement ation in P ython of the lower b ound is av ailable at the web address http:/ /www.c se.ucsd.edu/~avattani/k-means/lowerbound.py 2 Morning W atching W i − 1 Afternoon W atching W i − 1 Night Sleeping unt il W i +1 calls W i +1 ’s call: W i is aw oken If W i − 1 falls asleep, W i wak es it up 1st cal l If W i − 1 falls asleep, W i wak es it up 2nd call Figure 1 : The “day” of the watc hman W i , i > 0. 3.1 High lev el intuition The idea b ehind our co nstruction is simple and can b e rela ted to the saying “Who watches the watc hmen?” (or the or iginal latin phr ase “ Q uis custo diet ipsos c us tode s ?”). Consider a sequence o f t watc hmen W 0 , W 1 , . . . , W t − 1 . A “day” of a watc hman W i ( i > 0) can be describ ed a s follows (see Fig. 1 ): W i watc hes W i − 1 , waking it up o nce it falls asleep, and do es so t wice; afterwards, W i falls as leep itself. The watc hman W 0 instead will simply fall asleep directly after it ha s b een wok en up. Now if each w atchman is aw ake in the b eginning o f this pr o cess (or even just W t − 1 ), it is clear that W 0 will b e woken up 2 Ω( t ) times by the time that every watc hman is asleep. In the construction w e have a sequence o f gadgets G 0 , G 1 , . . . G t − 1 , where all gadgets G i with i > 0 are iden tical except for the scale. Any g adget G i ( i > 0) has a fixe d num b er of points and t wo centers, and different clusterings of its p oints will mo del which sta ge of the day G i is in. The clustering indicating that G i “fell asleep” has one center in a par ticular p osition S ∗ i . In the situation when G i +1 is a wak e and G i falls asleep, some points of G i +1 will be assig ned tempo rarily to the G i ’s center lo cated in S ∗ i ; in the next step this center will mov e s o tha t in one more step the initial clustering (or “mor ning clustering”) o f G i is restore d: this mo dels the fact that G i +1 wak es up G i . Note that since e a ch gadg et has a constant num b er of centers, we ca n build an instance with k clusters that ha s t = Θ( k ) gadg e ts, for whic h k -means will requir e 2 Ω( k ) iterations. Also since each gadget has a co nstant n um ber o f p oints, we can build a n insta nc e of n p oints and k = Θ( n ) clusters w ith t = Θ ( n ) g adgets. This will imply a lower bound o f 2 Ω( n ) on the running time of k -means. 3.2 Definitions and further intuition F or any i > 0, the ga dget G i is a tuple ( P i , C i , r i , R i ) whe r e P i ⊂ R 2 is the set o f p oints o f the g adget and is defined a s P i = { P i , Q i , A i , B i , C i , D i , E i } wher e the po int s hav e constant weigh ts, w hile C i is the set o f initial centers of the g adget G i and contains exac tly tw o centers. Finally , r i ∈ R + and R i ∈ R + denote r esp ectively the “inner radius” and the “outer radius” of the gadge t, and their purp os e w ill b e explained later on. Since the weigh ts of the p oints do not change b etw een the gadgets, we will denote the weigh t of P i (for any i > 0) with w P , and similarly for the other p oint s. As for the “leaf ” gadget G 0 , the set P 0 is comp osed of only one p oint F (of constant weight w F ), a nd C 0 contains only one center. The set of p oints o f the k -means istance will b e the union of the (weigh ted) p oints from all the g adgets, i.e. S t − 1 i =0 P i (with a total of 7( t − 1 ) + 1 = O ( t ) p oints of cons tant weigh t). Similarly , the set of initial centers will b e the union of the c e n ters fro m all the gadgets , that is S t − 1 i =0 C i (with a total of 2( t − 1) + 1 = O ( t ) centers). As we mentioned ab ov e, when one of the centers o f G i mov es to a sp ecial S ∗ i , it will mean that G i fell asleep. F or i > 0 we define S ∗ i as the center o f mas s of the cluster { A i , B i , C i , D i } , while S ∗ 0 coincides with F . 3 r i R i P i Q i A i B i C i D i E i S ∗ i − 1 Morning r i R i P i Q i A i B i C i D i E i S ∗ i − 1 1st Call (pt. I) r i R i P i Q i A i B i C i D i E i S ∗ i − 1 1st Call (pt. I I) r i R i P i Q i A i B i C i D i E i S ∗ i − 1 Afternoon r i R i P i Q i A i B i C i D i E i S ∗ i − 1 2nd Call (pt. I) r i R i P i Q i A i B i C i D i E i S ∗ i − 1 2nd Call (pt. I I) / Night S ∗ i Figure 2 : The “day” of the gadget G i . The diamonds denote the means o f the clusters. The lo cations of the p oints in fig ure gives an idea o f the actual gadget used in the pr o of. Also , the big ger the size o f a p oint is, the bigg er its weigh t is. F or a ga dg et G i ( i > 0), we depict the stages (clusterings ) it go es thr ough during any of its day . The entire sequence is shown in Fig. 2 . Morning This stage takes place right after G i has b een woken up or in the beg inning of the ent ire pro c e ss. The s ingleton { A i } is one cluster, and the rema ining p oints for m the other cluster. In this co nfig uration G i is watc hing G i − 1 and interv enes once it falls a sleep. 1st call Once G i − 1 falls asleep, P i will join the G i − 1 ’s cluster with cent er in S ∗ i − 1 (pt. I). A t the nex t step (pt. I I), Q i to o will join that cluster, and B i will ins tead mov e to the cluster { A i } . The tw o p o int s P i and Q i are waking up G i − 1 by causing a r estore of its morning clustering. Afternoon The p oints P i , Q i and C i will join the c lus ter { A i , B i } . Thus, G i ends up with the clusters { A i , B i , C i , P i , Q i } and { D i , E i } . In this configuratio n, G i is ag ain watc hing G i − 1 and is rea dy to wak e it up once it falls as leep. 2nd call Once G i − 1 falls asleep, similarly to the 1s t ca ll, P i will join the G i − 1 ’s cluster with center in S ∗ i − 1 (pt. I). At the next step (pt. I I), Q i to o will join that cluster , and D i will join the cluster { A i , B i , C i } (note that the other G i ’s cluster is the sing leton { E i } ). Again, P i and Q i are waking up G i − 1 . Night At this p oint, the cluster { A i , B i , C i , D i } is a lready formed, which implies that its mean is lo cated in S ∗ i : thus, G i is sleeping. How ever, note that P i and Q i are s till in some G i − 1 ’s cluster and the re ma ining p oint E i is in a singleton cluster. In the next step, concurrently with the beginning of a poss ible ca ll from G i +1 (see G i +1 ’s call, pt.I), the p oints P i and Q i will jo in the sing leton { E i } . 4 r i R i P i Q i A i B i C i D i E i P i +1 Q i +1 S ∗ i − 1 S ∗ i (1 − ǫ ) R i +1 G i ’s 2nd Call (pt. I I) / G i ’s Night r i R i P i Q i A i B i C i D i E i P i +1 Q i +1 G i +1 ’s call (pt. I) r i R i P i Q i A i B i C i D i E i P i +1 Q i +1 G i +1 ’s call (pt. I I) (1 + ǫ ′ ) r i +1 r i R i P i Q i A i B i C i D i E i P i +1 Q i +1 G i +1 ’s call (pt. I I I) / G i ’s morning Figure 3: G i +1 ’s call : how G i +1 wak es up G i . The distance b etw een the tw o gadgets is actually muc h larg er than it app ear s in figure. The tw o ra dius es of the ga dget G i ( i > 0) can b e in ter preted in the follo wing w ay . Whenever G i is watchin g G i − 1 (either mor ning o r afterno on), the distance b etw een the p oint P and its mean will b e exactly R i . On the other hand, the distance b etw een P i and S ∗ i − 1 – wher e a G i − 1 ’s mean will mov e when G i − 1 falls asleep – will b e just a bit less than R i . In this wa y we g uarantee that the waking-up pro c ess will star t at the right time. Also, we know that this pro ces s will inv olve Q i to o, and we wan t the mean that was or iginally in S ∗ i − 1 to end up at distance more than r i from P i . In that step, o ne of the G i ’s means will b e at distance exactly r i from P i , and th us P i (and Q i to o) will come back to one of the G i ’s cluster. Now we analy ze the waking-up pro ces s fr o m the p oint of view of the sleeping gadg et. W e suppo se that G i ( i > 0) is sleeping and that G i +1 wan ts to wak e it up. The sequence is shown in Fig. 3. G i +1 ’s cal l Supp ose that G i +1 started to waking up G i . Then, w e know that P i +1 joined the cluster { A i , B i , C i , D i } (pt. I). How ever, this does not caus e any p oint from this cluster to mov e to other cluster s. On the other ha nd, as we said b efore, the p oints P i and Q i will “come back” to G i by joining the cluster { E i } . At the nex t step (pt. I I), Q i +1 to o will join the c luster { A i , B i , C i , D i , P i +1 } . The new center will b e in a p osition such that, in one more s tep (pt. I I I), B i , C i and D i will move to the cluster { P i , Q i , E i } . Also we know that at that very sa me step, P i +1 and Q i +1 will co me ba ck to some G i +1 ’s cluster: th is implies that G i will e nd up with the clusters { B i , C i , D i , E i , P i , Q i } and { A i } , which is exa ctly the morning clustering: G i has b een wok en up. As fo r the “leaf ” gadg et G 0 , we said that it will fall asleep r ight a fter it has be en wok en up by G 1 . Th us we can describ e its day in the following wa y: 5 Night The r e is only o ne cluster which is the singleto n { F } . The center is obviously F which coincides with S ∗ 0 . In this co nfiguration G 0 is sleeping . G 1 ’s call The point P 1 from G 1 joins the cluster { P 0 } and in the next step Q 1 will join the same cluster too . After one more step, both P 1 and Q 1 will come back to some G 1 ’s cluster, which implies that the G 0 ’s cluster is the singleton { F } ag ain. Th us G 0 , after having b een tempo rarily woken up, fell asleep again. 3.3 F ormal Construction W e start giving the dista nc e s b e tween the p oints in a single gadget (int ra-ga dget). Afterwards, we will give the distances b etw een tw o consecutive gadgets (inter-gadget). Hencefor th x A i and y A i will deno te resp ectively the x -co ordinate and y -co or dina te of the po in t A i , and a nalogous notation will b e used for the o ther points. Also , for a set of p oints S , we define its total weight w S = P x ∈S w x , and its mean will b e denoted by µ ( S ), i.e. µ ( S ) = P x ∈S w x · x w S . W e supp ose that all the weights w P , w Q , w A , . . . have b een fixed to some p ositive integer v alues, and that w A = w B and w F = w A + w B + w C + w D . W e start describing the distances betw een p oints for a non- le a f gadget. F or simplicity , we start defining the lo cation of the p oints for an hypotetical “unit” g adget ˆ G that has unitary inner radius (i.e. ˆ r = 1) and is centered in the orig in (i.e. ˆ P = (0 , 0)). Then we will see how to define a ga dget G i (for any i > 0) in terms of the unit g adget ˆ G . The outer radius is defined as ˆ R = (1 + δ ) a nd also we let the p oint ˆ Q b e ˆ Q = ( λ, 0). The v alues 0 < δ < 1 and 0 < λ < 1 ar e constants whose v alue will b e assig ned later. The p o int ˆ E is defined as ˆ E = (0 , 1). The r emaining p oints are alig ned on the vertical line with x -co ordina te equals to 1 (formally , x ˆ A = x ˆ B = x ˆ C = x ˆ D = 1). As for the y - co ordinates, we set y ˆ A = − 1 / 2 and y ˆ B = 1 / 2. The v alue y ˆ C is uniquely defined by imp osing y ˆ C > 0 and that the mea n o f the cluster M = { ˆ A, ˆ B , ˆ C , ˆ P , ˆ Q } is at distance ˆ R from ˆ P . Thus, w e wan t the p ositive y ˆ C that satisfies the equation || µ ( M ) || = ˆ R , which ca n b e rewritten as w A + w B + w C + w Q λ w M 2 + w C y ˆ C w M 2 = (1 + δ ) 2 where we used the fact that w A y ˆ A + w B y ˆ B = 0 w hen w A = w B . W e easily obtain the s olution y ˆ C = 1 w C q ( w M (1 + δ )) 2 − ( w A + w B + w C + w Q λ ) 2 Note that the v alue under the sq uare ro ot is alwa y s positive b ecause λ < 1. It r emains to set y ˆ D . Its v alue is uniquely defined b y imp osing y ˆ D > 0 and that the mean of the clus ter N = { ˆ B , ˆ C , ˆ D, ˆ E , ˆ P , ˆ Q } is at distance ˆ R fr o m ˆ P . Analog ously to the pr evious ca se, y ˆ D is the p os itive v alue satisfying || µ ( N ) || = ˆ R , which is e q uiv alent to w B + w C + w D + w Q λ w N 2 + w D y ˆ D + w B (1 / 2) + w C y ˆ C + w E w N 2 = (1 + δ ) 2 Now, since the equation a 2 + ( b + x ) 2 = c 2 has the solutions x = ± √ c 2 − a 2 − b , we obtain the solution y D i = 1 w D q ( w N (1 + δ )) 2 − ( w B + w C + w D + w Q λ ) 2 − w B / 2 − w C y ˆ C − w E Again, the term under the square r o ot is alwa ys p o sitive. Finally , we define ˆ S ∗ in the natur al wa y as ˆ S ∗ = µ { ˆ A, ˆ B , ˆ C , ˆ D } . Now consider a gadget G i with i > 0. Suppo se to hav e fixed the inner ra dius r i and the center P i . Then we hav e the o uter ra dius R i = (1 + δ ) r i , and we define the lo cation of the p oints in 6 terms of the unit gadget b y scaling of r i and translating b y P i in fo llowing wa y: A i = P i + r i ˆ A , B i = P i + r i ˆ B , and so on for the other p oints. As for the gadge t G 0 , there ar e no intra-gadget distances to be defined, since it has only one po in t F . F or any i ≥ 0, the intra-gadget distance s in G i hav e b een defined (as a function o f P i , r i , δ and λ ). Now we define the (inter-gadget) dis ta nces b etw een the p oints of t wo consecutive gadgets G i and G i +1 , for any i ≥ 0. W e do this b y giving expliciting recursive expres sions for r i and P i . F or a point ˆ Z ∈ { ˆ A, ˆ B , ˆ C , ˆ D } , we define the “stretch” o f ˆ Z (from ˆ S ∗ with respect to µ { ˆ E , ˆ P , ˆ Q } ) a s σ ( ˆ Z ) = q d 2 ( ˆ Z , µ { ˆ E , ˆ P , ˆ Q } ) − d 2 ( ˆ Z , ˆ S ∗ ) The stretch will b e a real n um ber (for all p o int s ˆ A, ˆ B , ˆ C , ˆ D ), given the v alues λ , δ and the weigh ts used in the constructio n. W e set the inner ra dius r 0 of the leaf gadge t G 0 to a p ositive arbitra ry v alue, and for any i ≥ 0, we define r i +1 = r i 1 + δ w F + w P + w Q w P + (1 + λ ) w Q σ ( ˆ A ) (1) where we remind that w F = w A + w B + w C + w D . Now reca ll that S ∗ i = µ { A i , B i , C i , D i } fo r any i > 0, a nd S ∗ 0 = µ { F } = F . Assuming to hav e fixed the p oint F s omewhere in the plane, we define for any i > 0 x P i = x S ∗ i − 1 + R i (1 − ǫ ) (2) y P i = y S ∗ i − 1 where 0 < ǫ < 1 is some constant to define. Note that now the instance is completely defined in function of λ , δ , ǫ a nd the weigh ts. W e a re now ready to prove the lower b ound. 3.4 Pro of W e assume that the initial centers – that we seed k -means with – cor resp ond to the mea ns of the “mor ning clusters” of ea c h gadget G i with i > 0. Namely , the initial centers are µ { A i } , µ { B i , C i , D i , E i , P i , Q i } for all i > 0, in addition to the center µ { F } = F fo r the leaf g adget G 0 . In order to esta blish our r esult, it is eno ugh to show tha t there ex ist p ositive int eger v alues w A , w B , w C , w D , w E , w F , w P , w Q (with w A = w B ) and v alue s for λ , δ and ǫ , suc h that the behavior of k -means on the instance reflec ts exactly the clustering transitions described in Section 3.2. The c ho sen v alues (as well as other derived v alues used later in the a nalysis) a re in T able 1. The use of rational w eig h ts is not restrictive, b ecause the mean of a cluster (as well a s k -means’ b ehavior) do es not change if we m ultiply the weigh ts of its p oints by the sa me factor – in our c ase it is enoug h to multiply all the weight s by 100 to obtain integer weigh ts. Finally , for the v alue o f ǫ , we imp ose 0 < ǫ < min ( d 2 ( ˆ S ∗ , ˆ C ) (1 + δ ) 2 , λ 1 + δ , σ ( ˆ A ) − σ ( ˆ B ) σ ( ˆ A ) , 1 − (1 + λw Q )( w F + w P + w Q ) (1 + δ ) w F ) Throughout the pro of, we will say tha t a p oint Z in a cluster C is st able with re spec t to (w.r.t) another cluster C ′ , if d ( Z , µ ( C )) < d ( Z , µ ( C ′ )). Similarly , a p oint Z in a cluster C is stable if Z is stable w.r.t. any C ′ 6 = C . Also, similar definitions of stability ex tends to a cluster (resp. clus ter ing) if the stability holds for all the p oints in the cluster (re s p. for all the clusters in the clustering). W e consider an arbitrary gadget G i with i > 0 in any stag e of its da y (some cluster ing), and we s how tha t the steps that k -means g o es thro ugh ar e exactly the ones des c rib e d in Section 3.2 for that stage of the day (for the chosen v alues o f λ, δ, ǫ and weight s). F or the sake of conv e nience 7 Chosen v alues Unit gadget Other derived v alues used in the proof δ = 0 . 25 ˆ r = 1 (0 . 1432 , 1 . 0149) N (1 . 44 , 1 . 015 ) λ = 10 − 5 ˆ R = (1 + δ ) = 1 . 025 (0 . 9495 , 0 . 386) M (0 . 9496 , 0 . 386 1) w P = 1 ˆ P = (0 , 0) 1 . 003 ≤ α ≤ 1 . 004 w Q = 10 − 2 ˆ Q = ( λ, 0) = (10 − 5 , 0) 1 . 0526 ≤ β ≤ 1 . 05261 w A = 4 ˆ A = (1 , − 0 . 5) 0 . 99 ≤ γ ≤ 0 . 99047 w B = 4 ˆ B = (1 , 0 . 5) 1 . 0003 ≤ σ ( ˆ A ) ≤ 1 . 0004 w C = 11 (1 , 0 . 70 223) ˆ C (1 , 0 . 70224) 1 . 0001 ≤ σ ( ˆ B ) ≤ 1 . 0002 w D = 31 (1 , 1 . 35 739) ˆ D (1 , 1 . 3574) 1 ≤ σ ( ˆ C ) ≤ 1 . 0001 w E = 274 ˆ E = (0 , 1) 0 . 9999 ≤ σ ( ˆ D ) ≤ 0 . 99992 T able 1: The relatio n denotes the less- or-equa l comp onent-wise relation. and w.l.o.g , we assume that G i has unitar y inner ra dius (i.e. r i = ˆ r = 1 and R i = ˆ R = (1 + δ )) and that P i is in the orig in (i.e. P i = (0 , 0)). Morning W e need to prov e that the morning cluster ing of G i is stable assuming that G i − 1 is not sleeping. Note that this a ssumption implies that i > 1 since the gadget G 0 is always s leeping when G 1 is in the morning. Since the singleton cluster { A i } is trivially stable, we just need to show tha t N = { B i , C i , D i , E i , P i , Q i } is stable. It is easy to understand tha t it suffices to show that B i , Q i and P i are stable w.r.t { A i } (the other p oints in N ar e further from A i ), a nd that P i is stable w.r.t a ny G i − 1 ’s cluster. Letting N = µ ( N ), we hav e x N = ( w B + w C + w D + λw Q ) /w N , and y N = p (1 + δ ) 2 − x 2 N . The p oint P i is stable w.r.t. { A i } , since d ( P i , N ) = (1 + δ ) < p 1 2 + (0 . 5 ) 2 = d ( P i , A i ). T o prov e the sa me for Q i , no te that d ( Q i , A i ) = p (1 − λ ) 2 + (0 . 5 ) 2 > ˆ R , while o n the other hand x N > x Q i implies d ( Q i , N ) < ˆ R . As for B i , d 2 ( B i , N ) = ( x B − x N ) 2 + ( y B − y N ) 2 = || B i || 2 + ˆ R 2 − 2( x N x B i + y N y B i ). Thus, the inequa lit y d ( B i , N ) < d ( B i , A i ) = 1 simplifies to 5 / 4 + ˆ R 2 − 2 x N − y N < 1, which can b e chec ked to b e v a lid. It remains to prov e that P i is stable w.r.t. any G i − 1 ’s cluster. It is easy to understand that, in any stag e o f G i − 1 ’s day (different from the nigh t), the distance from a n y G i − 1 ’s center to P i is more than the dista nce betw een C i − 1 and P i . W e obser ve that d 2 ( P i , C i − 1 ) = ( x P i − x S ∗ i − 1 ) 2 + d 2 ( S ∗ i − 1 , C i − 1 ) = R 2 i (1 − ǫ ) 2 + ˆ r d 2 ( ˆ S ∗ i − 1 , ˆ C ), using (2). The assumption ǫ < d 2 ( ˆ S ∗ , ˆ C ) / (1 + δ ) 2 directly implies d 2 ( P i , C i − 1 ) > (1 + δ ) = d ( P i , N ). 1st Call W e s ta rt analyzing the part I of this s tage. Since we are ass uming tha t G i − 1 is sleeping, there m ust b e so me G i − 1 ’s cluster C with center in S ∗ i − 1 (note that G i − 1 can be the leaf gadget G 0 as well). By (2) we hav e d ( P i , S ∗ i − 1 ) < R i , a nd so P i will join C . W e claim that Q i (any other G i ’s p oint is implied) is instead stable, i.e. d ( Q i , N ) < d ( Q i , S ∗ i − 1 ). W e alrea dy know that d ( Q i , N ) < ˆ R , so we show d ( Q i , S ∗ i − 1 ) > ˆ R . Us ing (2), we ha ve ˆ R (1 − ǫ ) + λ ˆ r > ˆ R , which holds for ǫ < λ/ (1 + δ ). W e now a nalyze the nex t iter ation, i.e. the par t I I of this s ta ge. W e claim tha t Q i will join C ∪ { P i } , and B i will join { A i } . T o e s tablish the for mer, we show that d ( Q i , µ ( N ′ )) > ˆ R where N ′ = N − { P i } . Since P i is in the or ig in, we can write N ′ = αN with α = w N /w N ′ . Thu s, the inequality we ar e interested in is ( λ − αx N ) 2 + ( αy N ) 2 > ˆ R 2 which can rewr itten as ( α 2 − 1) ˆ R > 2 λαx N . Finally , since α > 1 , ˆ R > 1 and x N < 1, the inequa lit y is implied by α (1 − 2 λ ) > 1, which holds for the chosen v a lues . It r emains to prov e that B i is not stable w.r.t. { A i } , i.e. d ( B i , N ′ ) > d ( B i , A i ) = 1. Ag ain, starting with the inequa lit y (1 − αx N ) 2 + (1 / 2 − αy N ) 2 > 1, we get the equiv alent inequa lit y 1 / 4 + α 2 ˆ R > α (2 x N + y N ), which is easy to verify . 8 Finally , we prov e that C i is instead stable w.r.t. N ′ . Similarly we get x 2 C i + y 2 C i + α 2 ˆ R 2 − 2 α ( x N x C i + y N y C i ) < ( y A i − y 2 C i ), which is implied by 3 / 4 + α 2 ˆ R 2 < y C i (1 + 2 αy N ). Afternoon The last stage ended up with the G i ’s clusters N ′′ = { C i , D i , E i } and { A i , B i } , since P i and Q i bo th joined the clus ter C o f G i − 1 . W e claim that, at this p oint, P i , Q i and C i are not stable and will all join the c lus ter { A i , B i } . Let C ′ = C ∪ { P i , Q i } ; no te that the to ta l weight w C ′ of the cluster C ′ is the same if G i − 1 is the lea f gadget G 0 or not, s ince by definition of w C = w F = w A + w B + w C + w D . W e s ta rt showing that d ( P i , µ ( C ′ )) > ˆ r = 1 which proves that the claim is true for P i and Q i . By defining d = x P i − x S ∗ i − 1 , the ine q uality can b e rewr itten as d − ( w P d + w Q ( d + λ )) /w C ′ > 1, whic h by (2) is e q uiv alent to (1 − ǫ )(1 + δ ) w C /w C ′ > 1 + λw Q . It ca n b e chec ked that (1 + δ ) w C /w C ′ > 1 + λw Q and the assumption on ǫ completes the pro o f. Now we prove that C i is not stable w .r .t to { A i , B i } , by showing that d ( C i , N ′′ ) > y C i where N ′′ = µ ( N ′′ ). Note tha t the inequa lit y is implied by x C i − x N ′′ > y C i , which is equiv alent to w E /w N ′′ > y C i that ho lds for the chosen v alues. A t this point, analogolo usly to the morning s ta ge, w e want to show that this new clustering is stable, as s uming that G i − 1 is not sleeping. No te that the analysis in the morning stag e dir ectly implies that P i is stable w.r .t any G i − 1 ’s cluster. It can b e shown as well that P i is stable w.r.t to N ′′′ = { D i , E i } , a nd D i is stable w.r .t. M = { A i , B i , C i , P i , Q i } (other po in ts’ stability is implied). 2nd Call F or the par t I of this sta ge, i.e. we assume G i − 1 is sleeping, a nd so there is some G i − 1 ’s cluster C with center in S ∗ i − 1 . Similarly to the 1 s t ca ll (part I), P i will jo in C . The p oint Q i is instead stable, since we proved d ( Q i , S ∗ i − 1 ) > ˆ R , while x M > x Q i implies d ( Q i , M ) < ˆ R . W e now analyze the next itera tion, i.e. the part I I of this sta ge. W e claim that Q i will jo in C ∪ { P i } , and D i will join M ′ = M − { P i } . This can b e prov en analog ously to the pa rt II of the fir st call, by using M ′ = µ ( M ′ ) = β M , where β = w M /w M ′ . Night The last stag e le aves us with the clusters { A i , B i , C i , D i } and the singleton { E i } . W e want to prov e that in one iteratio n P i and Q i will join { E i } . In the a fterno on stage, we already prov ed that d ( P i , µ ( C ′ )) > ˆ r , and since d ( P i , A i ) = ˆ r = 1, the point P i will join { E i } . F or the po in t Q i , we hav e d ( Q i , µ ( C ′ )) = d ( P i , µ ( C ′ )) + λ > ˆ r + λ , while d ( Q i , E i ) = √ ˆ r 2 + λ 2 < ˆ r + λ . Thus, the po in t Q i , as well as P i , will join { E i } . G i +1 ’s call In this stage, we are analyzing the waking-up pro cess fro m the po in t of view of the sleeping gadget. W e supp ose that G i ( i > 0) is sleeping a nd that G i +1 wan ts to wak e it up. W e sta r t considering the part I of this stage, when o nly P i +1 joined the cluster S = { A i , B i , C i , D i } . Let S ′ = S ∪ { P i +1 } . W e wan t to verify that the po in ts in S are stable w.r.t. { E i , P i , Q i } , i.e. tha t for e a ch ˆ Z ∈ S , d ( ˆ Z , µ ( S ′ )) < d ( ˆ Z , µ { E i , P i , Q i } ). This ineq uality is equiv alent to d ( ˆ S ∗ , µ ( S ′ )) < σ ( ˆ Z ), and g iven the o rdering o f the stretches, it is enough to show it for ˆ Z = ˆ D . By (2), we have that d ( ˆ S ∗ , µ ( S ′ )) = (1 − ǫ ) R i +1 w P /w S ′ , and us ing (1 ) we get d ( ˆ S ∗ , µ ( S ′ )) = ˆ r (1 − ǫ ) γ σ ( ˆ A ) where γ = ( w P /w S ′ )( w S ′ + w Q ) / ( w P + (1 + λ ) w Q ). Finally , it is easy to verify that γ σ ( ˆ A ) < σ ( ˆ D ). In the par t I I of this stage , Q i +1 joined S ′ . Let S ′′ = S ′ ∪ { Q i +1 } .. W e wan t to verify that all the p oints in S but A will move to the cluster { E i , P i , Q i } . W e start showing that d ( A i , µ ( S ′′ )) < d ( ˆ Z , µ { E i , P i , Q i } ). This ineq ua lit y is equiv alent to d ( ˆ S ∗ , µ ( S ′′ )) < σ ( ˆ A ), a nd we have d ( ˆ S ∗ , µ ( S ′′ )) = (1 − ǫ ) R i +1 ( w P + (1 + λ ) w Q ) / ( w P + w Q + w F ). 9 Using (1) to substitute R i +1 , we get d ( ˆ S ∗ , µ ( S ′′ )) = (1 − ǫ ) σ ( ˆ A ), which prov e s that A i will not change cluster. Similarly , we wan t to prove that, for ˆ Z ∈ S , ˆ Z 6 = ˆ A , it holds that d ( ˆ S ∗ , µ ( S ′′ )) = (1 − ǫ ) σ ( ˆ A ) > σ ( ˆ Z ). Given the order ing of the s tretches, it suffices to show it fo r ˆ Z = ˆ B . Recalling that ǫ < ( σ ( ˆ A ) − σ ( ˆ B )) /σ ( ˆ A ), the pro of is concluded. 3.5 Extensions The pro of in the previous section as s umed that the s et of initial centers cor resp ond to the means of the “morning clus ters” for each g adget G i with i > 0. A c o mmon initializatio n for k -means is to cho ose the set of centers among the data p oints. W e now briefly explain how to mo dify our instance so to hav e this prop er t y and the s ame num b er of iterations. Consider the unit gadget ˆ G for simplicity . One of the center will b e the p oint ˆ E . In the beg inning we want all the p oints of ˆ G except ˆ A to be assigned to ˆ E . T o obtain this, w e will co nsider tw o new data p oints each with a center on it. Add a p oint (and center) ˆ I with x ˆ I = x ˆ A = 1 and such that y ˆ A − y ˆ I is slightly le ss than d ( ˆ A, ˆ E ). In this wa y ˆ A will b e ass igned to this c en ter. Also, we add another p oint (and center) ˆ J very clos e to ˆ I (but fur ther fr om ˆ A ) so that, when ˆ B joins the cluster { ˆ I } moving the center towards itself, the p oint ˆ I will move to the cluster { ˆ J } . By mo difying in this wa y a ll the gadgets in the instance, we will rea ch the morning clustering of each gadg et in tw o steps. Also it is ea sy to check that the new p oints do not affect the following steps. Har-Peled a nd Sadr i [9] conjectured that, for any dimension d , the num b er of iterations of k -means might b e b ounded by some p oynomial in the num b er o f p oint n and the sprea d ∆ (∆ is ra tio b etw een the la r gest and the smallest pairwise distance). This conjecture was already dispr ov en in [2] fo r d = Ω( √ n ). By using the sa me arg umen t, we ca n mo dify our c o nstruction to an instance in d = 3 dimens io n having linear spread, for which k - mea ns req uir es 2 Ω( n ) iterations. Thus, the conjecture do es not hold for a ny d ≥ 3. 4 Conclusions and further discussion W e pr esented how to constr uc t a 2-dimensio nal instance with k clusters for which the k - mea ns algorithm requires 2 Ω( k ) iterations. F or k = Θ ( n ), we o btain the low er bound 2 Ω( n ) . Our result improv es the b est known low er b ound [2] in ter ms of num ber of itera tio ns (which w as 2 Ω( √ n ) ), as well as in terms o f dimensiona lit y (it held for d = Ω( √ n )). W e obser ve that in our c onstruction ea ch gadget uses a constant num b er o f p oints and wak es up the next g adget t wice. F or k = o ( n ), we could use Θ( n/k ) p oints for each gadget, a nd it would b e interesting to see if one ca n construct a g adget with such many p oints that is able to wak e up the next o ne Ω( n/k ) times. Note that this would give the low er b ound ( n/ k ) Ω( n/k ) , which for k = n c (0 < c < 1 ), simplifies to n Ω( k ) . This ma tc hes the optimal upp er b ound O ( n kd ), a s long as the c onstruction lies in a constant nu m be r of dimensions . A p oly no mial upp er b ound for the cas e d = 1 has b een rece ntly prov en in the smo othed regime [14]. It is natural to a sk if this result can b e extended to the ordina ry case. Ac kno wledgemen ts W e grea tly thank Flavio Chierichetti and Sanjoy Dasg upta for their helpful co mmen ts and discussions. W e a lso thank David Arthur for having confirmed some of our intuitions on the pro of in [2]. 10 References [1] Pank a j K . Agar wal a nd Nabil H. Mustafa. k-means pro jective clus ter ing. In PODS ’04: Pr o c e e dings of the twenty-thir d ACM SIGMOD-S IGACT-SIGAR T symp osium on Principles of datab ase systems , pages 155–1 65, New Y ork, NY, USA, 2 004. ACM Pres s. [2] David Arthur and Ser gei V ass ilv itskii. How slow is the k -means metho d? In Nina Amenta and Otfried Cheong, editor s, Pr o c. of the 22nd ACM Symp osium on Computational Ge om- etry (SOCG) , page s 144 –153. A CM P ress, 200 6. [3] David Arth ur and Serge i V as silvitskii. W ors t-case a nd smo o thed analysis of the ICP a lg o- rithm, with an a pplication to the k -means metho d. In Pr o c. of t he 47th Ann. IEEE Symp. on F oundations of Comp. Scienc e (F OCS) , pag es 15 3–164 . IEEE Computer So cie t y , 20 06. [4] Pav el Berkhin. Survey of clustering data mining techniques. T echnical rep ort, Accrue Soft- ware, San Jose, CA, USA, 20 02. [5] Sa njoy Dasg upta. How fast is k - means? In COL T Computational L e arning The ory , volume 2777, page 735 , 2003. [6] Richard O. Duda, Peter E. Hart, a nd David G. Stor k . In Patt ern Classific ation , John Wiley & Sons, 200 0. [7] F orgy , E.W. Cluster analysis of m ultiv aria te data: e fficie nc y versus inter- pretability o f clas- sifications. In Biometric S o ciety Me eting , Riverside, California, 1965 . Abstract in Biometrics 21 (196 5 ), 768 . [8] F r ´ ed´ eric Gib o u and Rona ld F edkiw. A fast hybrid k- means level s e t algor ithm for segmen ta- tion. In 4th Annual H awaii In t ernational Confer enc e on St atistics and Mathematics , pa ges 281–2 91, 2 005. [9] Sa riel Har -Peled a nd Bardia Sadri. How fast is t he k -means metho d? In Algorithmi c a , 41(3):185 –202, 2005. [10] Mar y Inaba , Naoki Kato h, and Hiros hi Imai. V ariance-based k - clustering algor ithms b y V oro noi diag rams and randomization. In IEICE T r ansactions on Information and Systems , E83-D(6):1 1 99–12 06, 2000. [11] T. Kan ungo , D. M. Moun t, N. S. Netany a h u, C. D. P iatko, R. Silverman, and A. Y . W u. A lo cal s e arch approximation algorithm for k-means clustering . Comput. Ge om. , 28(2- 3):89–1 12, 2 004. [12] Stuar t P . Lloyd. Leas t squar es quantization in p cm. IEEE T r ansactions on I n formation The ory , 2 8(2):129– 136, 19 82. [13] J. B. MacQueen: Some Metho ds for c la ssification and Analysis o f Multiv aria te Obser v a- tions, In Pr o c e e dings of 5-t h Berkeley Symp osium on Mathematic al Statist ics and Pr ob ability , Berkeley , Universit y of Ca lifornia Pr ess, 1:2 81-29 7, 19 67. [14] Bo do Ma nt hey , Heiko R¨ oglin. Improv ed smo othed analysis of the k -means metho d. T o app ear in Pr o c e e dings of the 20th Annual ACM-SIAM S ymp osium on D iscr ete Algori thms, SODA 2009 , New Y or k , NY, USA, January 4-6, 20 09. [15] Daniel A. Spielma n and Shang-Hua T eng. Smo othed a na lysis of alg orithms: Wh y the simplex a lg orithm usually ta kes po lynomial time. In Journal of t he ACM , 51 (3 ):385–46 3, 2004. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment