Penalized Clustering of Large Scale Functional Data with Multiple Covariates
In this article, we propose a penalized clustering method for large scale data with multiple covariates through a functional data approach. In the proposed method, responses and covariates are linked together through nonparametric multivariate functi…
Authors: Ping Ma, Wenxuan Zhong
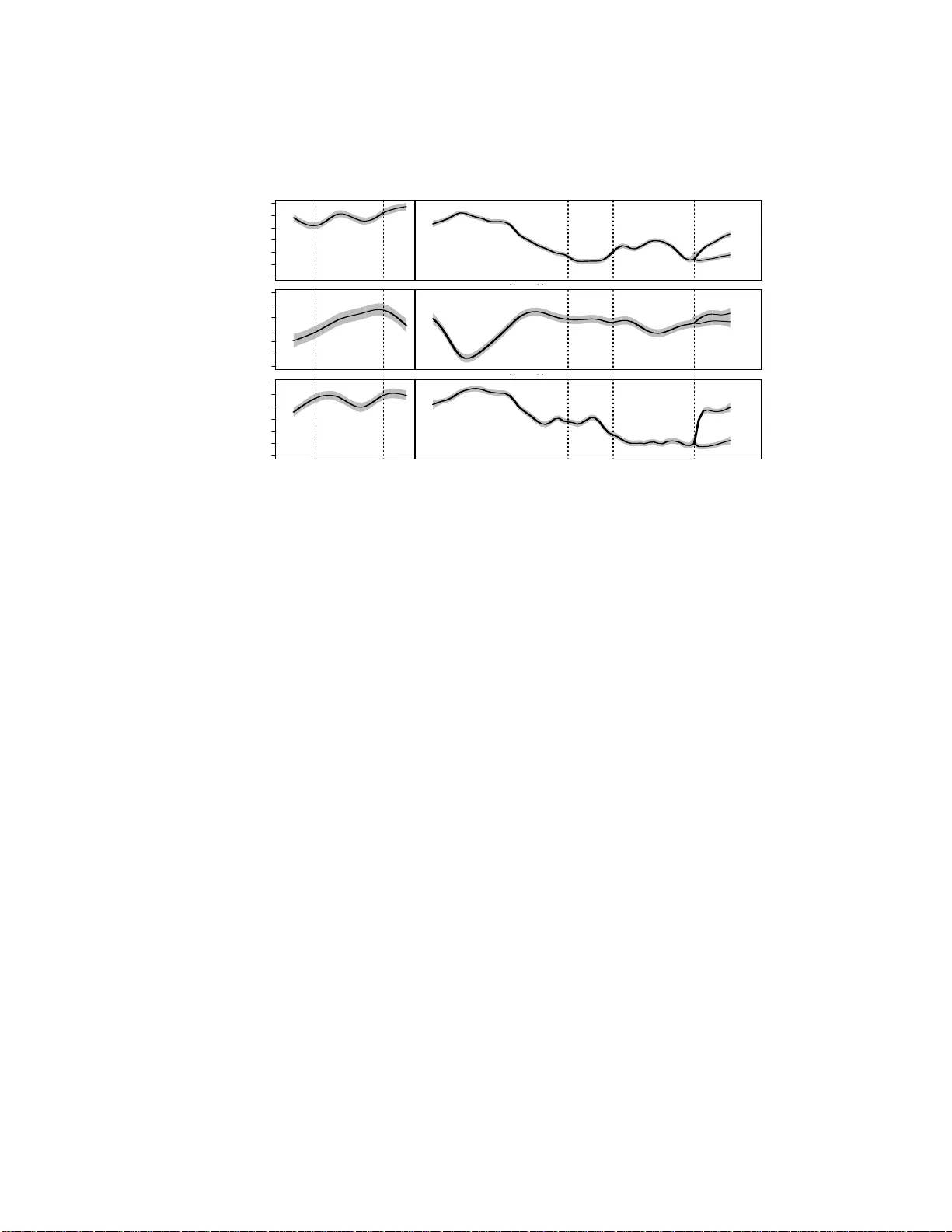
P enalized Clustering of Large Scale F unctional Data with Multiple C o v ariates Ping Ma and Wenxuan Zhong ∗ Abstract In this article, we prop ose a pen alized clustering method for large scale data with m ultiple co v ariates through a functional data approac h . In the prop osed metho d, resp onses an d co v ariates are link ed together t hrough nonparametric m ultiv ariate fun ctions (fixed effects), whic h ha v e great flexibilit y in m o deling a v ariet y of function features, such as jump p oin ts, branching, and p erio dicit y . F unctional ANOV A is employ ed to further decomp ose m ultiv ariate fun ctions in a repro du cing k ernel Hilb ert space and pro vide asso ciated notions of main effect and in teraction. P arsimonious rand om effects are used to capture v arious corre- lation structures. T he mixed-effect mo dels are nested under a general m ixture mo del, in wh ic h the heterogeneit y of fu n ctional data is c h aracterize d. W e pro- p ose a p enalized Henderson’s likeli ho o d appr oac h for mo d el-fitting and design a rejection-con trolled EM alg orithm for the estimation. Our metho d selects ∗ Ping Ma and W enxuan Zhong are Assis tan t P rofessor s (E -mail: pingma , wenxuan@uiuc.edu), Department of Sta tistics, Universit y of Illinois , Champa ign, IL 61 820. P M’s resea rch was par tially suppo rted by National Science F oundation g rant DMS-0 72375 9. The a uthors are grateful to Jun S. Liu, Chong Gu, Y u Zhu, Xuming He, Steve Portnoy for many illuminating discussio ns on this article. The a utho rs thank Kurt Kwast for pr oviding the yeast micr oarray data. The autho rs also thank the editor, the asso ciate editor, the tw o refere es, Jo hn Marden, and Ada m Martinsek for their constructive comments and suggestions that have led to significa n t improv ement of this article. 1 smo othing parameters through generalized cross-v alidatio n. F urthermore, the Ba yesia n confidence in terv als are u sed to measure the clustering u ncertain ty . Sim ulation studies and r eal-data examples are p r esen ted to inv estigate th e em- pirical p erformance of the prop osed metho d. Op en-source co de is a v ailable in the R pac k age MFD A. Key wor ds: Clustering, F unctional Data Analysis, Mixed-Effect Mo del, Smo othing Splin e, EM Algorithm. R unning title: Penalize d clustering of f u nctional data. 1 In tro duction With the rapid adv ancemen t in hig h throughput tec hnology , extensiv e rep eated mea- suremen ts ha ve b een tak en t o mo nit o r the system-wide dynamic s in man y scien tific in v estigations. A ty pical example is temp oral gene expression studies, in whic h a series of micora r r a y exp erimen ts are conducted sequen t ia lly during a biological pro cess, e.g., cell cycle microarray exp erimen ts (Sp ellman et al. 1 9 98). A t each time p oin t, mRNA expression lev els of thousands of genes are measured simu ltaneously . Collected ov er time, a gene’s “temp oral expression profile” giv es the scien tist some clues on what role this gene might pla y during the pro ces s. A group of g enes with similar profiles are often “co-regulated” or participants of a common and imp ort a n t biolog ical function. Th us clustering genes in to homogeneous gro ups is a crucial first step to decipher the underlying mec hanism. The need to account fo r in trinsic temp oral dependency of rep eated observ ations within the same individual renders traditional metho ds such as K-means and hierarc hical clustering inadequate. By casting rep eated observ ations as m ult iv a r ia te data with certain correlation structure, one ignores the time interv al a nd time order of sampling. Additionally , missing observ ations in the measuremen ts yield an unbalanced design, whic h requires imputation b eforehand fo r application of m ul- 2 tiv ariate approac hes, e.g., the m ultiv ariate G a ussian clustering metho d (MCLUST, F raley and Raftery 199 0). In addition to the time factor, suc h rep eated measuremen ts often con tain other co v ariates, e.g., replicates at each time p oint, sp ecies in comparativ e genomics studies (McCarroll et al. 2004), and treatmen t groups in case-con trol studies (Storey et a l. 2005), as w ell as man y factors in a factorial designed exp erimen t. Incorp oratio n of multi- ple cov ariates adds a nother lay er of complexit y . Clustering metho ds ta king all these factors in t o accoun t are still lac king. Recen tly , nonparametric analysis of data in the form o f curv es, i.e. functional data, is sub ject to active researc h. See Ramsa y and Silv erman (2 005, 20 02) for a com- prehensiv e treatmen t of functional data analysis . A curv e-based clustering metho d (F CM) w as in tro duced in James and Sugar (20 0 3) to cluster sparsely sampled func- tional data. Similar approache s were deve lop ed in Luan and Li (20 03, 2004) and Heard et al. (2006) to analyze temp oral gene express ion data. Although these meth- o ds mo del the time factor explicitly , none of them a re designed to accommo date additional factors. Moreo ver, smo othing-related para meters, e.g., knots and degrees of freedom, in these metho ds a re the same across a ll clusters and m ust b e sp ecified a priori . Consequen t ly , they can not mo de l drastically differen t patterns among differ- en t clus ters, whic h le ads to high false classification rat e. Finally , the computational costs of these metho ds are v ery high f or large scale data. Motiv ated b y analysis of temporal gene expression data, we prop ose a flexible functional data clustering method that o verc omes the a foremen tioned obstacles. In our prop osed metho d, resp o nses and cov ariates are link ed together thro ugh nonpara - metric m ultiv ariate functions (fixed effects), whic h ha v e great flexibilit y in mo delin g a v ariet y of function features, suc h as jump p oints, bra nc hing, and p erio dicity . F unc- tional ANO V A is emplo yed to further decomp ose m ultiv ariate functions (fixed effects) in a repro ducing k ernel Hilb ert space and pro vide asso ciated notions of main effect 3 and in teraction (W ah ba 1990 a nd Gu 2002). P a r simonious random effects, comple- men ting the fixed effects, a re used to capture v arious correlation structures. The mixed-effect mo dels are nested under a general mixture mo del, in whic h the hetero- geneit y of the functional dat a is c haracterized. W e prop ose a p enalized Henderson’s lik eliho o d approac h f o r mo del-fitting and design a rejection-con trolled EM algorithm for estimation. In this EM algorithm, the E-step is follow ed b y a rejection-controlled sampling step (L iu et a l. 1 9 98) to eliminate a significan t n um b er of functional obser- v ations, whose p osterior probabilities of b elonging to a particular cluster is negligible, from calculation in the subsequen t M-step. The M-step is decomp osed in to the si- m ult a neous maximization of p enalized weigh ted least squares in eac h cluster. The smo othing pa rameters asso ciated with the p enalt y a r e selected b y generalized cross- v alidation, whic h can b e sho wn to trac k a squared error lo ss asymptotically . Our metho d is th us data-ada ptive and automatically captures some imp ortan t functional fluctuations. F o r mo del selection, we emplo y BIC to select the num b er o f clusters. Moreo v er, the prop o sed metho d not only pro vides sub ject-to-cluster assignmen t but also the estimated mean function and asso ciated Ba y esian confidence in terv als for eac h cluster. The Ba y esian confidence interv als are used to measure the clustering uncertain ty . These nice features mak e the prop osed metho d extremely p ow erful for clustering large scale functional data. The remainder of the article is organized as follow s. In Section 2, w e presen t a nonparametric mixed-effect mo del represen tation for functional dat a . A mixture mo del for clus tering is considered in Section 3. Simulation and real data analysis follo w in Section 4 a nd 5. A few remarks in Section 6 conclude the article. Pro ofs of the theorems are collected in App endix. 4 2 Nonparametric Mixed-E ffe ct Rep resen tation of Homogeneo u s F unctional Data Assuming the data are homogeneous, i.e., the num b er of clusters is one, we shall presen t a mixed-effect represen ta tion of functional observ ations. 2.1 The Mo del Sp ecification W e assume the f unctiona l data of the i th individual, y i = ( y i 1 , · · · , y in i ) T , fo llo ws the mixed-effect mo del, y i = µ ( x i ) + Z i b i + ǫ i , (2.1) where the p opulation mean µ is a ssumed to b e a smo o t h function defined on a g eneric domain Γ, x i = ( x i 1 , . . . , x in i ) T is an ordered set of sampling p oin ts, b i ∼ N (0 , B ) is a p × 1 random effect v ector asso ciated with a n i × p design matrix Z i , and random errors ǫ i ∼ N ( 0 , σ 2 I ) are indep enden t of b i ’s, and of each other. The random effect co v ariance matrix B and random erro r v ariance σ 2 are to b e estimated fro m the data. Mo del (2.1) has b een extensiv ely studied in the statistical literature. See W ang (1998), Zhang et al. (1998), Gu and Ma (2005), and references t herein. F or m ultiv ariate x where x = ( x h 1 i , x h 2 i , · · · , x h d i ) T , each en try x h k i tak es v alues in some fairly general domain Γ k , i.e., Γ = ⊗ d k =1 Γ k . Some examples are Example 2.1 Γ = [0 , T ] × { 1 , · · · , c } to mo del temp oral v ariation from time 0 t o time T under m ultiple conditions; Γ = Circle × { 1 , · · · , s } to mo del p erio dicit y of a biological pro cess of m ultiple sp ecies. The functional ANOV A decomp osition of a m ultiv ariate function µ is µ ( x ) = µ 0 + d X j =1 µ j ( x h j i ) + d X j =1 d X k = j +1 µ j k ( x h j i , x h k i ) + · · · + µ 1 , ··· ,d ( x h 1 i , · · · , x h d i ) (2.2) 5 where µ 0 is a constan t, µ j ’s are the main effects, µ j k ’s are the t w o-w a y in teractions, and so on. The iden tifiability of the terms in (2.2) is assured b y side conditions through a v era g ing op erat ors. See W ah ba (199 0) and Gu (2002). By using different sp ecifications of the random effect b i and asso ciated design matrix Z i , mo del (2.1) can a ccommo da t e v arious correlation structures. Example 2.2 If w e let p = 1, i.e., b i is a scalar, B = σ 2 b and Z i = 1 , we ha v e the same correlation across time. If w e let p = 2, i.e. b i = ( b i 1 , b i 2 ) T , B = σ 2 b 1 σ 2 b 1 b 2 σ 2 b 1 b 2 σ 2 b 2 and Z i = ( 1 , x i ), the difference b et w een the i th sub ject profile and the mean profile is a linear function in time. The cov aria nce b et w een expression v alues at x 1 and x 2 for the same individual is σ 2 b 1 + ( x 1 + x 2 ) σ 2 b 1 b 2 + x 1 x 2 σ 2 b 2 . 2.2 Estimation Mo del (2.1) is estimated using p enalized least squares through the minimization of n X i =1 ( y i − µ ( x i ) − Z i b i ) T ( y i − µ ( x i ) − Z i b i ) + n X i =1 σ 2 b T i B − 1 b i + N λM ( µ ) , (2.3) for N = P i n i , where the first term measures the fidelit y of the mo del to the data, M ( µ ) = M ( µ, µ ) is a quadratic functional t ha t quantifie s the roughness of µ , a nd λ is the smo othing parameter that controls the trade-off b etw een the go o dness-of-fit and the smo othness of µ . (2.3) is also referred to as p enalize d Henderson’s lik eliho o d since t he first tw o terms are prop ortional to the jo in t density (Henderson’s lik eliho o d) of ( y i , b i ) (Robinson 1991). T o minimize (2.3) , we only need to consider smo oth functions in t he space { µ : M ( µ ) < ∞} or subspace therein. As a abstract generalization o f the vector spaces used extensiv ely in mu ltiv ariate analysis, Hilb ert spaces inherit many nice prop erties 6 of the v ector spaces. Ho wev er, the Hilb ert space is to o lo o se to use for functiona l data analysis since ev en the ev aluation functional [ x ]( f ) = f ( x ), the simplest func- tional one may encoun t er, is not guaran teed to b e con tin uous in a general Hilb ert space. An example is that in the Hilb ert space of square in tegra ble functions de- fined on [0,1], ev a lua tion is not ev en w ell defined. Consequen tly , one may fo cus on a constrained Hilb ert space for whic h the ev aluation functional is con t inuous. Suc h a Hilb ert space is referred t o as a repro ducing k ernel Hilb ert space (RK HS), for whic h Ramsay and Silv erman (2005) suggested a nic kname: con tin uous Hilb ert space. F or example, the space of functions with square integrable second deriv atives is an RKHS if it is equipp ed with appropriate inner pro ducts (Gu 2002). F or the ev aluation functional [ x ]( · ), b y the Riesz represen tat ion theorem, there exists a non- negativ e definite biv ar ia te function R ( x, y ), the repro ducing k ernel, which satisfies h R ( x, · ) , f ( · ) i = f ( x ), called the “represen ter” of [ x ]( · ), in RKHS. Giv en an RKHS, w e ma y deriv e the repro ducing kerne l from the Green’s function asso ciated with the quadratic functional M ( µ ). Since the construction of repro ducing k ernel is b ey ond the scop e of this article, readers ma y refer to W ah ba (1990) and Gu (2002) f o r details. The minimization of (2.3) is p erfo rmed in a repro ducing k ernel Hilb ert space H ⊆ { µ : M ( µ ) < ∞} in whic h M ( µ ) is a square semi norm. T o incorp ora te (2.2) in estimating multiv ariate functions, w e consider µ j ∈ H h j i , where H h j i is a repro ducing k ernel Hilb ert space with tensor sum decomp osition H h j i = H 0 h j i ⊕ H 1 h j i where H 0 h j i is the finite-dimensional “parametric” subspace consisting of parametric functions, and H 1 h j i is the “no nparametric” subspace consisting of smo oth f unctions. The induced tensor pro duct space is H = ⊗ d j =1 H h j i = ⊕ S [( ⊗ j ∈S H 1 h j i ) ⊗ ( ⊗ j / ∈S H 0 h j i )] = ⊕ S H S , where the summation runs ov er all subsets S ⊆ { 1 , · · · , d } . These subspaces H S form 7 t w o large subspaces: N M = { η : M ( µ ) = 0 } , whic h is the null space of M ( µ ) , and H ⊖ N M with the repro ducing k ernel R M ( · , · ). The solution of (2.3) has an expression µ ( x ) = m X ν =1 d ν φ ν ( x ) + T X i =1 c i R M ( s i , x ) , (2.4) where { φ ν } m ν =1 is a basis of N M , and d ν and c i are the co efficien ts, s = ( s 1 , · · · , s T ) is a distinct com bination of all x ij ( i = 1 , · · · , n, j = 1 , · · · , n i ). Example 2.3 Consider the temp or a l v ariat io n under a treatmen ts. T ak e the fixed effect as µ ( t, τ ), where τ ∈ { 1 , . . . , a } denotes the treatmen t lev els. One ma y decom- p ose µ ( t, τ ) = µ ∅ + µ 1 ( t ) + µ 2 ( τ ) + µ 1 , 2 ( t, τ ) , where µ ∅ is a constan t, µ 1 ( t ) is a function of t satisfying µ 1 (0) = 0, µ 2 ( τ ) is a function of τ satisfying P a τ =1 µ 2 ( τ ) = 0 , and µ 1 , 2 ( t, τ ) satisfies µ 1 , 2 (0 , τ ) = 0, ∀ τ , and P a τ =1 µ 1 , 2 ( t, τ ) = 0, ∀ t . The term µ ∅ + µ 1 ( t ) is the “ a v erage v ariation” and the term µ 2 ( τ ) + µ 1 , 2 ( t, τ ) is the “contrast v ariation”. F or flexible mo dels, o ne ma y use M ( µ ) = θ − 1 1 Z T 0 ( d 2 µ 1 /dt 2 ) 2 dt + θ − 1 1 , 2 Z T 0 a X τ =1 ( d 2 µ 1 , 2 /dt 2 ) 2 dt, (2.5) whic h has a n ull space N M of dimension 2 a . A set of φ ν are giv en b y { 1 , t, I { j } ( τ ) − 1 /a, ( I { j } ( τ ) − 1 /a ) t, j = 1 , . . . , a − 1 } , and the function R M is giv en b y R M ( t 1 , τ 1 ; t 2 , τ 2 ) = θ 1 Z T 0 ( t 1 − u ) + ( t 2 − u ) + du + θ 1 , 2 ( I { τ 1 } ( τ 2 ) − 1 /a ) Z T 0 ( t 1 − u ) + ( t 2 − u ) + du 8 See, e.g., Gu (2002, § 2.4.4). T o force an additiv e mo del µ ( t, τ ) = µ ∅ + µ 1 ( t ) + µ 2 ( τ ) , (2.6) whic h yields pa rallel curv es at differen t treatments , one may set θ 1 , 2 = 0 and remo ve ( I { j } ( τ ) − 1 /a ) t from the list o f φ ν . Substituting (2.4) into (2.3), w e hav e ( y − Sd − R c − Zb ) T ( y − Sd − Rc − Zb ) + b T Ωb + N λ c T Qc , (2.7) where y = ( y T 1 , · · · , y T n ) T , d = ( d 1 , · · · , d m ) T , c = ( c 1 , · · · , c T ) T , b = ( b T 1 , · · · , b T n ) T , S = ( S T 1 , · · · , S T n ) T with the ( k , ν )th entry o f the n i × m matrix S i equal to φ ν ( t ik ), R = ( R T 1 , · · · , R T n ) T with the ( l , j )th entry of the n i × T matrix R i equal to R M ( t il , s j ), the design ma t r ix Z = diag( Z 1 , · · · , Z n ), Ω = σ 2 diag( B − 1 , · · · , B − 1 ) and Q is T × T matrix with the ( j, k )th en try equal to R M ( s j , s k ). Differen tiating (2.7) with resp ect to d , c and b and setting t he deriv ativ es to 0, one has S T S S T R S T Z R T S R T R + ( N λ ) Q R T Z Z T S Z T R Z T Z + Ω ˆ d ˆ c ˆ b = S T y R T y Z T y . (2.8) The system (2.8) can b e solv ed through the piv o ted Cholesky decompo sition follo w ed b y bac kward and forw ard substitutions. See, e.g., Kim a nd G u ( 2 004) for details. The fitted v alues ˆ y = S ˆ d + R ˆ c + Z ˆ b of (2.3 ) can b e written as ˆ y = A ( λ, Ω ) y , 9 where A ( λ, Ω ) is the smo othing matrix g iven b elo w, A ( λ, Ω ) = ( S , R , Z ) S T S S T R S T Z R T S R T R + ( N λ ) Q R T Z Z T S Z T R Z T Z + Ω + S T R T Z T , (2.9) and C + denotes the Mo ore-P enrose in vers e o f C satisfying CC + C = C , C + CC + = C + , ( CC + ) T = CC + and ( C + C ) T = C + C . With v arying smo othing parameters λ (including θ ) and correlation par a meters Ω , (2.8) defines an a rra y of p ossible estimates, in whic h we need to c ho ose a sp ecific one in practice. A classic data - driv en approach f or selecting the smo o thing parameter λ is generalized cross-v alidatio n (GCV), whic h w as prop osed in Crav en and W ahba (1979). T reating the correlation parameters Ω a s extra smo othing parameters, w e a do pt the approac h of G u a nd Ma (2005) to estimate λ and the correlation parameters Ω si- m ult a neously through minimizing the GCV score V ( λ, Ω ) = N − 1 y T ( I − A ( λ, Ω )) 2 y { N − 1 tr( I − A ( λ, Ω ) ) } 2 . (2.10) Since the GCV score V ( λ, Ω ) is non- quadra t ic in λ and Ω , one ma y emplo y standard nonlinear optimization alg o rithms to minimize the GCV as a function of the tuning parameters. In particular, w e used the mo dified Newton algorithm dev elop ed b y Dennis and Sc hnab el (1 996) to find the minimizer. The distinguishing feature of generalized cross-v alidation is that its asymptotic optimality can b e justified in a decision-theoretic framew ork. One ma y define a quadratic lo ss function as, L ( λ, Ω ) = 1 N n X i =1 ( ˆ y i − µ ( x i ) − Z i b i ) T ( ˆ y i − µ ( x i ) − Z i b i ) . 10 Under general conditions, Gu and Ma (20 0 5) show ed t ha t the GCV t rac ks the lo ss function asymptotically , V ( λ, Ω ) − L ( λ, Ω ) − 1 N n X i =1 ǫ T i ǫ i = o p ( L ( λ, Ω )) . Note that ǫ i do es not dep end on λ and Ω . It then follows that the minimizer of the GCV score V ( λ, Ω ) approximately minimizes the loss function L ( λ, Ω ). 2.3 Ba y esian Confidence In terv als Unlik e confidence estimates in para metric mo dels, a rigorously justified in terv al esti- mate is a r arit y for nonparametric functional estimation. An exception is the Bay esian confidence in terv al dev elop ed b y W ah ba (198 3) fro m a Ba y es mo del. A nice feature of Ba y esian confidence in terv als is that they ha ve a certain a cro ss-the-f unction co v er- age prop ert y . See Nyc hk a (1988). In this section, we derive the p osterior mean and v ariance for constructing Bay esian confidence interv als in our setting. The regularization is equiv alen t to imp osing a prior on the functional form of µ ( x ). T o see this,w e decomp ose µ = f 0 + f 1 , where f 0 has a diffuse prior in the space N M and f 1 has an indep enden t Gaussian pro ce ss prior with mean zero and co v aria nce, E [ f 1 ( s k ) f 1 ( s l )] = σ 2 N λ R M ( s k , s T ) Q + R M ( s , s l ) . (2.11) The minimizer of ( 2.3) can b e show n to b e the p osterior mean under the ab ov e prior b y the follo wing theorem. Theorem 2.1 With the prior for µ sp e cifie d a b ove and a generic np × 1 ve ctor z , the 11 p osterior me an of µ ( x ) + z T b has the fol lowing expr ession: E [ µ ( x ) + z T b | y ] = φ T ˆ d + ξ T ˆ c + z T ˆ b , (2.12) wher e φ is m × 1 with the ν th entry φ ν (x), ξ is T × 1 with the i th entry R ( s i , x ) , ˆ d , ˆ c , an d ˆ b ar e the solutions of (2.8). The p osterior v ariance is giv en in t he follo wing theorem. Theorem 2.2 Under the mo del sp e cifie d in The or em 2.1, the p o sterior varianc e has the fol lowing expr ession: N λ σ 2 V ar [ µ ( x ) + z T b | y ] = ξ T Q + ξ + N λ z T Ω + z + φ T ( S T W − 1 S ) − 1 φ − 2 φ T ( S T W − 1 S ) − 1 S T W − 1 R Q + ξ − 2 N λ φ T ( S T W − 1 S ) − 1 S T W − 1 ZΩ + z − ( ξ T Q + R T + N λ z T Ω + Z )( W − 1 − W − 1 S ( S T W − 1 S ) − 1 S T W − 1 )( R Q + ξ + N λ ZΩ + z ) , wher e W = R Q + R T + N λ ZΩ + Z T + N λ I . The pro ofs of the a b o v e t wo theorems are give n in App endix. Using Theorem 2.1 and Theorem 2.2, w e construct the 100 ( 1 − α )% Bay esian confidence in terv als as, E [ µ ( x ) + z T b | y ] ± Φ(1 − α / 2) − 1 p V ar[ µ ( x ) + z T b | y ], where Φ(1 − α / 2) − 1 is the 100(1 − α/ 2) p ercen tile of the standard Gaussian distribution. Letting z = 0, w e get Ba y esian confidence inte rv als for µ ( x ). Note that the construction of Bay esian con- fidence in terv als is p oin t wise. It is unclear whether the across-the-function cov erage prop ert y of Nyc hk a (1988) holds in our case. 12 3 The Mixture Mo del Based o n the mixed-effect represen tatio n of homogeneous functional data, w e shall no w presen t a mixture mo del for characterizin g the heterogeneit y . 3.1 The Mo del Sp ecification When the p opulation is heterogeneous, we assume that the i th f unctional o bserv at io n can b e mo deled as y i = µ k ( x i ) + Z i b i + ǫ i with probabilit y p k (3.1) where k = 1 , · · · , K , the k th cluster’s mean µ k is a smo oth function defined on a generic domain Γ, b i ∼ N (0 , B k ) is a p × 1 random effect v ector asso ciated with a n i × p design matrix Z i , ǫ i ∼ N (0 , σ 2 I ) are ra ndo m errors indep enden t of the b i ’s and of each other, cluster probabilities p k satisfy P K k =1 p k = 1 , and K is the n um b er of clusters in the p opulation. T o ease the computation, we intro duce a “la ten t” mem b ership lab eling v aria ble J ik suc h that J ik = 1 indicates individual i b elongs to the k t h cluster a nd J ik = 0 otherwise. Th us w e ha v e the pro babilit y that J ik = 1 is p k . The mixture Henderson’s lik eliho o d is seen to b e n X i =1 log K X k =1 [ p k f y ( y i ; b i , J ik = 1) f b ( b i ; J ik = 1)] where f y and f b are probability densit y functions for y i and b i resp ectiv ely . 13 3.2 Estimation The negativ e p enalized Henderson’s lik eliho o d of complete data ( y i , J ik ) where i = 1 , · · · , n , is seen to b e L c = Constan t − n X i =1 K X k =1 J ik log p k + 1 2 σ 2 n X i =1 K X k =1 J ik [( y i − µ k ( x i ) − Z i b i ) T ( y i − µ k ( x i ) − Z i b i )+ σ 2 b T i B − 1 k b i ]+ K X k =1 N λ k M ( µ k ) (3.2) where λ k is the smo othing parameter f o r µ k . Once t he p enalized Henderson’s lik eliho o d (3.2 ) is obtained, the EM algorithm (Dempster et al. 1 977, Green 1990) can b e deriv ed as fo llo ws. The E-step simply requires the calculation of w ik = p k ϕ ( y i ; µ k ( x i ) , Σ k ) P K l =1 p l ϕ ( y i ; µ l ( x i ) , Σ l ) (3.3) where Σ k = Z i B k Z T i + σ 2 I , and ϕ is the Gaussian densit y function. The M-step requires the conditional minimization of the following equation − K X k =1 n X i =1 w ik log p k (3.4) + 1 2 σ 2 n X i =1 K X k =1 w ik [( y i − µ k ( x i ) − Z i b ik ) T ( y i − µ k ( x i ) − Z i b ik ) + σ 2 b T ik B − 1 k b ik ] + K X k =1 N λ k M ( µ k ) , (3.5) where b ik is b i giv en the membership J ik . Thu s the M-step is equiv alen t to minimizing (3.4) and (3.5) separately . 14 By minimizing (3.4), we hav e p k = 1 n n X i =1 w ik for k = 1 , · · · , K . (3.6) By minimizing (3.5), we can minimize the follow ing K equations simu ltaneously n X i =1 w ik [( y i − µ k ( x i ) − Z i b ik ) T ( y i − µ k ( x i ) − Z i b ik )+ σ 2 b T ik B − 1 k b ik ]+ N λ k M ( µ k ) k = 1 , · · · , K. (3.7) where 1 / 2 σ 2 is absorb ed in to λ k . The minimization of (3.7) is p erformed in the repro ducing k ernel Hilb ert space H ⊆ { η : M ( µ ) < ∞} . Substituting solution (2.4) in to (3.7), w e ha v e ( y − Sd k − Rc k − Zb k ) T W k ( y − Sd k − Rc k − Zb k ) + b T k ˜ W 1 / 2 k Ω k ˜ W 1 / 2 k b k + N λ k c T k Qc k , (3.8) where y = ( y T 1 , · · · , y T n ) T , d k = ( d 1 k , · · · , d mk ) T , c k = ( c 1 k , · · · , c T k ) T , b k = ( b T 1 k , · · · , b T nk ) T , S = ( S T 1 , · · · , S T n ) T with the ( k , ν )th entry o f the n i × m matrix S i equal to φ ν ( t ik ), R = ( R T 1 , · · · , R T n ) T with the ( l , j )th entry of the n i × T matrix R i equal to R M ( t il , s j ), the design matrix Z = diag( Z 1 , · · · , Z n ), W k = diag( w 1 k I n 1 , · · · , w nk I n n ), ˜ W k = diag( w 1 k I p , · · · , w nk I p ), Ω k = σ 2 diag( B − 1 k , · · · , B − 1 k ) and Q is the T × T matrix with the ( j, k )th entry equal to R M ( s j , s k ). W riting (3.8) in a more compact form, w e ha v e ( y w k − S w k d k − R w k c k − Zb w k ) T ( y w k − S w k d k − R w k c k − Zb w k )+ b T w k Ω k b w k + N λ k c T k Qc k , (3.9) where y w k = W 1 / 2 k y , S w k = W 1 / 2 k S , R w k = W 1 / 2 k R , Z w k = W 1 / 2 k Z ˜ W − 1 / 2 k , and b w k = ˜ W 1 / 2 k b k . Then (3.9) can b e minimized using the techniq ues dev elop ed in Section 2. 15 The v ariance of measuremen t error is estimated as ˆ σ 2 = 1 N n X i =1 K X k =1 w ik ( y i − µ k ( x i ) − Z i b ik ) T ( y i − µ k ( x i ) − Z i b ik ) . (3.10) The algorithm it era t es through (3.3), (3.6), (3.9) a nd (3 .10) un til all the parame- ters con v erge. The selection of the smo ot hing parameters Ω k and λ k pla ys an imp o r tan t role in the prop osed algorithm. When first run our algo r ithm, in eac h iteration, the optimal smo othing para meters are selected for each cluster using GCV in (3.9). Once all parameters con v erge, we fixed the selected smo othing parameters and run o ur algorithm for fixed smo othing parameters. After we fit the mixture mo del to the data, w e can g iv e a probabilistic (soft) clus- tering o f each observ ation y i . That is, for each y i , w i 1 , · · · , w iK giv e the estimated probabilities that this observ ation b elongs to the first, sec ond,..., and K th comp o- nen ts, resp ectiv ely , of the mixture. How ev er, in man y practical settings, it is highly desirable to giv e hard clustering of these observ ations by assigning each observ ation to one comp onent of the mixture. In the rest of the pap er, w e adopt the hard clustering of McLac hlan and P eel (2001) by estimating the mem b ership lab el, ˆ J ik = 1 if k = a rgmax h w ih 0 otherwise where k = 1 , · · · , K and i = 1 , · · · , n . 3.3 Efficien t Computation with Rejection Con trol With thousands of observ a tions under consideration, the E-step (3.3) results in a h uge num b er of w ik ’s, man y of whic h are extremely small. With the presence of these 16 small w ik ’s, the calculatio n of matrices in volv ed in the M-step (3.9) is exp ensiv e, unstable and sometimes ev en infeasible. T o alleviate the computation and stabilize the alg o rithm, w e prop ose t o add a rejection control step (Liu et al. 1998) in the EM algorithm and refer to the mo dified a lgorithm as rejection controlled EM algorithm. Firstly , w e set up a threshold v alue c (e.g., c = 0 . 05). Giv en this threshold v alue, w e intro duce the following rejection controlled step: w ∗ ik = w ik if w ik > c c with probability w ik /c if w ik ≤ c 0 with probabilit y 1 − w ik /c if w ik ≤ c. The resulting w ∗ ik needs to b e normalized: w ∗∗ ik = w ∗ ik / P k w ∗ ik . Then we replace w ik b y w ∗∗ ik righ t after t he E-step ( 3 .3). Note that when c = 0, the prop osed algorithm is exactly the o riginal EM algorithm, whereas the prop osed algorithm reduces to a v arian t o f Mon te Carlo EM algor it hm (W ei and T anner 1990) when c = 1. In this w ay , it is p ossible to mak e accurate appro ximations during the E-step while greatly reducing the computation of the M-step. Finally , in order to av oid lo cal optima, the rejection controlled EM is run with m ult iple c hains. In practice, we first set the threshold c close to 1 a t an early stage of the iterations t o exp edite the calculation, then w e gradually low er c so that the algorithm can ac hiev e a b etter approximation of the original EM. A critical issue arising f rom the new algorithm is ho w to c ho ose an appropriate stopping rule. F o r the orig inal EM algorithm, the lik eliho o d function increases after eac h iteration, so w e can stop the iteration when the lik eliho o d do es not c hange. Ho w eve r, for the rejection controlled EM algorit hm, the likelihoo d functions fluctuates b ecause of the sampling sc heme. So a stopping rule lik e those used in the Gibbs sampler is employ ed. When the lik eliho o d function is no lo ng er increasing for sev eral 17 consecutiv e iterations, w e stop and c ho o se the estimates with the highest like liho o d. 3.4 The Selection of the Num b er of Clusters The success of our prop osed metho ds hea vily dep ends o n the selection of the num- b er of clusters K . A natural c hoice in mo del-based clustering is to use the Bay esian Information Criterion (BIC). The BIC imp o ses a p enalty o n t he tot a l num b er of pa- rameters, scaled by the logar it hm of sample size, so as to strik e a bala nce b et w een the go odness-of-fit and the mo del complexit y . A critical issue in using BIC in non- parametric settings is to determine the effectiv e n um b er of par a meters. Here w e use the trace of the smo o t hing matrix to appro ximate the n um b er of par a meters in eac h cluster (Hastie and Tibshirani 1990, G u 2002). Thus BIC under our mo del is B I C = − 2 n X i =1 log K X k =1 p k ϕ ( y i ; µ k ( x i ) , Σ k ) + ( K X k =1 tr A k ( λ k , Ω k ) + P ) log N , (3.11) where A k is the smo othing matrix for the k th cluster as defined in (2.9), P is the n um b er of free parameters in p k , λ k , and Ω k where k = 1 , · · · , K . 4 Sim ulati o n T o assess the p erformance of the pr o p osed metho d, w e carr ied out extensiv e analysis on sim ulated datasets. This simulation is designed to demonstrate the perfo rmance of the prop osed metho d when the underlying clusters’ mean functions are differen t for differen t clus- 18 ters. Fir st, one h undred replicates of samples were generated according to y 1 ij τ = 3 sin(6 π t j )(1 − t j ) + 2 I { 1 } ( τ ) − 1 + ǫ 1 ij τ , i = 1 , · · · , 30; y 2 ij τ = 3 sin(6 π t j )(1 − t j ) + ǫ 2 ij τ , i = 1 , · · · , 40; y 3 ij τ = 1980 t 7 j (1 − t j ) 3 + 85 8 t 2 j (1 − t j ) 10 − 2 + ǫ 3 ij τ , i = 1 , · · · , 50; y 4 ij τ = 3 sin(2 π t j ) + 2 I { 1 } ( τ ) − 1 + ǫ 4 ij τ , i = 1 , · · · , 30; where t j = 1 / 15 , 2 / 15 , · · · , 1, τ = 0 , 1, indicator function I { 1 } ( τ ) = 1 if τ = 1 and 0 otherwise, random errors ǫ we re generated from a Gaussian distribution with mean zero and co v ariance matrix as f o llo ws: V ar[ ǫ lij τ ] = 1 , Co v( ǫ lij τ 1 , ǫ lik τ 2 ) = 0 . 2 , for l = 1 , 3; V ar[ ǫ lij τ ] = 1 . 2 , Co v ( ǫ lij τ 1 , ǫ lik τ 2 ) = 0 . 4 , for l = 2 , 4; W e analyzed the sim ulated data using the prop osed metho d with the follo wing mixture mo del y i = µ k ( t , τ ) + b i 1 + ǫ i with probabilit y p k , where k = 1 , · · · , K , τ = 1 , 2 for tw o groups, b i ∼ N ( 0 , σ 2 b ) is t he individual sp ecific random effect. The imp orta n t feature o f the simulated data is tha t the true mean curv es in t w o groups, indexed b y τ , ar e either iden tical or parallel. This information w a s built in to our metho d throug h enforcing the a dditiv e mo del (2.6 ). The p enaliz ed Henderson’s lik eliho o d w as emplo yed for estimation with roughness p enalty M ( µ ) = R 1 0 ( d 2 µ 1 /dt 2 ) 2 dt . W e compared our metho d with MCLUST (F raley and Raftery 1990), FCM classi- fication likelih o o d (FCMc ), and F CM mixture lik eliho od (FCM m) (James and Sugar 200 3). 19 time −4 −2 0 2 4 −4 −2 0 2 4 time −4 −2 0 2 4 −4 −2 0 2 4 Figure 4.1: The estimated mean curves ( dash lines) a nd 9 5% Bay esian confidence in terv als for one simulated dataset. The true functions are superimp osed as solid lines. Since the num b er of clusters m ust b e sp ecified a priori in the partially implemen ted F CM soft w are, w e ga ve a significant starting adv antage to the FC M algo rithm b y letting the n um b er of clusters b e the true n um b er of clusters (four). F or MCLUST, the clustering result with optimal BIC was rep o r t ed, whic h was estimated from eigh t mo dels with different cov ariance structures. The estimated mean curve s using the prop osed metho d for eac h cluster and the true curv es o f one sample ar e plotted in Figure 4.1. F or comparison, w e need a measure of the a g reemen t of t he clustering results with the true cluster mem b ership. A p opular one is the Rand index, whic h is the p ercen tage of concordance pairs o v er all p ossible data pairs. Hub ert and Arabie ( 1 985) pro p osed an adjusted Rand index, whic h tak es one as t he ma ximum v a lue when t w o clustering results are the same and the expected v alue is equal to zero when t w o clustering results are indep enden t. W e fo und that across 10 0 samples the a v erage of the adjusted Rand indices for the prop o sed metho d is 0.9676 (median is 0.983 8 ), whereas those of MCLUST, FCMm , F CMc are 0 .7553, 0.8 936, and 0 .8 896, resp ectiv ely . Moreo v er, t he 20 in ter-quartile ra ng e of the adjusted R and indices o f the prop osed metho d is 0 .0565, (0.0972, 0.2 189 and 0.2 262 for MCLUST, FCM m, and F CMc respective ly). These results suggest that the prop osed metho d outp erforms FCMc and FCMm (ev en under the ideal scenario where the true num b er of clusters is provide d to F CMc and F CMm a priori) as w ell as MCLUST. 5 Real Data Examples 5.1 Comparativ e G enomic Study of F ruitfly and W orm Gene Expressions Dev elopment is an imp ortant biolo gical pro cess that shares man y common features among differen t organisms. It is we ll-know n that D . melano ga ster (fruitfly) a nd C. ele ganc e (worm) are t w o highly div erged sp ecies, the last common ancestor of whic h existed a b out one billion y ear s ag o. T heir dev elopment is an activ e researc h area: In Arb eitman et al. (2002), the mRNA lev els of 4028 genes in D. melano gaster we re measured using cDNA microarra ys during 62 time p oints starting at fertilization and spanning em bry onic, larv al, pupal (metamophosis) stages and the first 30 da ys of adultho o d. mRNA w as extracted fro m mixed male and female p opulations un til adultho o d when males and females w ere sampled separately . Jiang et al. (2 0 01) re- p orted a cDNA microarray exp erimen t for 17871 genes ov er the lif e- cycle of C. ele gans at 6 time p oin ts, including eggs, larv al stages: L1, L2 , L3 and L4, and y oung adults. T o study the genomic connections in expression pa tterns across the t w o sp ecies, w e com bined the gene expression datasets of Arb eitman et al. (200 2) and Jiang et al. (200 1) using the ortho lo gous genes pro vided b y McCarroll et al. (200 4 ), whic h resulted in a merged expression dataset con taining 8 0 8 orthologo us genes. W e analyzed the dat a 21 using the prop osed metho d with the mixture mo del, y i = µ k ( t , τ ) + b i 1 + ǫ i with pro ba bilit y p k where k = 1 , · · · , K , τ = 1 for fruitfly and τ = 2 for worm, b i ∼ N (0 , σ 2 b ) is the gene sp ecific random effect. The p enalized Henderson’s lik eliho o d w a s emplo y ed with roughness p enalt y M of the form (2.5). Sex differen tiation of t he fruitfly w as mo deled b y a branchin g spline (Silv erman and W o od 198 7), the general analytic form of whic h with tw o branche s on the righ t is µ ( t ) = P m ν =1 d ν φ ν ( t ) + P k i =1 c i R M ( s i , t ) if t ≤ s k P m ν =1 d ν φ ν ( t ) + P k i =1 c i R M ( s i , t ) + P T i = k +1 c 1 i R M ( s i − s k , t − s k ) if t > s k P m ν =1 d ν φ ν ( t ) + P k i =1 c i R M ( s i , t ) + P T i = k +1 c 2 i R M ( s i − s k , t − s k ) if t > s k where s k is the branc hing p oin t, and the second and third rows are express ions of the tw o branc hes. A cubic smo othing spline w as use d. The 80 8 genes w ere clus- tered b y our metho d into 34 clusters. Biological functions of genes in eac h cluster w ere annota ted using G ene On tology , and Bonferroni corrected P-v alues of biolog- ical function enric hmen t we re calculated based on the h yp ergeometric distribution (Castillo-Davis and Hartl 20 0 3). Of the 34 cluste rs disco v ered, 21 clusters ex hibit significan t biological functions ov er-represen tatio n (P-v alue < 0.05). The estimated mean gene expression curve s of three clusters and their 95% Bay esian confidence in terv als are giv en in F ig ure 5 .1 . In cluster A, whic h consists of 31 genes, gene expressions of worms hav e p eaks at eggs, lar v a a nd y o ung adult. In the same cluster, w e observ ed tha t fruit-fly gene expressions that are up-regulated during emb ry ogenesis are also up-regulated during metamorphosis, suggesting t ha t man y genes used fo r pattern format io n during em- bry o g enesis (the transition fr om egg to larv a) are re-deplo y ed during metamorphosis 22 sampling time log2(expression) M F −1.5 −1.0 −0.5 0.0 0.5 1.0 1.5 sampling time log2(expression) M F −1.5 −1.0 −0.5 0.0 0.5 1.0 1.5 log2(expression) M F −1.5 −1.0 −0.5 0.0 0.5 1.0 1.5 Figure 5.1: Estimated mean expression curve s and 95% Ba y esian confidence interv als (grey bands) for cluster A, B and C ( f rom top t o b ottom) discov ered in the w orm- fly temp oral expres sion data. V ertical solid lines separate w orm (eggs, larv a and young adult are separately by dash lines in the left frame), fruit-fly (em bry ogenesis, larv a, pupa, a nd adult stages are separated by dash lines in the righ t frame). Adult fruit-fly male and female mean expression curves a re lab eled as M and F, resp ectiv ely . (the transition from larv a to adult). Consisten tly , this cluster is enric hed f o r genes in v olved in em bryonic dev elopmen t (P-v alue =0.0003) , p ost-embry onic b o dy morpho- genesis (P-v alue =0 .0 07), a nd mR NA pro cessing (P- v a lue = 0.002), among others. In cluster B, consisting of 24 genes, gene expressions of worms increase start- ing at eggs until they reach a p eak at late larv al stage. Then expressions go do wn during adultho od. Ho w ev er, w e observ ed that fruit-fly gene express ions that are do wn-regulated during em bry ogenesis are up-regulat ed during metamorphosis a nd adult, suggesting that many genes are inv olv ed in dev elopmen t. The enric hed gene functions are em bry onic (P-v alue =0.02), la rv al dev elopment (P-v alue =0 .008), and gro wth regulation (P-v alue < 10 − 5 ). Cluster C con tains 25 genes. F or w orms, gene expressions hav e peaks at larv a 23 and adult stages. An ov er-represen ta tion o f gene functions suc h as repro duc tion (P-v alue < 1 0 − 6 ), larv al dev elopmen t (P-v alue < 10 − 7 ). F ruit- flies sho w p eaks in gene expression in the early embry o, and older females (but not males). An ov er- represen tation o f gene functions suc h as repro duc tion (P-v alue < 10 − 6 ) and em bry onic dev elopmen t(P-v alue < 10 − 5 ) are presen t in this cluster. Among related functions, this cluster a lso con t a ins f unctions of female gamete generation, grow th, and p ositiv e regulation of growth rate. G enes of this cluster are thus inf erred to par t icipate in sex determination, female pro duc tion of eggs, a nd g r o wth regulation. 5.2 Budding Y east Gene Expression u nder A erobic and Anaer- obic Conditions T o study the o xygen-resp onsiv e gene netw orks, Lai et al. (2006) used cDNA microar- ra y to monitor the gene expression c ha ng es of wild-t yp e budding ye ast ( Sac ch ar omyc es c er evisiae ) under aero bic and anaerobic conditions in a ga lactose medium. Under the aerobic conditions, the oxygen concen tr a tion w as lo w ered gra dually un til oxyge n w a s exhausted during a p erio d of ten minutes . After 2 4 hours o f ana ero bio sis, the o xygen concen tratio n w a s pro gressiv ely increased back to normal lev el during another p erio d of ten min utes, whic h was referred to as the anaerobic conditions. Microarray exp er- imen ts were conducted at 14 time p oints under aerobic conditions and 10 time p oin ts under anaerobic conditions. A reference sample p o oled from all time p o in ts was used for h ybridization. F or their analysis, Lai et al. (2006 ) normalized gene expressions to gene expres- sions o f time 0 and filtered out differen tially expressed genes. Th us the normalized expressions at 23 t ime p oints of 2388 differen tia lly expresse d genes are used for our clustering analysis. W e mo de led nor ma lized gene expression y i of the i th gene using 24 sampling time log2(expression) −2 −1 0 1 2 3 sampling time log2(expression) −1.5 −1.0 −0.5 0.0 0.5 1.0 1.5 log2(expression) −1.0 −0.5 0.0 0.5 1.0 Figure 5.2: Estimated mean expression curve s and 95% Ba y esian confidence interv als (grey bands) for cluster A, B and C (from top to b otto m) discov ered in the ye ast a ero- bic and anaerobic expression data . The aerobic (left) a nd a na erobic (right) conditions w ere separated b y tw o v ertical lines. the mixture mo del, y i = µ k ( t , τ ) + b i 1 + ǫ i with probability p k where k = 1 , · · · , K , τ = 1 for aerobic and τ = 2 for anaerobic condition, b i ∼ N (0 , σ 2 b ) is the g ene sp ecific ra ndo m effect. W e fit the mo del using the p enalty ( 2.5) with a = 2. In total, 2388 genes we re clustered in to 2 8 clusters using our metho d. F unSp ec (R o binson et al. 20 02) w as used fo r gene annotation and biological function enric hmen t analysis. W e found 26 clusters o ut of 28 clusters discov ered ha v e o v er- represen ted biological functions. The estimated mean gene expression pro files and asso ciated Ba y esian confidence interv als of three clusters are giv en in Figure 5.2. In cluster A, whic h consists of 57 genes, the estimated mean express ion go es down progressiv ely as oxy gen level go es dow n, whic h suggests that the genes in this cluster are transien tly dow n-regulated in resp onse to ana erobisis. F urthermore, the estimated 25 mean expression increases as ox ygen concen tr a tion shifts back to normal lev el. Ac- cordingly , g enes inv olv ed in respiration, lipid fatt y-acid and isoprenoid biosyn thesis, and cell defense are ov er-represen ted in this cluster (P-v alue ≤ 10 − 5 ). In contrast to cluster A, cluster B (85 genes) consists of genes in v o lv ed in v ari- ous biosyn thesis, metab olism and catab olism suc h as glucose metab olism (P-v alue ≤ 10 − 6 ). These biolo g ical pro cesses are necessary to main tain the basic living needs of y east cells. In terestingly , the alcohol biosythesis and metab olism a re also enric hed in this cluster. Consisten t with biological function o v er-represen tation, the estimated mean expression is up- regulated in aerobic conditions and down-regulated in anaero- bic conditions. W e hav e 70 genes in cluster C, where the estimated mean gene expression go es up at the b eginning a nd then drops down rapidly under aerobic conditions. Under anaerobic conditions, the estimated mean gene express ion is up-regulated. In this cluster, respiratory deficiency and carb on utilization are also o v er-represen ted (P- v alue ≤ 10 − 8 ). The initial up- regulation of gene expression under aero bic conditions can b e partly explained by the fa ct that the cell increases energy up-taking through other biological pro cesses, suc h a s carb on utilization, when ox ygen go es down. But as the ox ygen lev el con tinues to drop, these pro ce sses are replaced by more energy efficien t pro cesses, such as glucose metab olism. Under the anaerobic conditions, these pro cesses are revitalized again as oxygen lev el increases. 6 Discuss ion In this article, w e pro p ose a clustering metho d for large scale functional da ta with mul- tiple co v ariates. Nonparametric mixed-effect mo dels we re built, which w ere nested under a mixture mo del. The p enalized Henderson’s lik eliho o d w as employ ed for estimation. Data- driv en smo othing para meters, selected through g eneralized cross- 26 v alidation, w ere used to a utomatically capture t he functional features. The rejection- con trolled EM algor ithm was designed to reduce the exp ensiv e computational cost for large scale data . The sim ulation analyses suggest that the prop o sed metho d outp er- forms the existing clustering metho ds. Moreo ve r, the Bay esian in terpretation of the prop osed metho d allows the dev elopmen t of an equiv alen t fully Bay esian functional data clustering metho d, whic h can accommo date additiona l genomic and proteomic information for gene expression study . Although it w as mot iv a ted for clustering temp oral express ion data, our prop o sed metho d has a wide sp ectrum of applica- tions, including those inv olving seismic w av e data arising from geophys ical researc h (W ang et al. 2 006 a nd Ma et al. 20 0 7). The calculations rep orted in this article w ere p erformed in R. Op en-source co de is a v ailable in the R pack age MFDA. As a sequel to this w ork, a clustering metho d f o r discrete da t a, esp ecially those arising from temp oral text mining, is under activ e dev elopment. App endix Pr o of of The or em 2.1 : Note the fact that if w e sp ecify the prio r for f 0 as a Gaussian pro ce ss with mean zero and cov aria nces E [ f 0 ( s k ) f 0 ( s l )] = τ 2 P m ν =1 φ ν ( s k ) φ ν ( s l ), then when τ 2 → ∞ , t he prior for f 0 b ecomes a diffuse prior; see W ah ba (1 983) and Gu (2002). Assuming f 0 ( t ) has a G aussian pro ce ss prior sp ecified ab ov e, f 1 ( x ) has a Gaussian pro cess prio r sp ecified as in Theorem 2.1, and b follows a normal distribution with mean zero a nd v ariance-co v ariance matr ix B , w e can deriv e tha t the j oin t distribution of y and f 0 ( x )+ f 1 ( x )+ z T b follows a Ga ussian distribution with mean 0 and co v ariance matrix b FV + F T + τ 2 SS T + σ 2 I b FV + ˜ ξ + τ 2 S φ b ˜ ξ T V + F T + τ 2 φ T S T b ˜ ξ T V + ˜ ξ + τ 2 φ T φ (6.1) 27 where ˜ ξ = ( R 1 ( s 1 , x ) , . . . , R 1 ( s T , x ) , z ) T is ( T + p ) × 1, φ is m × 1 with the ν th en tr y φ ν ( t ), F = ( R , Z ), and V + is the Mo ore- P enrose in ve rse of V = diag( Q , 1 N λ Ω ) satisfying VV + F T = F T . Standard calculation yields E [ µ ( x ) + z T b | y ] = ( b ˜ ξ T V + F T + τ 2 φ T S T )( b FV + F T + τ 2 S S T + σ 2 I ) − 1 y = ρ φ T S T ( W + ρ SS T ) − 1 y + ˜ ξ T V + F T ( W + ρ SS T ) − 1 y , where ρ = τ 2 /b , N λ = σ 2 /b , and W = FV + F T + N λ I . No w letting ρ → ∞ , w e hav e lim ρ →∞ ( ρ SS T + W ) − 1 = W − 1 − W − 1 S ( S T W − 1 S ) − 1 S T W − 1 , (6.2) lim ρ →∞ ρ S T ( ρ SS T + W ) − 1 = ( S T W − 1 S ) − 1 S T W − 1 . (6.3) See W ah ba (1983) and Gu (200 2 ) for the pro of. Therefore, lim τ 2 →∞ E [ µ ( x ) + z T b | y ] = φ T d + ˜ ξ T ˜ c , where d = ( S T W − 1 S ) − 1 S T W − 1 y , ˜ c = V + F T ( W − 1 − W − 1 S ( S T W − 1 S ) − 1 S T W − 1 ) y . (6.4) It is straigh tforward to verify that the d and ˜ c giv en in (6.4) satisfy (2.8). Pr o of of The or em 2.2 : The p o sterior v ariance can b e easily calculated b y using expression (6.1) as follows , v ar[ µ ( x ) + z T b | y ] = ˜ ξ T V + ˜ ξ + ρ φ T φ − ( ˜ ξ T V + F T + ρ φ T S T )( W + ρ SS T ) − 1 ( FV + ˜ ξ + ρ S φ ) Notice that lim ρ →∞ ρI − ρ 2 S T ( ρ SS T + W ) − 1 S = ( S T W − 1 S ) − 1 , and V V + F T = F T . 28 Therefore as ρ → ∞ , we hav e lim τ 2 →∞ V ar[ µ ( x )+ z T b | y ] /b = ˜ ξ T V + ˜ ξ + φ T ( S T W − 1 S ) − 1 φ − 2 φ T ( S T W − 1 S ) − 1 S T W − 1 FV + ˜ ξ − ˜ ξ T V + F T ( W − 1 − W − 1 S ( S T W − 1 S ) − 1 S T W − 1 ) FV + ˜ ξ . References Arb eitman, M., E. F urlong, F. Imam, E. Johnson, B. H. Null, B. S. Bake r, M. Kras- no w, M. P . Scott, R. W. D a vis, and K. P . White (2002). Gene expression during the life cycle of drosophila melanoga ster. Scienc e 297 (5590), 2270–227 5. Castillo-Dav is, C. and D . Hartl (2003). Genemerge: p ost-genomic analysis, data- mining and hy p othesis. Bioinformatics 19 , 891–8 92. Cra v en, P . and G . W ah ba (1979). Smo othing noisy data with spline functions: Estimating the correct degree o f smo othing b y the metho d o f generalized cross- v alidation. Numer. Math. 31 , 377– 403. Dempster, A. P ., N. M. Laird, and D. B. Rubin (1977). Maxim um lik eliho o d from incomplete data via the EM algor ithm. J. R oy. S tatist. So c. Ser. B 3 9 , 1–3 7 (with discussions). Dennis, J. E. and R. B. Sc hnab el (19 96). Numeric al Metho d s for Unc o n str aine d Optimization and Nonlin e ar Equations . Philadelphia: SIAM . Corrected reprint of the 1983 original. F raley , C. and A. E. Raftery (199 0). Mo del-based clustering, discriminan t analysis, and densit y estimation. J. Amer. Statist. Asso c. 97 , 6 11–631. Green, P . J. (1990). On the use of the EM algorithm f o r p enalized lik eliho o d esti- mation. J. R oy. Statist. So c. Ser. B 52 , 443–45 2. 29 Gu, C. (2002). Smo o thin g Spline ANO V A Mo dels . New Y ork: Springer-V erlag. Gu, C. and P . Ma (200 5). Optimal smo othing in nonpar ametric mixed effect mo dels. A nn. Statist. 33 , 1357–137 9 . Hastie, T. and R. Tibshirani (1990). Gener a lize d A d d itive Mo dels . London: Chap- man & Hall. Heard, N. A., C. C. Holmes, and D. A. Stephens (2006). A quantitativ e study of gene regulation inv olv ed in the imm une resp onse of anopheline mosquito es: An application of ba y esian hierarc hical clustering of curve s. J. A mer. Statist. Asso c. 101 (473), 18–29. Hub ert, L. and P . Arabie (198 5 ). Comparing partitio ns. J. Classific ation 2 , 193 – 218. James, G. M. and C. A. Sugar (2003) . Clustering fo r sparsely sampled functional data. J. A mer. Statist. Asso c. 98 (462), 397–408. Jiang, M., J. Ryu, M. Kiraly , K. D uke, V. Reink e, and S. K. Kim (200 1). Genome- wide analysis of dev elopmen tal and sex-regulated gene expression profiles in caenorhab ditis elegans. Pr o c . Natl. A c ad. S c i. 98 (1), 218–22 3 . Kim, Y.-J. and C. Gu ( 2 004). Smo othing spline gaussian regression: More scalable computation via efficien t approx imation. J. R oy. Statist. So c. S er. B 66 , 337– 356. Lai, L. C., A. L. Ko soruk off, P . Burk e, and K. E. Kw ast (2006). Metab olic- stat e- dep enden t remodeling of the transcriptome in resp onse to ano xia and subse- quen t reo xygenation in sacch aromy ces cerevisiae. Eukaryot Cel l 5 , 1468–89. Liu, J. S., R. Chen, and W. H. W ong (1998). Rejection con trol a nd sequen t ia l imp ortance sampling. J. Amer. Statist. Asso c. 93 , 1 022–1031. 30 Luan, Y. and H. Li (2003 ) . Clustering of time-course g ene express ion data using a mixed-effects mo dels with B- spline. Bioinformatics 19 (4), 474–28 2. Luan, Y. and H. Li (2 004). Mo del-based metho ds f o r iden tifying p erio dically reg- ulated genes based on the time course microarr ay gene expression data. Bio i n - formatics 20 (4), 332– 3 39. Ma, P ., P . W ang, L. T enorio, M. V. de Ho op, and R. D . v an der Hilst (2007 ) . Imaging o f structure at and near the core man tle b oundary using a generalized Radon transform: 2. statistical inference of singularities. J. Ge op hys. R es. 112 , B08303. McCarroll, S. A., C. T. Murph y , S. Zou, S. D. Pletc her, C. S. Chin, Y. N. Jan, C. Ken y on, C. I. Bargmann, and H. L i (2004). Comparing g enomic expres- sion patterns across sp ecies iden tifies shared tra nscriptional pro gram in aging. Natur e Genetics 36 (2), 197–2 04. McLac hlan, G. J. and D. P eel (2001 ). Finite Mixtur e Mo dels . John Wiley & Sons. Nyc hk a, D. (1988). Bay esian confidence in terv als for smo o thing splines. J. Amer. Statist. Asso c. 83 , 1134–1 143. Ramsa y , J. O. and B. W. Silv erman (200 2 ). App l i e d F unctional Data Analysis: Metho ds and Case S tudies . Springer-V erlag Inc. Ramsa y , J. O. and B. W. Silv erman (2 005). F unc tion a l Data Analysis . Springer- V erlag Inc. Robinson, G. K. (1991). That BLUP is a g o o d thing: The estimation of the random effects. Statist. Sci. 6 , 15–51 (with discussions). Robinson, M. D ., J. Grig ull, N. Mohammad, and T. R. Hug hes (2002). F unsp ec: a w eb-based cluster in terpreter for ye ast. BMC Bioinformatics 3 , 3–35. 31 Silv erman, B. W. and J. T. W o o d (1 987). The nonparametric estimation o f branc h- ing curv es. J. Amer. Statist. Asso c. 82 , 551–5 5 8. Sp ellman, P . T., G. Sherlo c k, M. Q. Zhang, V. R . Iy er, K . Anders, M. B. Eisen, P . O. Bro wn, and B. Botstein D F utc her (1998 ). Comprehensiv e identification of cell cycle-regulated genes of the ye ast sacc haromy ces cerevisiae by microarr ay h ybridization. Mol Biol Cel l. 9 (12), 327 3–97. Storey , J. D., W. Xiao , J. T. Leek, and R. T ompkins, R. G.and Dav is (2005). Significance of time course microarra y experimen ts. Pr o c. Natl. A c ad. Sci. 10 2 , 12837–12 842. W ah ba, G . (1983 ). Ba y esian “confidence in terv als” for the cross-v alidated smo oth- ing spline. J. R oy. Statist. So c. Ser. B 45 , 133–1 50. W ah ba, G. (199 0). Spli n e Mo dels for Observational Data , V olume 59 o f CBMS-NSF Regional Conference Series in Applied Mathematics. Philadelphia: SIAM. W ang, P ., M. V. de Ho op, R . D . v an der Hilst, P . Ma, a nd L. T enorio (2006). Imag- ing of structure at and near the core mantle b oundary using a generalized r a don transform: 1. construction of image gathers. J. Ge ophys. R es. 111 , B12 304. W ang, Y. (1 998). Mixed-effects smo othing spline ANO V A. J. R oy. Statist. So c. Ser. B 60 , 159–1 74. W ei, G. C. and M. A. T anner (19 90). A Monte Carlo implemen t a tion of the EM algorithm and the p oor man’s data augmen ta tion algo rithms. J. A mer. Statist. Asso c. 85 , 699– 704. Zhang, D ., X. Lin, J. Raz, and M. So w ers (1998). Semiparametric sto c hastic mixed mo dels for longitudinal data. J. A mer. Statist. Asso c . 93 , 710–719. 32
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment