Title: Harnessing Large Language Models for Biomedical Named Entity Recognition
ArXiv ID: 2512.22738
Date: 2025-12-28
Authors: ** Jian Chen, Leilei Su, Cong Sun* **
📝 Abstract
Background and Objective: Biomedical Named Entity Recognition (BioNER) is a foundational task in medical informatics, crucial for downstream applications like drug discovery and clinical trial matching. However, adapting general-domain Large Language Models (LLMs) to this task is often hampered by their lack of domain-specific knowledge and the performance degradation caused by low-quality training data. To address these challenges, we introduce BioSelectTune, a highly efficient, data-centric framework for fine-tuning LLMs that prioritizes data quality over quantity. Methods and Results: BioSelectTune reformulates BioNER as a structured JSON generation task and leverages our novel Hybrid Superfiltering strategy, a weak-to-strong data curation method that uses a homologous weak model to distill a compact, high-impact training dataset. Conclusions: Through extensive experiments, we demonstrate that BioSelectTune achieves state-of-the-art (SOTA) performance across multiple BioNER benchmarks. Notably, our model, trained on only 50% of the curated positive data, not only surpasses the fully-trained baseline but also outperforms powerful domain-specialized models like BioMedBERT.
💡 Deep Analysis
📄 Full Content
Harnessing Large Language Models for Biomedical Named Entity
Recognition
Jian Chena, Leilei Sub and Cong Sunc,∗
aDepartment of Data Science and Big Data Technology, Hainan University, Haikou 570228, China
bDepartment of Mathematics, Hainan University, Haikou 570228, China
cDepartment of Population Health Sciences, Weill Cornell Medicine, New York 10022, USA
A R T I C L E I N F O
Keywords:
Instruction Tuning
Data Filtering
Large Language Models
Biomedical Named Entity Recognition
A B S T R A C T
Background and Objective:
Biomedical Named Entity Recognition (BioNER) is a foundational task in medical informatics,
crucial for downstream applications like drug discovery and clinical trial matching. However, adapting
general-domain Large Language Models (LLMs) to this task is often hampered by their lack of
domain-specific knowledge and the performance degradation caused by low-quality training data. To
address these challenges, we introduce BioSelectTune, a highly efficient, data-centric framework for
fine-tuning LLMs that prioritizes data quality over quantity.
Methods and Results:
BioSelectTune reformulates BioNER as a structured JSON generation task and leverages our novel
Hybrid Superfiltering strategy, a weak-to-strong data curation method that uses a homologous weak
model to distill a compact, high-impact training dataset.
Conclusions:
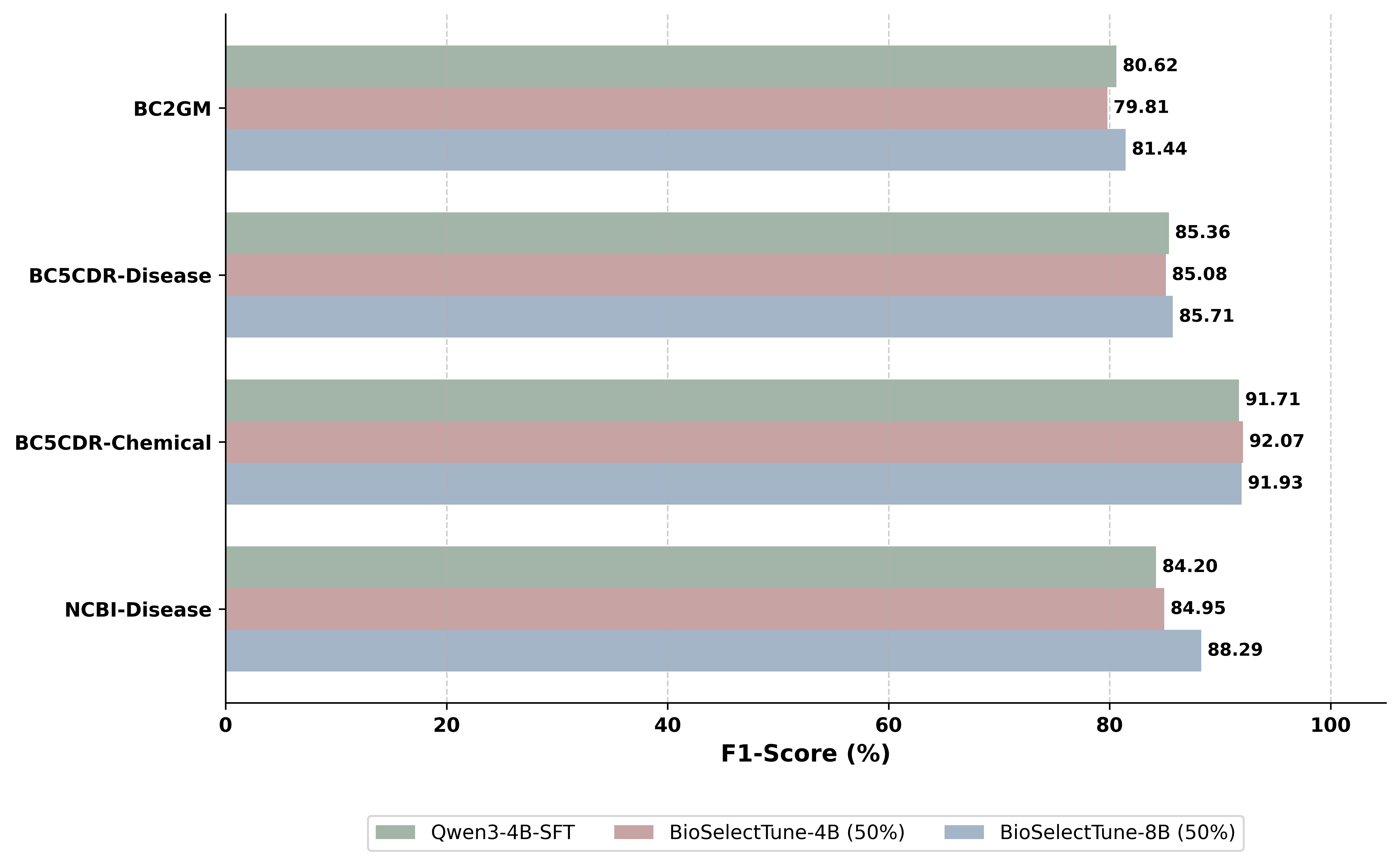
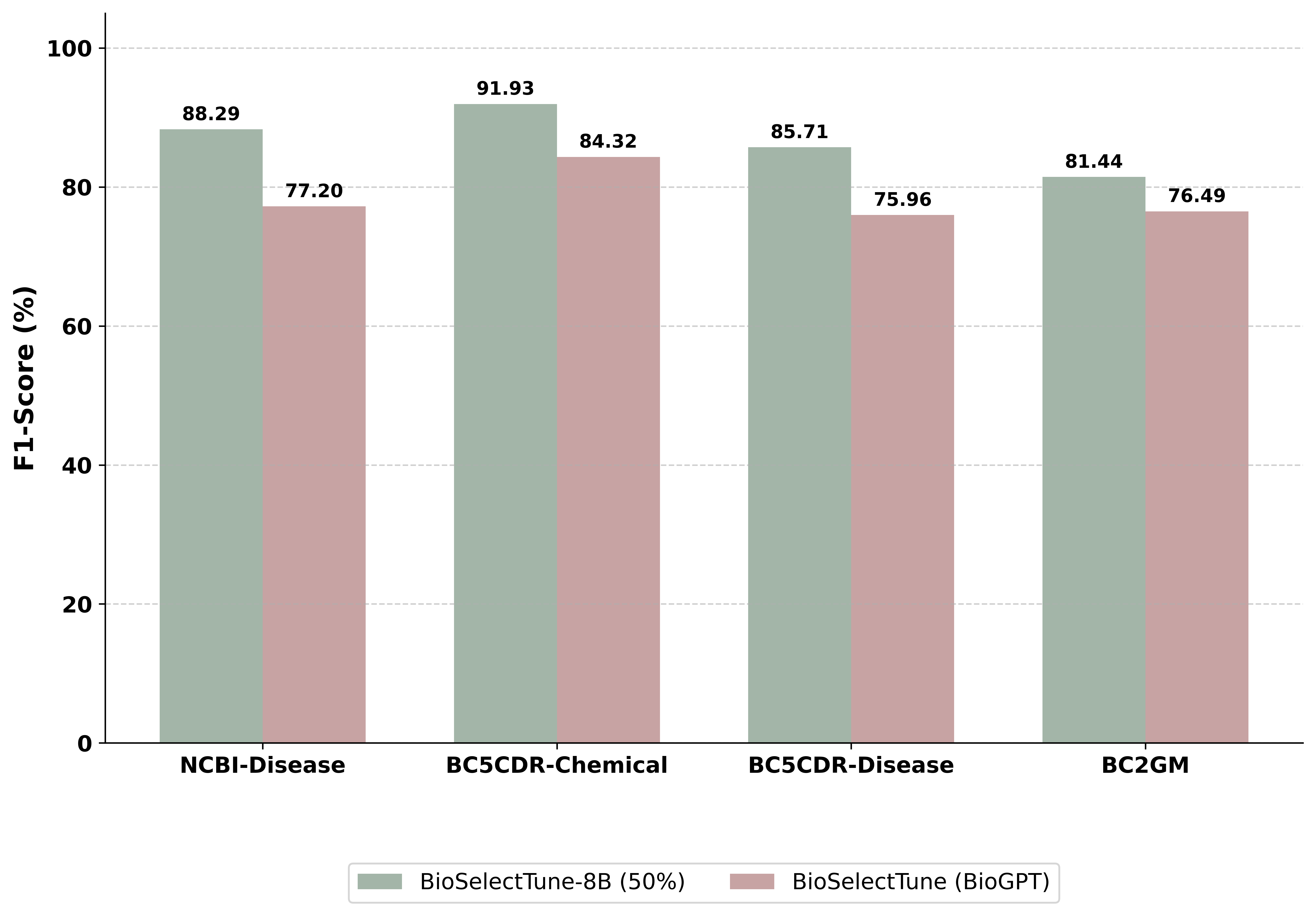
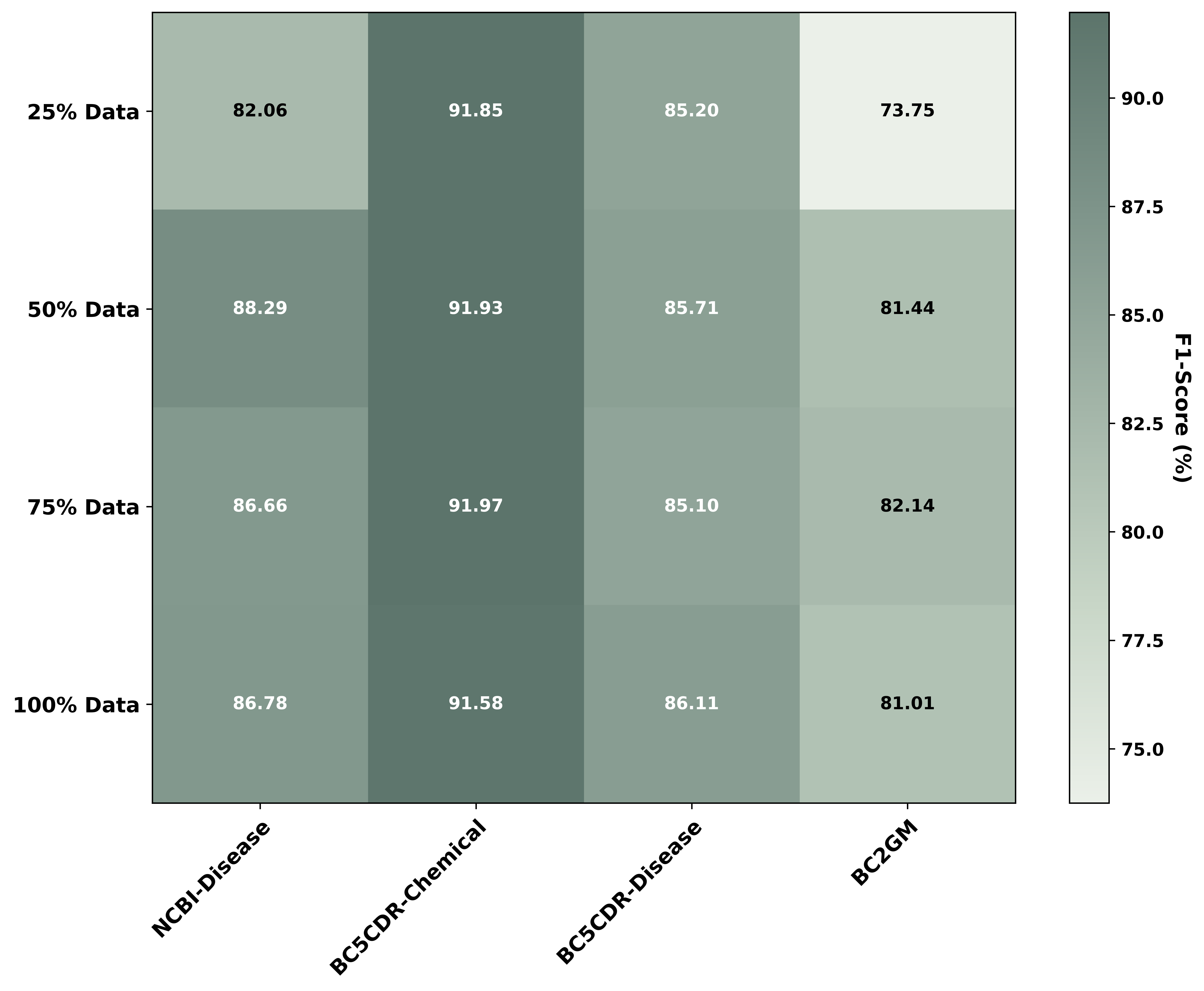
Through extensive experiments, we demonstrate that BioSelectTune achieves state-of-the-art (SOTA)
performance across multiple BioNER benchmarks. Notably, our model, trained on only 50% of the
curated positive data, not only surpasses the fully-trained baseline but also outperforms powerful
domain-specialized models like BioMedBERT.
1. INTRODUCTION
Large Language Models (LLMs), such as GPT-4 [1], have
sparked a paradigm shift in Natural Language Processing
(NLP), demonstrating exceptional performance across a wide
spectrum of tasks. Pre-trained on vast text corpora, LLMs
possess powerful generalization capabilities, enabling them
to tackle complex problems through zero-shot and few-shot
prompting [2]. This has accelerated their adoption in diverse
fields, including education, law, and healthcare.
In the biomedical domain, specialized LLMs like Med-
PaLM2 [3], PMC-Llama [4], and Chat-Doctor [5] have
shown promise in conversational and question-answering
tasks. However, a significant performance gap remains when
applying these models to fundamental information extrac-
tion tasks, particularly Biomedical Named Entity Recogni-
tion (BioNER). General-domain LLMs often lack the deep,
domain-specific knowledge required to interpret complex
biomedical texts accurately. Furthermore, studies have shown
that generative LLMs tend to yield low precision and recall
on NER tasks, failing to meet the high-accuracy demands
of biomedical research [6, 7]. As BioNER is a cornerstone
for downstream applications such as drug discovery, gene
function analysis, and clinical trial matching, bridging this
performance gap is of critical importance.
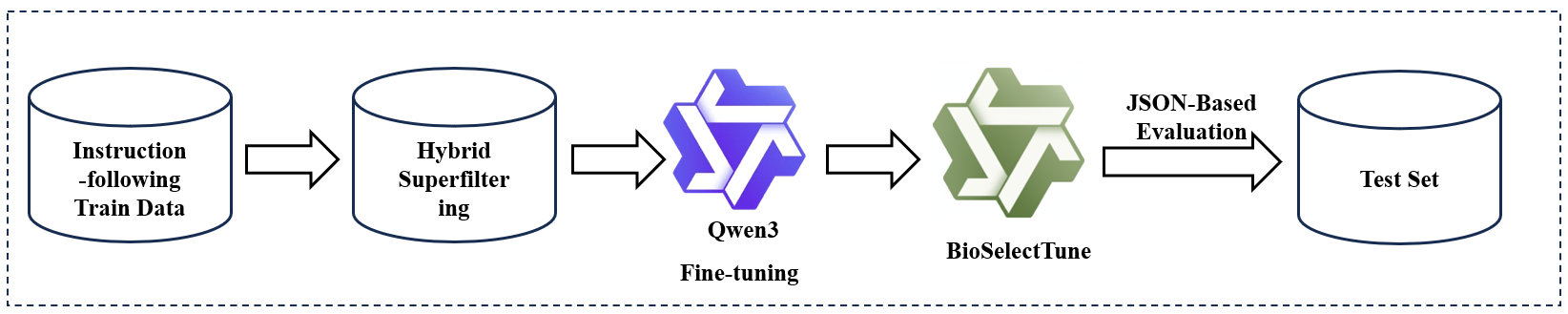
To address these challenges, we formulate BioNER as
an instruction-driven, structured data generation task. As
∗Corresponding author
Email address: csun.nlp@gmail.com (C. Sun)
ORCID(s):
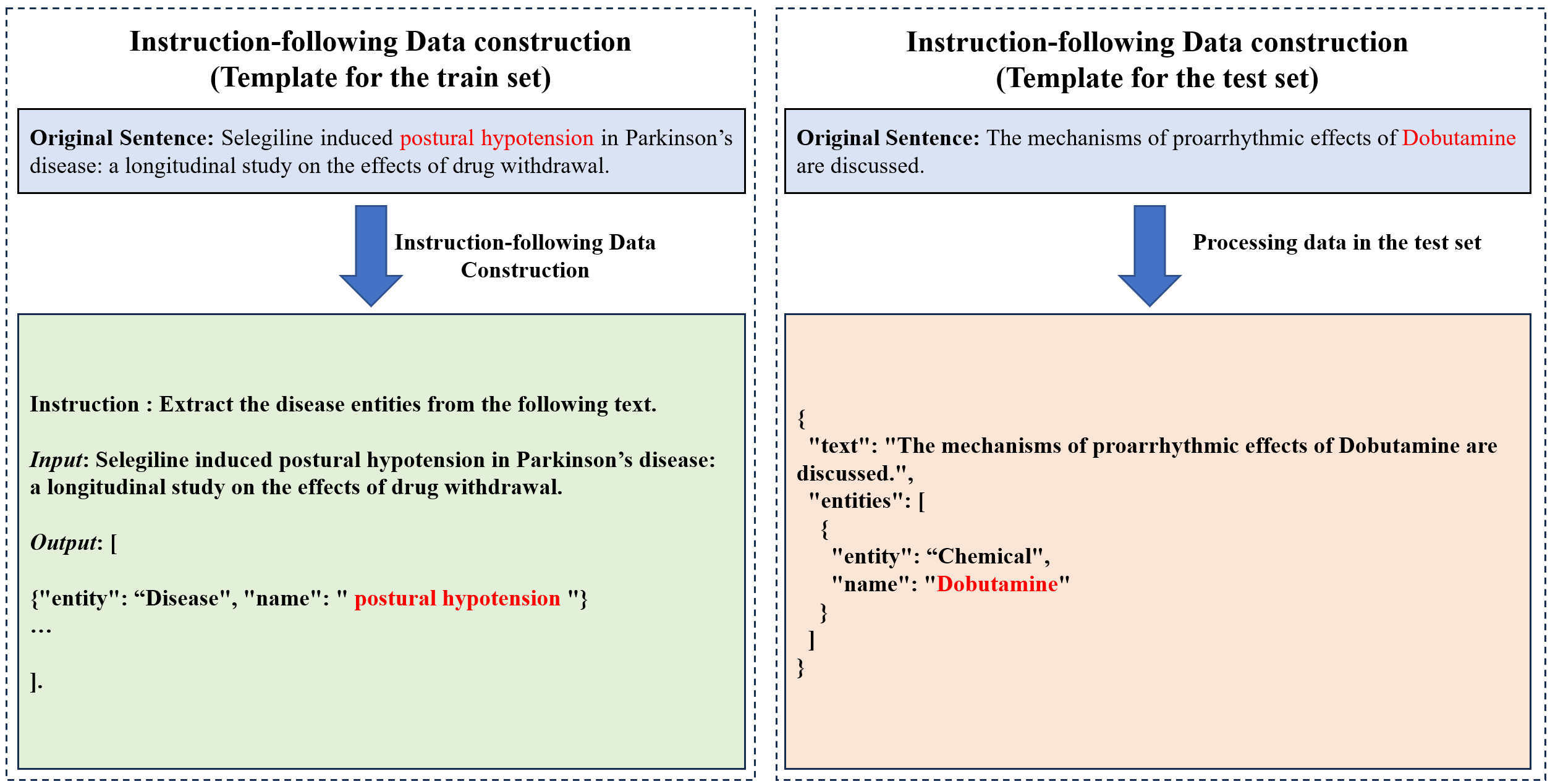
illustrated in Figure 1, the model is provided with a piece
of biomedical text and a specific instruction and is trained
to generate a standardized, machine-readable JSON list of
the identified entities. This approach not only unifies the
extraction paradigm across different entity types but also
capitalizes on the powerful instruction-following and text gen-
eration capabilities of modern LLMs. And we propose a novel
framework to efficiently adapt general-domain LLMs for high-
performance BioNER. Rather than relying on costly domain-
specific pre-training, we focus on unlocking the potential
of existing models through instruction tuning. We select the
Qwen3 family of models as our foundation [8] and, to this end,
curate and unify four benchmark BioNER datasets [9] into an
instruction-following format. The core of our framework is a
novel data curation strategy we term "Hybrid Superfiltering,"
[10] which leverages a computationally inexpensive "weak"
model to intelligently identify and select the most informative
and difficult training samples for fine-tuning a more powerful
"strong" model. Our main contributions are as follows:
• We introduce Hybrid Superfiltering, a weak-to-strong
data filtering strategy tailored for BioNER instruc-
tion tuning. By separating positive and negative sam-
ples and using a homologous weak model to score
Instruction-Following Difficulty (IFD), this method
curates a high-quality training subset that significantly
boosts learning efficiency and model performance.
• We reformulate BioNER as an end-to-end text-to-
structured-data generation task. By fine-tuning the
Su et al.: Preprint submitted to Elsevier
Page 1 of 9
arXiv:2512.22738v1 [cs.CL] 28 Dec 2025
Figure 1: Templates for instruction-following data and test data.
LLM to directly output ent