An Empirical Study of Cache-Oblivious Priority Queues and their Application to the Shortest Path Problem
In recent years the Cache-Oblivious model of external memory computation has provided an attractive theoretical basis for the analysis of algorithms on massive datasets. Much progress has been made in discovering algorithms that are asymptotically op…
Authors: ** Benjamin Sach, Raphaël Clifford (Bristol University, 영국) **
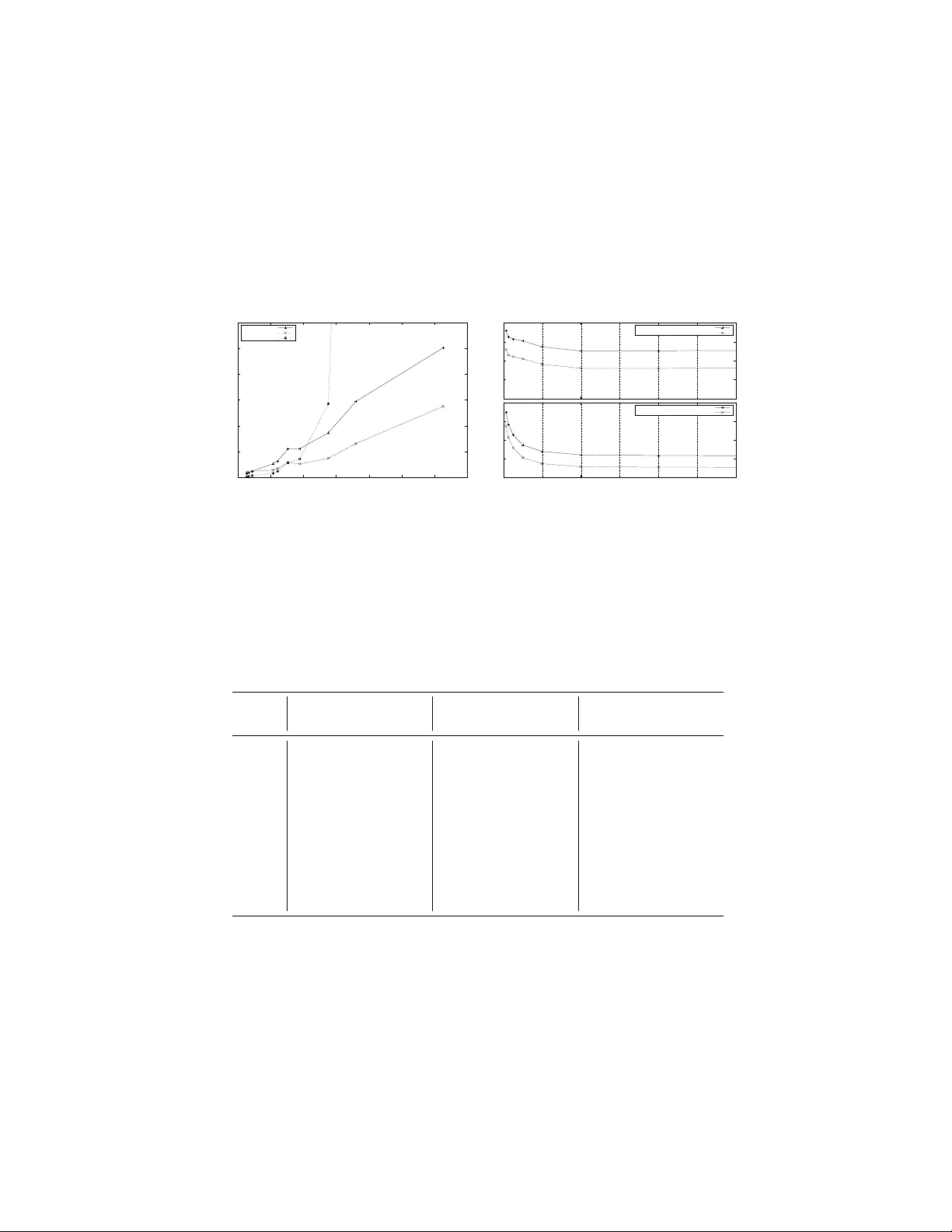
An Empirical Study of Cac he-Oblivious Priorit y Queues and their Application to the Shortest P ath Problem Benjamin Sac h and Rapha¨ el Clifford Bristol Univ ersity , Bristol, UK { sach,clifford } @cs.bris.ac.uk , http://www.cs.bris.ac.uk/ ∼ sach/COSP/ Abstract. In recent years the Cache-Oblivious mo del of external mem- ory computation has provided an attractiv e theoretical basis for the anal- ysis of algorithms on massiv e datasets. Much progress has been made in disco vering algorithms that are asymptotically optimal or near optimal. Ho wev er, to date there are still relatively few successful exp erimental studies. In this pap er w e compare t wo differen t Cac he-Oblivious priorit y queues based on the F unnel and Buck et Heap and apply them to the sin- gle source shortest path problem on graphs with p ositive edge weigh ts. Our results show that when RAM is limited and data is swapping to external storage, the Cache-Oblivious priority queues achiev e orders of magnitude sp eedups ov er standard internal memory tec hniques. How- ev er, for the single source shortest path problem both on simulated and real world graph data, these sp eedups are mark edly lo wer due to the time required to access the graph adjacency list itself. 1 In tro duction The need to transfer blo cks of data b et ween memory lev els is a prop erty of real world systems not accoun ted for in the standard RAM mo del of computing. The I/O-Mo del introduced by Aggarwal and Vitter [2], con- siders tw o lev els of memory , internal and external. The internal memory is of fixed size M and the external memory is unbounded in size. Data is transferred b etw een lev els in blo cks of size B with each blo ck transferred costing a single I/O op eration. F rigo et al [13] later in troduced the Cac he-Oblivious model whic h pro- vides a theoretical basis for designing algorithms for systems with mul- tiple levels of memory . This mo del has tw o significan t adv antages. First, algorithms designed sp ecifically for the standard tw o level I/O model (so- called Cac he-Aware algorithms) need careful tuning to the parameters of the system on whic h they are run. More significantly , mo dern computer systems ma y contain many levels of cache, internal memory and external 2 storage. An optimal Cac he-Oblivious algorithm will in theory b e optimal across all lev els of the memory hierarch y sim ultaneously [13]. There has b een a flurry of results in Cac he-Oblivious algorithms since its conception whic h include sorting, link ed lists, B-trees, orthogonal range searc hing and priority queues (see e.g. [11] for a general o verview). De- spite these theoretical adv ances, far less is kno wn ab out the empirical p erformance of the techniques developed. The exp erimental studies that ha ve been carried out in to the performance of Cac he-Oblivious algorithms (see e.g. [20, 9, 5, 17, 19, 15, 8]) ha ve largely fo cused on internal memory p erformance in order to test L 1 and L 2 cache p erformance. One notable exception is a recen t study where the fastest Cac he-Aw are and Cac he- Oblivious sorting algorithms are also compared in external memory [8]. Our fo cus here is on the empirical p erformance of Cac he-Oblivious priorit y queues and their application to Dijkstra’s single source shortest path algorithm for data sizes to o large to fit in in ternal memory . F our Cac he-Oblivious priorit y queues hav e b een developed whic h w e name Arge Heap[4], F unnel Heap[6], Buck et Heap[7] and Buffer Heap[10]. Al- though typically these structures hav e optimal or near optimal asymp- totic p erformance for the op erations they supp ort, none so far supp orts all three of DecreaseKey , Inser t and DeleteMin needed for a stan- dard implementation of Dijkstra’s algorithm (see Section 2 for a de- scription of some of the mo difications required). The I/O complexity for eac h priority queue is shown in Figure 1 where we include results for a Cac he-Aware tournament tree [16], a Cache-Aw are priority queue [16] and Cac he-Oblivious tournament trees [10] for completeness. T able 1. The I/O complexit y of different priority queues Priorit y Queue I nser t D eleteM in D ecr easeK ey U pdate Binary Heap O (log N ) Cac he-Aware Priority Queue O ( 1 B log M B N B ) - - F unnel Heap O ( 1 B log M B N B ) - - Arge Heap O ( 1 B log M B N B ) - - Buc ket/Buffer Heap - O ( 1 B log N B ) - O ( 1 B log N B ) Cac he-Aware tournament tree - O ( 1 B log N B ) - Cac he-Oblivious tournament tree - O (log N B ) O ( 1 B log N B ) - 3 Figure 2 giv es the corresponding I/O and time complexities for the mo dified Dijkstra’s algorithms ev aluated in this study . F aster asymptotic b ounds can be deriv ed in the Cache-Aw are mo del [18] or if the graphs ha ve b ounded weigh ts [3] or are planar [14]. T able 2. The I/O complexities of Dijkstra’s Algorithm for the heaps implemen ted Binary Heap Buck et/Buffer Heap F unnel Heap I/O complexit y O ( E log V ) O ( V + E B log V B ) O ( V + E B log M B V B ) In this pap er we implement Buc ket [7] and F unnel Heap [6] and com- pare their p erformance b oth to each other and to a standard Binary Heap implemen tation. These priorit y queues are representativ e of the t wo main approaches that ha ve b een taken. Our preliminary implemen- tation of Buffer Heap for example (not sho wn here), indicates that its p erformance tracks that of Buck et Heap closely but is marginally slo wer in all cases. W e then implement Dijkstra’s single source shortest path al- gorithm using the same priorit y queues and run a series of tests on b oth random and real world graph data. W e show that algorithms not explic- itly designed for external memory suffer a dramatic p erformance p enalt y compared to the Cac he-Oblivious algorithms w e implemen t when data is to o large to hold in RAM. Results Our main findings are: – F or small problem sizes the Binary Heap consistently outp erformed the tw o Cache-Oblivious solutions. This shows that the adv an tages of optimal multi-lev el cac he usage are outw eighed b y the constan t factor o verheads of the more complicated Cache-Oblivious algorithms. – F or problem sizes to o large to fit in RAM, b oth the F unnel and Buc ket Heap show considerable sp eedups o ver Binary Heap on our tests. F or example, using 16MB of RAM and 1 . 2 million elements, Binary Heap to ok o v er 4 hours and sp en t > 99% of its time w aiting for I/O requests. F unnel and Buc k et Heap b y contrast to ok under 4 min utes and 10 min utes resp ectively . 4 – The p erformance of Dijkstra’s algorithm implemented using the Cache- Oblivious priorit y queues also show ed speedups for large inputs for b oth synthetic and real world graphs. Ho wev er, as predicted by the theory these sp eedups are markedly lo wer than for the simple priority queue tests due to the cost of accessing the edges in the graph itself. F or example, on a graph of ∼ 1 million vertices ( ∼ 8 million edges) using 16MB of RAM for the priorit y queue and a further 16MB for the graph, Dijkstra’s algorithm implemen ted with F unnel Heap was 5 times faster than using Binary Heap and 20% faster than Buc ket Heap. 2 Implemen tation All co de was written in C++ and compiled using the g++ 4.1.2 compiler with optimisation level -O3 on GNU / Linux distribution Ubuntu 7 . 10 (ker- nel version 2 . 6) with a dual 1 . 7 Ghz In tel Xeon pro cessor PC (only one w as used), 1280MB of RAM, 8KB L1 and 256KB L2 cache. The test setup made use of the STXXL Library [12] v ersion 1 . 0 e whic h is designed to b e an STL replacement for pro cessing of large data for exp erimen- tal testing of external memory algorithms (hence ST XXL ).The library pro vides containers and algorithms for large datasets which do not fit in in ternal memory and handles all sw apping of data to and from external storage. As STXXL is designed for Cac he-Aware implementations, only a minimal subset of the features av ailable was used with the c hosen v al- ues of M and B not a v ailable to the implemented algorithms. In order to set up a realistic Cac he-Oblivious en vironmen t, each algorithm uses one STXXL V ector 1 for the priorit y queue and in the case of Dijkstra’s algorithm, a further V ector of the same size to store the adjacency list. STXXL V ectors ha ve individual caches which we set to 16MB and the blo c k size B was set to 4096 b ytes. The blo c k replacement policy w as c hosen to b e Least Recen tly Used (LR U). Eac h machine also has t wo hard disk driv es, a primary drive containing the Lin ux b o ot sector and secondary drive assigned exclusively to the STXXL Library . Both driv es p erform at 7 , 200 RPM with 8 . 5ms seek time, 8MB data buffer with sep- arate parallel A T A 133 in terfaces and no secondary cable use. All tests w ere run in single user mo de with the op erating system swapping turned off so that STXXL is solely resp onsible for moving blo cks of data in and out of memory . F or each test we output the total (wall) time and the I/O w ait time as measured by STXXL. 1 A dynamic arra y equiv alent to the STL vector 5 Some further implementation details for the sp ecific tasks carried out follo w. Binary Heap Our Binary Heap implemen tation is arra y based with implicit p oin ters. The DecreaseKey op eration requires kno wledge of the lo cation of the element to b e decreased. Maintaining an array of the lo cations of no des in the heap requires O (log N ) I/Os. F unnel Heap F unnel Heap was implemented following the description in [11]. An imp ortan t limitation of the F unnel Heap is that it do esn’t sup- p ort the DecreaseKey op eration. W e mo dified Dijkstra’s algorithm to replace all DecreaseKey op erations with an Inser t op eration instead. A bit vector is then required to record which vertices hav e b een seen b e- fore. This bit v ector has size V bits but is required to b e kept in in ternal memory separately from the STXXL V ectors. The problem is mitigated b y the fact that the bitset is small compared to both the adjacency list of the graph and the priorit y queue data structure that is built. Without the use of an internal memory bit vector the I/O complexity of Dijkstra’s algorithm using a F unnel Heap is O ( E + E B log M B E B ). Buc k et Heap Buc ket Heap was implemented follo wing the description in [7]. The Buck et Heap implements an Upda te op eration instead of Inser t and DecreaseKey op erations. The Upda te op eration acts as an Inser t if the element is not already in the heap and a DecreaseKey otherwise. This creates the complication that once a vertex has b een remo ved from the heap and settled it ma y b e re-inserted later by an Upda te op eration (acting as an edge relaxation). As we do not w ant to DeleteMin any vertex more than once, this re-insertion must b e undone b y deleting the elemen t. The problem is to iden tify which elements are to b e deleted. T o solve this problem we deplo y a technique given b y Kumar and Sch w ab e [16] for external memory tournamen t trees. In summary , w e allo w spurious Upda te s to o ccur and then delete them b efore they can be returned by the DeleteMin . T o iden tify these spurious up dates a second heap is introduced whic h has an Upd a te p erformed on it for ev ery relaxation of the first heap. Ho wev er, some mo dification of the original metho d of [7] is required to b e able to handle the case where the tw o heaps return elemen ts with iden tical keys. W e therefore pro cess the elemen ts from the second heap t wice, once b efore elements from the main heap and then again afterw ards. The modification leav es the asymptotic I/O complexit y of Dijkstra’s algorithm unchanged. 6 3 Results and Analysis In this Section w e presen t the main exp erimen tal results. A single STXXL V ector was used for each priorit y queue test with asso ciated cache size M set to 16MB. In the tests of Dijkstra’s algorithm, an additional STXXL V ector with asso ciated cac he size 16MB w as used to store the input graph. A further set of tests w as also carried out to test the effect of v arying the cac he size. Priorit y queue tests W e tested the performance of the Binary , F unnel and Buc ket Heap b y p erforming a simple sequence of Inser t and DeleteMin op erations: 1. Inser t N elemen ts with randomly chosen priorities. 2. Perform b N 2 c DeleteMin s. 3. Inser t b N 2 c elemen ts with randomly chosen priorities. 4. Perform N DeleteMin s, leaving the heap empty at the end. Eac h test was terminated automatically if the run time exceeded 6 hours and results quoted are av erages ov er three runs. W e also ran a sec- ond set of tests o ver the range during which Binary Heap began swapping whic h were not rep eated due to the length of time they to ok to run. Figure 1 and T able 3 sho w the results for increasing num b ers of el- emen ts. When the input size is small enough that Binary Heap fits in- side memory its p erformance is consistently sup erior to the tw o external memory heaps. Due to the m uch higher space requiremen ts of F unnel and Buck et Heap b oth also started swapping earlier than Binary Heap. As an example, for 524288 elemen ts Binary Heap sp ends < 5% of the total time waiting for I/O requests while F unnel Heap and Buc ket Heap sp end ∼ 73% and ∼ 32% resp ectively . After ∼ 0.7 million elemen ts Binary Heap starts to sw ap and slows down dramatically . F unnel and Buc ket Heap con tinue to p erform well even once all three structures are sw apping heavily . F unnel Heap completes on ∼ 33 million elemen ts in less time than Binary Heap on 1 million elements and appro x- imately the same time as Buck et Heap on ∼ 8 million elements. The sup e- rior p erformance of F unnel Heap is likely to b e for a n umber of reasons. Not only do es it ha ve an O (log M B ) factor lo wer asymptotic complexity but it is also a considerably less complicated structure than the Buc ket Heap. Another adv an tage the F unnel Heap has ov er Buck et Heap is the use of an extra V internal bits whic h are not swapped out (see Section 2). 7 W e also note that the p ercen tage I/O wait time for F unnel Heap has considerable fluctuations. This is b ecause the heap gro ws in increasingly large jumps as each additional funnel is added. That is, the addition of a single elemen t may require the construction of an entire funnel. It is p os- sible that this fluctuation could b e remo ved b y part building/expanding the funnels only when they are needed. 0 0.5 1 1.5 2 2.5 3 3.5 4 0 1 2 3 4 5 6 7 8 Time (minutes) Largest number of elements (tens of thousands) Priority Queue Tests (Small Inputs, 16MB) Binary Heap Funnel Heap Bucket Heap 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 0 1 2 3 4 5 6 7 8 Time (hours) Largest number of elements (millions) Priority Queue Tests (Large Inputs, 16MB) Binary Heap Funnel Heap Bucket Heap Fig. 1. T otal time taken for Priority Queue tests T able 3. Priority queue tests with 16MB internal memory Size Binary Heap F unnel Heap Buc ket Heap Time (s) I/O wait (%) Time (s) I/O wait (%) Time (s) I/O wait (%) 65536 2 - 2 28.9% 6 9.6% 131072 3 - 4 17.0% 13 6.2% 262144 8 - 7 9.5% 32 15.2% 524288 16 4.4% 123 73.3% 88 32.2% 1048576 6850 99.1% 180 70.9% 255 49.1% 2097152 > 6 hrs - 299 66.9% 694 59.5% 4194304 - - 463 63.7% 1649 63.5% 8388608 - - 843 62.7% 4028 68.0% 16777216 - - 1756 64.3% 9792 71.5% 33554432 - - 4057 69.5% > 6 hrs - Figure 2 giv es the time taken p er op eration for each of the heaps. The time p er op eration for Binary Heap rapidly exceeds 4ms while it remains b elow 0.2ms for b oth Buck et and F unnel Heap even past 16 8 milion elements. F unnel Heap’s time p er op eration is strongly affected by ho w recently a new funnel has b een created, particularly for small input ho wev er its o verall sup erior p erformance is again clear. 0 1 2 3 4 5 0 1 2 3 4 5 6 Time per operation (milliseconds) Largest number of elements (millions) Priority Queue Tests (16MB) Binary Heap Funnel Heap Bucket Heap 0 0.05 0.1 0.15 0.2 0.25 0 5 10 15 20 Time per operation (milliseconds) Largest number of elements (millions) Priority Queue Tests (16MB) Funnel Heap Bucket Heap Fig. 2. Time taken p er element for Priority Queue tests The same tests carried out with M set to 128MB show ed almost ex- actly equiv alent but suitably scaled results. The details are omitted for reasons of space. Shortest path tests The graphs were generated according to the Erd¨ os- R ´ en yi ( G ( n, p )) mo del. In this mo del the structure of a graph is generated based on t wo parameters, the n umber of vertices, n and a probability , p , of each edge existing. W e used integer weigh ts and p = 16 V − 1 giving an exp ected E = 8 V edges. The graphs w ere undirected and all results are a veraged across three test runs. Figure 3 (right) shows the p erformance of Dijkstra’s algorithm run to completion on random graphs with the start no des also chosen at ran- dom. As b efore Binary Heap p erforms well for small graphs but T able 4 sho ws that as the num b er of vertices increases from ∼ 0.75 to ∼ 1 mil- lion vertices Binary Heap’s running time increases b y a factor of ∼ 5.8. Here F unnel Heap’s p erformance is m uch closer to Buc k et Heap’s than in the previous tests. The mo difications made to Dijkstra’s algorithm to accoun t for F unnel Heap’s lack of a DecreaseKey op eration mean that the heap contains O ( E ) elements not O ( V ) elements. While this do es not affect the asymptotic complexity , it is lik ely to b e the main con tributor to the decreased separation b et ween the p erformace of Buck et and F un- 9 nel Heap. Figure 3 (left) shows the p erformance for graphs small enough that the priorit y queues fit completely in RAM. It can clearly b e seen that the structures containing O ( E ) elements start to sw ap heavily at ∼ 35 thousand v ertices. 0 0.5 1 1.5 2 2.5 3 3.5 4 0 1 2 3 4 5 6 7 8 Time (minutes) Number of vertices (tens of thousands) Dijkstra Tests (Small Inputs, 16MB) Binary Heap Funnel Heap Bucket Heap 0 1 2 3 4 5 6 7 8 9 0 2 4 6 8 10 12 Time (hours) Number of vertices (hundreds of thousands) Dijkstra Tests (Large Inputs, 16MB) Binary Heap Funnel Heap Bucket Heap Fig. 3. T otal time tak en in Dijkstra’s Algorithm tests on random graphs T able 4. Selected Dijkstra’s Algorithm tests on random graphs with 16MB in ternal memory V ertices Binary Heap F unnel Heap Buc ket Heap Time (s) I/O wait (%) Time (s) I/O wait (%) Time (s) I/O wait (%) 65536 145 98.2% 313 84.6% 631 63.2% 131072 672 98.9% 1167 92.6% 2124 78.6% 262144 1908 99.1% 3095 94.6% 5628 83.1% 524288 4895 99.1% 8361 96.1% 13987 84.6% 750000 19100 99.4% 13995 96.6% 19725 83.8% 1048576 111061 99.7% 21984 97.0% 26389 83.4% Real world graphs In addition to randomly generated graphs, the al- gorithms w ere run on real world graphs 2 from the DIMA CS shortest path c hallenge[1]. These graphs are almost planar and as a result sparse with 2 The DIMACS SSSP c hallenge graphs are undirected v ersions of the ma jor road net works of the United States of America 10 E < 3 V in all cases. Figure 4 shows the p erformance on these graphs. F unnel Heap p erforms b etter on the real w orld graphs than on the ran- dom graphs due to this increased sparseness. This reduces the ov erhead caused b y having to store O ( E ) elemen ts in its heap. 0 0.2 0.4 0.6 0.8 1 1.2 0 1 2 3 4 5 6 7 Time (hours) Number of vertices (millions) Real World Dijkstra Tests (16MB) Bucket Heap Funnel Heap Binary Heap 15 10 5 192 160 128 96 64 32 0 Time (minutes) Memory size (MB) 20 0 Bucket Heap wall time Bucket Heap I/O wait time 3 2 1 Time (minutes) Varying Memory Priority Queue Tests (1 million elements) 4 0 Funnel Heap wall time Funnel Heap I/O wait time Fig. 4. T otal time taken for Dijkstra’s algorithm on real world graphs (left) and the effects of v arying memory size on the simple priority queue tests (righ t) T able 5. Dijkstra’s Algorithm tests on real world graphs with 16MB in ternal memory V ertices Binary Heap F unnel Heap Buc ket Heap Time (s) I/O wait (%) Time (s) I/O wait (%) Time (s) I/O wait (%) 264346 14 66.2% 138 78.6% 102 10.0% 321270 24 74.8% 146 79.9% 120 17.2% 435666 42 78.6% 164 80.4% 169 22.4% 1070376 107 76.4% 200 74.1% 376 13.8% 1207945 169 82.5% 238 75.9% 452 20.7% 1524453 406 90.0% 411 79.1% 791 29.7% 1890815 510 90.1% 371 76.7% 802 25.8% 2758119 2055 95.8% 528 77.1% 1240 27.5% 3598623 > 6 hrs - 939 81.9% 2120 30.2% 6262104 - - 1983 85.6% 3622 37.8% V arying in ternal memory size W e inv estigated the effect of v arying the in ternal memory size on the Cac he-Oblivious priority queues with 1 million elemen ts. This size w as chosen as it is small enough to b e reason- 11 ably fast to compute but large enough that b oth Buc k et and F unnel Heap are sw apping heavily for all but the largest memory sizes. With 1 million elemen ts, Buc ket and F unnel Heap use ∼ 125MB and ∼ 160MB space re- sp ectiv ely . W e ran tests for memory size of up to 1024MBs (repeated 3 times). Figure 4 shows that ev en once the structures fit completely into memory some I/O is still rep orted b y STXXL. This is due to the set up costs of creating the STXXL V ectors. The most remark able asp ect of the results is that F unnel Heap with 2MB of memory outp erforms Buck et Heap with 1024MB of memory . It is also of in terest that Buc k et Heap app ears to b e affected far more b y v arying memory than F unnel Heap. This is a prop erty of the data structures whic h is not fully captured by their asymptotic I/O complexit y . Ac kno wledgment The authors would like to thank Ashley Mon tanaro for helpful commen ts on the final draft. References [1] 9th DIMACS Implementation Challenge: Shortest Paths. http://www.dis.uniromal/it/$\sim$challenge9/ . [2] Alok Aggarwal and S. Vitter Jeffrey . The input/output complexit y of sorting and related problems. Commun. ACM , 31(9):1116–1127, 1988. [3] Luca Allulli, Peter Lic ho dzijewski, and Norb ert Zeh. A faster cache-oblivious shortest-path algorithm for undirected graphs with bounded edge lengths. In SODA ’07 , pages 910–919. [4] Lars Arge, Michael A. Bender, Erik D. Demaine, Bryan Holland-Minkley , and J. Ian Munro. Cache-oblivious priority queue and graph algorithm applications. In STOC ’02 , pages 268–276. [5] G. Bro dal, R. F agerb erg, and R. Jacob. Cac he oblivious search trees via binary trees of small heigh t. In SODA ’02 , pages 39–48. [6] Gerth Stølting Bro dal and Rolf F agerb erg. F unnel heap - a cache oblivious priority queue. In ISAAC ’02 , pages 219–228. [7] Gerth Stølting Bro dal, Rolf F agerberg, Ulrich Meyer, and Norb ert Zeh. Cac he- oblivious data structures and algorithms for undirected breadth-first search and shortest paths. In SW A T ’04 , pages 480–492. [8] Gerth Stølting Bro dal, Rolf F agerb erg, and Kristoffer Vin ther. Engineering a cac he-oblivious sorting algorithm. J. Exp. Algorithmics , 12, 2007. [9] Siddhartha Chatterjee and Sandeep Sen. Cache-efficien t matrix transp osition. In HPCA ’00 , pages 195–205. [10] Rezaul Alam Chowdh ury and Vijay a Ramachandran. Cache-oblivious shortest paths in graphs using buffer heap. In SP AA ’04 , pages 245–254. [11] Erik D. Demaine. Cache-Oblivious algorithms and data structures. In L e ctur e Notes fr om the EEF Summer Scho ol on Massive Data Sets . BRICS, Universit y of Aarh us, Denmark, June 27–July 1 2002. [12] Roman Dementiev, Lutz Kettner, and P eter Sanders. STXXL: Standard template library for XXL data sets. In ESA ’05 , pages 640–651. 12 [13] Matteo F rigo, Charles E. Leiserson, Harald Prokop, and Sridhar Ramachandran. Cac he-Oblivious algorithms. In F OCS ’99 , pages 285–298. [14] Hema Jampala and Norbert Zeh. Cac he-oblivious planar shortest paths. In ICALP ’05 , pages 563–575. [15] Piyush Kumar. Cac he oblivious algorithms. In Algorithms for Memory Hier ar- chies: A dvanc e d L e ctur es , pages 193–212, 2003. [16] Vijay Kumar and Eric J. Sch wabe. Improv ed algorithms and data structures for solving graph problems in external memory . In SPDP ’96 , pages 169–177. [17] R. Ladner, R. F ortna, and B. Nguyen. A comparison of cache a ware and cache oblivious static search trees using program instrumen tation. In Exp erimental Algorithmics: F r om Algorithm Design to R obust and Efficient Softwar e , 2002. [18] Ulrich Meyer and Norb ert Zeh. I/O-efficient undirected shortest paths with un- b ounded edge lengths. In ESA ’06 , pages 540–551. [19] Jesp er Holm Olsen and Søren Sk ov. Cac he-oblivious algorithms in practice. http: //www.dunkel.dk/thesis/ , 2002. [20] D. Tsifakis, A.P . Rendell, and P .E. Strazdins. Cache oblivious matrix transp osi- tion: Simulation and exp eriment. In Computational Scienc e - ICCS 2004 , pages 17–25. Springer Berlin / Heidelberg, 2004.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment