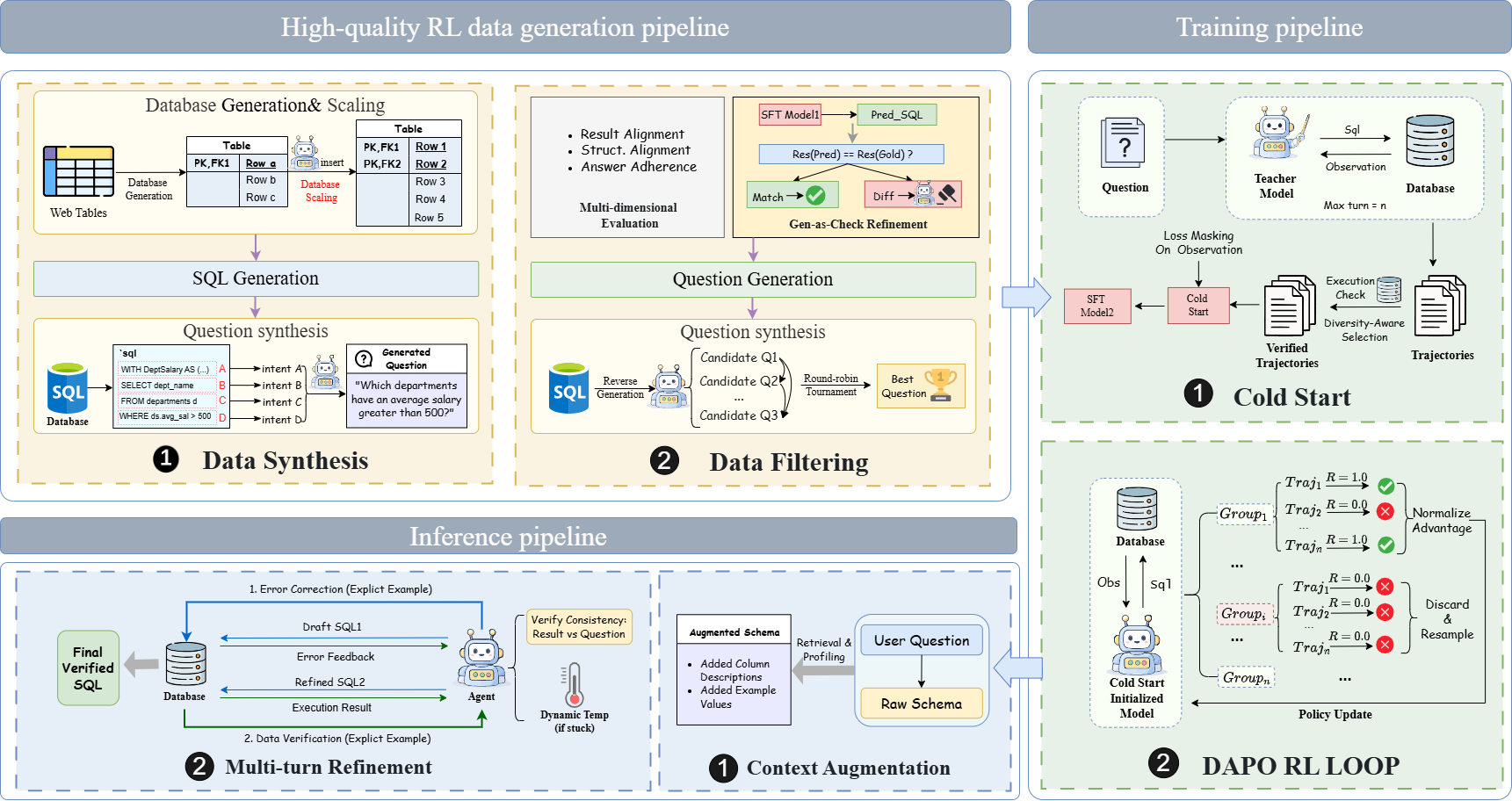
Designing Multi-Level Buffer Management and Storage Systems for Non-Volatile Memory
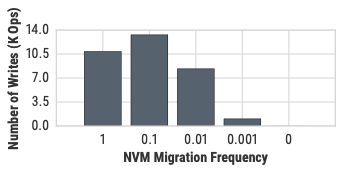
The design of the buffer manager in database management systems (DBMSs) is influenced by the performance characteristics of volatile memory (DRAM) and non-volatile storage (e.g., SSD). The key design assumptions have been that the data must be migrated to DRAM for the DBMS to operate on it and that storage is orders of magnitude slower than DRAM. But the arrival of new non-volatile memory (NVM) technologies that are nearly as fast as DRAM invalidates these previous assumptions. This paper presents techniques for managing and designing a multi-tier storage hierarchy comprising of DRAM, NVM, and SSD. Our main technical contributions are a multi-tier buffer manager and a storage system designer that leverage the characteristics of NVM. We propose a set of optimizations for maximizing the utility of data migration between different devices in the storage hierarchy. We demonstrate that these optimizations have to be tailored based on device and workload characteristics. Given this, we present a technique for adapting these optimizations to achieve a near-optimal buffer management policy for an arbitrary workload and storage hierarchy without requiring any manual tuning. We finally present a recommendation system for designing a multi-tier storage hierarchy for a target workload and system cost budget. Our results show that the NVM-aware buffer manager and storage system designer improve throughput and reduce system cost across different transaction and analytical processing workloads.