Improving Code-Switching Speech Recognition with TTS Data Augmentation
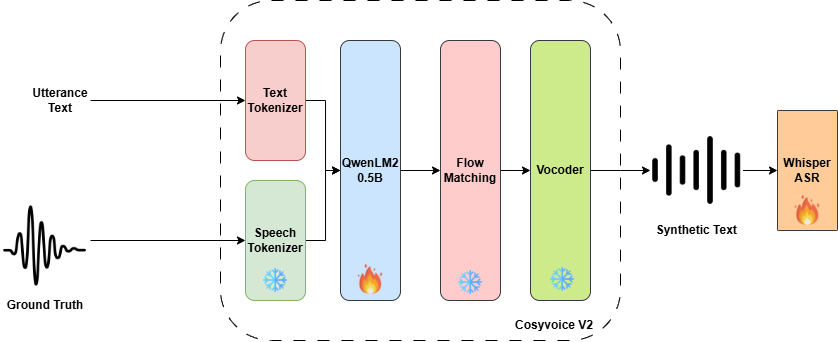
Automatic speech recognition (ASR) for conversational code-switching speech remains challenging due to the scarcity of realistic, high-quality labeled speech data. This paper explores multilingual text-to-speech (TTS) models as an effective data augmentation technique to address this shortage. Specifically, we fine-tune the multilingual CosyVoice2 TTS model on the SEAME dataset to generate synthetic conversational Chinese-English code-switching speech, significantly increasing the quantity and speaker diversity of available training data. Our experiments demonstrate that augmenting real speech with synthetic speech reduces the mixed error rate (MER) from 12.1 percent to 10.1 percent on DevMan and from 17.8 percent to 16.0 percent on DevSGE, indicating consistent performance gains. These results confirm that multilingual TTS is an effective and practical tool for enhancing ASR robustness in low-resource conversational code-switching scenarios.