Authors: ** Yubin Kim¹³†, Ken Gu¹, Chanwoo Park³, Chunjong Park², Samuel Schmidgall², A. Ali Heydari¹, Yao Yan¹, Zhihan Zhang¹, Yuchen Zhuang², Yun Liu¹, Mark Malhotra¹, Paul Pu Liang³, Hae Won Park³, Yuzhe Yang¹, Xuhai Xu¹, Yilun Du¹, Shwetak Patel¹, Tim Althoff¹, Daniel McDuff¹, Xin Liu¹† ¹Google Research, ²Google DeepMind, ³Massachusetts Institute of Technology †Corresponding authors: ybkim95@mit.edu, xliucs@google.com — **
📝 Abstract
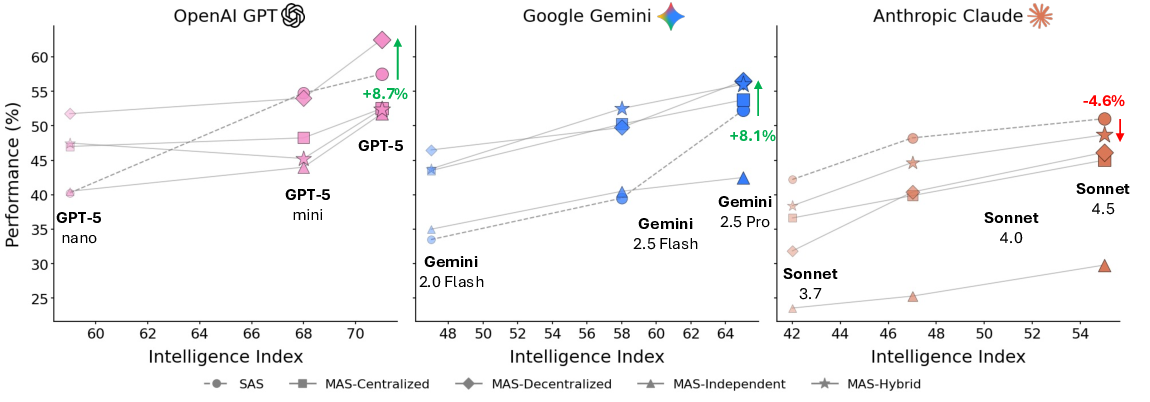
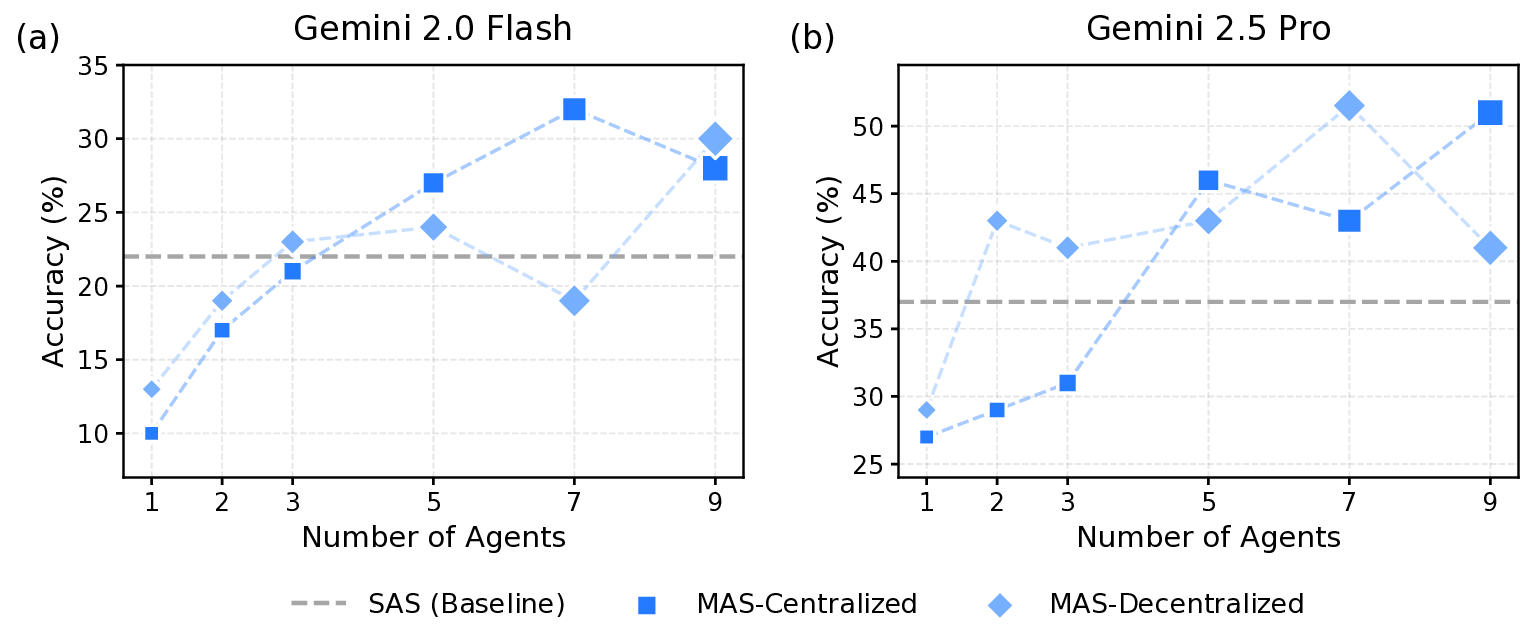
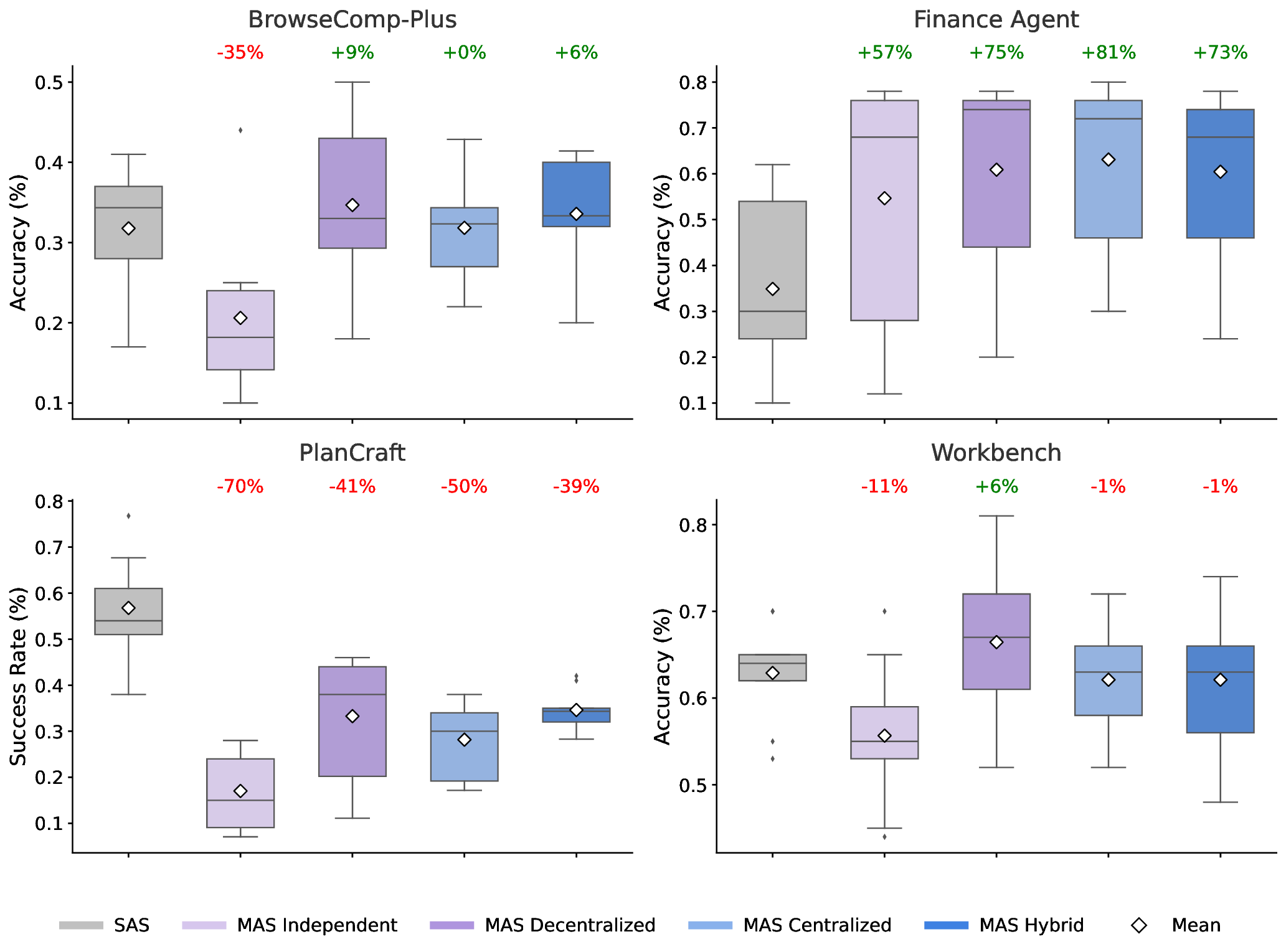
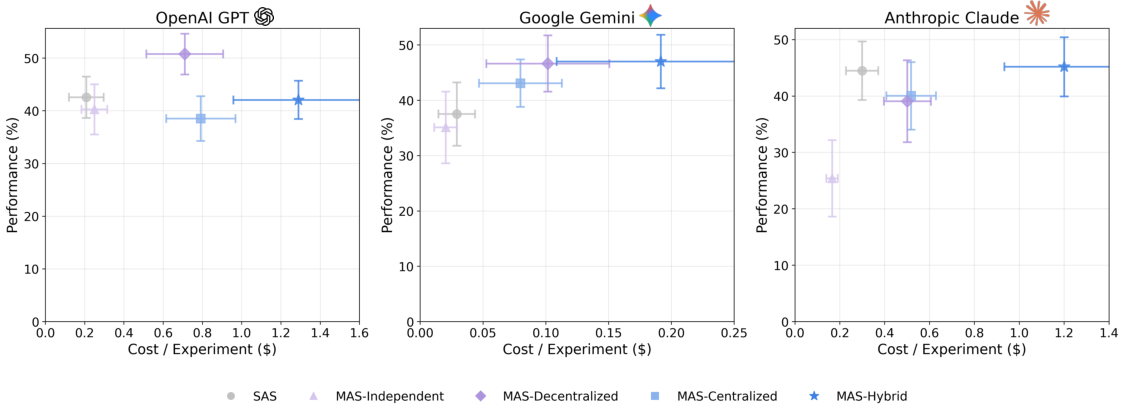
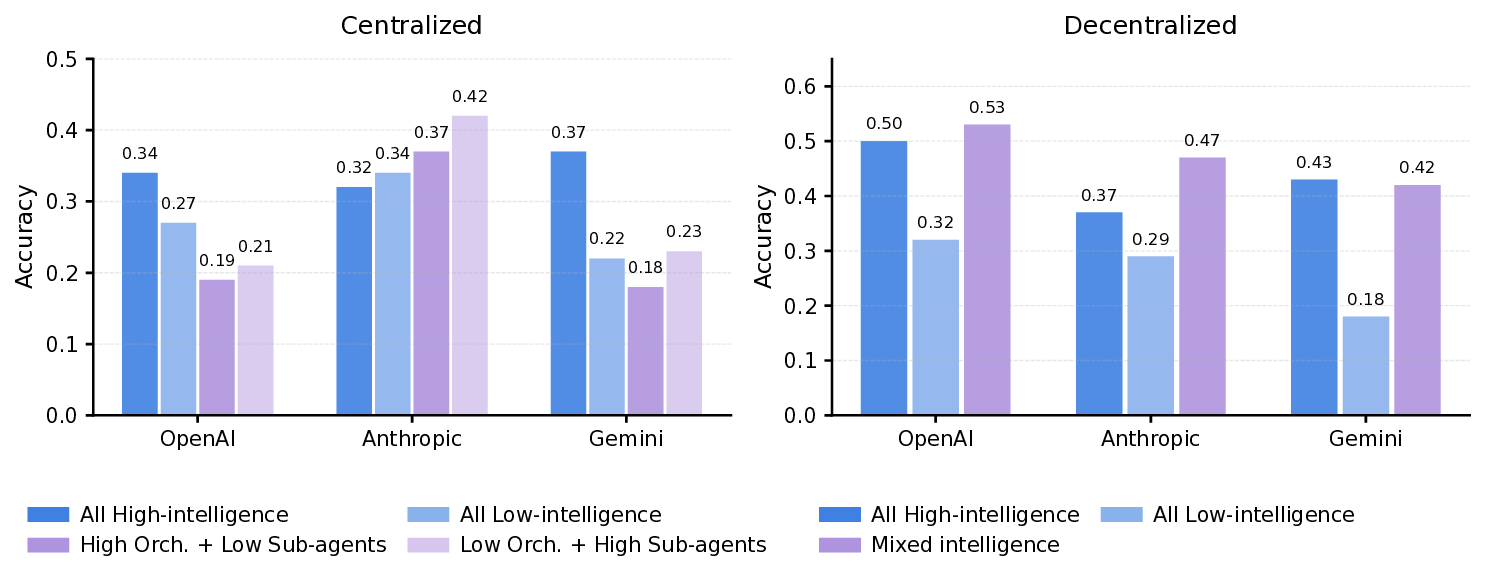
Agents, language model (LM)-based systems that are capable of reasoning, planning, and acting are becoming the dominant paradigm for real-world AI applications. Despite this widespread adoption, the principles that determine their performance remain underexplored, leaving practitioners to rely on heuristics rather than principled design choices. We address this gap by deriving quantitative scaling principles for agent systems. We first formalize a definition for agentic evaluation and characterize scaling laws as the interplay between agent quantity, coordination structure, model capability, and task properties. We evaluate this across four diverse benchmarks: Finance-Agent, BrowseComp-Plus, PlanCraft, and Workbench, spanning financial reasoning, web navigation, game planning, and workflow execution. Using five canonical agent architectures (Single-Agent System and four Multi-Agent Systems: Independent, Centralized, Decentralized, Hybrid), instantiated across three LLM families, we perform a controlled evaluation spanning 180 configurations, standardizing tools, prompt structures, and token budgets to isolate architectural effects from implementation confounds. We derive a predictive model using empirical coordination metrics, including efficiency, overhead, error amplification, and redundancy, that achieves cross-validated 𝑅 2 =0.524, enabling prediction on unseen task domains by modeling task properties rather than overfitting to a specific dataset. We identify three dominant effects: (1) a tool-coordination trade-off : under fixed computational budgets, tool-heavy tasks suffer disproportionately from multi-agent overhead. (2) a capability saturation: we observe that coordination yields diminishing or negative returns ( β=-0.404, 𝑝<0.001) once single-agent baselines exceed an empirical threshold of ∼45%. (3) topology-dependent error amplification: independent agents amplify errors 17.2× through unchecked propagation, while centralized coordination contains this to 4.4×. Crucially, coordination benefits are task-contingent. Centralized coordination improves performance by 80.8% on parallelizable tasks like financial reasoning, while decentralized coordination excels on dynamic web navigation (+9.2% vs. +0.2%). Yet for sequential reasoning tasks, every multi-agent variant we tested degraded performance by 39-70%. The framework predicts the optimal coordination strategy for 87% of held-out configurations. Out-of-sample validation on GPT-5.2, released after our study, achieves MAE=0.071 and confirms four of five scaling principles generalize to unseen frontier models, providing a quantitatively predictive framework for agentic scaling based on measurable task properties.