평면에서도 k‑평균은 지수적 반복 횟수를 요구한다
본 논문은 2차원 평면에 존재하는 n개의 데이터와 Θ(n)개의 초기 중심을 이용해 k‑means 알고리즘이 최악의 경우 2^{Ω(n)} 번의 반복을 수행한다는 새로운 하한을 제시한다. 이는 기존에 고차원(≈√n 차원)에서만 알려졌던 초다항 하한을 2차원으로 낮추고, 기존 상한 O(n^{kd})와 거의 일치하는 최적에 가까운 결과이다. 논문은 “감시자” 메타포를 이용한 가젯 체인을 구성해 각 가젯이 이전 가젯을 깨우는 과정을 반복함으로써 지수적 …
저자: Andrea Vattani
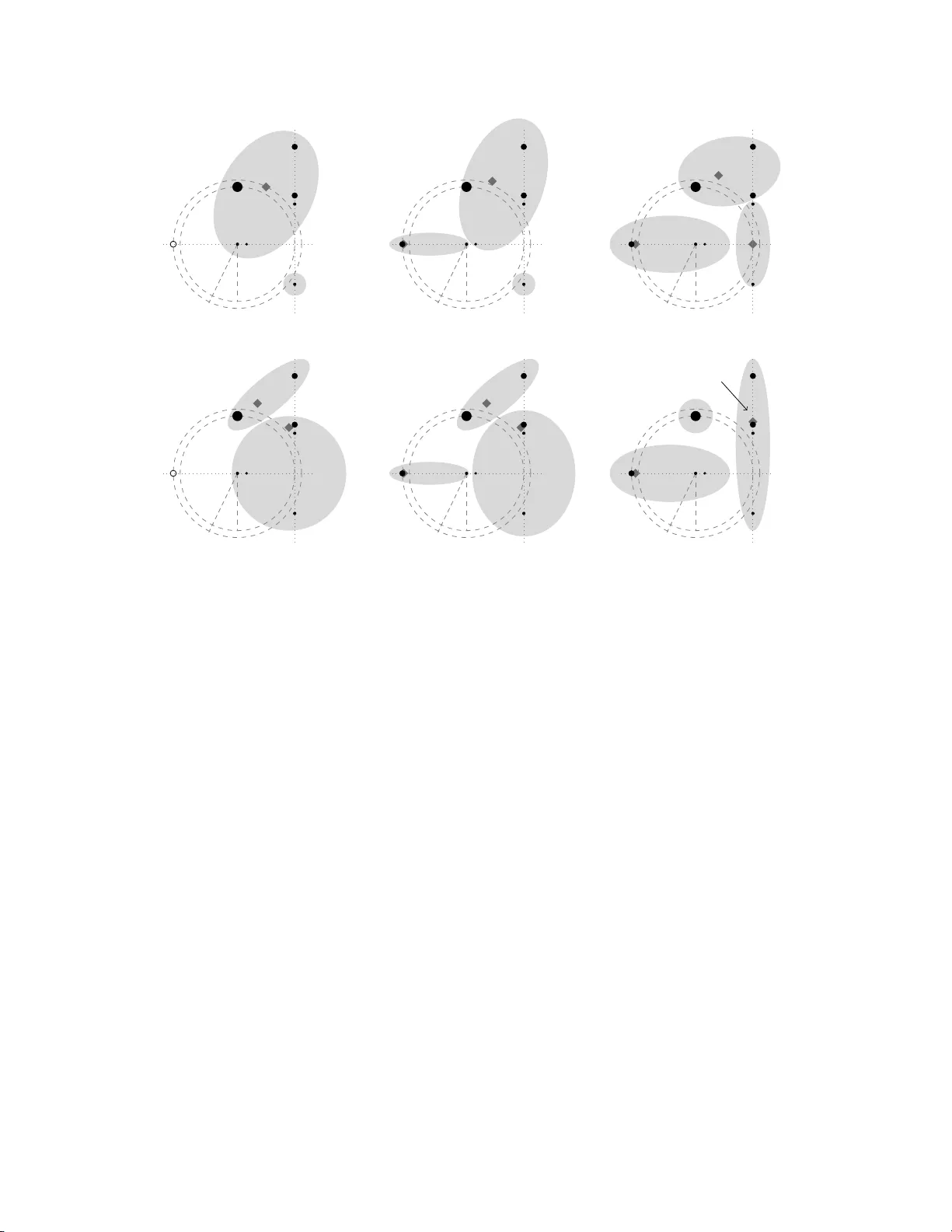
본 논문은 k‑means 알고리즘이 2차원 평면에서도 최악의 경우 지수적인 반복 횟수를 요구한다는 새로운 하한을 제시한다. 먼저, 기존 연구들을 정리한다. k‑means는 실무에서 단순하고 빠른 클러스터링 방법으로 널리 쓰이지만, 이론적으로는 O(n^{kd}) 라는 상한이 존재한다. 하한은 오랫동안 Ω(n) 수준에 머물렀으며, Arthur와 Vassilvitskii는 d=Θ(√n) 차원에서 2^{Ω(√n)} 의 초다항 하한을 보였고, 모든 d≥2 에서도 초다항 하한이 존재할 것이라고 추측하였다.
논문은 이 추측을 2차원(d=2)까지 확장하고, 하한을 2^{Ω(n)} 로 크게 강화한다. 핵심은 “감시자” 메타포를 이용한 가젯 체인이다. 각 가젯 G_i (i>0)는 7개의 고정 가중치 점과 두 개의 중심을 포함한다. 점들은 P_i, Q_i, A_i, B_i, C_i, D_i, E_i 로 명명되며, 각각의 가중치는 정수이며 상수이다. 가젯은 내부 반경 r_i 와 외부 반경 R_i 로 정의된 두 원형 영역을 갖고, 이 반경은 인접 가젯 간의 거리와 정밀히 조정된다.
가젯은 네 단계(아침, 첫 호출, 오후, 두 번째 호출, 밤)를 순환한다. “아침” 단계에서는 {A_i} 가 단일 클러스터를 이루고 나머지 점들이 다른 클러스터에 속한다. “첫 호출” 단계에서는 G_{i-1} 가 잠들 때 P_i 가 G_{i-1} 의 클러스터에 일시적으로 합류하고, 이어 Q_i 가 합류하면서 G_{i-1} 의 중심이 이동한다. 이때 B_i 가 {A_i} 로 이동한다. “오후” 단계에서는 P_i, Q_i, C_i 가 {A_i,B_i} 클러스터에 합류하고, D_i와 E_i 가 별도 클러스터를 이룬다. “두 번째 호출” 단계는 첫 호출과 대칭적으로 진행되며, 최종적으로 {A_i,B_i,C_i,D_i} 클러스터가 형성되어 중심이 S_i^* 로 이동한다. 이때 G_i 가 “잠듦” 상태가 된다.
다음으로, G_{i+1} 가 G_i 를 깨우는 과정을 살펴본다. G_{i+1} 의 P_{i+1} 가 G_i 의 잠든 클러스터에 합류하고, Q_{i+1} 가 이어 합류하면서 중심이 이동한다. 이때 B_i, C_i, D_i 가 새로운 클러스터 {P_i,Q_i,E_i} 로 이동하고, P_i와 Q_i 가 다시 G_i 내부로 돌아와 원래 “아침” 클러스터 구성을 복원한다. 따라서 G_i 가 다시 잠들 때까지 두 번의 호출이 필요하고, 각 호출은 이전 가젯이 잠든 상태를 감지하고 깨우는 역할을 한다.
이러한 연쇄 구조를 t개의 가젯에 대해 연속적으로 배치하면, 가장 마지막 가젯 G_{t-1} 가 잠들 때까지 각 가젯이 최소 두 번씩 호출된다. 즉, 전체 반복 횟수는 2·t = Θ(k) 가 되며, 여기서 k = Θ(n) 이므로 전체 반복 횟수는 2^{Ω(n)} 에 해당한다. 중요한 점은 각 가젯이 상수 개의 점과 중심만을 사용하므로 전체 인스턴스의 크기는 O(n) 에 머무른다.
논문은 또한 초기 중심을 데이터 점의 부분집합으로 제한하는 경우에도 동일한 하한이 유지된다는 것을 보인다. 이는 실제 구현에서 흔히 사용하는 k‑means++ 혹은 random‑subset 초기화와도 호환된다. 더 나아가, 기존의 고차원 구성에서 사용된 “저스프레드” 기법을 3차원으로 축소시켜, d≥3 인 경우에도 저스프레드 인스턴스에서 2^{Ω(n)} 반복이 발생함을 증명한다. 이는 Har‑Peled와 Sadrí가 제시한 “스프레드에 대한 다항 시간” 추측을 반박한다.
마지막으로, 최근의 smoothed analysis 결과(예: Manthey와 Röglin의 O(n·poly(k)) 상한)와 비교했을 때, 본 하한은 k가 ω(log² n) 인 경우에 smoothed 상한보다 크게 된다. 이는 작은 차원에서도 k‑means가 여전히 최악의 경우 지수적 복잡도를 가질 수 있음을 강조한다. 논문은 이러한 결과가 k‑means의 이론적 이해에 중요한 전진을 의미하며, 실무에서의 초기화 전략 및 차원 축소 기법에 대한 재검토를 촉구한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기