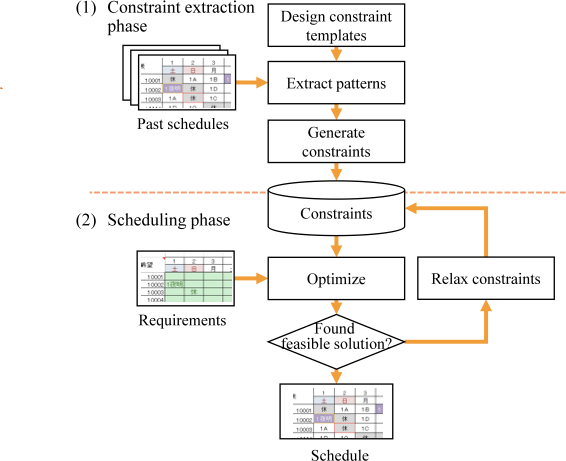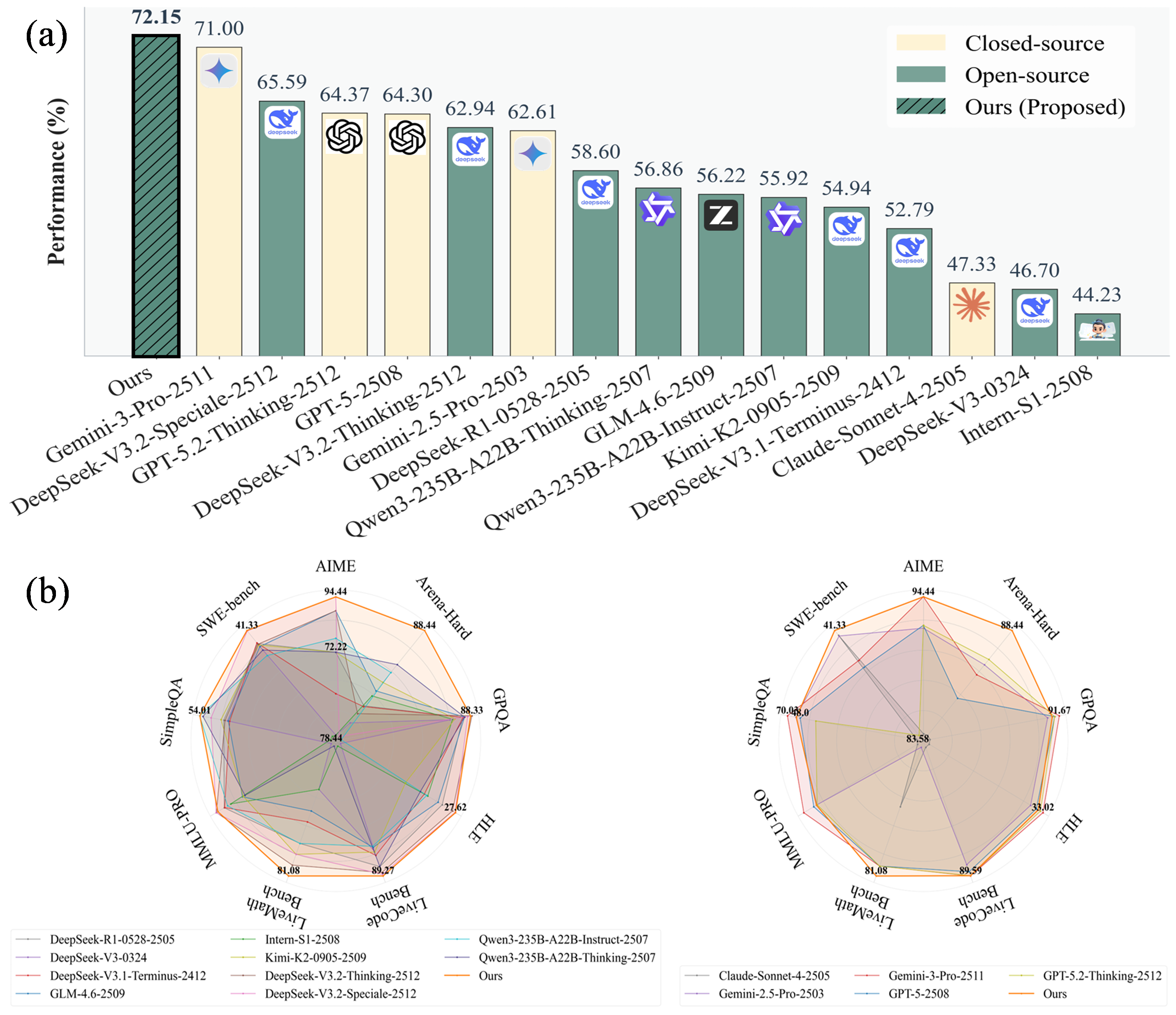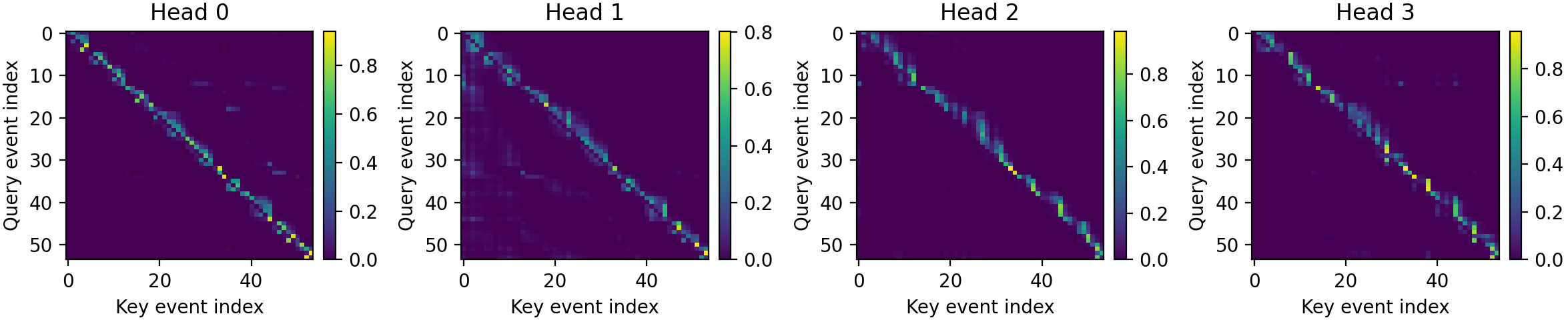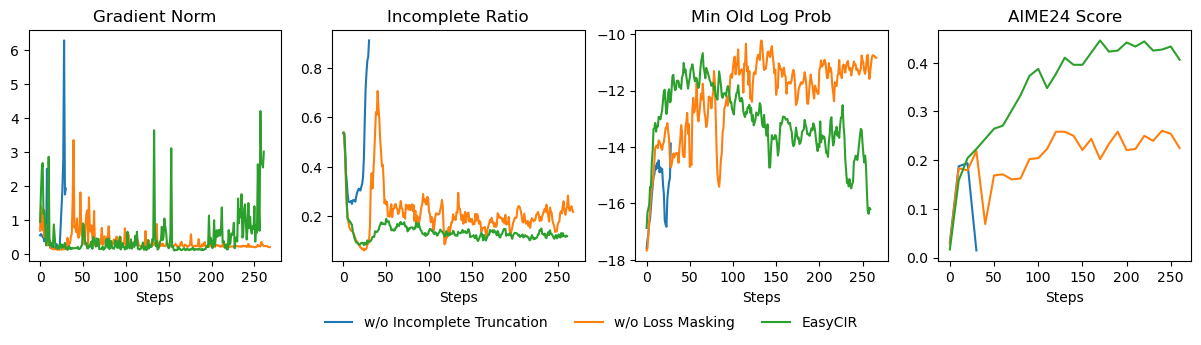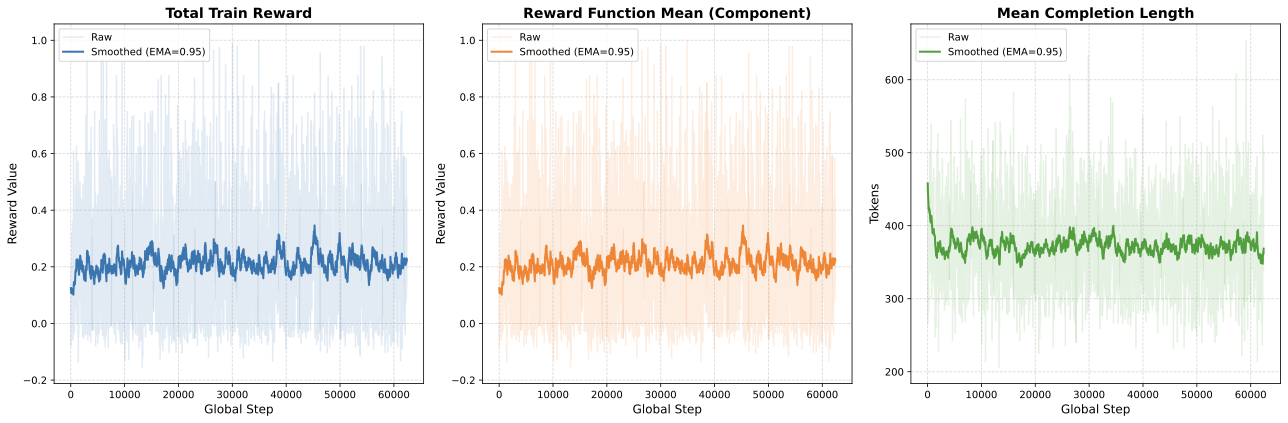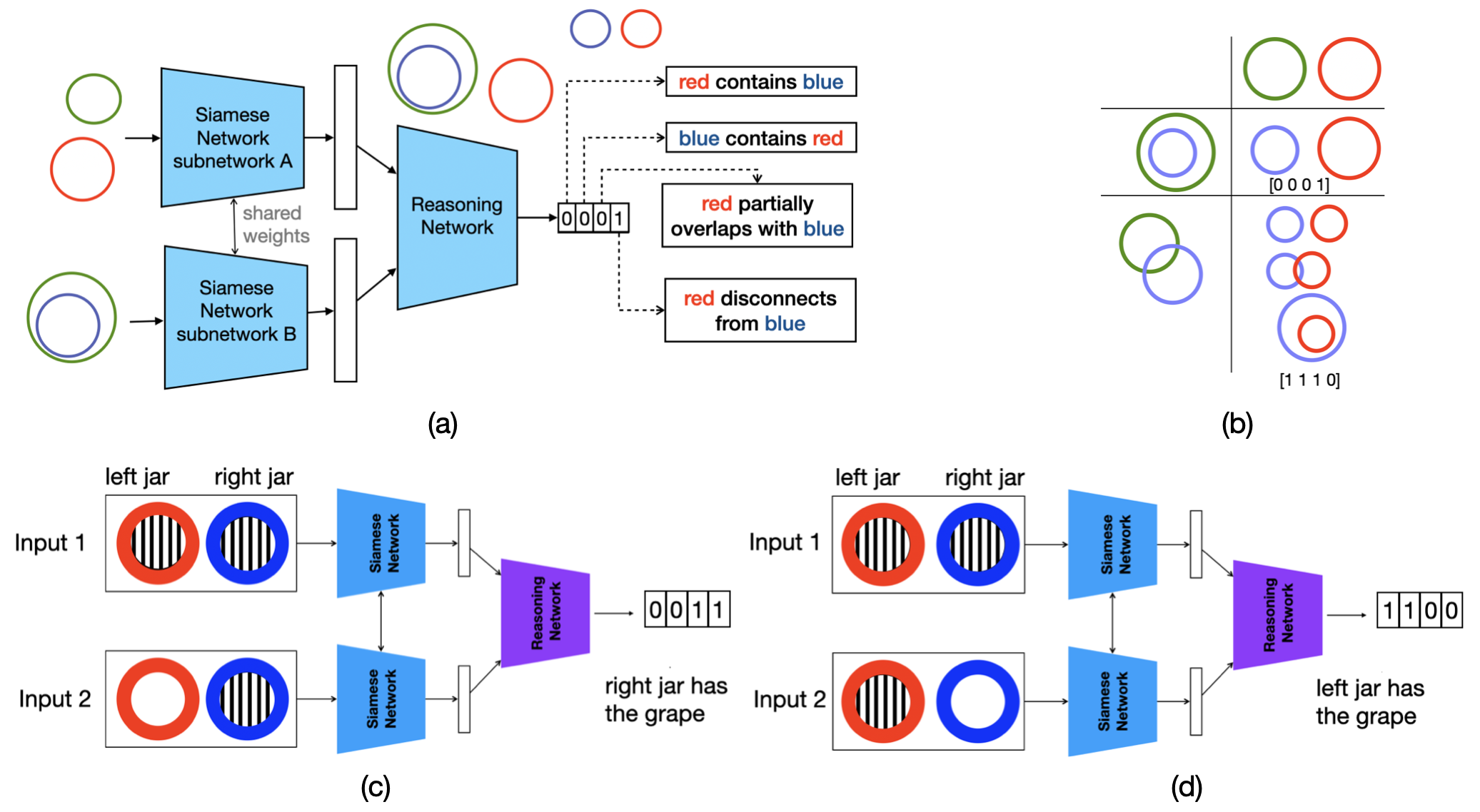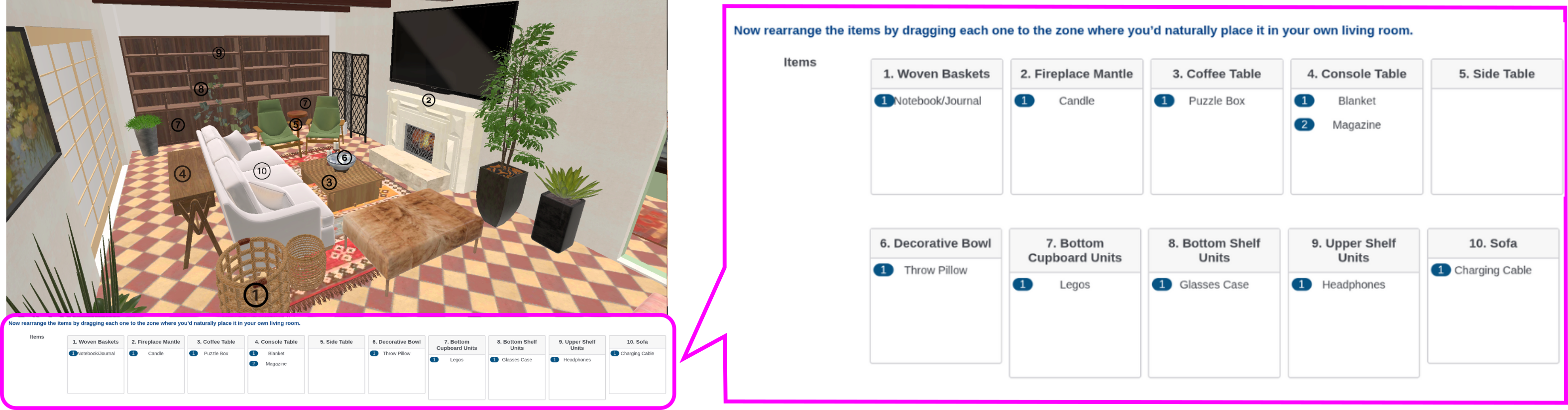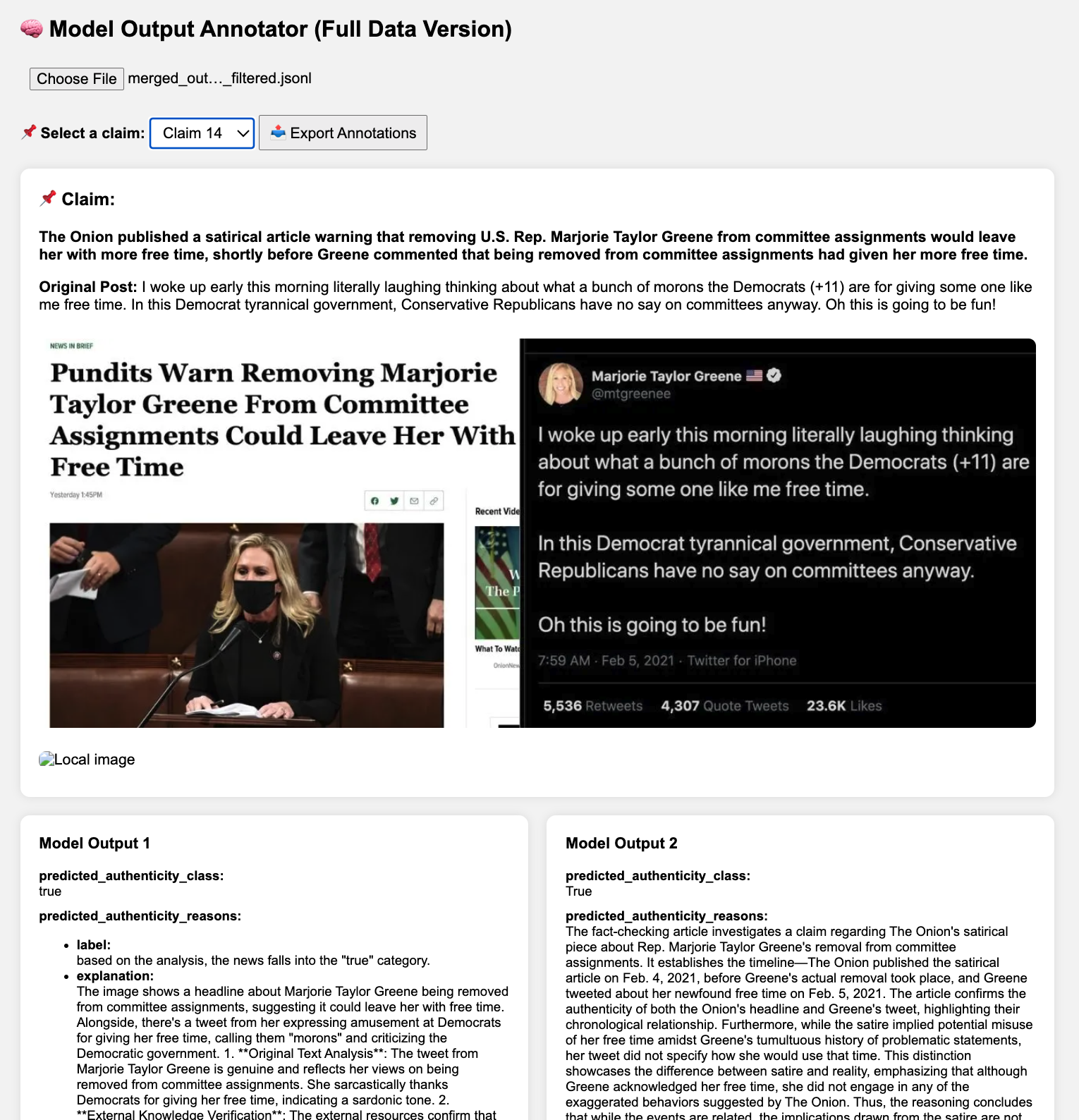
Communication-Efficient Federated Deep Learning with Asynchronous Model Updates and Temporally Weighted Aggregation
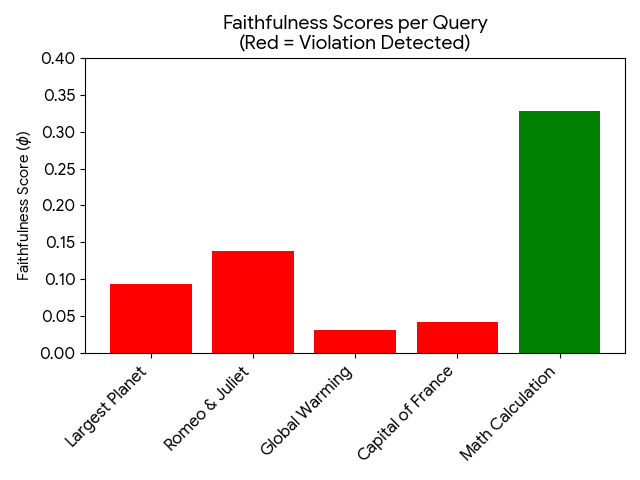
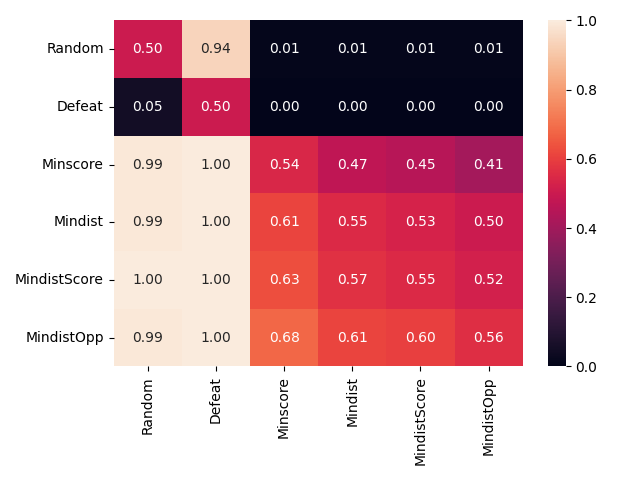
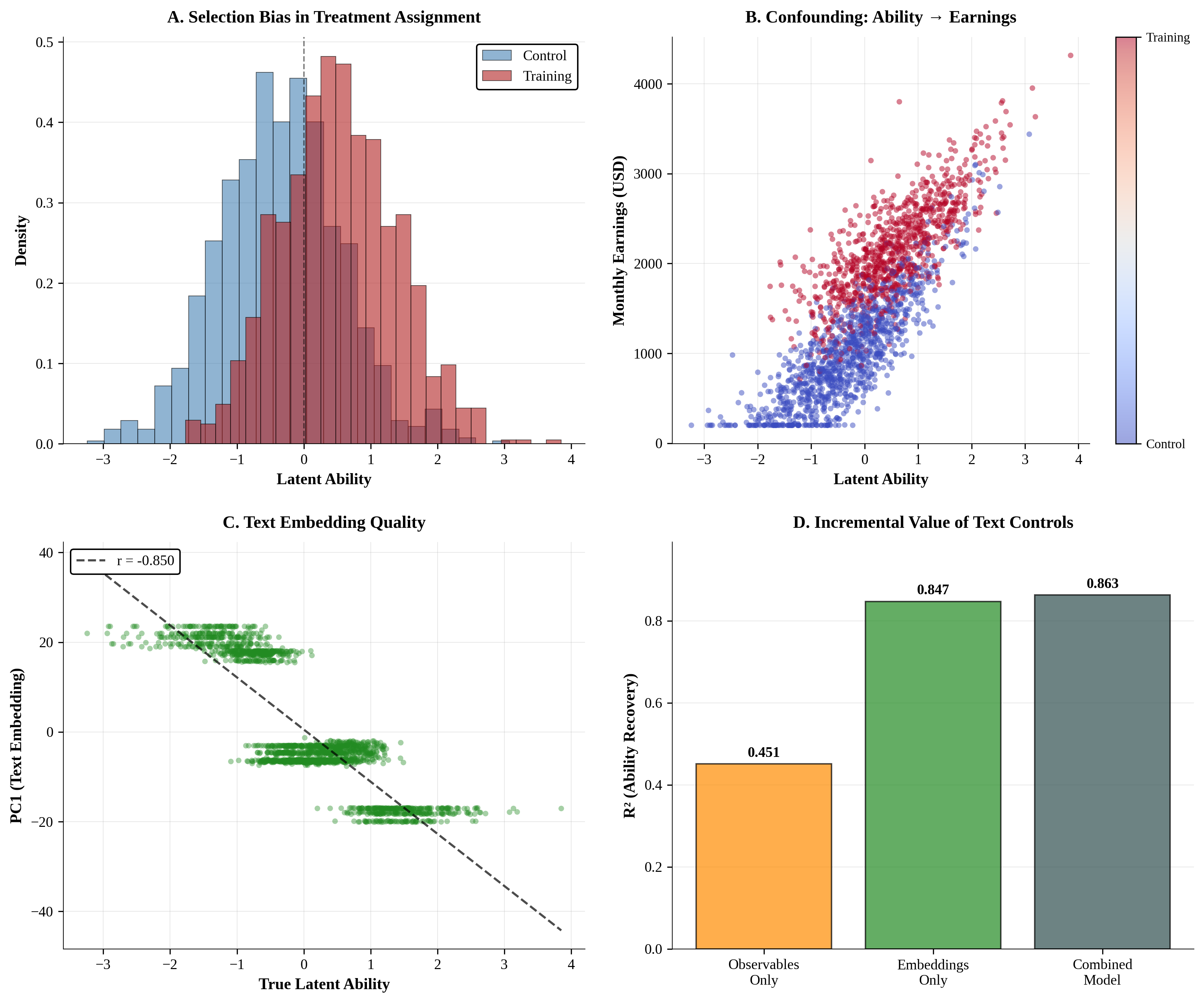
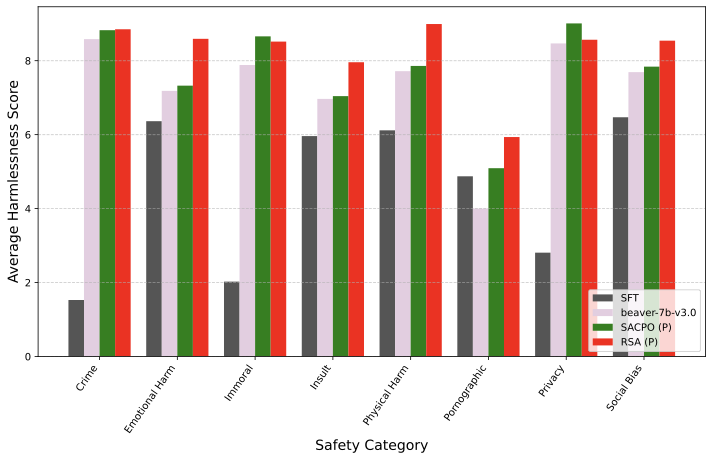
Federated learning obtains a central model on the server by aggregating models trained locally on clients. As a result, federated learning does not require clients to upload their data to the server, thereby preserving the data privacy of the clients. One challenge in federated learning is to reduce the client-server communication since the end devices typically have very limited communication bandwidth. This paper presents an enhanced federated learning technique by proposing a synchronous learning strategy on the clients and a temporally weighted aggregation of the local models on the server. In the asynchronous learning strategy, different layers of the deep neural networks are categorized into shallow and deeps layers and the parameters of the deep layers are updated less frequently than those of the shallow layers. Furthermore, a temporally weighted aggregation strategy is introduced on the server to make use of the previously trained local models, thereby enhancing the accuracy and convergence of the central model. The proposed algorithm is empirically on two datasets with different deep neural networks. Our results demonstrate that the proposed asynchronous federated deep learning outperforms the baseline algorithm both in terms of communication cost and model accuracy.