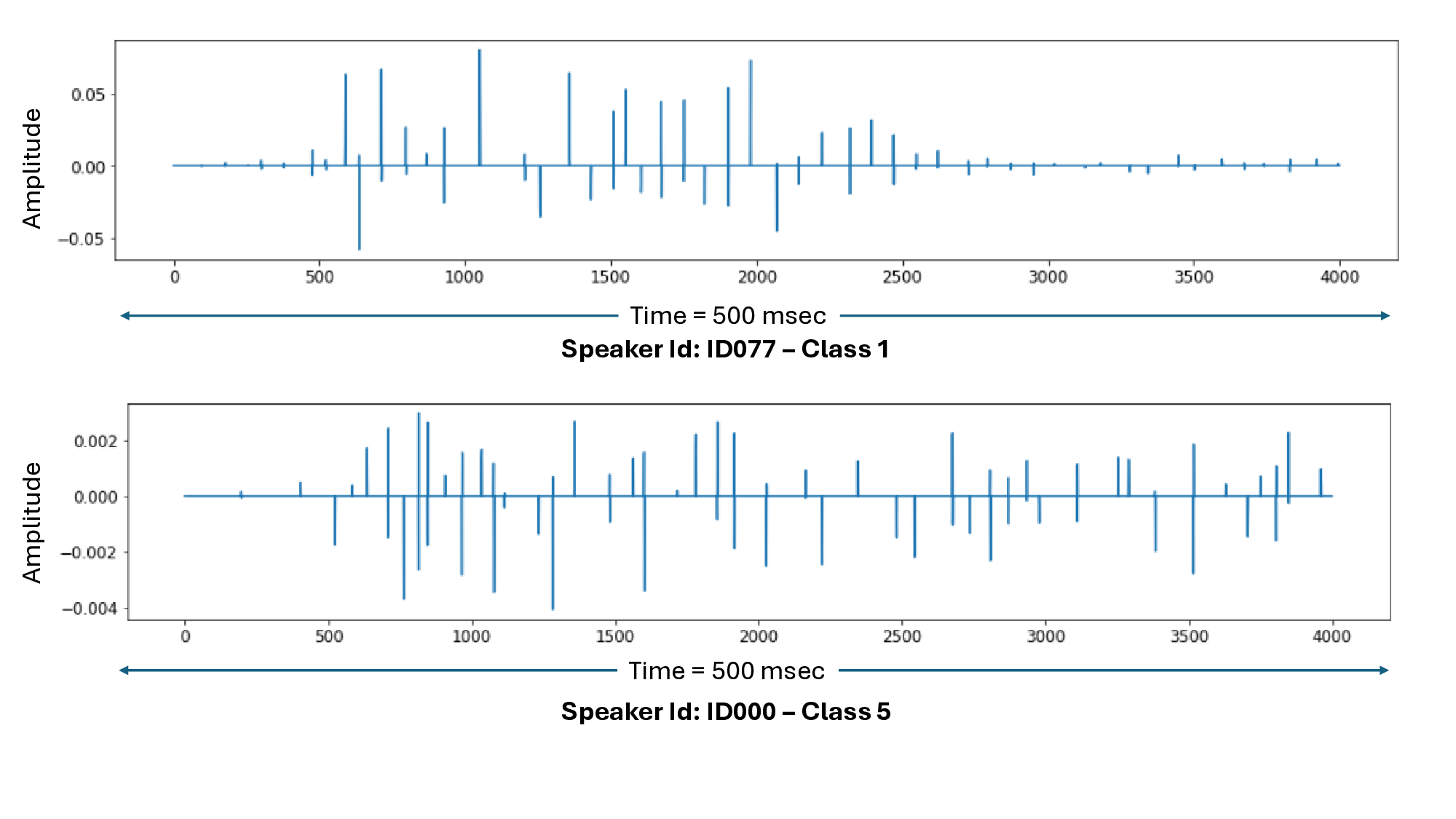
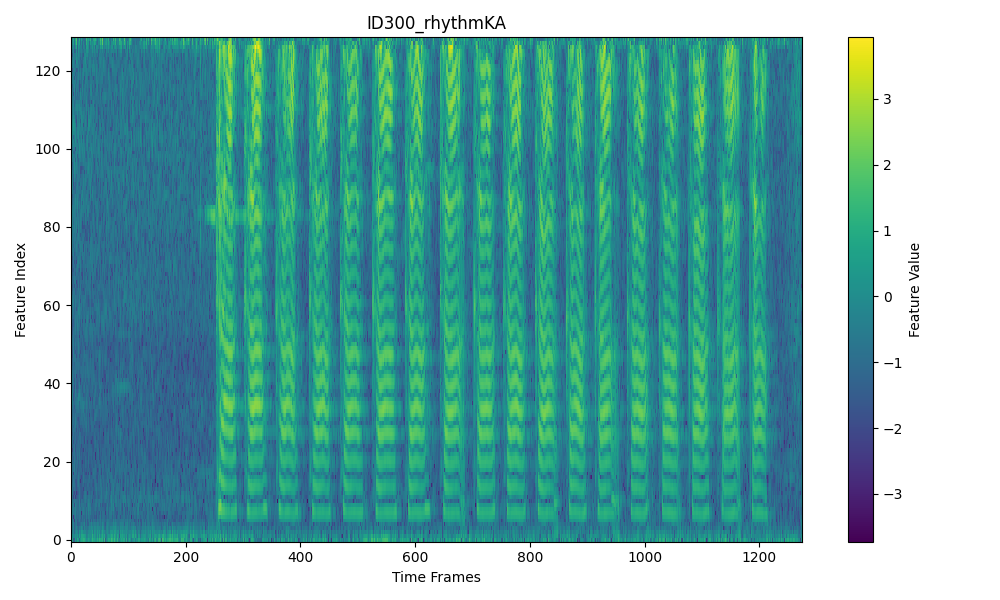
This paper presents a unified study of four distinct modeling approaches for classifying dysarthria severity in the Speech Analysis for Neurodegenerative Diseases (SAND) challenge. All models tackle the same five-class classification task (ALS patients rated 1-4 in severity, and 5 for healthy controls) using a common dataset of ALS patient speech recordings. We investigate: (1) a VIT-AVE method leveraging a Vision Transformer on spectrogram images with an averaged-loss training strategy, (2) a 1D-CNN approach using eight 1-D convolutional neural networks (CNNs) with majority-vote fusion, (3) a BILSTM-OF approach using nine BiLSTM models with majority-vote fusion, and (4) a Hierarchical XGBoost ensemble that combines glottal and formant features through a two-stage learning framework. Each method is described, and their performances on a validation set of 53 speakers are compared. Results show that while the feature-engineered XGBoost ensemble achieves the highest macro-F1 (0.86), the deep learning models (ViT, CNN, BiLSTM) attain competitive F1-scores (0.64-0.70) and offer complementary insights into the problem. We discuss the trade-offs of each approach and highlight how they can be seen as complementary strategies addressing different facets of dysarthria classification. In conclusion, combining domain-specific features with datadriven methods appears promising for robust dysarthria severity prediction.
💡 Deep Analysis
📄 Full Content
SAND CHALLENGE: FOUR APPROACHES FOR DYSARTHRIA SEVERITY
CLASSIFICATION
Gauri Deshpande, Harish Battula, Ashish Panda, Sunil Kumar Kopparapu
TCS Research, Tata Consultancy Services Limited, India
ABSTRACT
This paper presents a unified study of four distinct modeling
approaches for classifying dysarthria severity in the Speech
Analysis for Neurodegenerative Diseases (SAND) challenge.
All models tackle the same five-class classification task (ALS
patients rated 1–4 in severity, and 5 for healthy controls) using
a common dataset of ALS patient speech recordings. We in-
vestigate: (1) a VIT-AVE method leveraging a Vision Trans-
former on spectrogram images with an averaged-loss training
strategy, (2) a 1D-CNN approach using eight 1-D convo-
lutional neural networks (CNNs) with majority-vote fusion,
(3) a BILSTM-OF
approach using nine BiLSTM models
with majority-vote fusion, and (4) a Hierarchical XGBoost
ensemble that combines glottal and formant features through
a two-stage learning framework. Each method is described,
and their performances on a validation set of 53 speakers are
compared. Results show that while the feature-engineered
XGBoost ensemble achieves the highest macro-F1 (0.86), the
deep learning models (ViT, CNN, BiLSTM) attain competi-
tive F1-scores (0.64–0.70) and offer complementary insights
into the problem. We discuss the trade-offs of each approach
and highlight how they can be seen as complementary strate-
gies addressing different facets of dysarthria classification.
In conclusion, combining domain-specific features with data-
driven methods appears promising for robust dysarthria sever-
ity prediction.
Index Terms— BiLSTM, CNN, Glottal Features, Phase
Features, Late Fusion, Hierarchical Modeling, ViT
1. INTRODUCTION
Dysarthria is a motor speech disorder common in neuro-
degenerative diseases such as Amyotrophic Lateral Sclerosis
(ALS). The Speech Analysis for Neuro-degenerative Diseases
(SAND) challenge [1] at ICASSP 2026 focuses on automatic
classification of dysarthria severity into five levels. Task #1
of this challenge asks participants to predict the severity class
(“ALSFRS-R” score category) for each speaker’s voice, given
a fixed set of short utterances (spoken vowels and syllables).
Class labels range from 1 (most severe dysarthric speech) to 4
(milder dysarthria in ALS patients), and 5 for healthy control
speakers.
All approaches in this study use the same dataset provided
in SAND challenge. The dataset contains recorded utterances
from 219 ALS patients for training and 53 speakers for val-
idation.
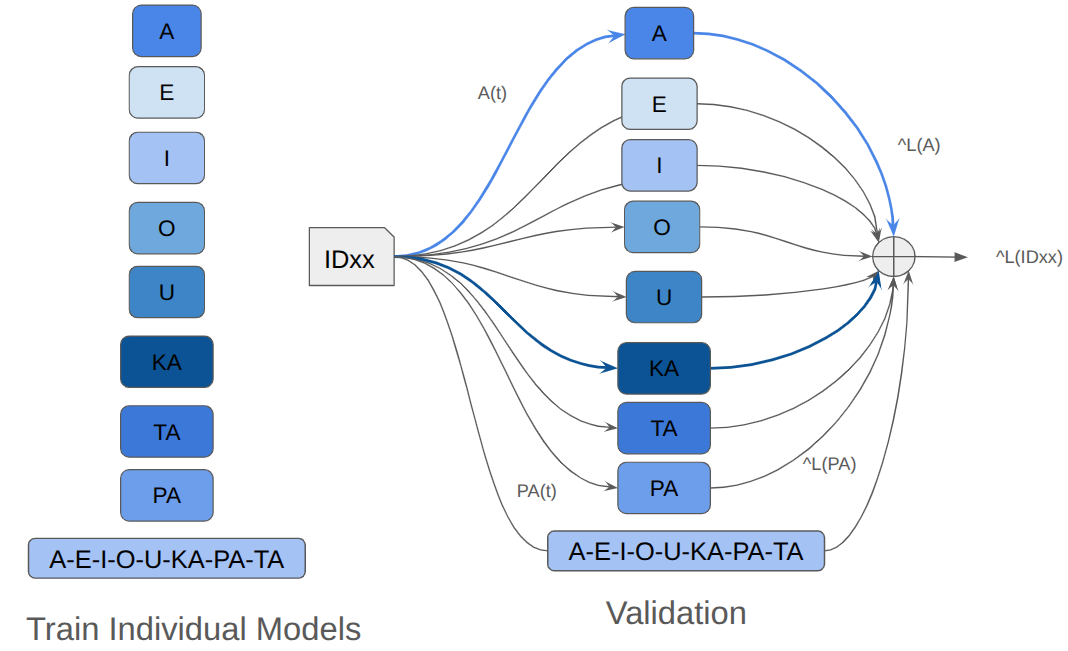
Each speaker provides 8 specific utterances: five
sustained phonations (vowels A, E, I, O, U) and three repet-
itive rhythmic syllables (KA, PA, TA). These utterances cap-
ture different aspects of speech production (vowel phonation
versus articulatory rhythm). The classification task is chal-
lenging due to severe class imbalance – for example, only 4
speakers are labeled Class 1 (most severe) while 86 are Class
5 (healthy) in the training set. This imbalance necessitates
strategies like data augmentation and weighted loss to avoid
biasing toward the majority class. Additionally, there is a gen-
der imbalance, with male-to-female ratios of 1.28 in training
and 1.30 in validation sets (see Table 1).
In this paper, we consolidate four complementary models
developed for SAND Task #1, integrating our findings into
a single cohesive report.
Despite differing methodologies,
all four aim to maximize classification accuracy on the same
task and dataset. By unifying their perspectives, we provide a
comprehensive view of how diverse techniques, ranging from
deep learning on raw spectrograms to machine learning on
engineered features, can contribute to the dysarthria sever-
ity classification problem. The following sections describe
each approach’s methodology, followed by a comparison of
their performance and a discussion on their complementary
strengths.
Table 1: Gender distribution across classes, SAND Task #1
dataset.
Training Baseline
Validation Baseline
Class
F
M
Total
Class
F
M
Total
1
3
1
4
1
1
1
2
2
12
10
22
2
3
1
4
3
16
29
45
3
5
7
12
4
24
38
62
4
4
10
14
5
41
45
86
5
10
11
21
Total
96
123
219
Total
23
30
53
Male/Female ratio = 1.28
Male/Female ratio = 1.30
arXiv:2512.02669v1 [cs.SD] 2 Dec 2025
2. METHODOLOGY
We developed four different models to address the five-class
dysarthria classification. Each approach leverages a unique
modeling technique and fusion strategy for the multiple utter-
ances per speaker. In the following, we detail each approach:
VIT-AVE , Hierarchical XGBoost, 1D-CNN , and BILSTM-
OF .
2.1. ViT Model with Averaged Loss (VIT-AVE )
The VIT-AVE approach uses a vision transformer model to
classify dysarthria severity from spectrogram images.
We
started with a pre-trained Vision Transformer (ViT-B16)
model (originally developed for image recognition) and fine-
tuned it on the speech spectrogram data. Each audio utterance
(vowel or syllable) was converted to a 2D spec