QSLM A Performance- and Memory-aware Quantization Framework with Tiered Search Strategy for Spike-driven Language Models
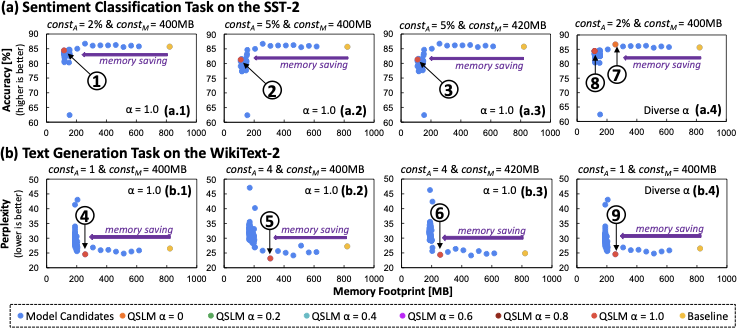
Large Language Models (LLMs) have been emerging as prominent AI models for solving many natural language tasks due to their high performance (e.g., accuracy) and capabilities in generating high-quality responses to the given inputs. However, their large computational cost, huge memory footprints, and high processing power/energy make it challenging for their embedded deployments. Amid several tinyLLMs, recent works have proposed spike-driven language models (SLMs) for significantly reducing the processing power/energy of LLMs. However, their memory footprints still remain too large for low-cost and resource-constrained embedded devices. Manual quantization approach may effectively compress SLM memory footprints, but it requires a huge design time and compute power to find the quantization setting for each network, hence making this approach not-scalable for handling different networks, performance requirements, and memory budgets. To bridge this gap, we propose QSLM, a novel framework that performs automated quantization for compressing pre-trained SLMs, while meeting the performance and memory constraints. To achieve this, QSLM first identifies the hierarchy of the given network architecture and the sensitivity of network layers under quantization, then employs a tiered quantization strategy (e.g., global-, block-, and module-level quantization) while leveraging a multi-objective performance-and-memory trade-off function to select the final quantization setting. Experimental results indicate that our QSLM reduces memory footprint by up to 86.5%, reduces power consumption by up to 20%, maintains high performance across different tasks (i.e., by up to 84.4% accuracy of sentiment classification on the SST-2 dataset and perplexity score of 23.2 for text generation on the WikiText-2 dataset) close to the original non-quantized model while meeting the performance and memory constraints.