Deep reinforcement learning (DRL) methods have demonstrated potential for autonomous navigation and obstacle avoidance of unmanned ground vehicles (UGVs) in crowded environments. Most existing approaches rely on single-frame observation and employ simple concatenation for multi-modal fusion, which limits their ability to capture temporal context and hinders dynamic adaptability. To address these challenges, we propose a DRL-based navigation framework, DRL-TH, which leverages temporal graph attention and hierarchical graph pooling to integrate historical observations and adaptively fuse multi-modal information. Specifically, we introduce a temporal-guided graph attention network (TG-GAT) that incorporates temporal weights into attention scores to capture correlations between consecutive frames, thereby enabling the implicit estimation of scene evolution. In addition, we design a graph hierarchical abstraction module (GHAM) that applies hierarchical pooling and learnable weighted fusion to dynamically integrate RGB and LiDAR features, achieving balanced representation across multiple scales. Extensive experiments demonstrate that our DRL-TH outperforms existing methods in various crowded environments. We also implemented DRL-TH control policy on a real UGV and showed that it performed well in realworld scenarios.
F OR crowded scenarios, effective navigation requires un- manned ground vehicles (UGVs) to exhibit efficient multi-modal perception and obstacle avoidance to ensure both safety and task completion. While classical navigation methods have been widely applied to UGV navigation [1]- [3], they requires maintaining an extensive "if-else" case repository, leading to limited scalability and insufficient fault tolerance. Consequently, recent studies have increasingly shifted toward learning-based approaches that leverage data-driven models to enhance UGV navigation in such settings.
There exist some works based on deep learning (DL) [4]- [6] and imitation learning (IL) [7]- [9] to address the limitations of classical methods in crowded environments. DL methods quintessentially focus on environmental perception tasks, such as object detection and semantic segmentation, and do not explicitly learn the navigation policy. Some studies [6], [10], [11] have attempted to train policy using offline annotations from real-world environments. Such policy annotations are not only time-consuming and laborious to generate, particularly at a large scale in highly dynamic environments, but also subject to a fixed, limited, and discrete set of action states. Similarly, IL methods depend on expert datasets to clone expert behavior, enabling UGVs to emulate demonstrated trajectories. This approach often fails to adequately evaluate the quality of navigation behavior, and the trained policy can not generalize beyond the scope of the expert data [12]. When the expert dataset is insufficient in size and diversity, IL methods are prone to overfitting and encounter difficulties in transferring from simulation to real-world scenarios (Sim2Real).
In contrast, deep reinforcement learning (DRL) learns optimal navigation policies by maximizing expected returns through extensive interactions with the environment. Prior work [13]- [16] maps raw sensor inputs to navigation commands, enabling UGVs to adapt to dynamic conditions. However, extracting useful latent features from high-dimensional raw data places a significant learning burden on policy models, often requiring larger and more complex networks. Other studies [17]- [20] preprocess sensor data using perception networks to generate intermediate-level feature maps, thereby reducing complexity and enhancing the feasibility for Sim2Real transfer. Although these maps are easier to process, modality fusion is commonly performed through concatenation and lacks dynamic adaptability. Recently, Transformer-based methods [15], [21], [22] offer higher representation capacity, and they are sensitive to geometric or semantic misalignments between modalities, which may lead to feature shifts and make UGV decisions unstable. In addition, effective obstacle avoidance requires the navigation policy to understand the actual context of the scene in crowded environments. Most current works focus on instance-level prediction [4], [23], [24], such as trajectory forecasting or diffusion model inference. While these methods can achieve high accuracy, they are computationally intensive and thus unsuitable for deployment on UGV platforms with limited computing resources.
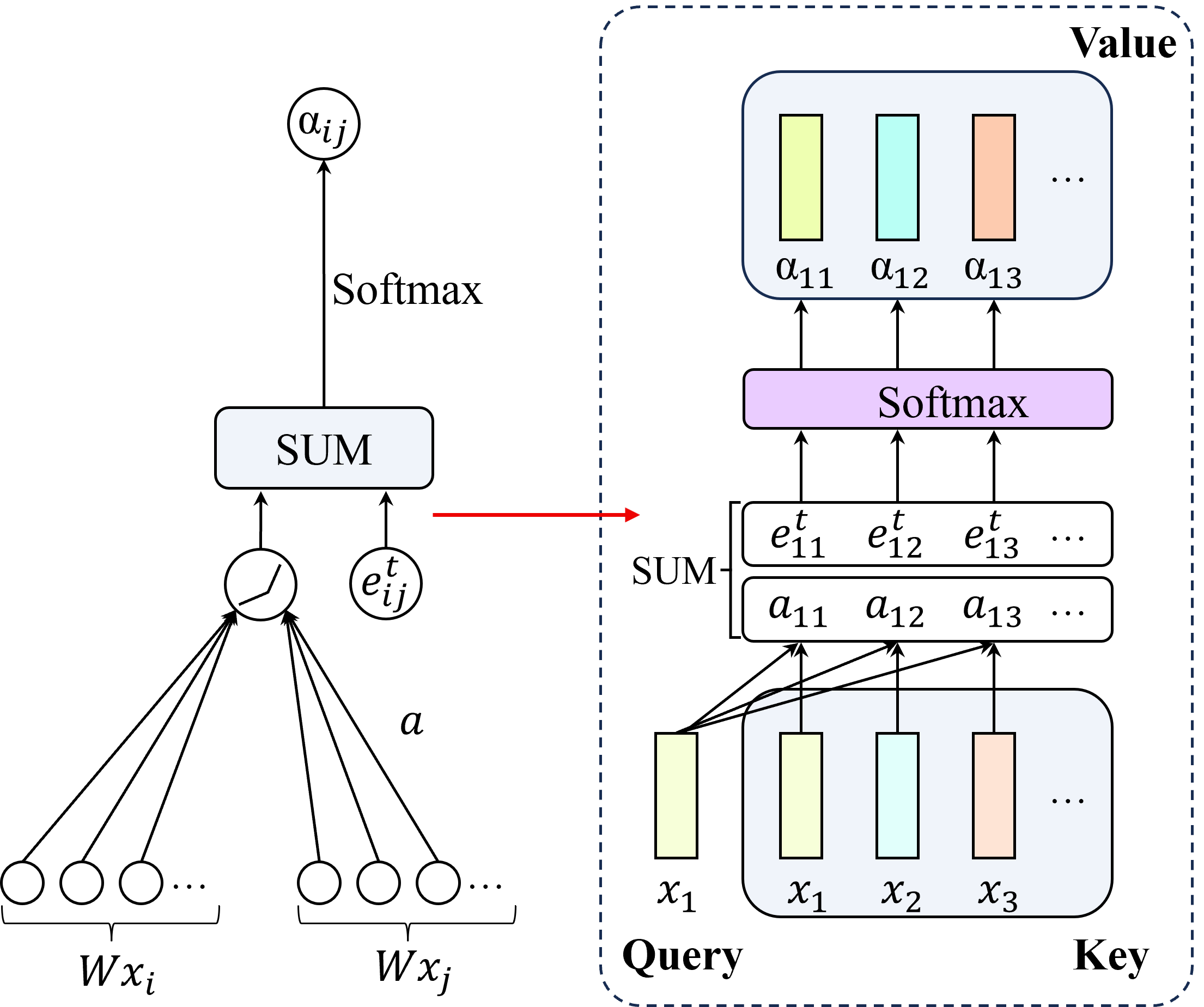
To address the aforementioned challenges, this paper incorporates graph neural networks (GNNs) for dynamic integration of multi-modal features and implicit context reasoning, serving as an alternative to instance-level prediction and enabling deployment in real-world environments. In particular, we propose DRL-TH, a deep reinforcement learning framework that integrates GNNs for UGV navigation in crowded environments. DRL-TH initially processes raw LiDAR and RGB data through feature extraction networks, representing them as delineations of traversable and non-traversable areas in bird’s-eye view (BEV) and first-person view (FPV). These features are then sequentially weighted and fused by the temporal-guided graph attention network (TG-GAT) and graph hierarchical abstraction module (GHAM), ultimately feeding into a proximal policy optimization (PPO) [25] network to output navigation commands.
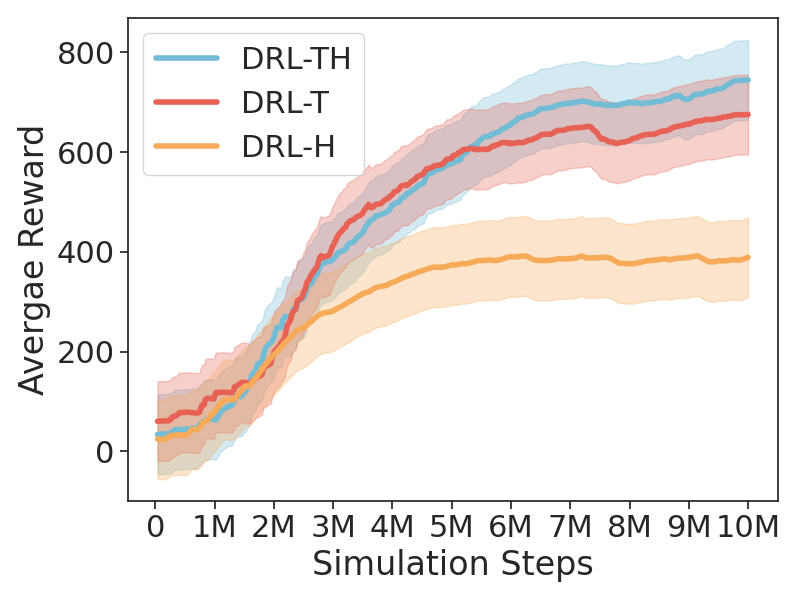
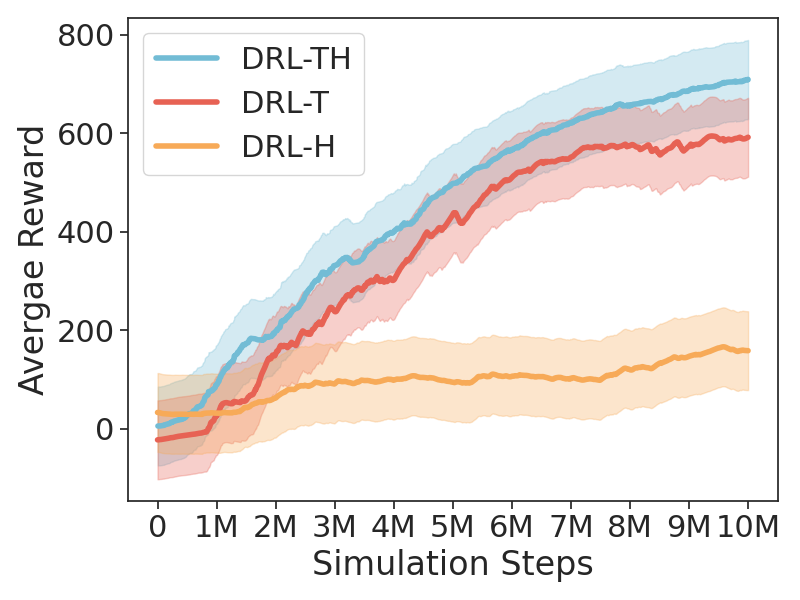
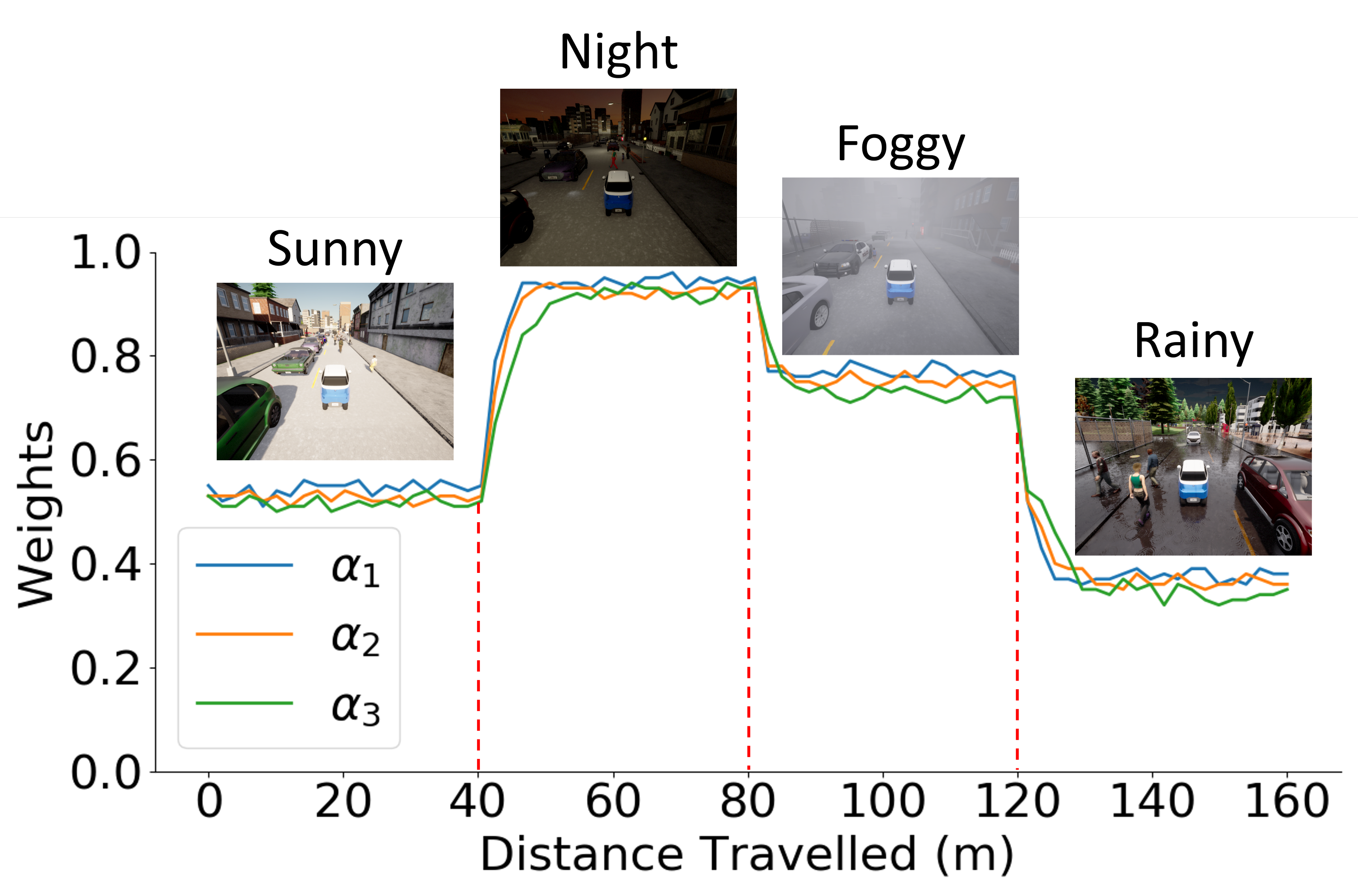
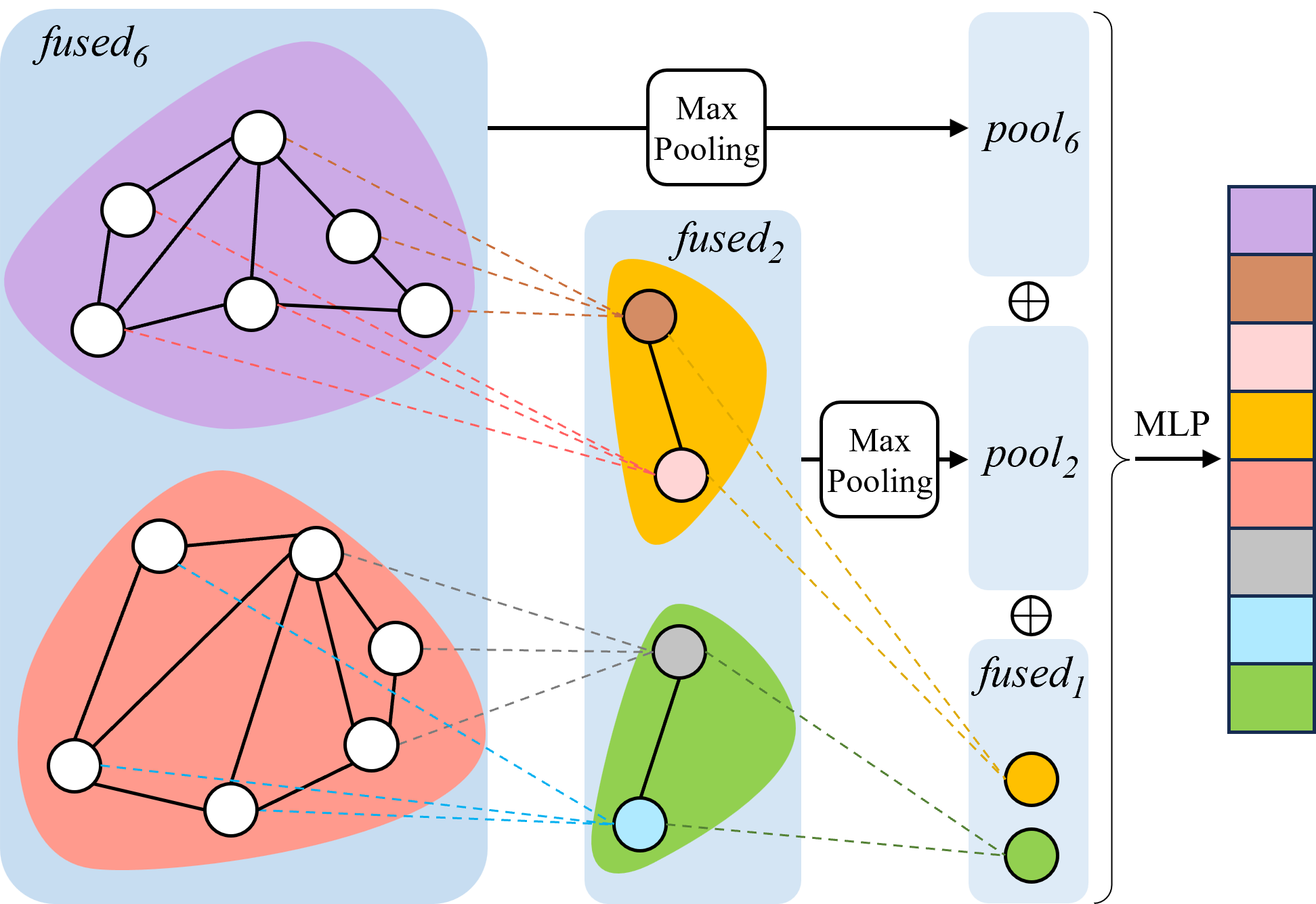
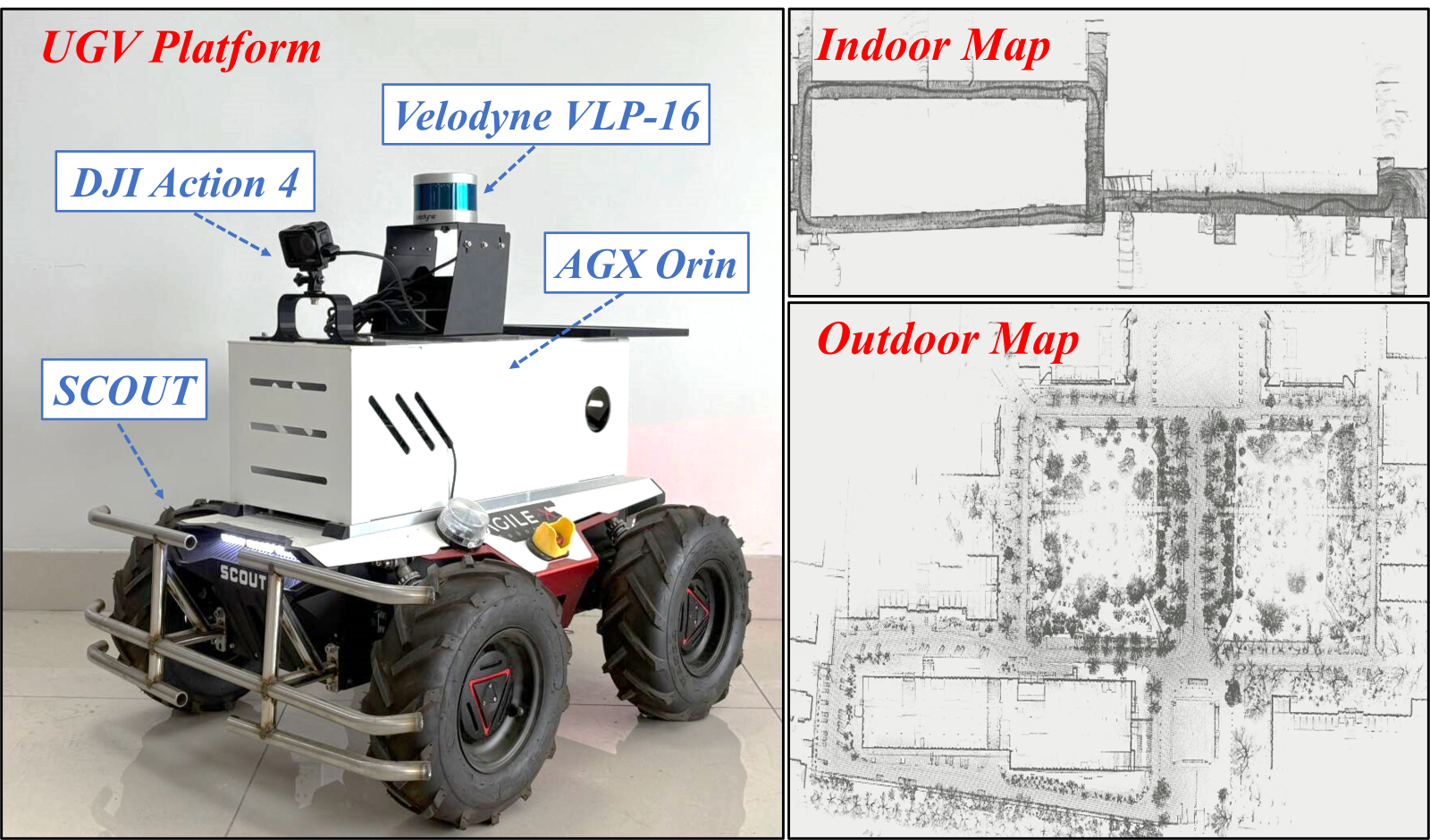
Specifically, we first represent a frame sequence as a graph, where nodes correspond to frames and edges capture temporal relationships. TG-GAT incorporates temporal weights into attention scores to model these relationships, enabling the UGV to effectively capture of scene evolution. GHAM then utilizes hierarchical pooling and learnable weighted fusion to dynamically integrate RGB and LiDAR features. GHAM employs learnable weights to balance modality features across multiple scales, ensuring adaptive fusion optimized for environmental complexity. We conducted extensive experiments in both simulated and real-world environments. The results demonstrate that DRL-TH achieves superior navigation performance in crowded scenarios with various obstacle densities, effectively avoiding both static and dynamic obstacles.
In summary, the contributions of this work are
This content is AI-processed based on open access ArXiv data.