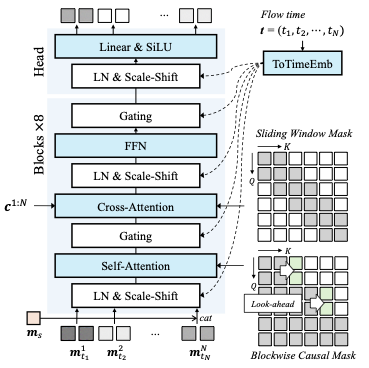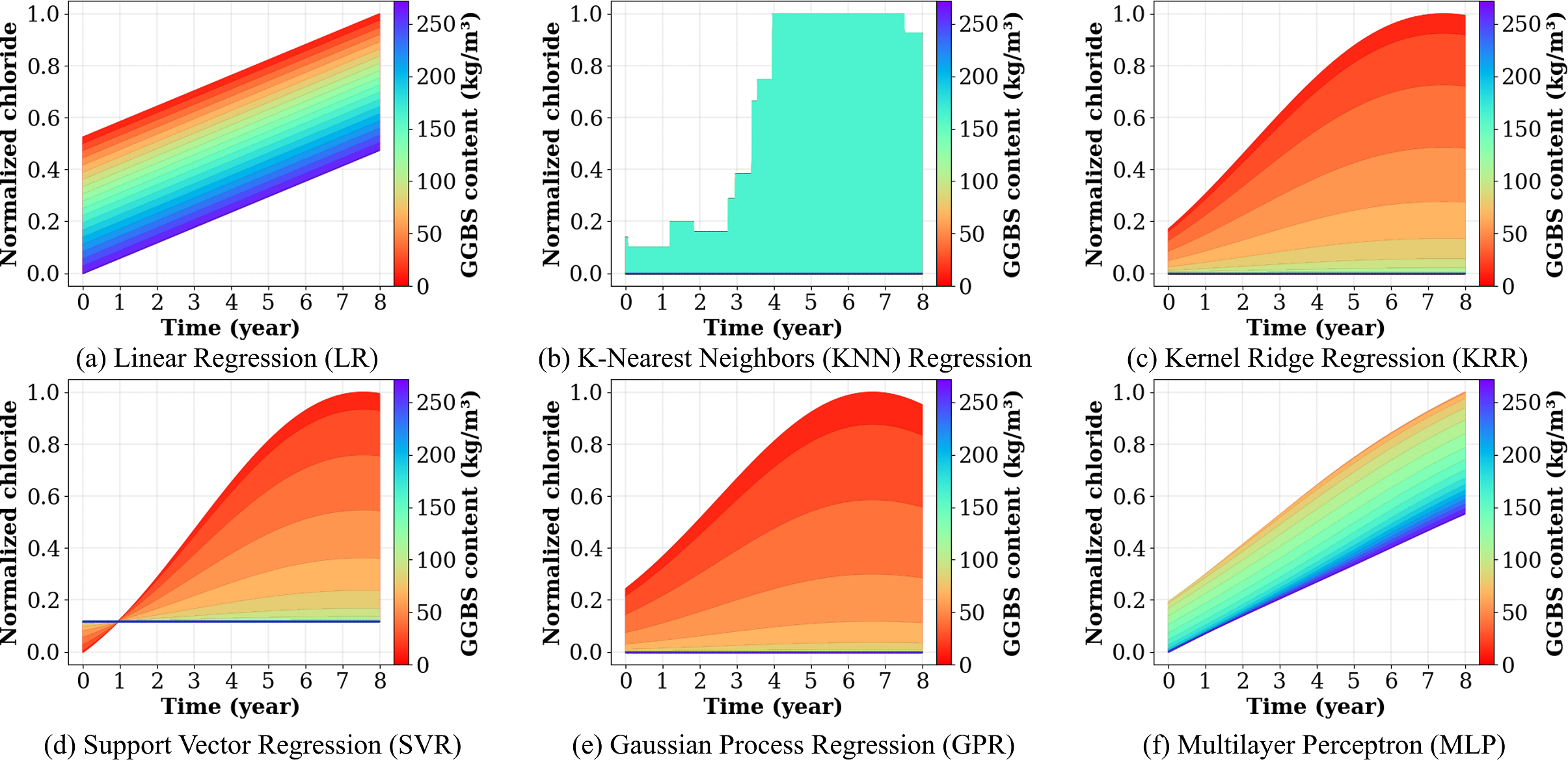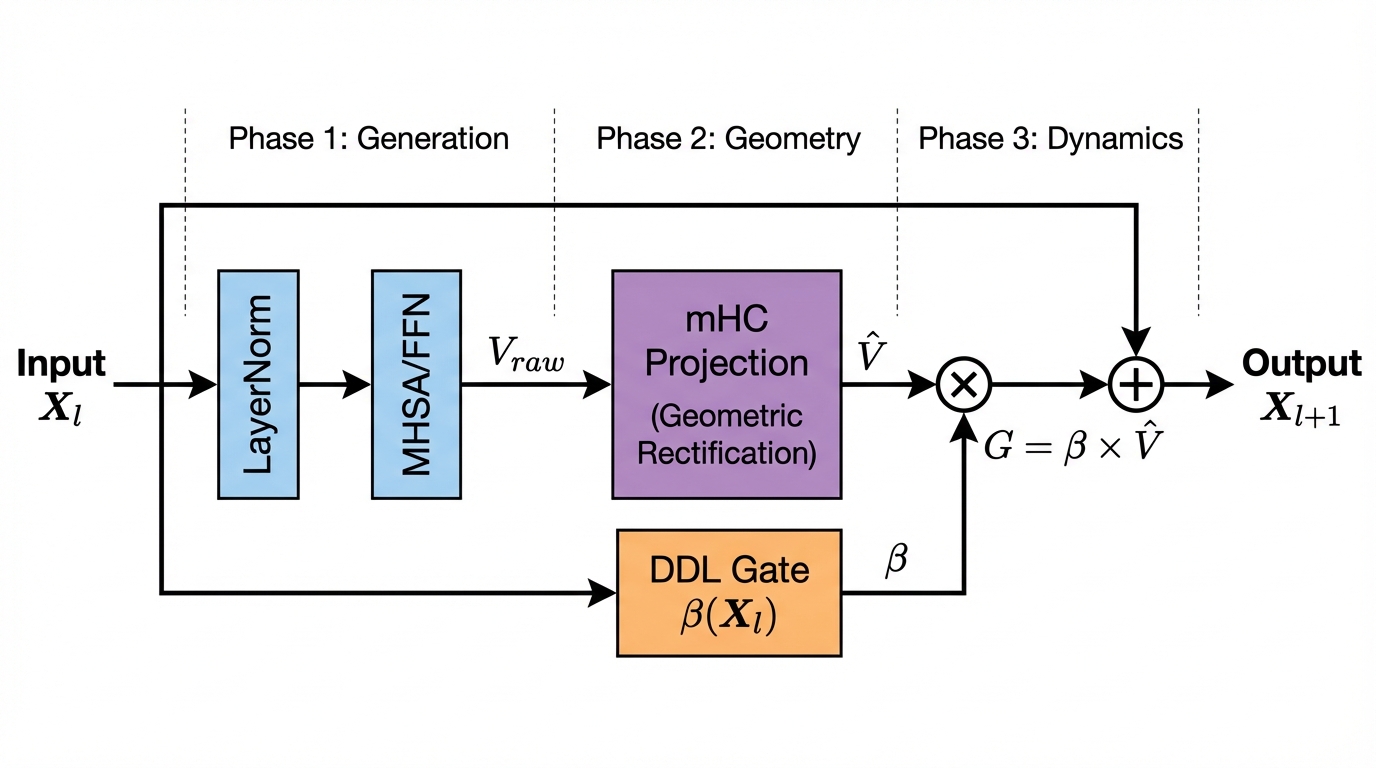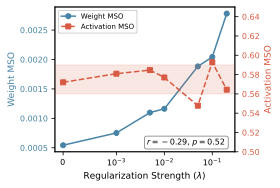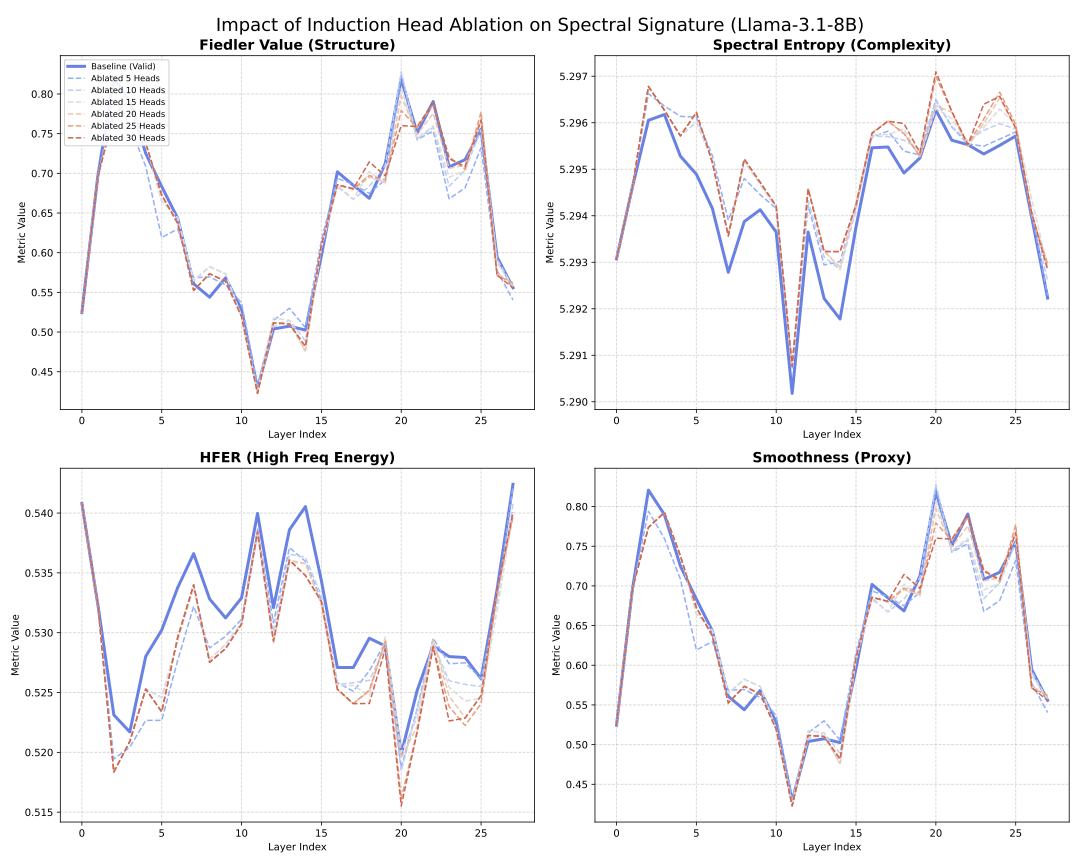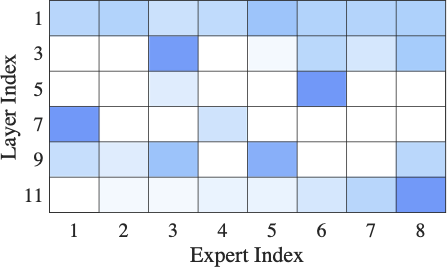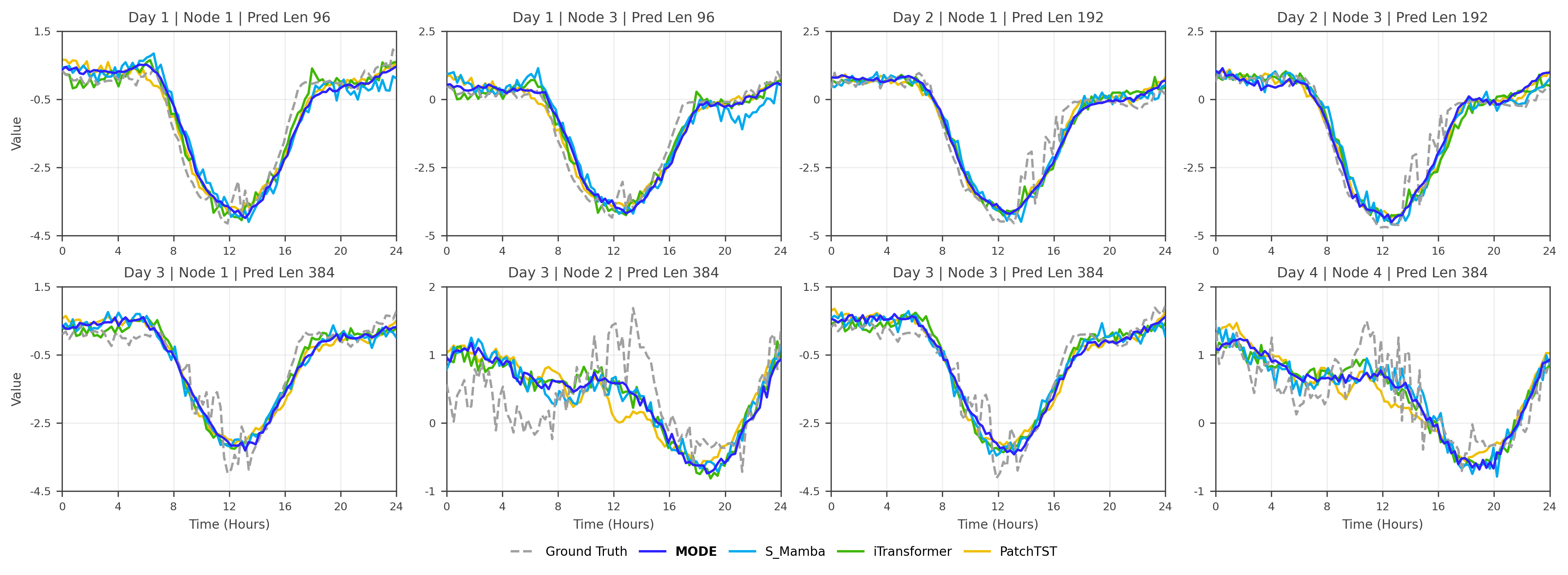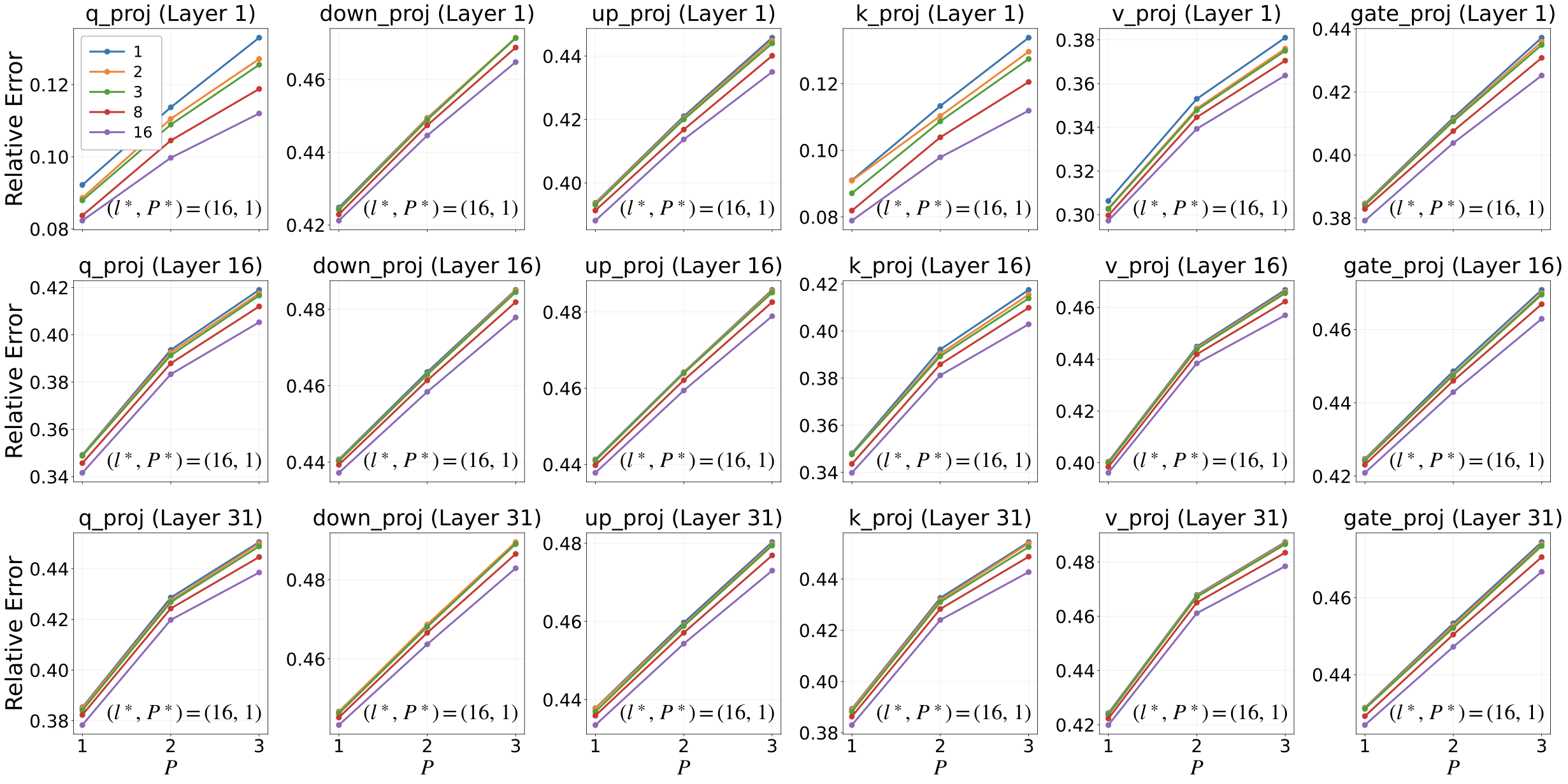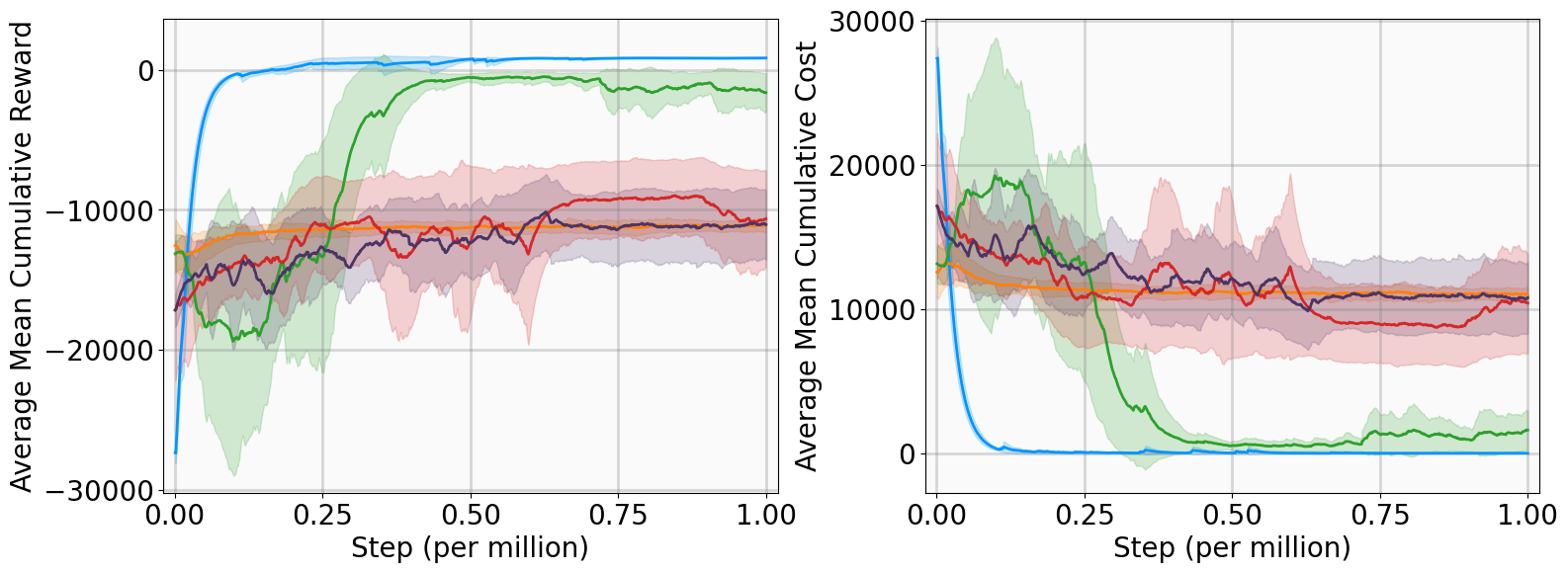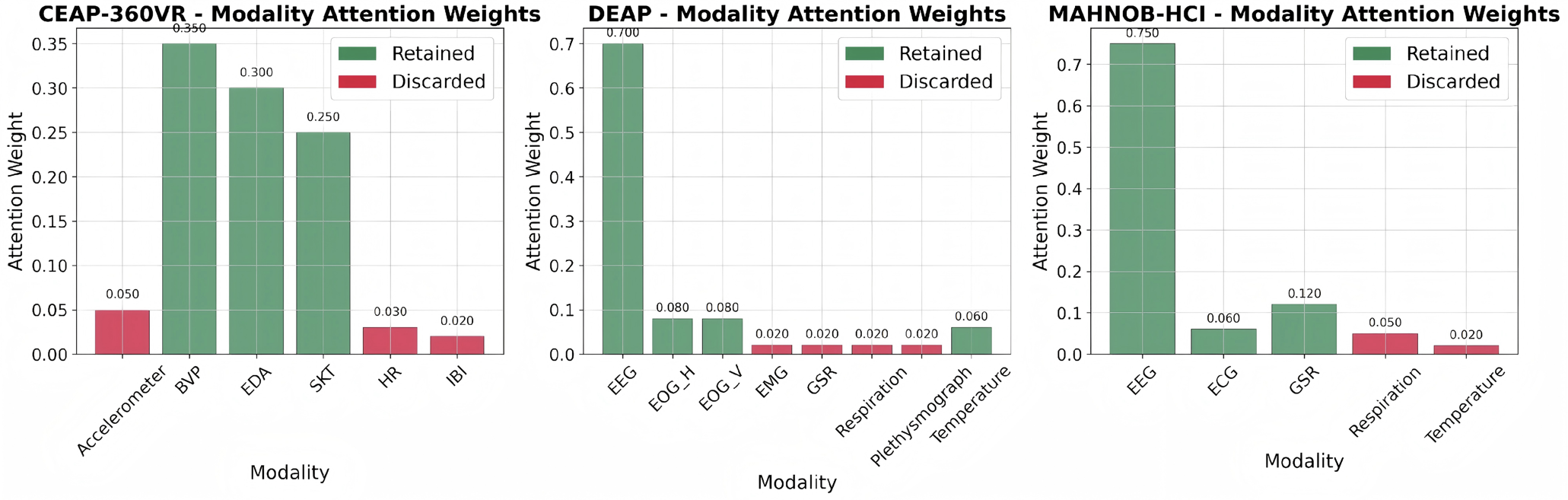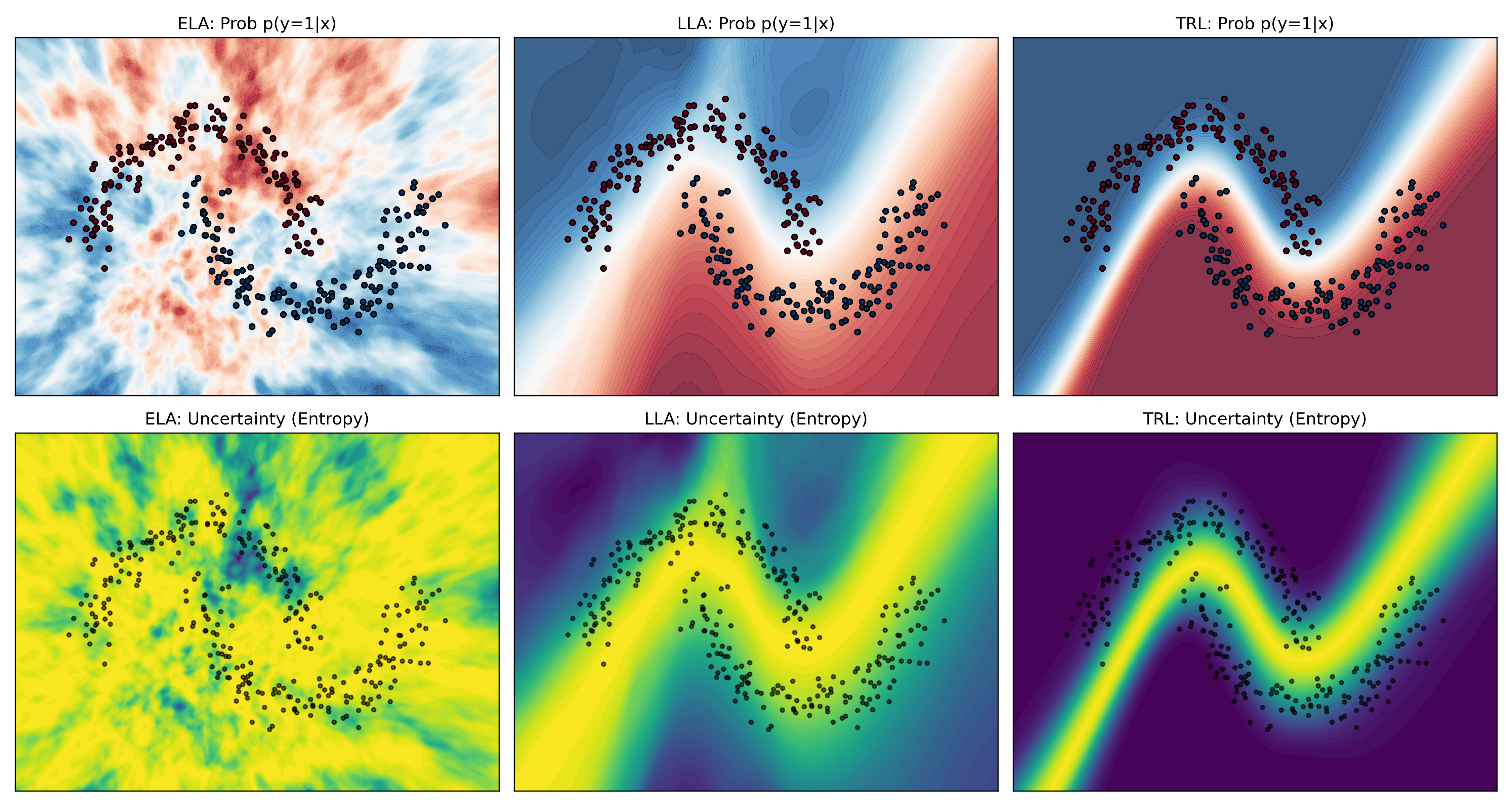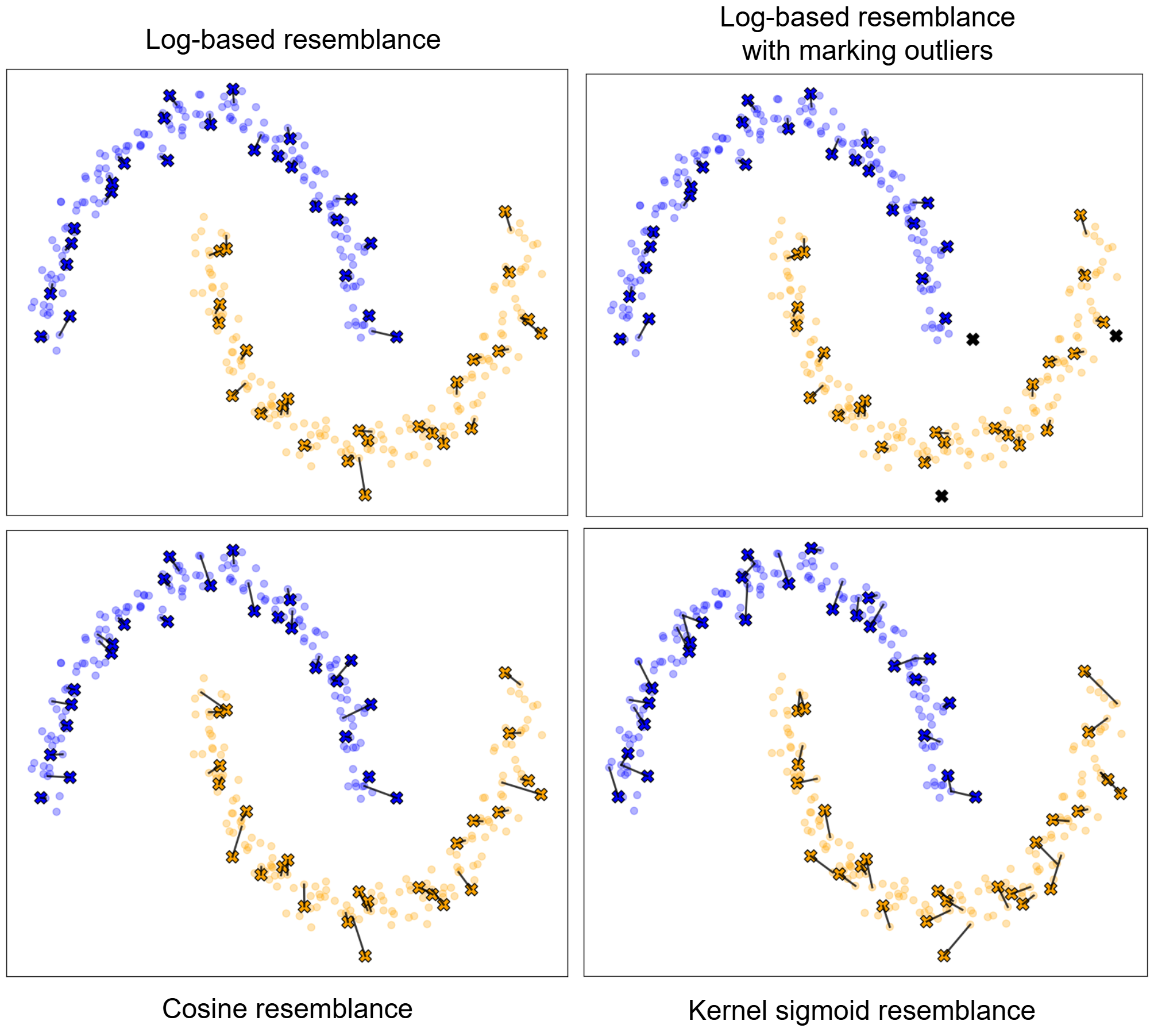
A Generalized UCB Bandit Algorithm for ML-Based Estimators
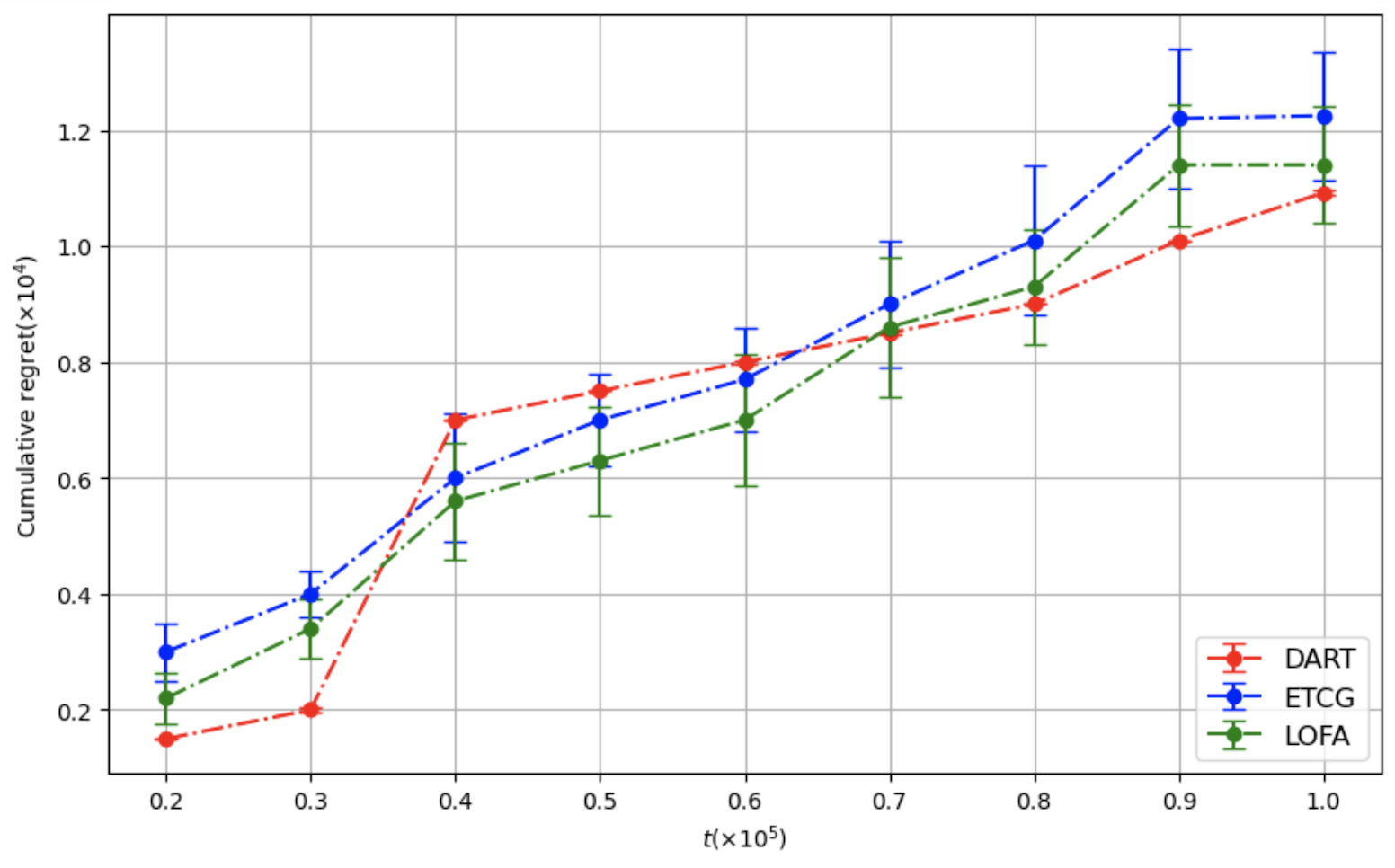
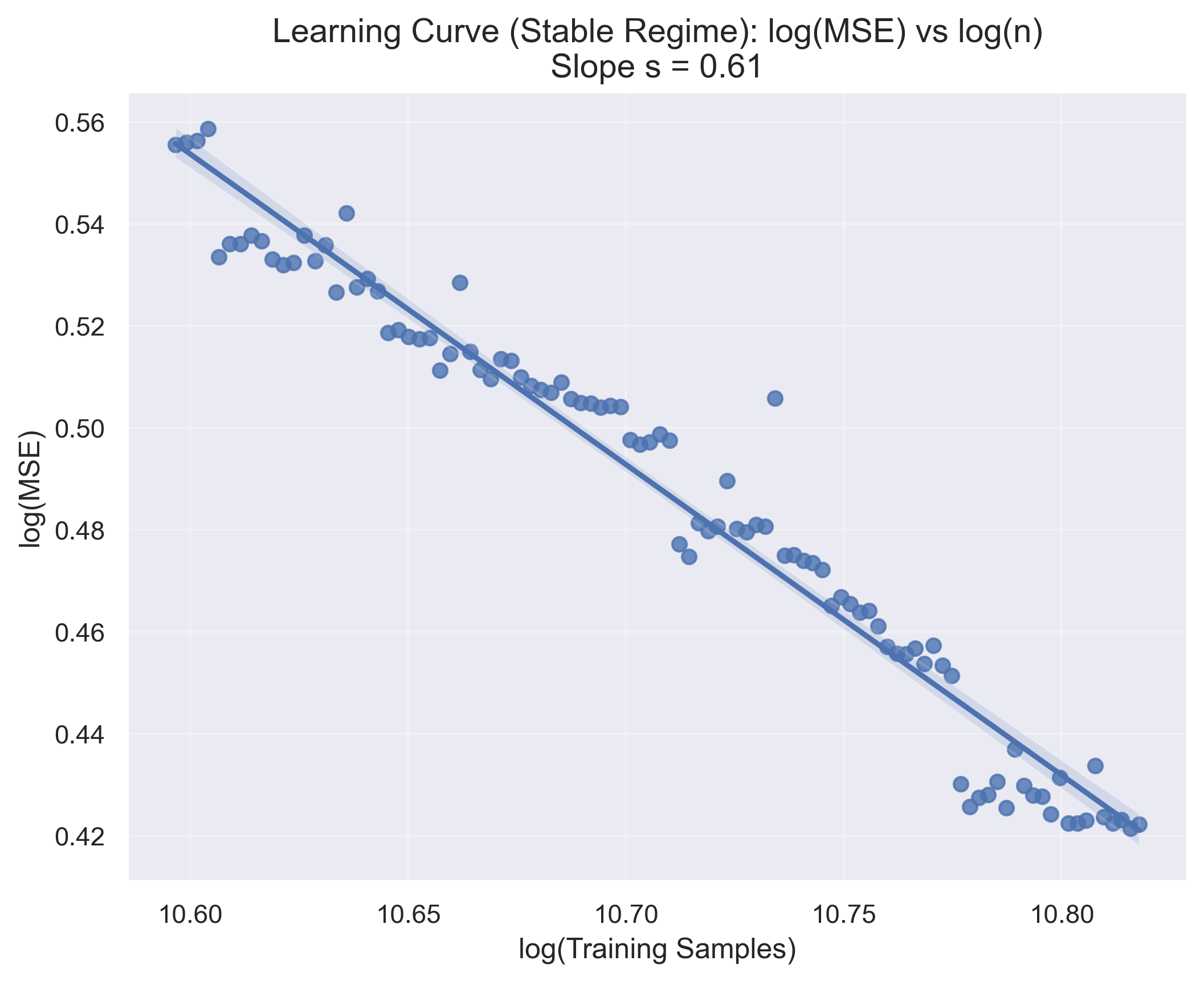
We present ML-UCB, a generalized upper confidence bound algorithm that integrates arbitrary machine learning models into multi-armed bandit frameworks. A fundamental challenge in deploying sophisticated ML models for sequential decision-making is the lack of tractable concentration inequalities required for principled exploration. We overcome this limitation by directly modeling the learning curve behavior of the underlying estimator. Specifically, assuming the Mean Squared Error decreases as a power law in the number of training samples, we derive a generalized concentration inequality and prove that ML-UCB achieves sublinear regret. This framework enables the principled integration of any ML model whose learning curve can be empirically characterized, eliminating the need for model-specific theoretical analysis. We validate our approach through experiments on a collaborative filtering recommendation system using online matrix factorization with synthetic data designed to simulate a simplified two-tower model, demonstrating substantial improvements over LinUCB