Bridging Information Security and Environmental Criminology to Better Mitigate Cybercrime
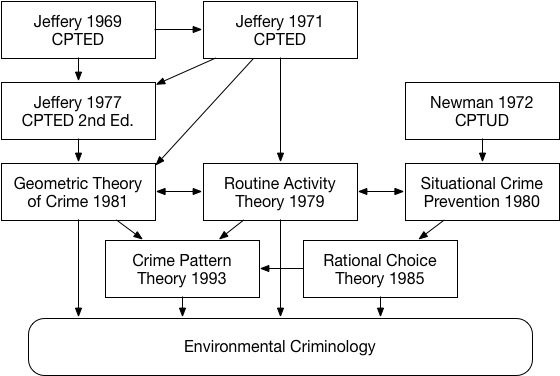
Cybercrime is a complex phenomenon that spans both technical and human aspects. As such, two disjoint areas have been studying the problem from separate angles the information security community and the environmental criminology one. Despite the large body of work produced by these communities in the past years, the two research efforts have largely remained disjoint, with researchers on one side not benefitting from the advancements proposed by the other. In this paper, we argue that it would be beneficial for the information security community to look at the theories and systematic frameworks developed in environmental criminology to develop better mitigations against cybercrime. To this end, we provide an overview of the research from environmental criminology and how it has been applied to cybercrime. We then survey some of the research proposed in the information security domain, drawing explicit parallels between the proposed mitigations and environmental criminology theories, and presenting some examples of new mitigations against cybercrime. Finally, we discuss the concept of cyberplaces and propose a framework in order to define them. We discuss this as a potential research direction, taking into account both fields of research, in the hope of broadening interdisciplinary efforts in cybercrime research.