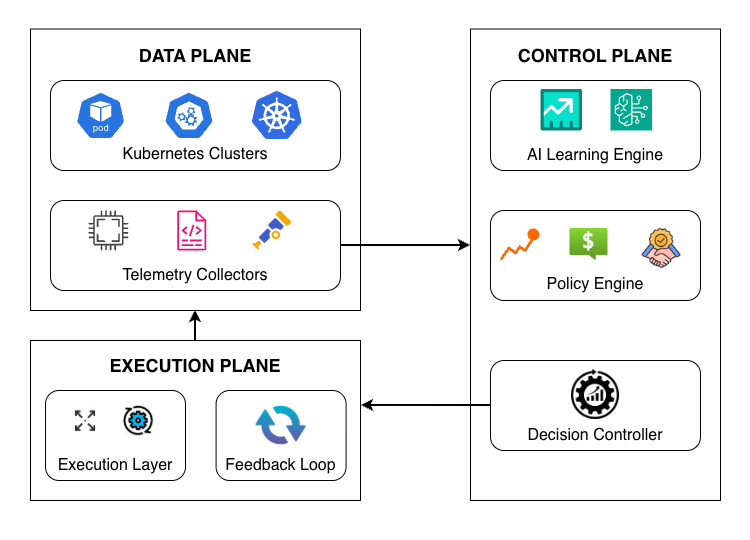
AI-Driven Cloud Resource Optimization for Multi-Cluster Environments
Modern cloud-native systems increasingly rely on multi-cluster deployments to support scalability, resilience, and geographic distribution. However, existing resource management approaches remain largely reactive and cluster-centric, limiting their ability to optimize system-wide behavior under dynamic workloads. These limitations result in inefficient resource utilization, delayed adaptation, and increased operational overhead across distributed environments. This paper presents an AI-driven framework for adaptive resource optimization in multi-cluster cloud systems. The proposed approach integrates predictive learning, policy-aware decision-making, and continuous feedback to enable proactive and coordinated resource management across clusters. By analyzing cross-cluster telemetry and historical execution patterns, the framework dynamically adjusts resource allocation to balance performance, cost, and reliability objectives. A prototype implementation demonstrates improved resource efficiency, faster stabilization during workload fluctuations, and reduced performance variability compared to conventional reactive approaches. The results highlight the effectiveness of intelligent, self-adaptive infrastructure management as a key enabler for scalable and resilient cloud platforms.