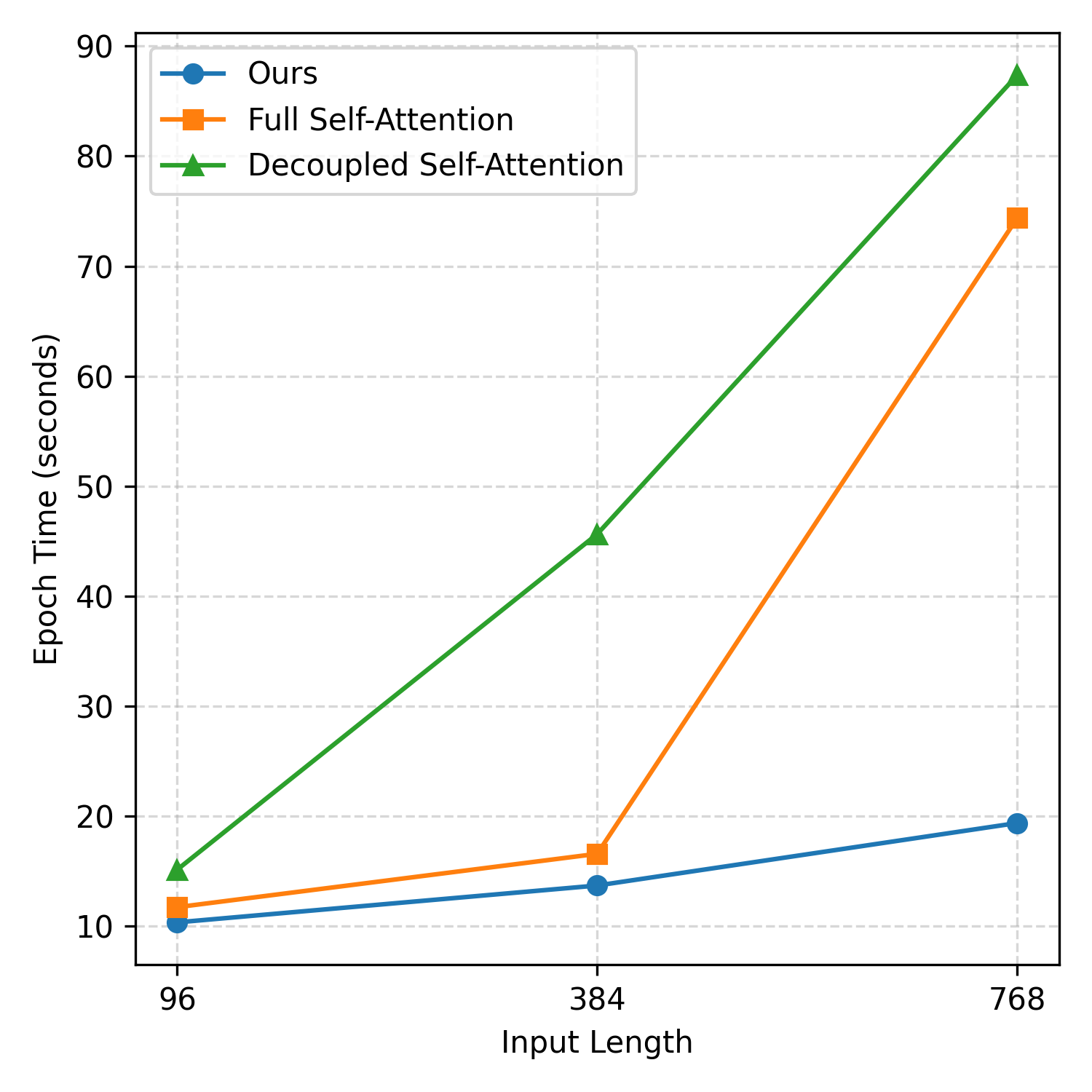
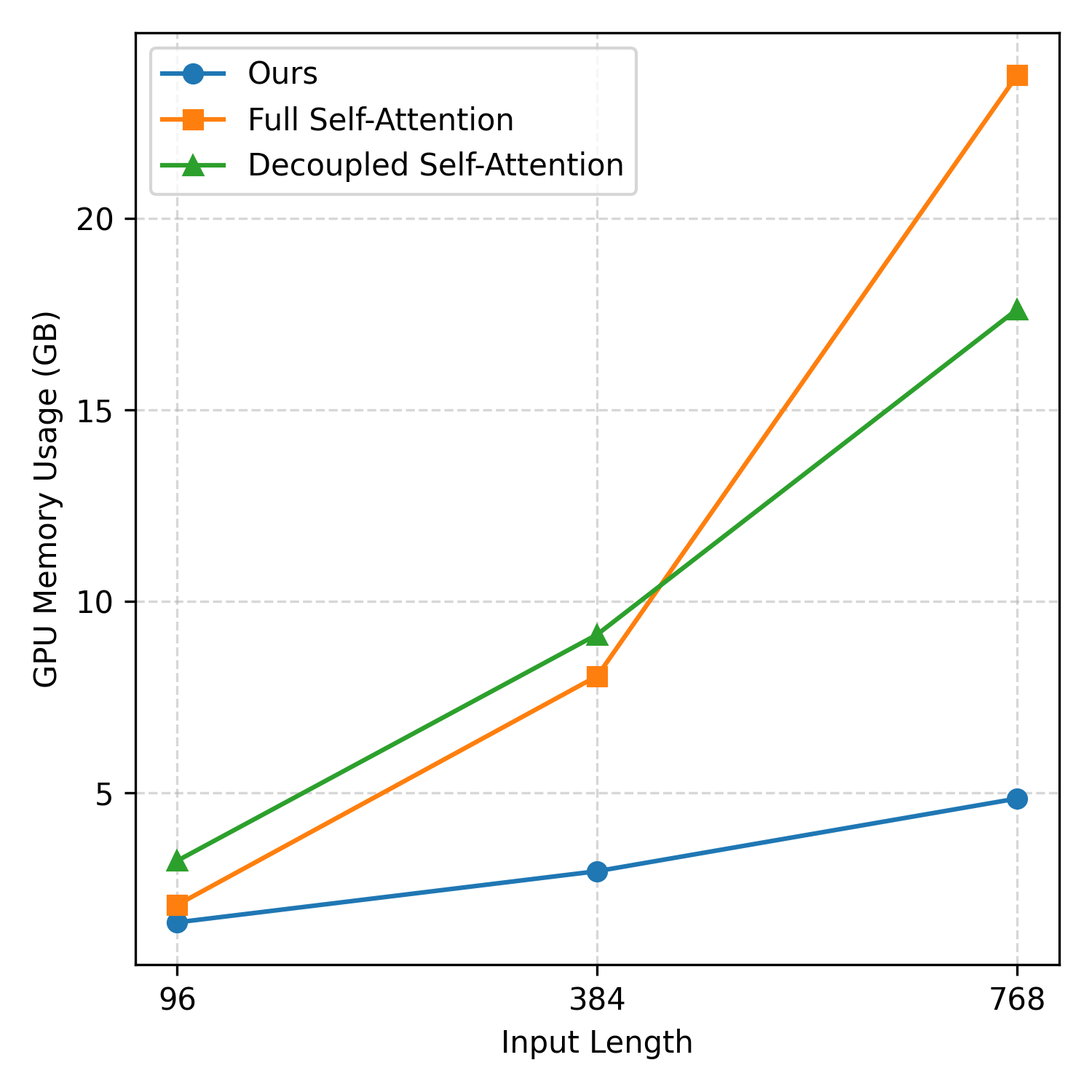
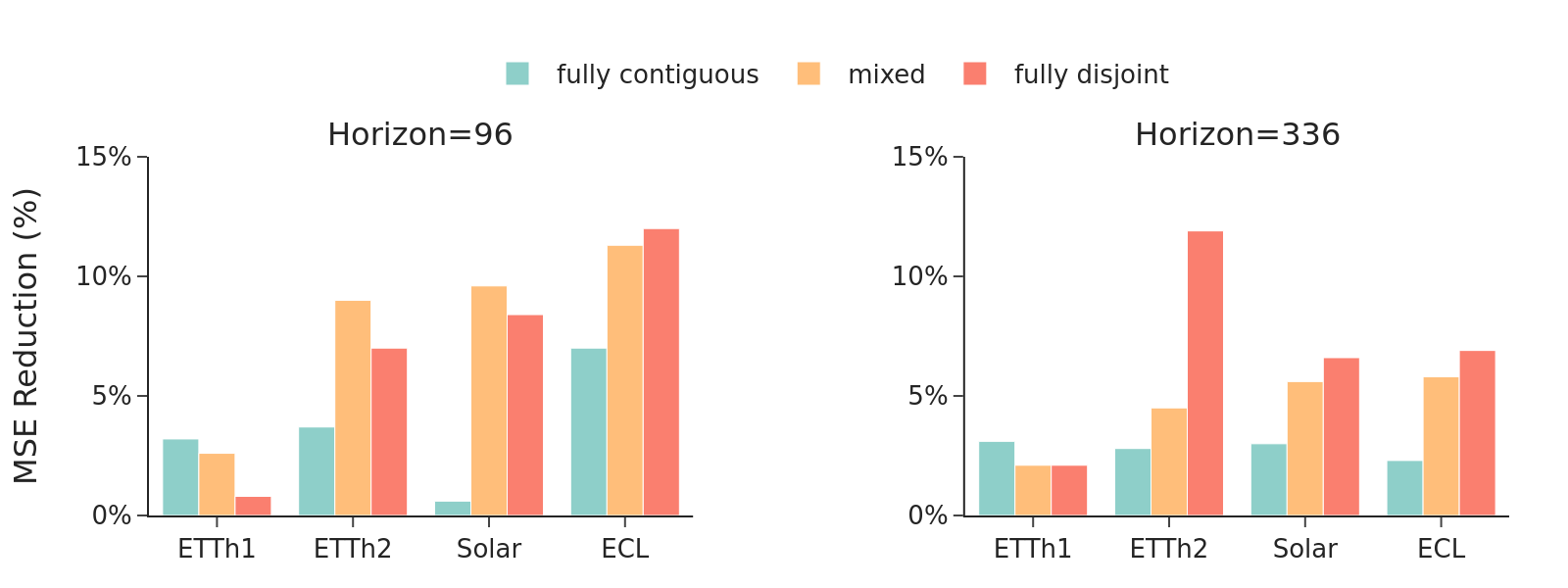
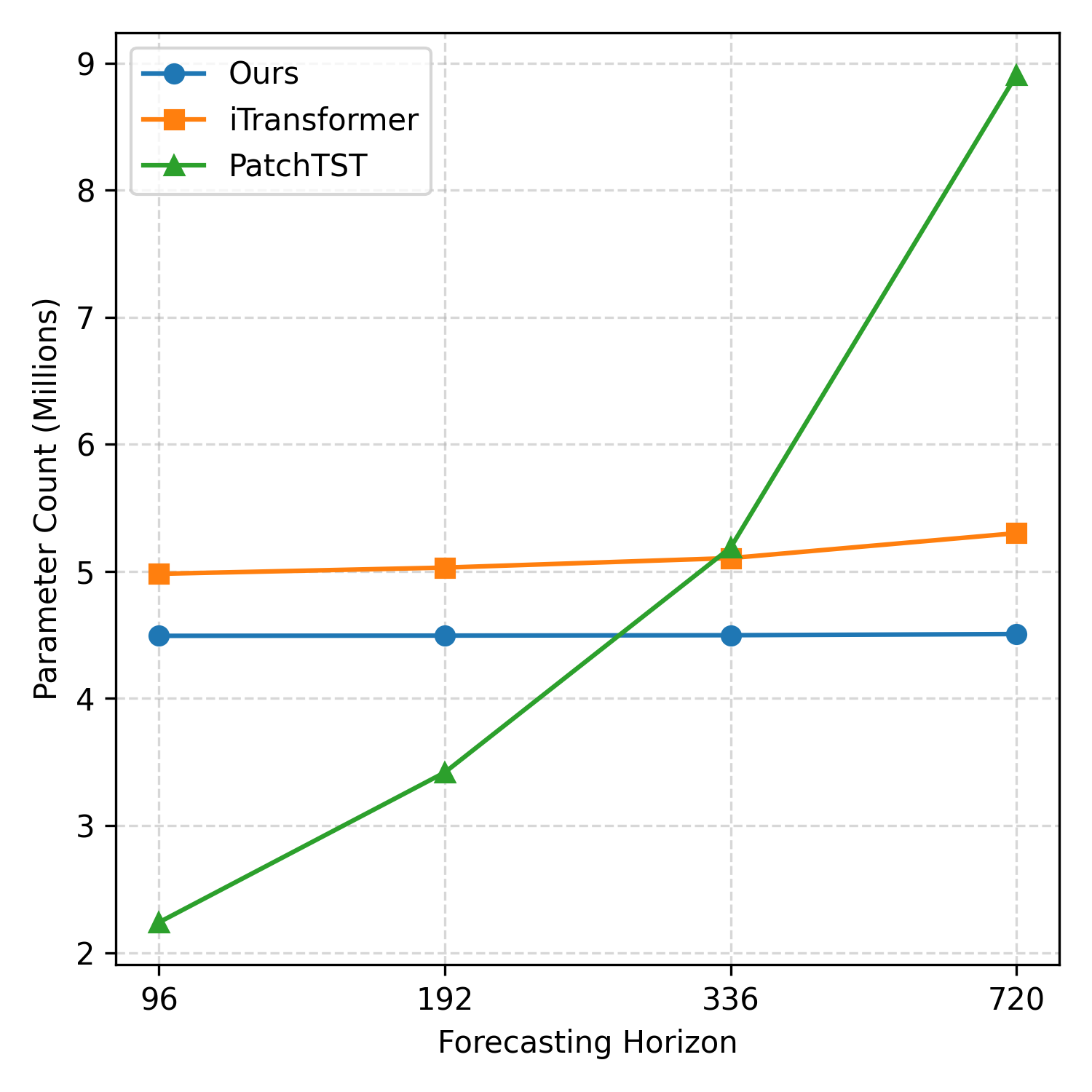
In machine learning, effective modeling requires a holistic consideration of how to encode inputs, make predictions (i.e., decoding), and train the model. However, in time-series forecasting, prior work has predominantly focused on encoder design, often treating prediction and training as separate or secondary concerns. In this paper, we propose TIMEPERCEIVER, a unified encoder-decoder forecasting framework that is tightly aligned with an effective training strategy. To be specific, we first generalize the forecasting task to include diverse temporal prediction objectives such as extrapolation, interpolation, and imputation. Since this generalization requires handling input and target segments that are arbitrarily positioned along the temporal axis, we design a novel encoder-decoder architecture that can flexibly perceive and adapt to these varying positions. For encoding, we introduce a set of latent bottleneck representations that can interact with all input segments to jointly capture temporal and cross-channel dependencies. For decoding, we leverage learnable queries corresponding to target timestamps to effectively retrieve relevant information. Extensive experiments demonstrate that our framework consistently and significantly outperforms prior state-of-the-art baselines across a wide range of benchmark datasets. The code is available at https://github.com/efficient-learning-lab/TimePerceiver.
💡 Deep Analysis
📄 Full Content
TIMEPERCEIVER: An Encoder-Decoder Framework
for Generalized Time-Series Forecasting
Jaebin Lee
Sungkyunkwan University
jaebin.lee@skku.edu
Hankook Lee
Sungkyunkwan University
hankook.lee@skku.edu
Abstract
In machine learning, effective modeling requires a holistic consideration of how
to encode inputs, make predictions (i.e., decoding), and train the model. How-
ever, in time-series forecasting, prior work has predominantly focused on encoder
design, often treating prediction and training as separate or secondary concerns.
In this paper, we propose TIMEPERCEIVER, a unified encoder-decoder forecast-
ing framework that is tightly aligned with an effective training strategy. To be
specific, we first generalize the forecasting task to include diverse temporal pre-
diction objectives such as extrapolation, interpolation, and imputation. Since this
generalization requires handling input and target segments that are arbitrarily po-
sitioned along the temporal axis, we design a novel encoder-decoder architecture
that can flexibly perceive and adapt to these varying positions. For encoding,
we introduce a set of latent bottleneck representations that can interact with all
input segments to jointly capture temporal and cross-channel dependencies. For
decoding, we leverage learnable queries corresponding to target timestamps to
effectively retrieve relevant information. Extensive experiments demonstrate that
our framework consistently and significantly outperforms prior state-of-the-art
baselines across a wide range of benchmark datasets. The code is available at
https://github.com/efficient-learning-lab/TimePerceiver.
1
Introduction
Time-series forecasting is a fundamental task in machine learning, aiming to predict future events
based on past observations. It is of practical importance, as it plays a crucial role in many real-world
applications, including weather forecasting [1], electricity consumption forecasting [2], and traffic
flow prediction [3]. Despite decades of rapid advances in machine learning, time-series forecasting
remains a challenging problem due to complex temporal dependencies, non-linear patterns, domain
variability, and other factors. In recent years, numerous deep learning approaches [4–18] have been
proposed to improve forecasting accuracy, and it continues to be an active area of research.
One promising and popular research direction is to design a new neural network architecture for
time-series data, such as Transformers [4–9], convolutional neural networks (CNNs) [11, 12], multi-
layer perceptrons (MLPs) [13–15], and state space models (SSMs) [17, 18]. These architectures
primarily focus on capturing temporal and channel (i.e., variate) dependencies within input signals,
and how to encode the input into a meaningful representation. The encoder architectures are often
categorized into two groups: channel-independent encoders, which treat each variate separately
and apply the same encoder across all variates, and channel-dependent encoders, which explicitly
model interactions among variates. The channel-independent encoders are considered simple yet
robust [19]; however, they fundamentally overlook cross-channel interactions, which can be critical
for multivariate time-series forecasting. In contrast, the channel-dependent encoders [5, 6, 8] can
inherently capture such cross-channel dependencies, but they often suffer from high computational
39th Conference on Neural Information Processing Systems (NeurIPS 2025).
arXiv:2512.22550v1 [cs.LG] 27 Dec 2025
fω
Xpast = [x1, x2, . . . , x6]
ˆXfuture = [ˆx7, ˆx8, . . . , ˆx10]
X = [x1, x2, . . . , x10]
Input
Target
(a) Standard formulation
gω
XI = [x2, x3, x4, x5, x7, x8]
ˆXJ = [ˆx1, ˆx6, ˆx9, ˆx10]
I = {2, 3, 4, 5, 7, 8}
J = {1, 6, 9, 10}
X = [x1, x2, . . . , x10]
Target
Input
(b) Generalized formulation (ours)
Figure 1: (a) The standard time-series forecasting task aims to predict only the future values from
past observations. In contrast, (b) our generalized task formulation aims to predict not only the future,
but also the past and missing values based on arbitrary contextual information.
cost and do not consistently yield significant improvements in forecasting accuracy over channel-
independent baselines.
While the encoder architecture is undoubtedly a core component of time-series forecasting models,
it is equally important to consider (i) how to accurately predict (i.e., decode) future signals from
the encoded representations of past signals, and (ii) how to effectively train the entire forecasting
model. However, they often been studied independently, and little attention has been paid to how
to effectively integrate them. For decoding, most prior works rely on a simple linear projection that
directly predicts the future from the encoded representations. This design offers advantages in terms
of simplicity and training efficiency, but may struggle to fully capture complex temporal structures.
For training, inspired by BERT [20], masking-and