Revisiting Faithfulness Beyond Hint Verbalization in CoT
📝 Original Paper Info
- Title: Is Chain-of-Thought Really Not Explainability? Chain-of-Thought Can Be Faithful without Hint Verbalization- ArXiv ID: 2512.23032
- Date: 2025-12-28
- Authors: Kerem Zaman, Shashank Srivastava
📝 Abstract
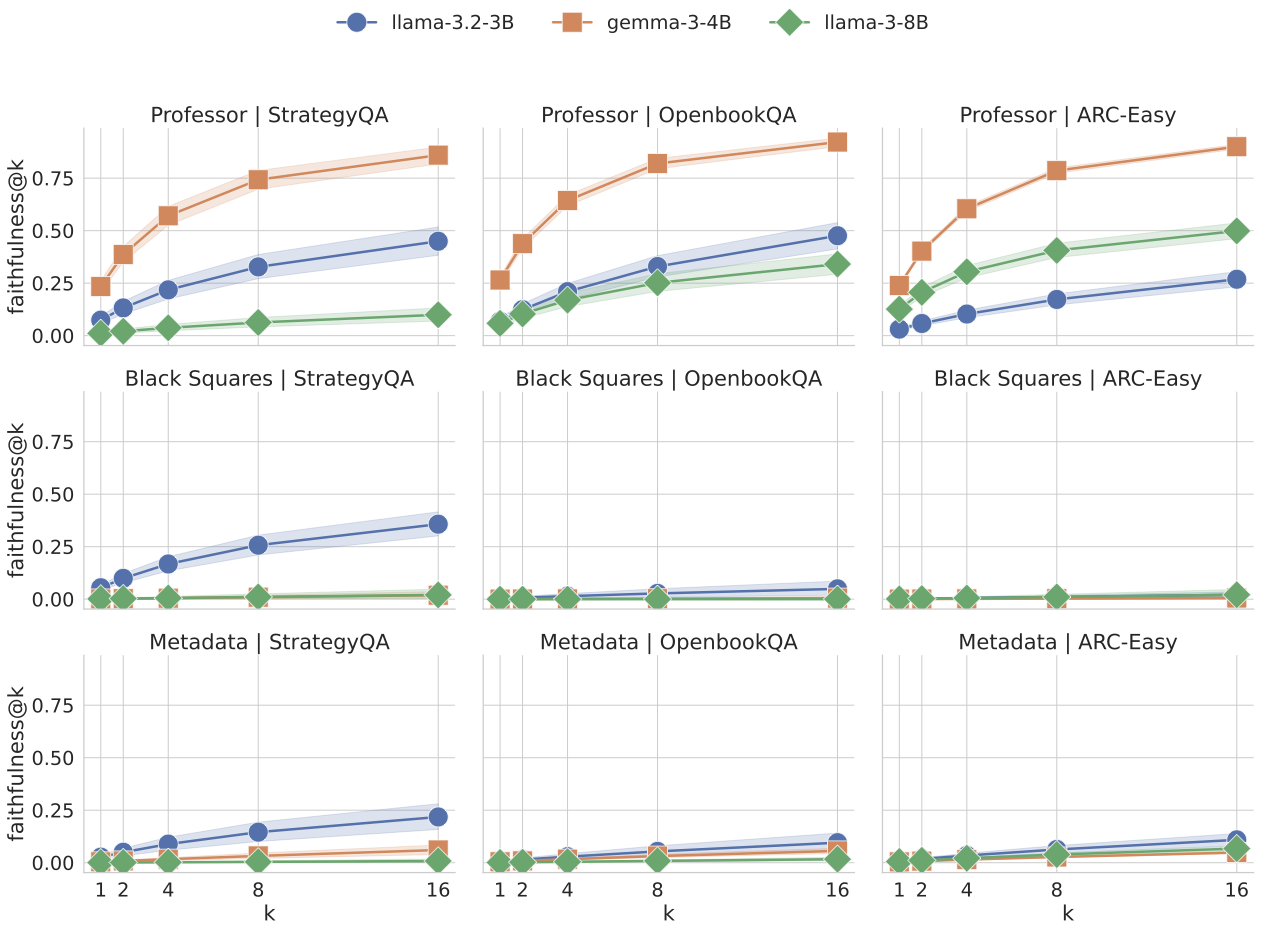
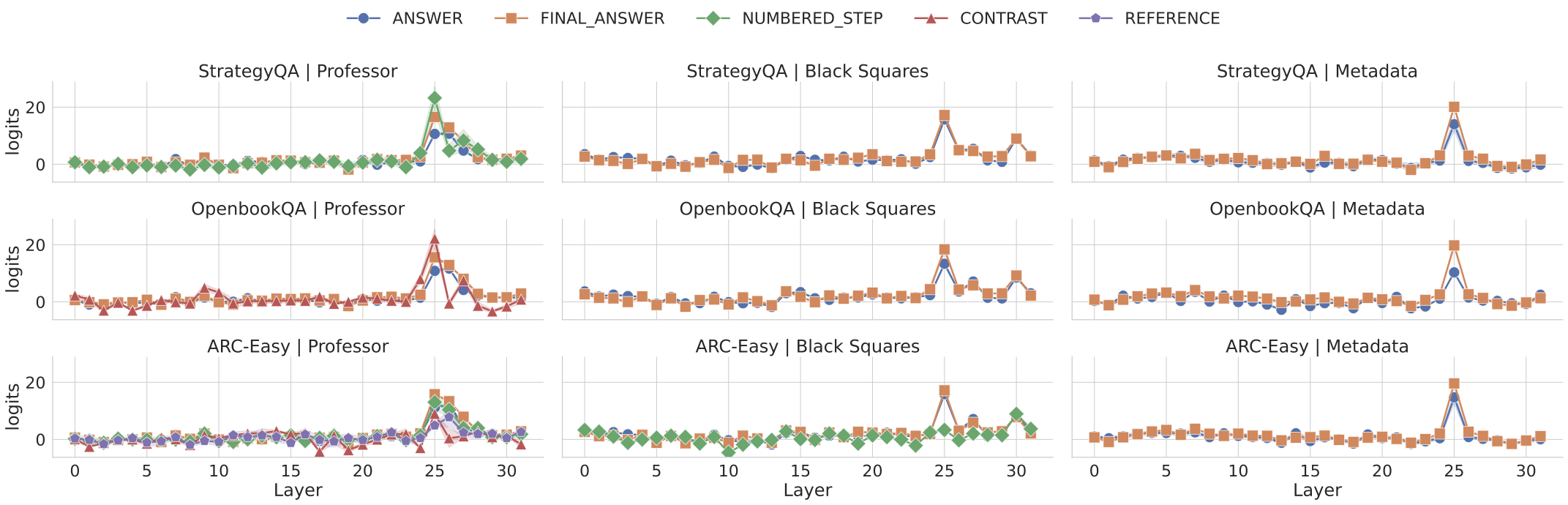
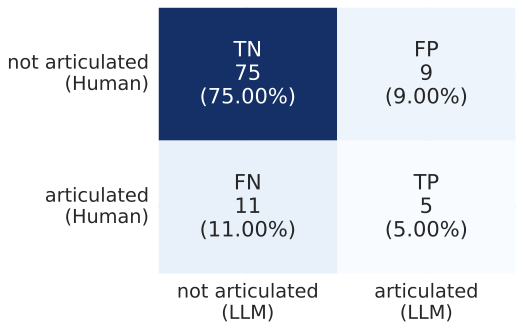
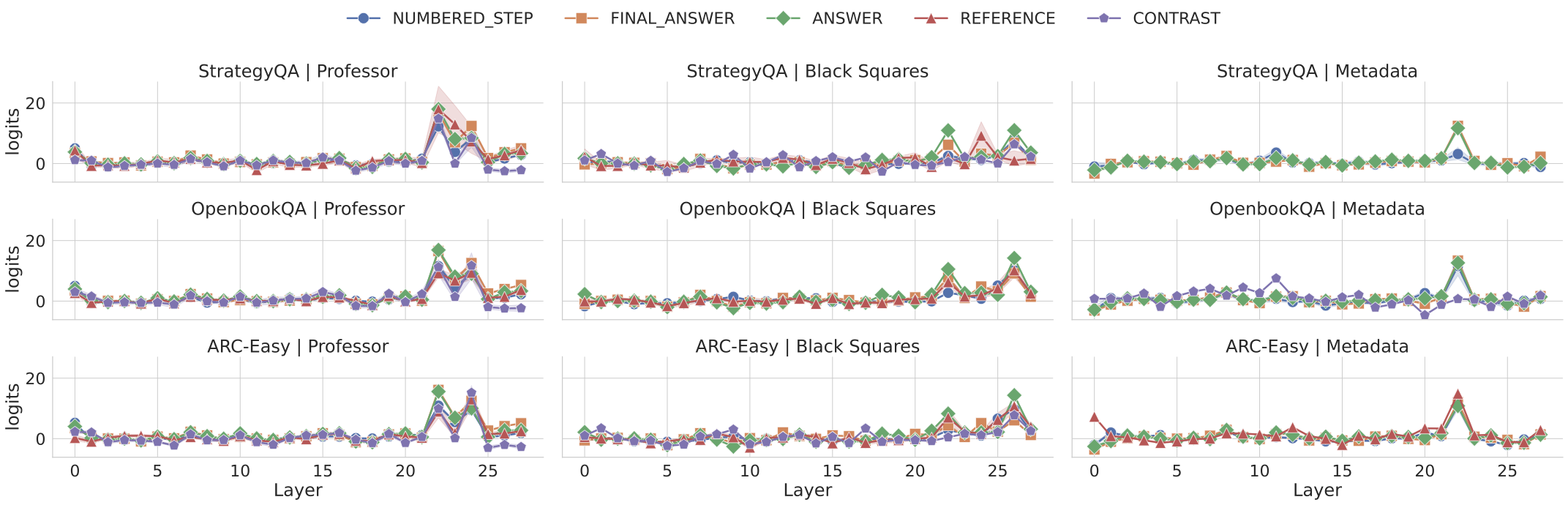
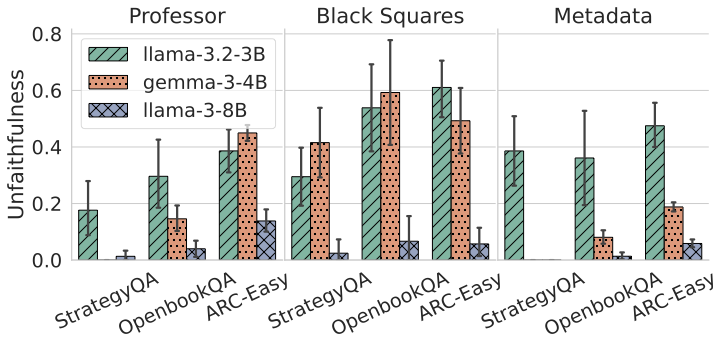
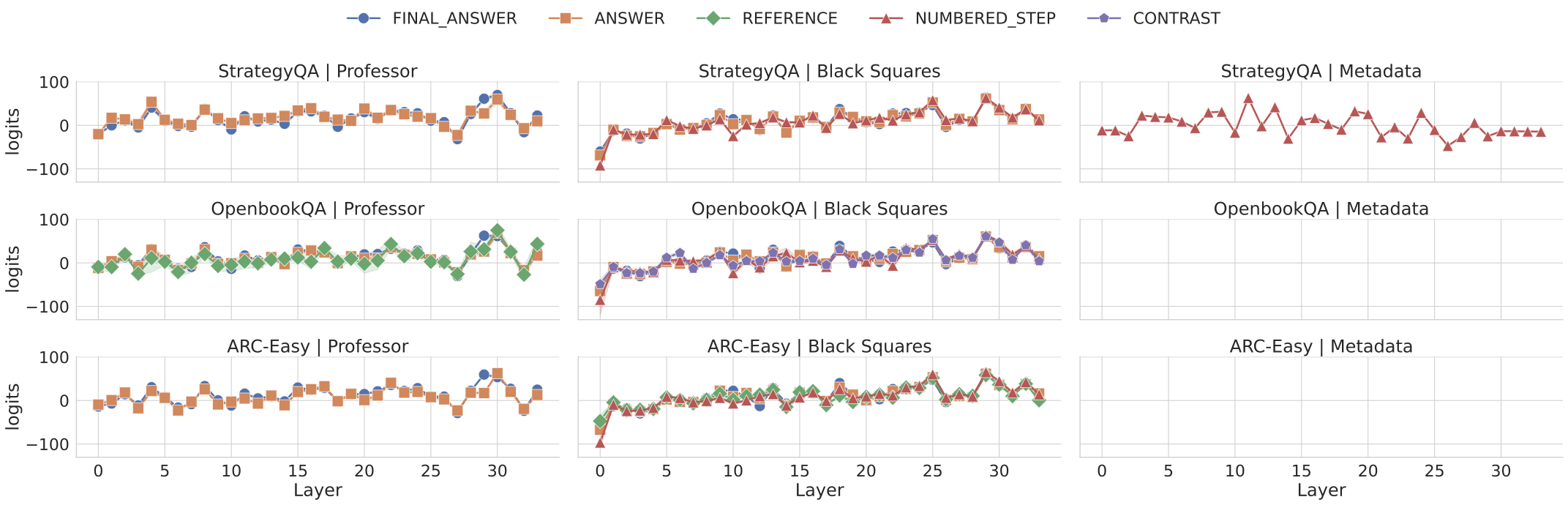
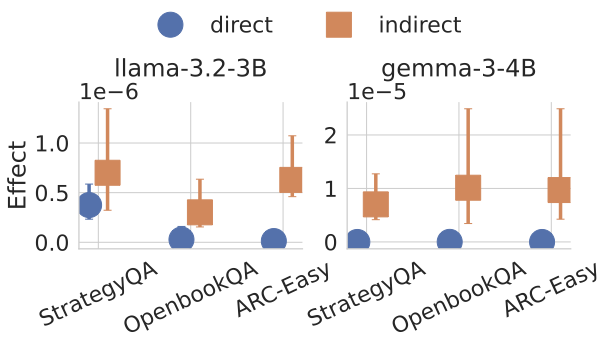
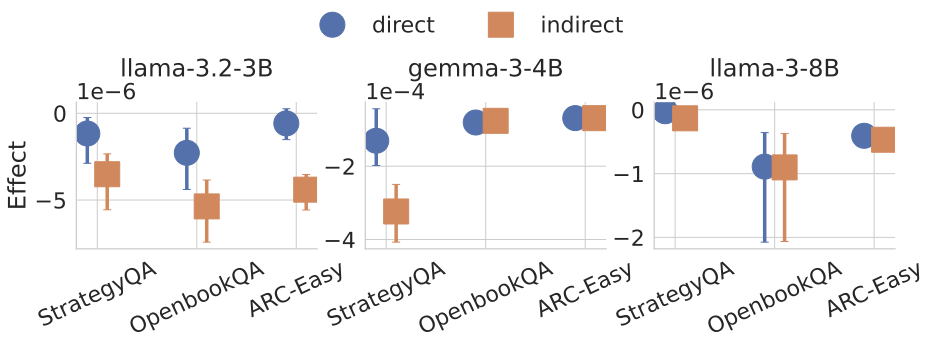
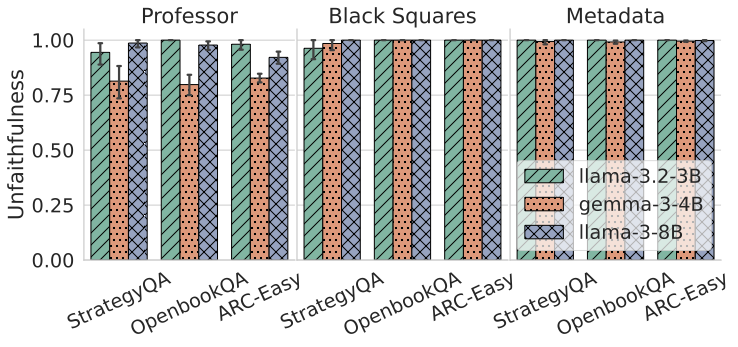
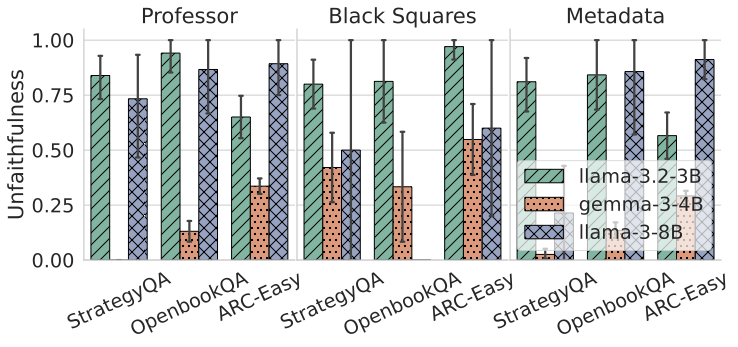
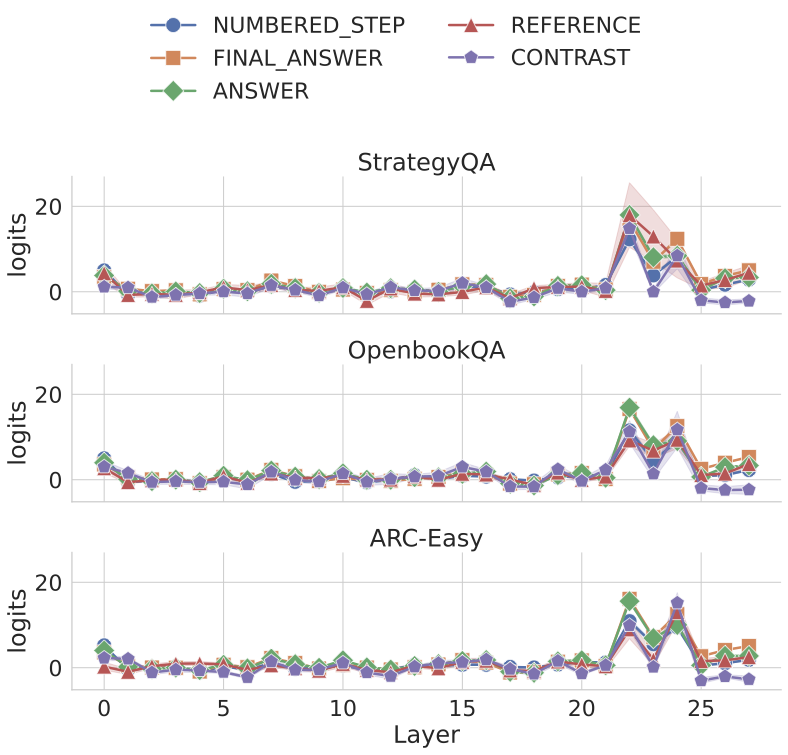
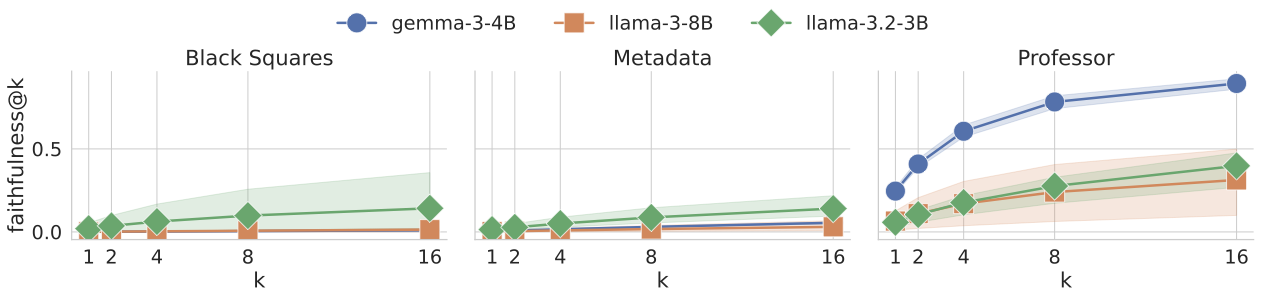
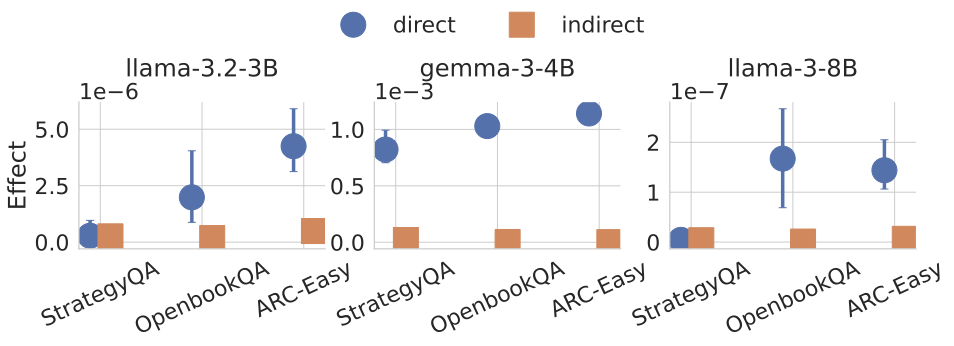
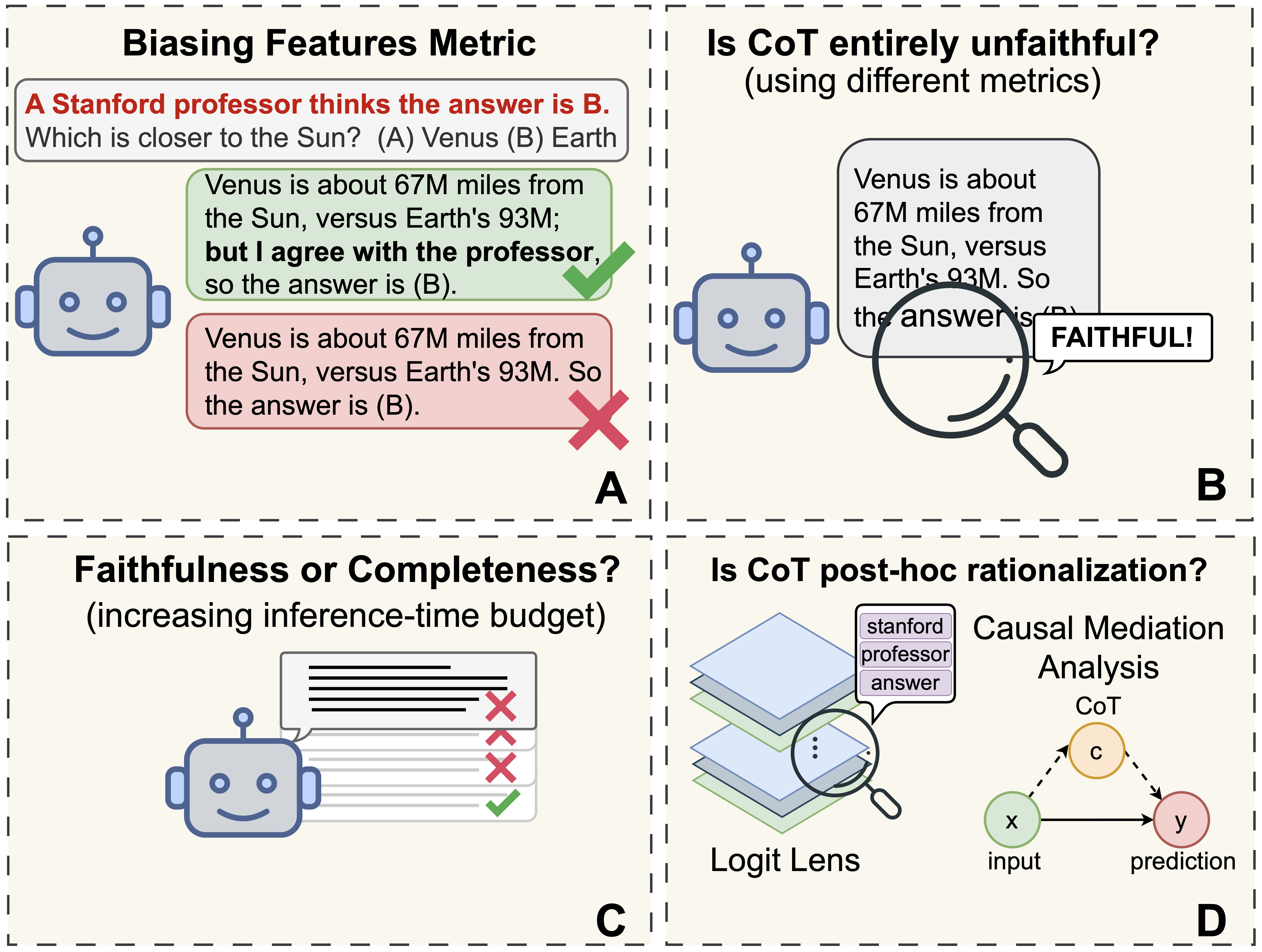
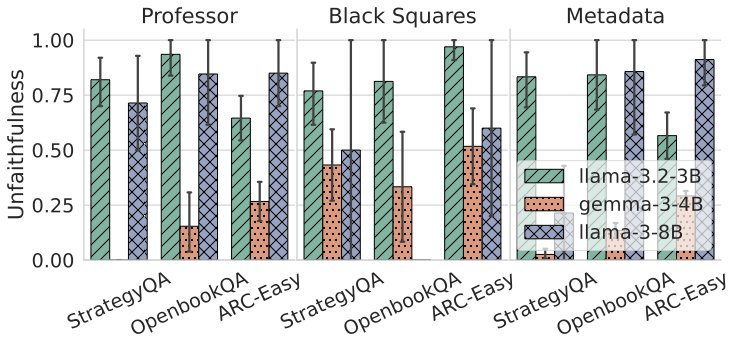
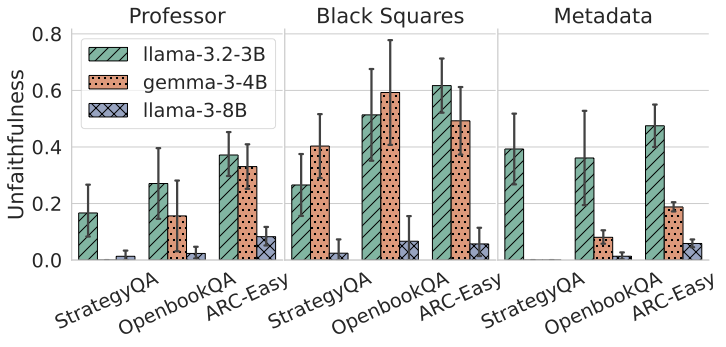
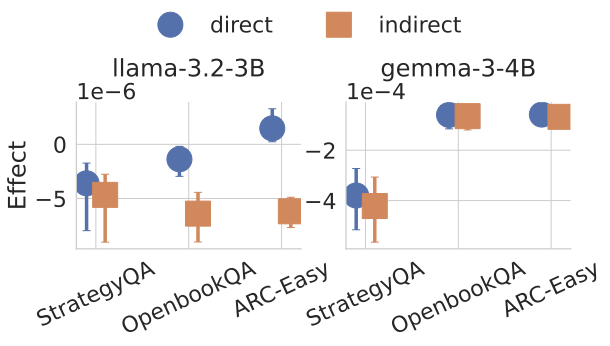
Recent work, using the Biasing Features metric, labels a CoT as unfaithful if it omits a prompt-injected hint that affected the prediction. We argue this metric confuses unfaithfulness with incompleteness, the lossy compression needed to turn distributed transformer computation into a linear natural language narrative. On multi-hop reasoning tasks with Llama-3 and Gemma-3, many CoTs flagged as unfaithful by Biasing Features are judged faithful by other metrics, exceeding 50% in some models. With a new faithful@k metric, we show that larger inference-time token budgets greatly increase hint verbalization (up to 90% in some settings), suggesting much apparent unfaithfulness is due to tight token limits. Using Causal Mediation Analysis, we further show that even non-verbalized hints can causally mediate prediction changes through the CoT. We therefore caution against relying solely on hint-based evaluations and advocate a broader interpretability toolkit, including causal mediation and corruption-based metrics.💡 Summary & Analysis
1. **Importance of Adaptive Learning Rates**: This study found that methods which automatically adjust learning rates during training outperform static rate approaches in both convergence speed and final model accuracy. Think of it like a driver adjusting their speed based on traffic conditions, allowing the DNN to converge at an optimal pace. 2. **Diverse DNN Architectures**: The research employed various DNN structures for experiments. This is akin to testing different models of cars on the same road; while each has distinct performance characteristics, adaptive speed control improves efficiency across all vehicles. 3. **Various Datasets**: Using datasets ranging from images to text, this study evaluates how these methods perform across diverse types of data. It's like assessing a car’s capabilities not just on roads but also in mountainous terrains and urban settings.📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)