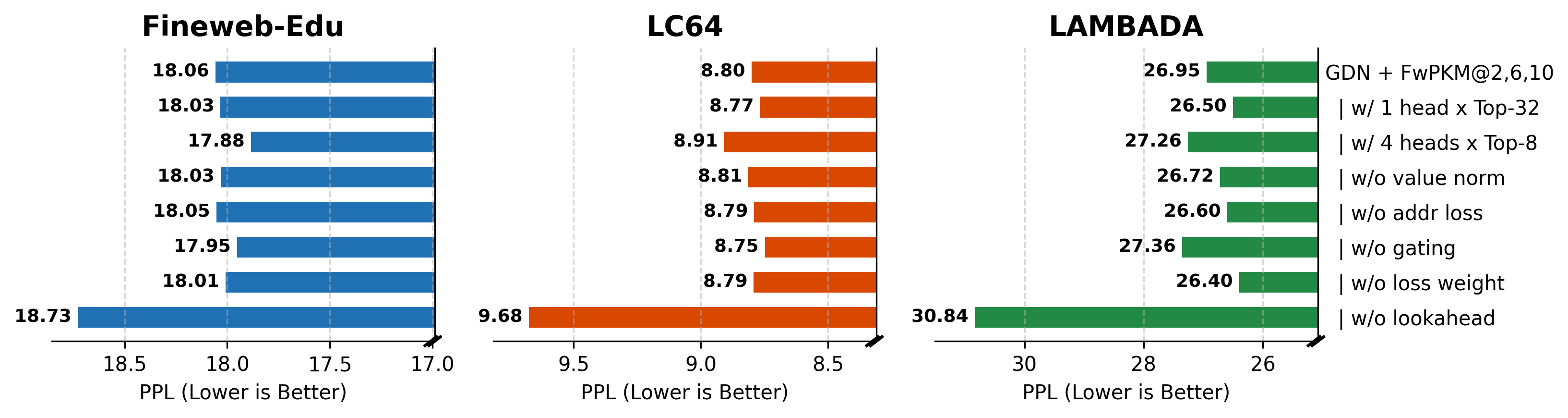
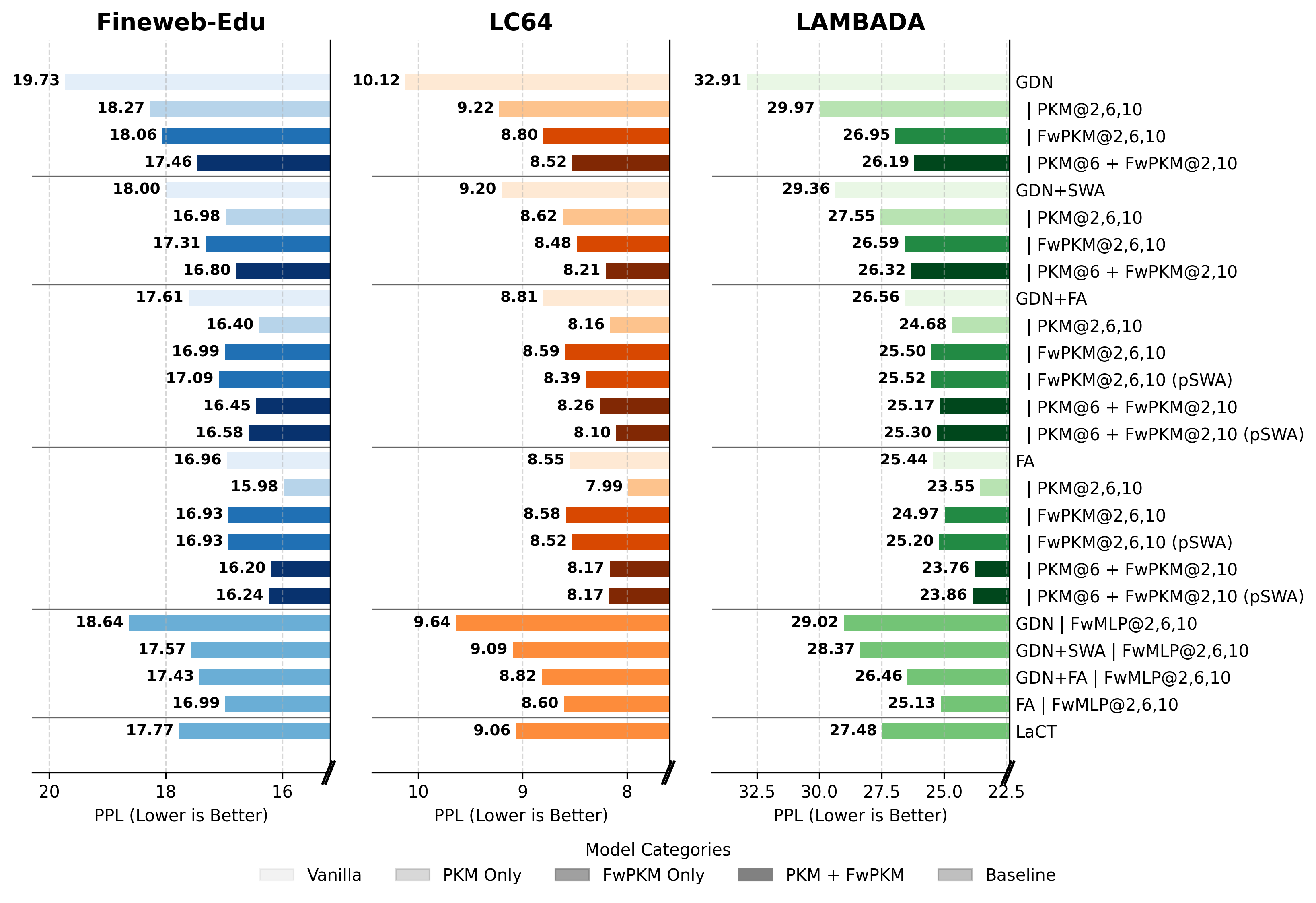
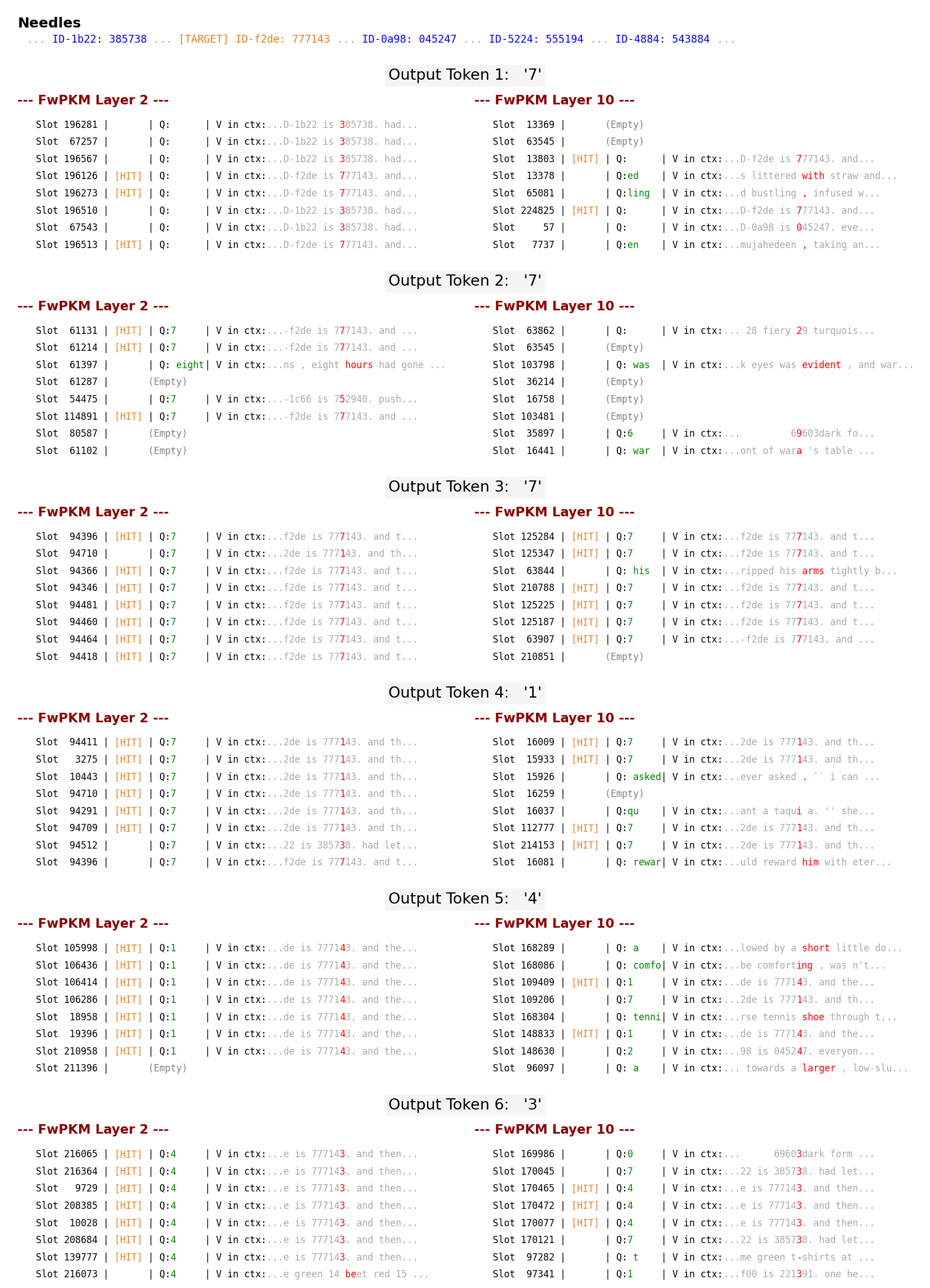
Sequence modeling layers in modern language models typically face a trade-off between storage capacity and computational efficiency. While Softmax attention offers unbounded storage at prohibitive quadratic costs, linear variants provide efficiency but suffer from limited, fixed-size storage. We propose Fast-weight Product Key Memory (FwPKM), a novel architecture that resolves this tension by transforming the sparse Product Key Memory (PKM) from a static module into a dynamic, "fast-weight" episodic memory. Unlike PKM, FwPKM updates its parameters dynamically at both training and inference time via local chunk-level gradient descent, allowing the model to rapidly memorize and retrieve new key-value pairs from input sequences. Experiments reveal that FwPKM functions as an effective episodic memory that complements the semantic memory of standard modules, yielding significant perplexity reductions on long-context datasets. Notably, in Needle in a Haystack evaluations, FwPKM generalizes to 128K-token contexts despite being trained on only 4K-token sequences.
💡 Deep Analysis
📄 Full Content
2026-1-1
Fast-weight Product Key Memory
Tianyu Zhao1 and Llion Jones1
1Sakana AI
Sequence modeling layers in modern language models typically face a trade-off between storage capacity
and computational efficiency. While Softmax attention offers unbounded storage at prohibitive quadratic
costs, linear variants provide efficiency but suffer from limited, fixed-size storage. We propose Fast-weight
Product Key Memory (FwPKM), a novel architecture that resolves this tension by transforming the sparse
Product Key Memory (PKM) from a static module into a dynamic, “fast-weight” episodic memory. Unlike PKM,
FwPKM updates its parameters dynamically at both training and inference time via local chunk-level gradient
descent, allowing the model to rapidly memorize and retrieve new key-value pairs from input sequences.
Experiments reveal that FwPKM functions as an effective episodic memory that complements the semantic
memory of standard modules, yielding significant perplexity reductions on long-context datasets. Notably, in
Needle in a Haystack evaluations, FwPKM generalizes to 128K-token contexts despite being trained on only
4K-token sequences.
Contents
1
Introduction
2
2
Product Key Memory
2
3
Fast-weight Product Key Memory
4
4
Experiments
9
5
Interpretability Analyses
11
6
Cost Analyses
15
7
Related Work
15
8
Conclusion
16
A
Detailed Training Settings
22
B
Ablation Study
23
C
More Visualization Examples
24
Corresponding author(s): Tianyu Zhao (tianyu@sakana.ai)
arXiv:2601.00671v1 [cs.CL] 2 Jan 2026
Fast-weight Product Key Memory
1. Introduction
Sequence modeling layers, or token mixers, are the foundational components in modern language
models. The most successful architectures today can be fundamentally understood as forms of
associative memory (Dao and Gu, 2024; Peng et al., 2025; Vaswani et al., 2017; Yang et al., 2024b,
2025), characterized by their ability to maintain key-value associations, execute retrieval, and perform
memorization (Gershman et al., 2025).
Within this framework, existing layers lie on a spectrum defined by the trade-off between storage
capacity and computational efficiency. Standard softmax attention (Vaswani et al., 2017) acts as
an associative memory with unbounded storage, yet its computational cost becomes increasingly
prohibitive as the sequence length grows (Zhong et al., 2025). Conversely, linear attention vari-
ants (Behrouz et al., 2025c; Dao and Gu, 2024; Gu and Dao, 2024; Katharopoulos et al., 2020; Schlag
et al., 2021b; Sun et al., 2025; Yang et al., 2025) provide efficient, sub-quadratic mechanisms but
rely on fixed storage capacities that often struggle to capture the same depth of information.
We focus our investigation on resolving this specific tension: balancing large-scale storage with
low computational overhead. We posit that an ideal associative memory should satisfy four key
properties:
1. Key-value Association: The ability to link keys to values.
2. Large Storage: Capacity that is extensive, if not unbounded.
3. Low Cost: Sub-quadratic computational complexity w.r.t. input length.
4. Retrieval and Memorization: The capability to retrieve information and, crucially, memorize
new key-value pairs from inputs at any time.
Product Key Memory (PKM, Lample et al. 2019) is an architecture that elegantly satisfies the first
three properties. Its sparse key-value design handles an enormous number of memory slots (e.g.,
𝑁= 106) with fixed and low computation. However, PKM was originally designed as a “slow-weight”
channel mixer – similar to Feed-Forward Networks (FFN) – meaning it is updated only during training
and remains frozen during inference. Consequently, it lacks the ability to rapidly adapt to new inputs
during deployment, failing property 4.
In this paper, we propose to convert PKM from a static, slow-weight module into Fast-weight Product
Key Memory (FwPKM). By redesigning PKM to update its parameters dynamically at both training
and inference time, we enable it to function as a high-fidelity episodic memory. FwPKMcan store
“episodes” directly from input sequences and carry that memory across different contexts, offering a
promising new path for continual learning and personalized AI agents.
2. Product Key Memory
Top-𝑘Key-value Memory
A standard key-value memory consists of a key matrix 𝐾∈R𝑁×𝐷𝐾and
a value matrix 𝑉∈R𝑁×𝐷𝑉, where 𝑁represents the number of memory slots and 𝐷{𝐾,𝑉} are the
hidden dimensions. A common approach to learning a large memory without sacrificing computation
efficiency is to exploit sparsity via a Top-𝑘operation (Rae et al., 2016; Weston et al., 2015). Given
an input query vector q, the model computes a score 𝑠𝑖for each memory slot as the inner product
between the query and the keys. A Top-𝑘operation T𝑘then selects the indices of the 𝑘slots with
the highest scores. The selected scores are normalized via softmax to produce weights {𝑠′
𝑖}, and the
2
Fast-weight Product Key Memory
Table 1 | Comparison of PKM and FwPKM
PKM
FwPKM
Weight Type
Slow Weig