대규모 다변량 공변량을 갖는 함수형 데이터의 패널티 기반 군집화
본 논문은 시간·조건·처리 등 여러 공변량을 동시에 고려한 대규모 함수형 데이터를 위한 혼합효과 모델 기반 군집화 방법을 제안한다. 비선형 다변량 고정효과를 재생 커널 힐베르트 공간(RKHS)에서 함수형 ANOVA로 분해하고, 패널티화된 Henderson likelihood와 GCV 기반 스무딩 파라미터 선택을 결합한다. EM 알고리즘에 거부 제어 샘플링을 도입해 계산 효율성을 높였으며, 베이지안 신뢰구간을 통해 군집 불확실성을 정량화한다.
저자: Ping Ma, Wenxuan Zhong
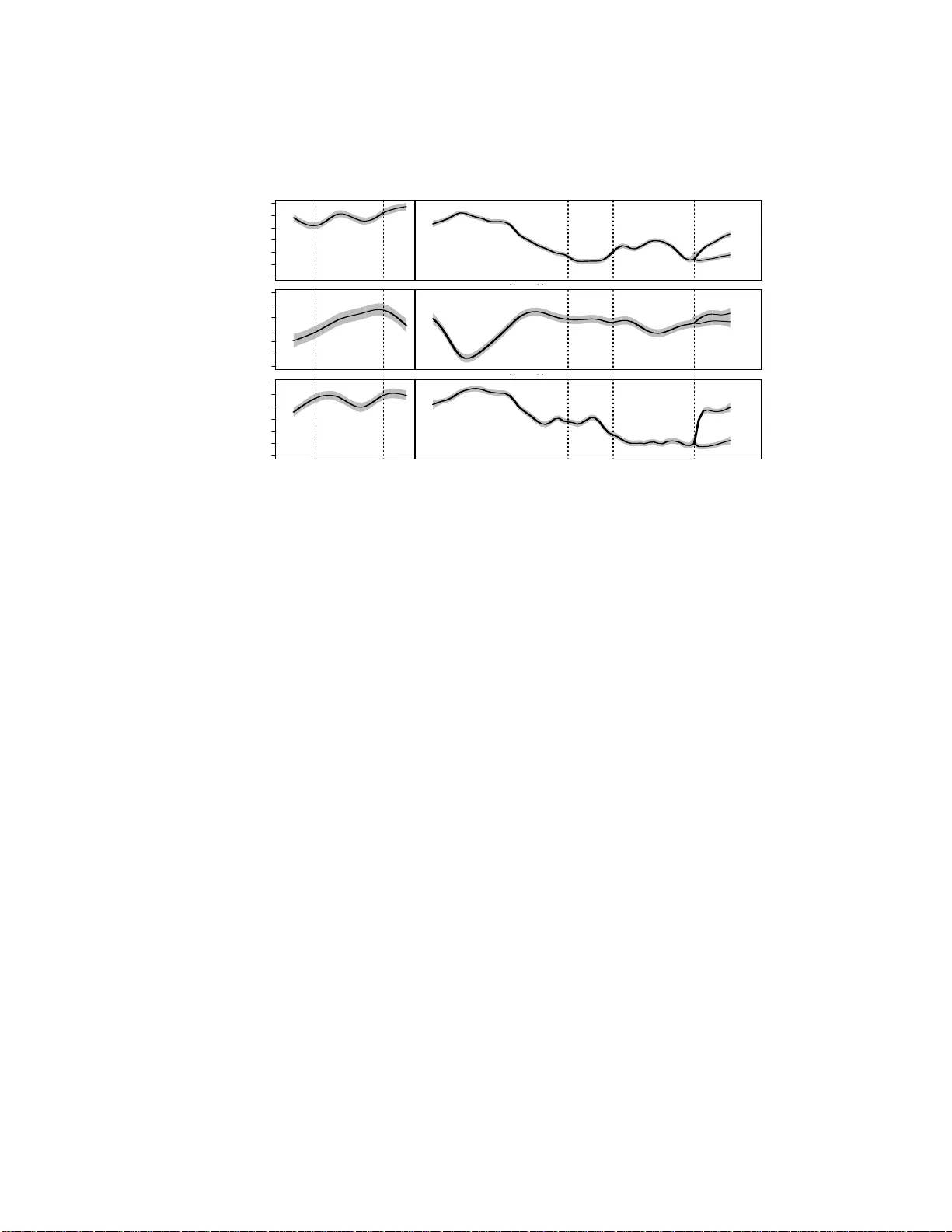
본 논문은 현대 생명과학·공학 분야에서 흔히 나타나는, 시간뿐 아니라 복수의 실험 조건·처리·복제 등 다양한 공변량을 동시에 포함하는 대규모 함수형 데이터를 효과적으로 군집화하기 위한 새로운 통계적 프레임워크를 제시한다. 기존의 K‑means, 계층적 군집법, 다변량 가우시안 혼합 모델(MCLUST) 등은 관측치 간의 순서·시간 의존성을 무시하거나, 결측치가 많은 불균형 설계에 대해 사전 보간이 필요하다는 한계를 가지고 있다. 또한, 최근 제안된 함수형 데이터 기반 군집법(FCM, Luan & Li 등)은 스무딩 파라미터(노드·자유도)를 모든 클러스터에 동일하게 적용함으로써 서로 다른 패턴을 충분히 표현하지 못한다. 이러한 문제점을 극복하고자 저자들은 다음과 같은 핵심 아이디어를 도입한다.
1. **비모수 다변량 고정효과와 혼합효과의 결합**
각 개체 i의 관측 벡터 y_i는
y_i = μ(x_i) + Z_i b_i + ε_i
로 모델링된다. 여기서 μ(x)는 다변량 비모수 함수이며, x는 시간·조건·처리 등 d 차원의 공변량 벡터이다. Z_i b_i는 개체별 랜덤 효과이며, ε_i는 독립 정규 오차이다. 랜덤 효과 구조는 p 차원 정규분포(b_i ~ N(0,B))와 설계 행렬 Z_i에 의해 다양한 상관 구조(동일 상관, 선형 트렌드 등)를 표현한다.
2. **함수형 ANOVA와 RKHS 기반 분해**
μ(x) 를 함수형 ANOVA 형태로 전개한다.
μ(x)=μ₀+∑_{j=1}^d μ_j(x_j)+∑_{j
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기