Optimizing a Supply-Side Platforms Header Bidding Strategy with Thompson Sampling
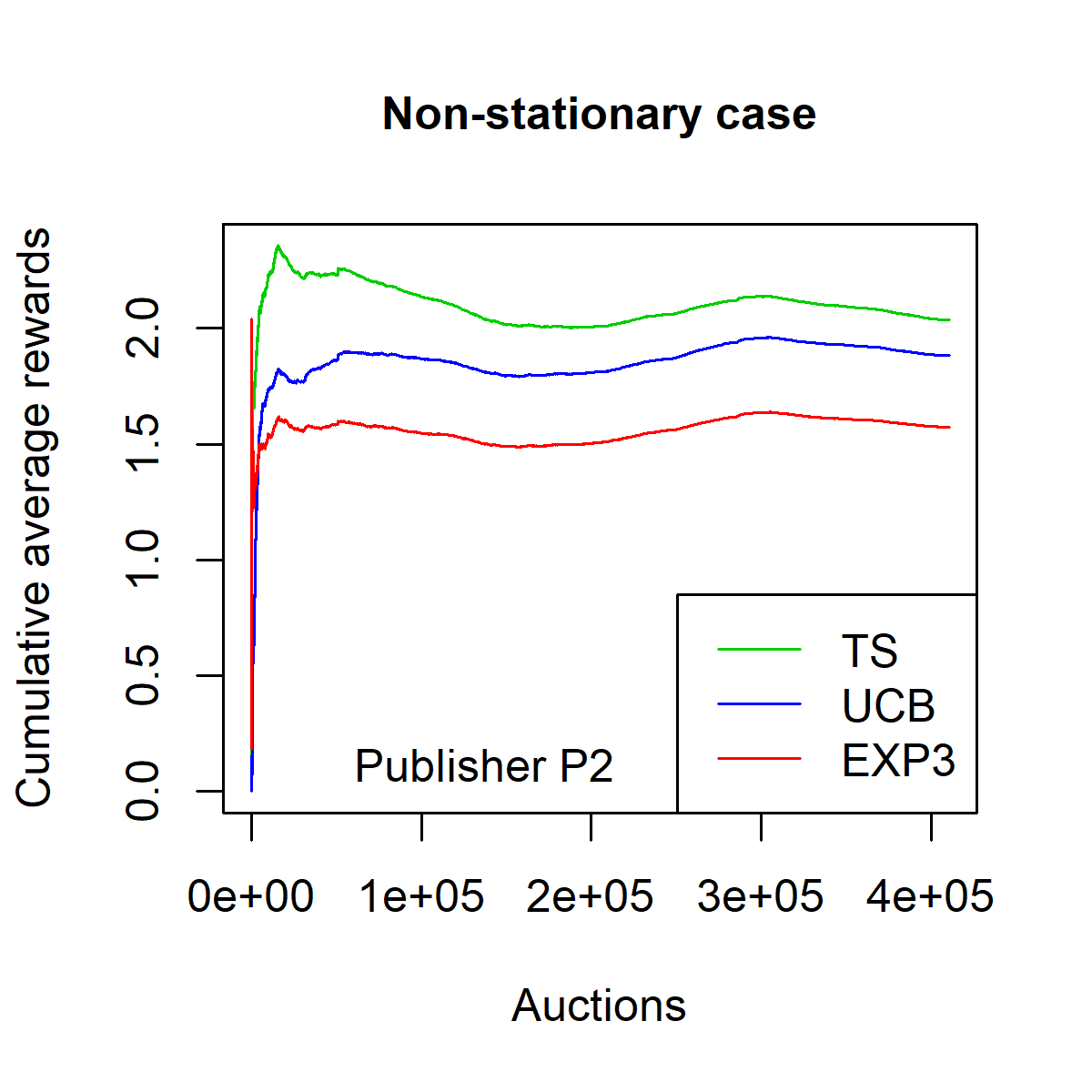
Over the last decade, digital media (web or app publishers) generalized the use of real time ad auctions to sell their ad spaces. Multiple auction platforms, also called Supply-Side Platforms (SSP), were created. Because of this multiplicity, publishers started to create competition between SSPs. In this setting, there are two successive auctions a second price auction in each SSP and a secondary, first price auction, called header bidding auction, between SSPs.In this paper, we consider an SSP competing with other SSPs for ad spaces. The SSP acts as an intermediary between an advertiser wanting to buy ad spaces and a web publisher wanting to sell its ad spaces, and needs to define a bidding strategy to be able to deliver to the advertisers as many ads as possible while spending as little as possible. The revenue optimization of this SSP can be written as a contextual bandit problem, where the context consists of the information available about the ad opportunity, such as properties of the internet user or of the ad placement.Using classical multi-armed bandit strategies (such as the original versions of UCB and EXP3) is inefficient in this setting and yields a low convergence speed, as the arms are very correlated. In this paper we design and experiment a version of the Thompson Sampling algorithm that easily takes this correlation into account. We combine this bayesian algorithm with a particle filter, which permits to handle non-stationarity by sequentially estimating the distribution of the highest bid to beat in order to win an auction. We apply this methodology on two real auction datasets, and show that it significantly outperforms more classical approaches.The strategy defined in this paper is being developed to be deployed on thousands of publishers worldwide.