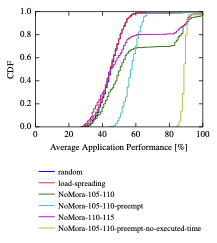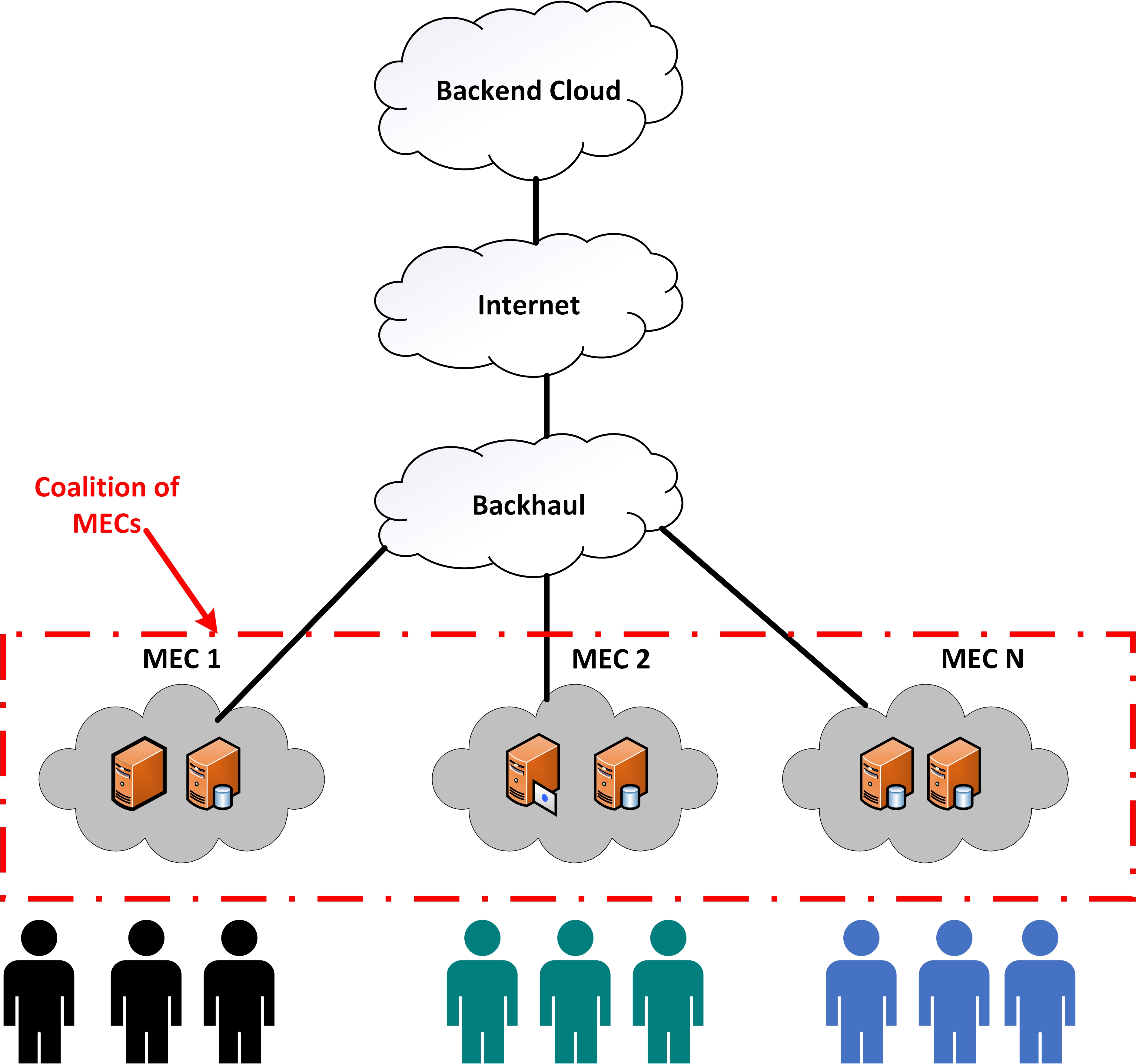
A Study of Network Congestion in Two Supercomputing High-Speed Interconnects
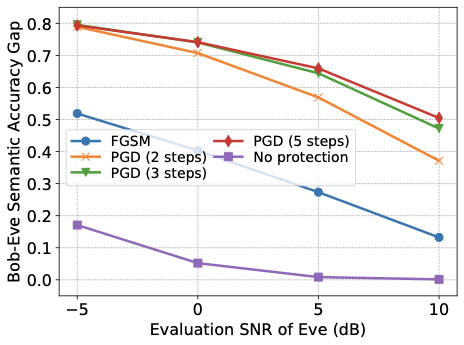
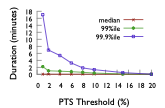
Network congestion in high-speed interconnects is a major source of application run time performance variation. Recent years have witnessed a surge of interest from both academia and industry in the development of novel approaches for congestion control at the network level and in application placement, mapping, and scheduling at the system-level. However, these studies are based on proxy applications and benchmarks that are not representative of field-congestion characteristics of high-speed interconnects. To address this gap, we present (a) an end-to-end framework for monitoring and analysis to support long-term field-congestion characterization studies, and (b) an empirical study of network congestion in petascale systems across two different interconnect technologies (i) Cray Gemini, which uses a 3-D torus topology, and (ii) Cray Aries, which uses the DragonFly topology.