Learning Multilingual Embeddings for Cross-Lingual Information Retrieval Using Topically Aligned Corpora
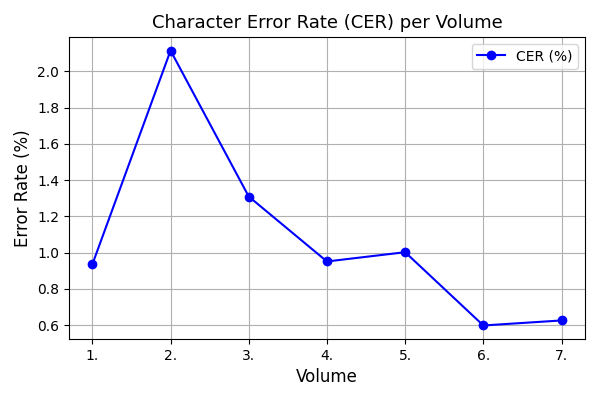
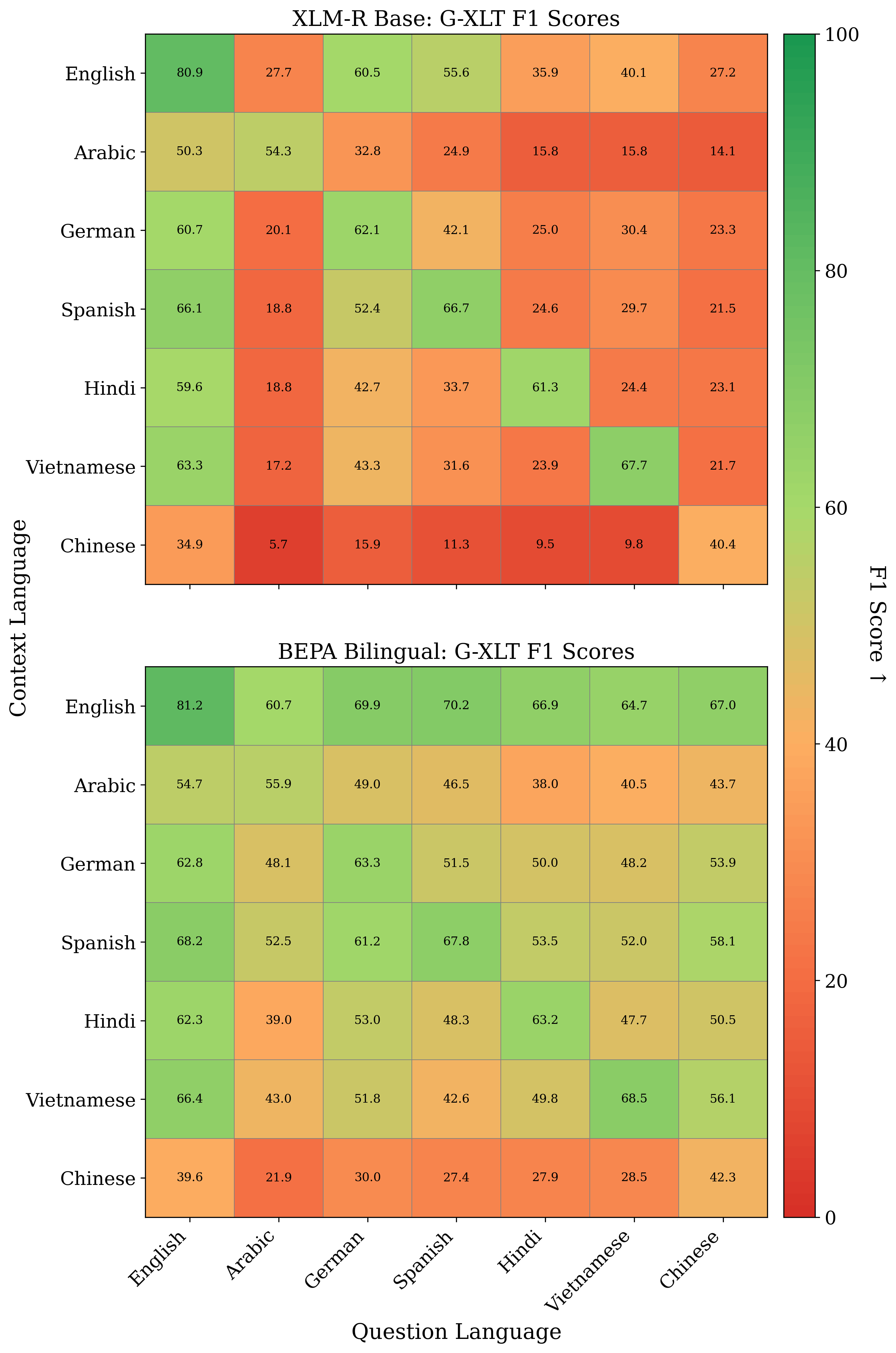
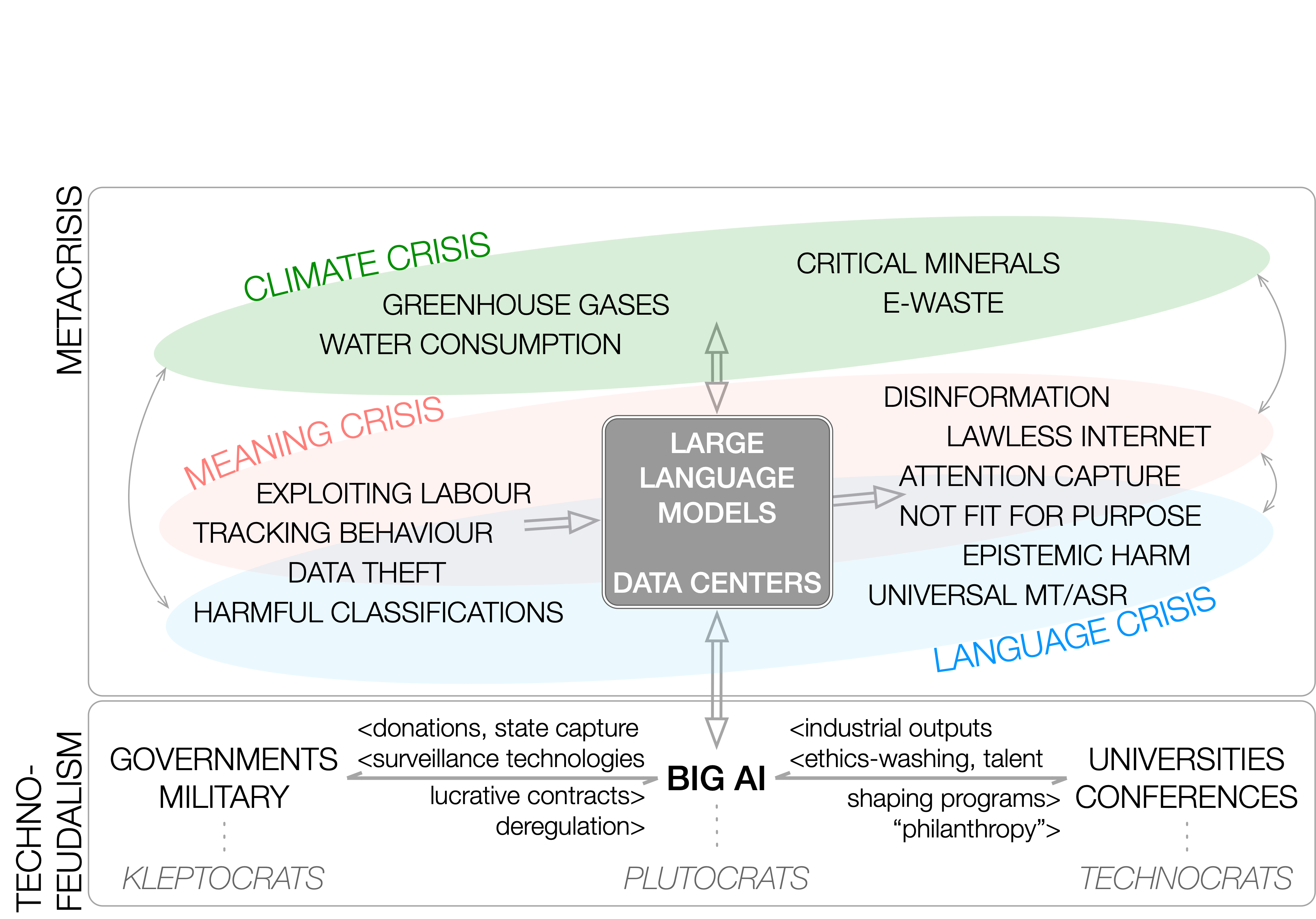
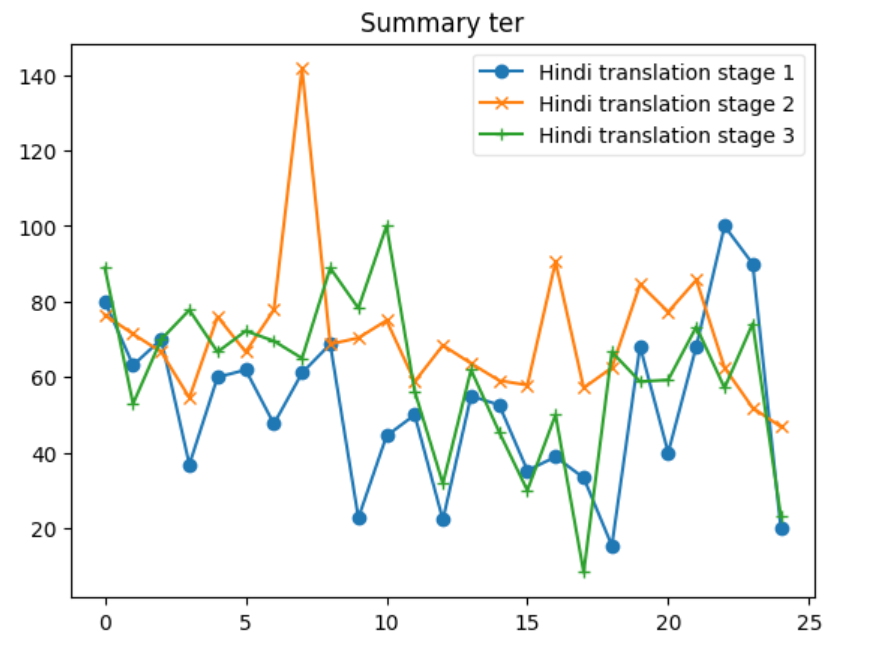
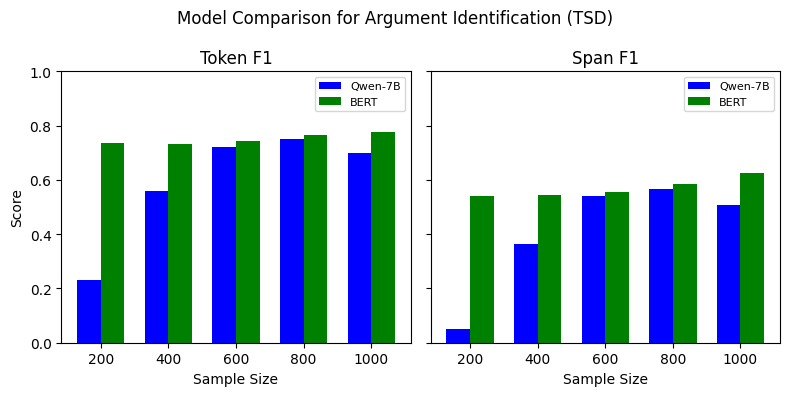
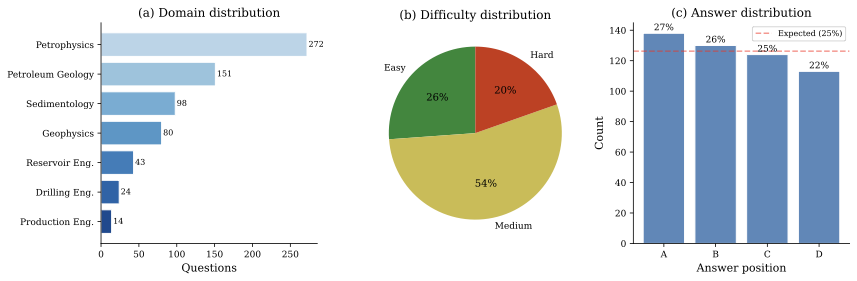
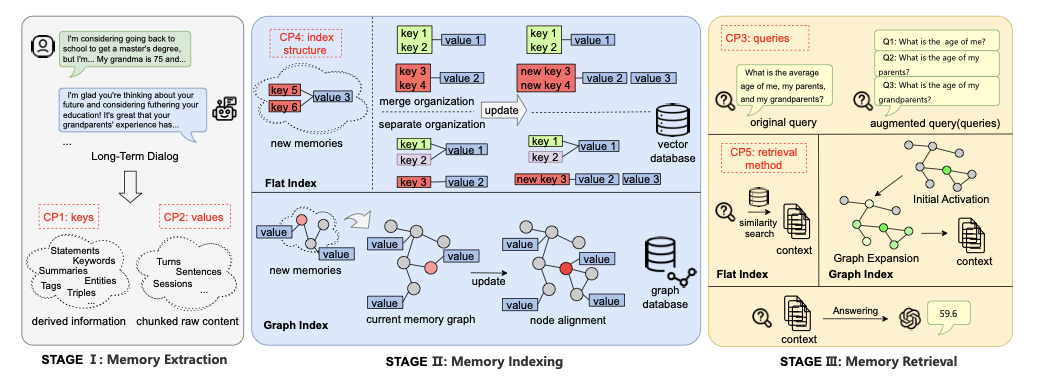
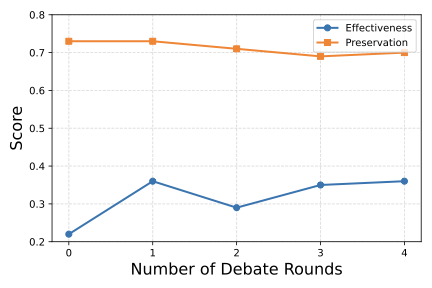
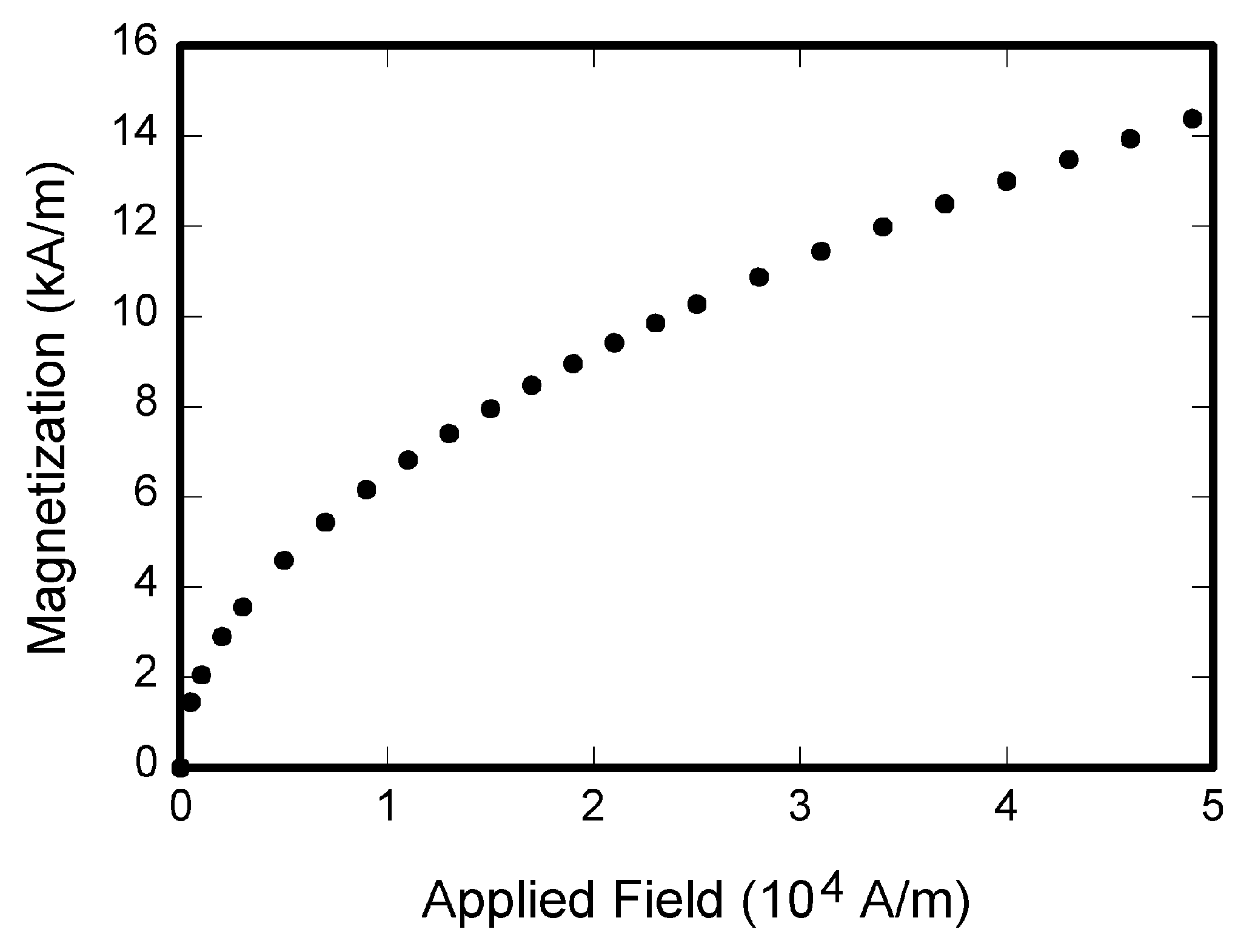
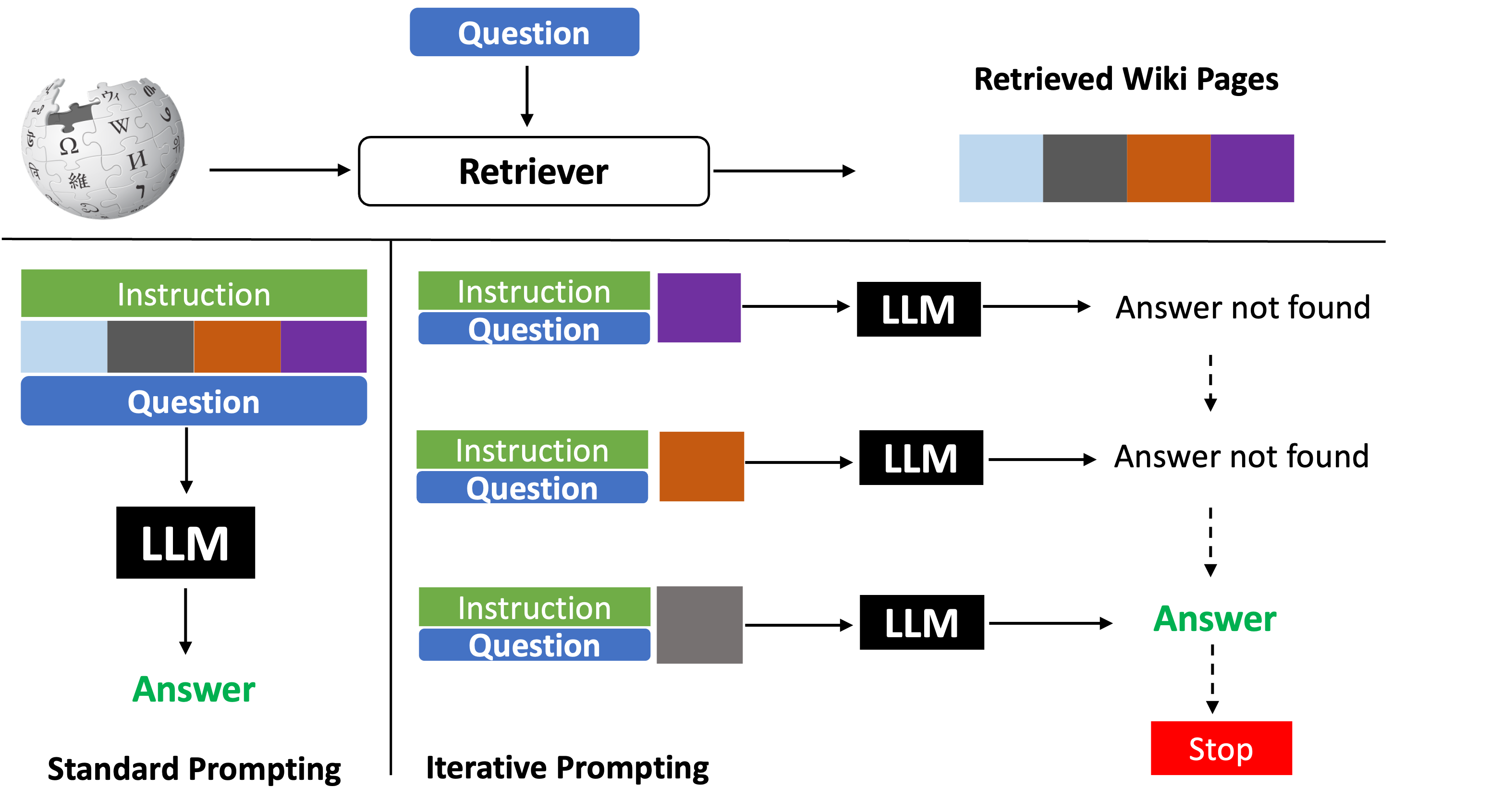
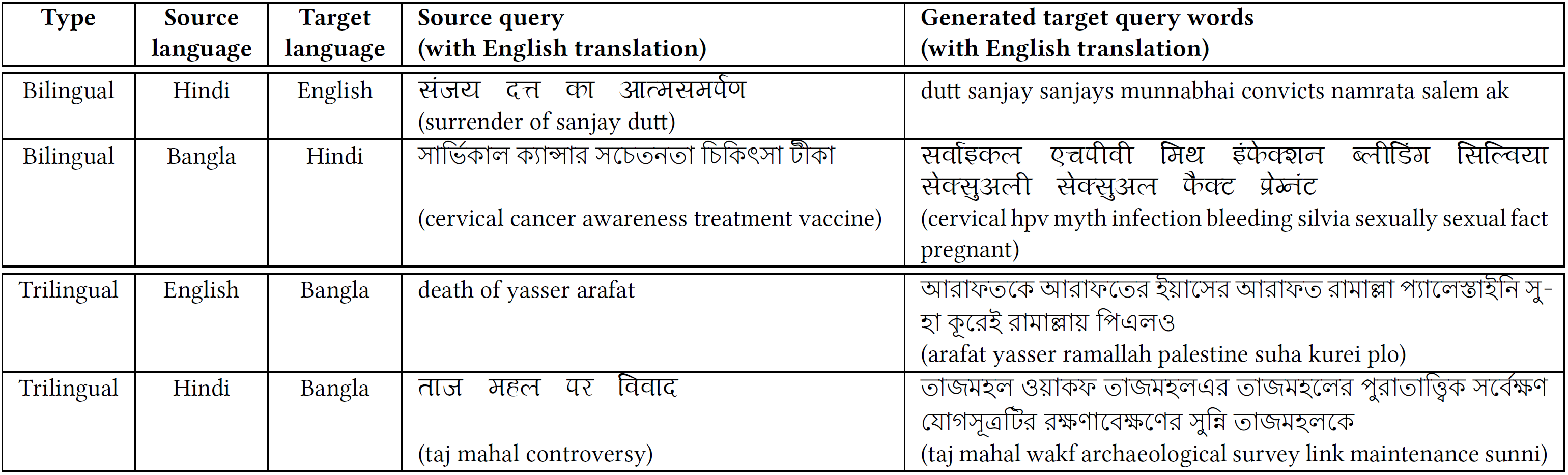
Cross-lingual information retrieval is a challenging task in the absence of aligned parallel corpora. In this paper, we address this problem by considering topically aligned corpora designed for evaluating an IR setup. To emphasize, we neither use any sentence-aligned corpora or document-aligned corpora, nor do we use any language specific resources such as dictionary, thesaurus, or grammar rules. Instead, we use an embedding into a common space and learn word correspondences directly from there. We test our proposed approach for bilingual IR on standard FIRE datasets for Bangla, Hindi and English. The proposed method is superior to the state-of-the-art method not only for IR evaluation measures but also in terms of time requirements. We extend our method successfully to the trilingual setting.