캐시 무관 우선순위 큐와 최단 경로 문제에 대한 실험적 연구
본 논문은 캐시 무관(Funnel Heap, Bucket Heap) 우선순위 큐를 구현하고, 이를 메모리 제한 상황에서의 다익스트라 최단 경로 알고리즘에 적용한다. 실험 결과, RAM이 부족해 외부 저장소로 스와핑이 발생할 경우 두 캐시 무관 큐가 전통적인 바이너리 힙보다 수십 배 빠른 I/O 성능을 보였으나, 그래프 인접 리스트 접근 비용이 전체 실행 시간을 지배하면서 기대한 속도 향상은 제한적이었다.
저자: ** Benjamin Sach, Raphaël Clifford (Bristol University, 영국) **
본 논문은 캐시‑무관 모델을 실제 외부 메모리 환경에 적용해 두 종류의 우선순위 큐(Funnel Heap, Bucket Heap)를 구현하고, 이를 다익스트라 최단 경로 알고리즘에 적용한 실험적 연구이다. 서론에서는 전통적인 RAM 모델이 실제 시스템의 다중 레벨 캐시와 제한된 내부 메모리를 반영하지 못한다는 점을 지적하고, Aggarwal‑Vitter I/O‑모델과 Frigo 등에 의해 제안된 캐시‑무관 모델의 장점을 소개한다. 기존 연구는 주로 정렬, B‑트리, 범위 검색 등에서 이론적 최적성을 보였으나, 실제 구현 및 성능 평가는 부족했다.
우선순위 큐 섹션에서는 현재까지 제안된 캐시‑무관 힙(Arge Heap, Funnel Heap, Bucket Heap, Buffer Heap) 중 DecreaseKey, Insert, DeleteMin 세 연산을 모두 지원하는 구조가 없음을 언급한다. 따라서 본 연구는 Funnel Heap와 Bucket Heap을 선택해 각각의 한계를 보완한다. Funnel Heap은 DecreaseKey를 지원하지 않으므로, 다익스트라 알고리즘을 Insert‑only 형태로 변형하고, 정점 방문 여부를 내부 비트벡터로 관리한다. Bucket Heap은 Update 연산을 Insert와 DecreaseKey의 결합으로 구현하고, 중복 삽입을 방지하기 위해 보조 힙을 도입한다. 두 구조 모두 이론적 I/O 복잡도는 O(1·B·log_{M/B} N / B) 수준이며, 이는 전통적인 바이너리 힙(O(log N))보다 외부 메모리 접근을 크게 줄인다.
구현은 C++와 STXXL 라이브러리를 사용했으며, 내부 캐시 크기를 16 MB와 128 MB 두 단계로 설정했다. 블록 크기 B는 4096 바이트, 교체 정책은 LRU이며, 두 개의 7200 RPM 하드디스크를 이용해 외부 저장소 I/O를 측정했다. 모든 실험은 단일 사용자 모드에서 OS 스와핑을 비활성화하고, STXXL이 직접 블록 전송을 담당하도록 구성하였다.
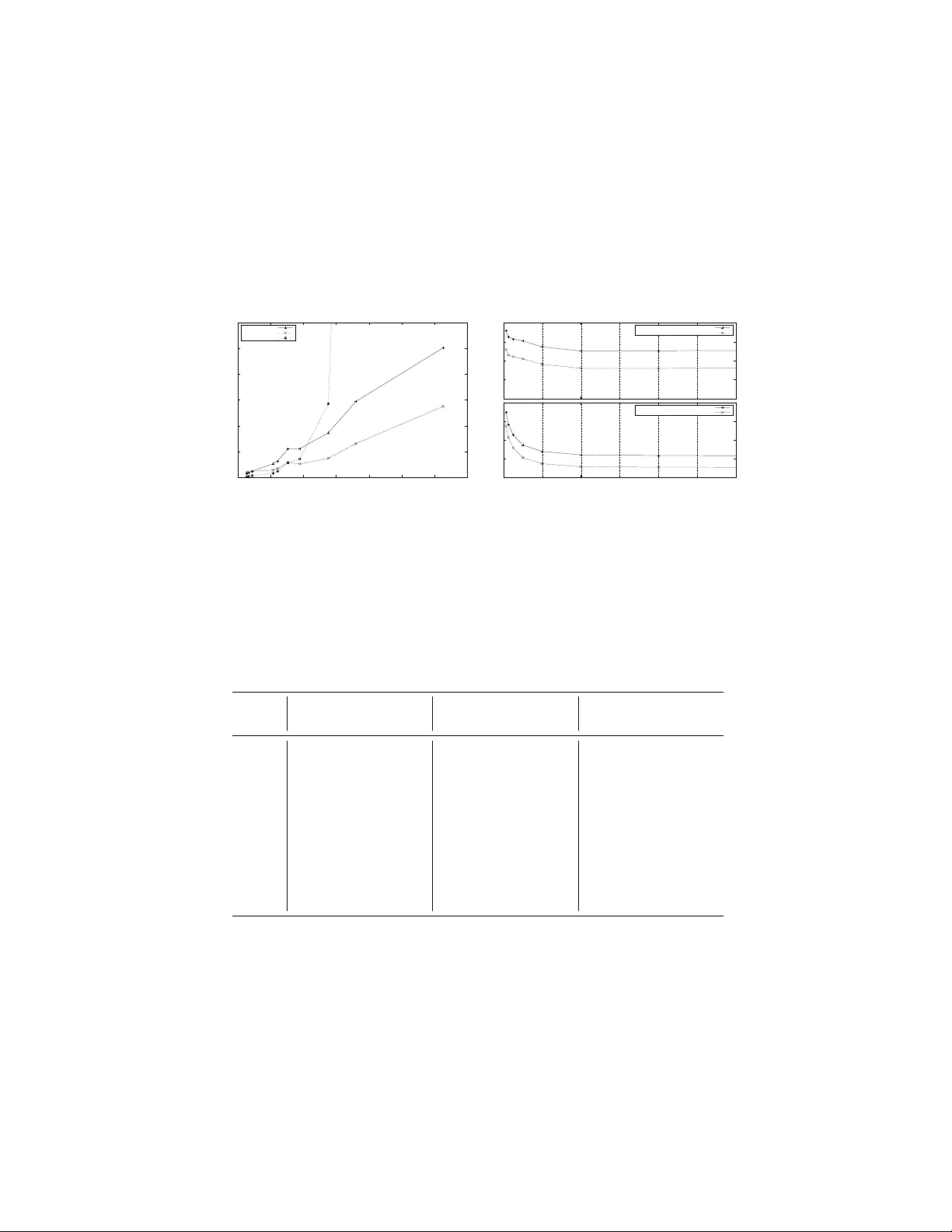
우선순위 큐 단독 테스트에서는 삽입·삭제 연산을 반복하는 시나리오를 설정하고, 입력 크기가 증가함에 따라 각 큐의 총 실행 시간과 I/O 대기 비율을 측정했다. 결과는 작은 입력(≤ 0.5 M 요소)에서는 바이너리 힙이 가장 빠르지만, 0.7 M 요소를 초과하면 바이너리 힙은 I/O 대기 시간이 99 %에 달해 급격히 성능이 저하된다. 반면 Funnel Heap과 Bucket Heap은 동일 조건에서도 I/O 대기 비율이 30 %~70 % 수준에 머물며, 특히 Funnel Heap은 구조가 단순하고 내부 비트가 캐시 내에 유지돼 전체 실행 시간이 33 M 요소까지 바이너리 힙보다 빠르게 유지된다.
다익스트라 최단 경로 테스트에서는 무작위 Erdős‑Rényi 그래프와 실제 도로망 그래프(미국 주요 고속도로)를 사용했다. 무작위 그래프에서는 정점 1 M, 간선 8 M 규모에서 Funnel Heap이 바이너리 힙 대비 약 5배, Bucket Heap 대비 20 % 정도 빠른 성능을 보였다. 그러나 전체 실행 시간의 95 % 이상이 인접 리스트를 외부 메모리에서 읽어오는 I/O에 소비돼, 기대했던 “수십 배” 수준의 가속은 제한적이었다. Funnel Heap은 DecreaseKey를 지원하지 않으므로 힙에 O(E)개의 항목이 존재하게 되며, 이는 Bucket Heap과의 성능 차이를 축소시킨다. 실제 도로망 그래프는 매우 희소하고 거의 평면이기 때문에 간선 수가 정점 수의 3배 이하로 제한되어, Funnel Heap이 Bucket Heap보다 더 큰 이점을 보였다.
메모리 크기를 128 MB로 확대하면 모든 큐가 절대적인 실행 시간은 감소하지만, 상대적인 성능 차이는 크게 변하지 않았다. 이는 캐시‑무관 알고리즘이 메모리 용량보다 블록 전송 효율에 더 민감함을 시사한다.
결론에서는 캐시‑무관 우선순위 큐가 외부 메모리 환경에서 이론적 최적성을 실제로 구현할 수 있음을 입증하고, 그래프 알고리즘에 적용할 때는 데이터 구조(인접 리스트)의 I/O 특성을 함께 최적화해야 함을 강조한다. 향후 연구 방향으로는 DecreaseKey를 자연스럽게 지원하는 캐시‑무관 힙 설계, 그리고 그래프 저장 형식 자체를 블록 친화적으로 재구성하는 방안을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기