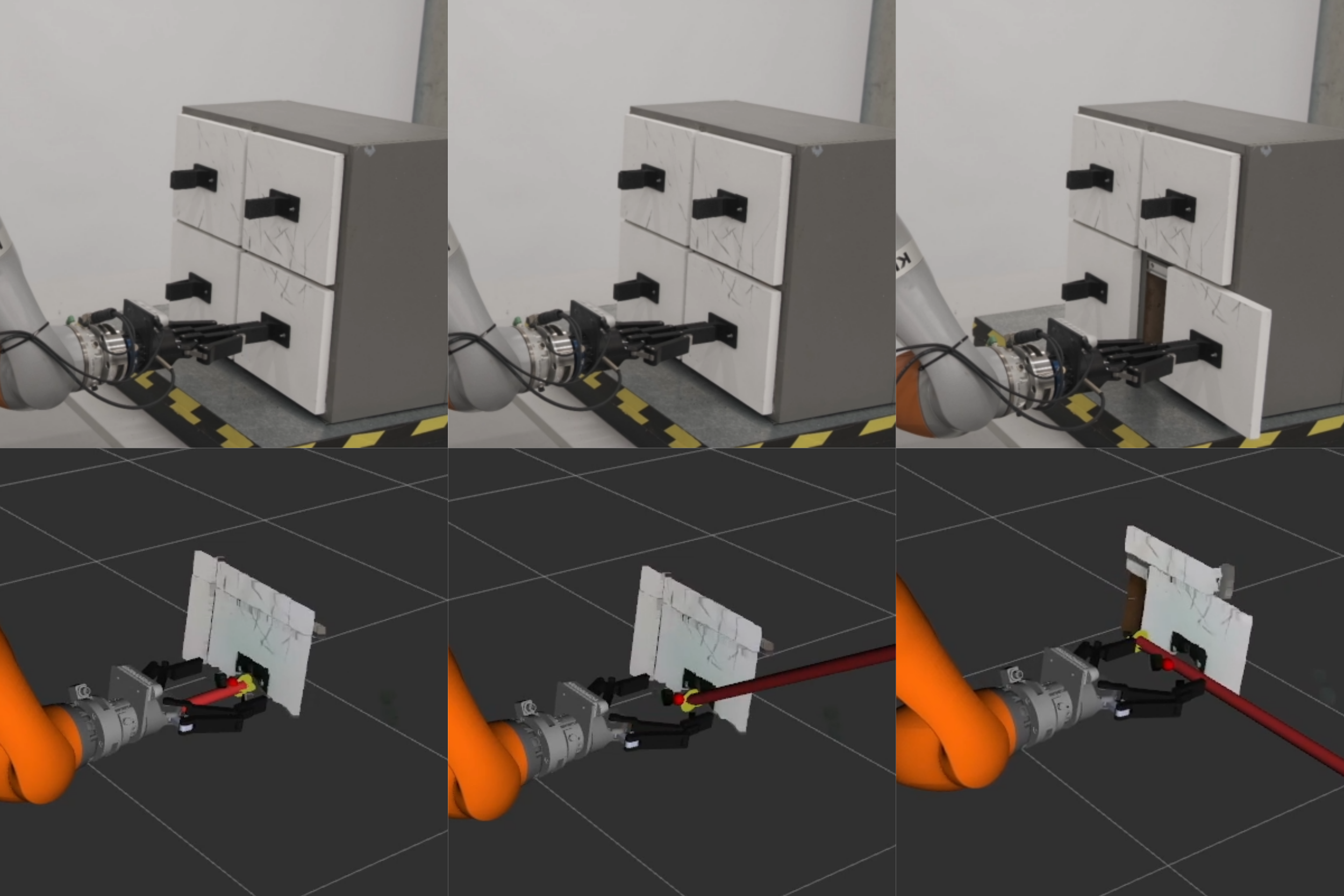
Coordinated Humanoid Manipulation with Choice Policies
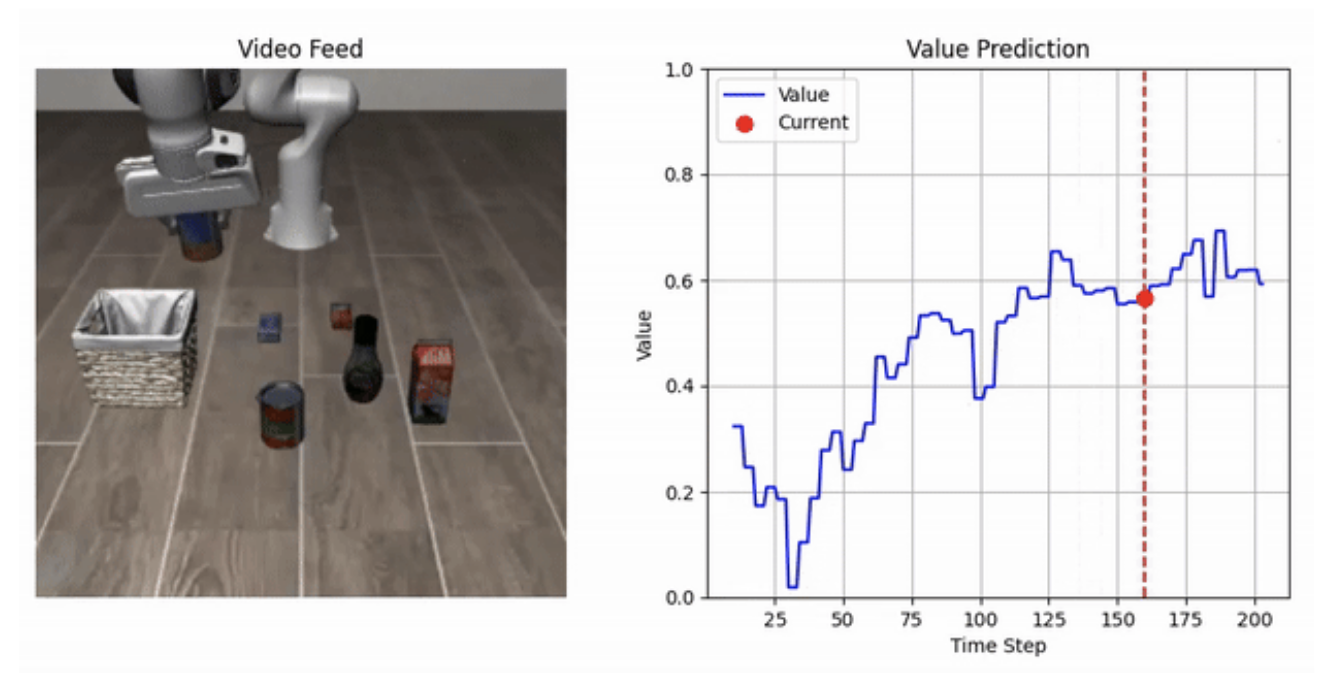
Humanoid robots hold great promise for operating in human-centric environments, yet achieving robust whole-body coordination across the head, hands, and legs remains a major challenge. We present a system that combines a modular teleoperation interface with a scalable learning framework to address this problem. Our teleoperation design decomposes humanoid control into intuitive submodules, which include hand-eye coordination, grasp primitives, arm end-effector tracking, and locomotion. This modularity allows us to collect high-quality demonstrations efficiently. Building on this, we introduce Choice Policy, an imitation learning approach that generates multiple candidate actions and learns to score them. This architecture enables both fast inference and effective modeling of multimodal behaviors. We validate our approach on two real-world tasks dishwasher loading and whole-body loco-manipulation for whiteboard wiping. Experiments show that Choice Policy significantly outperforms diffusion policies and standard behavior cloning. Furthermore, our results indicate that hand-eye coordination is critical for success in long-horizon tasks. Our work demonstrates a practical path toward scalable data collection and learning for coordinated humanoid manipulation in unstructured environments.