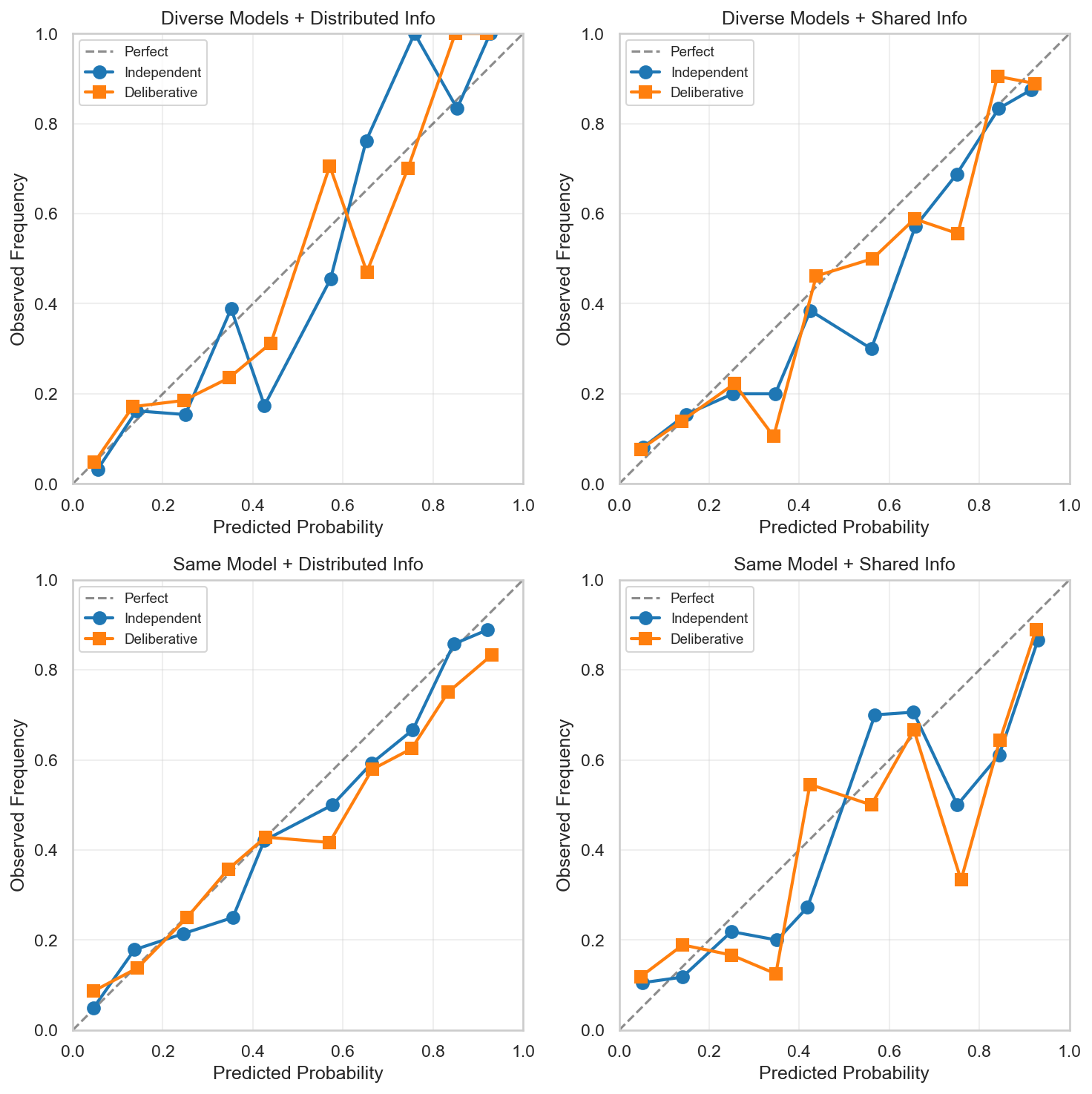
Structured deliberation has been found to improve the performance of human forecasters. This study investigates whether a similar intervention, i.e. allowing LLMs to review each other's forecasts before updating, can improve accuracy in large language models (GPT-5, Claude Sonnet 4.5, Gemini Pro 2.5). Using 202 resolved binary questions from the Metaculus Q2 2025 AI Forecasting Tournament, accuracy was assessed across four scenarios: (1) diverse models with distributed information, (2) diverse models with shared information, (3) homogeneous models with distributed information, and (4) homogeneous models with shared information. Results show that the intervention significantly improves accuracy in scenario (2), reducing Log Loss by 0.020 or about 4 percent in relative terms (p = 0.017). However, when homogeneous groups (three instances of the same model) engaged in the same process, no benefit was observed. Unexpectedly, providing LLMs with additional contextual information did not improve forecast accuracy, limiting our ability to study information pooling as a mechanism. Our findings suggest that deliberation may be a viable strategy for improving LLM forecasting.
💡 Deep Analysis
📄 Full Content
The Wisdom of Deliberating AI Crowds: Does Deliberation
Improve LLM-Based Forecasting?
Paul Schneider∗
Amalie Schramm∗
Abstract
Structured deliberation has been found to improve the performance of human forecasters.
This
study investigates whether a similar intervention—allowing LLMs to review each other’s forecasts before
updating—can improve accuracy in large language models (GPT-5, Claude Sonnet 4.5, Gemini Pro 2.5).
Using 202 resolved binary questions from the Metaculus Q2 2025 AI Forecasting Tournament, accuracy was
assessed across four scenarios: (1) diverse models with distributed information, (2) diverse models with
shared information, (3) homogeneous models with distributed information, and (4) homogeneous models
with shared information. Results show that the intervention significantly improves accuracy in scenario (2),
reducing Log Loss by 0.020 or about 4% in relative terms (p = 0.017). However, when homogeneous groups
(three instances of the same model) engaged in the same process, no benefit was observed. Unexpectedly,
providing LLMs with additional contextual information did not improve forecast accuracy, limiting our
ability to study information pooling as a mechanism. Our findings suggest that deliberation may be a
viable strategy for improving LLM forecasting.
Introduction
Expert forecasting is the systematic elicitation of
probability judgments about future events. It usu-
ally involves obtaining probability estimates from
multiple experts and aggregating their judgments
into a single estimate (Mellers et al., 2014; Arm-
strong, 2001; Tetlock, 2005). Probabilistic forecasts
can support policy decision making and risk man-
agement across many domains, including geopoli-
tics (e.g., election outcomes), economics, and AI
safety (Hanea et al., 2021; Surowiecki, 2004; Tetlock
et al., 2014).
Traditionally,
forecasting relied on human ex-
perts (Tetlock, 2005; Tetlock and Gardner, 2015).
However, recent advancements in large language
models (LLMs) has sparked a new research program
into whether AI systems can potentially also provide
accurate forecasts (Zou et al., 2022; Schoenegger
et al., 2024; Ye et al., 2024; Halawi et al., 2024).
Various studies have since explored this question
*PRIORB, Bochum, Germany. Contact: paul@priorb.com
and found mixed results: while some authors report
that LLMs are already approaching or even exceed-
ing human-level performance (Halawi et al., 2024;
Schoenegger et al., 2025), a public AI forecasting
tournament showed that human expert forecasters
still outperform LLM-based systems by a significant
margin (Metaculus, 2025b,c).
In line with benchmarks in other areas, AI forecast-
ing results suggest that general LLM capabilities
might be the most important determinant of forecast
performance (Brown et al., 2020; Wei et al., 2022;
Kaplan et al., 2020; Metaculus, 2025b). Notwith-
standing, methodological choices also matter. This
includes prompt engineering, fine-tuning, retrieval
strategies, and aggregation methods.
One method that has not yet been systematically
tested is deliberation, i.e., the process of structured
discussion and sharing of information. It has been
shown to improve forecast accuracy when used by
teams of human experts (Hemming et al., 2018;
Dezecache et al., 2022). A deliberation-like protocol
(“multi-agent debate”) was also found to be effec-
1
arXiv:2512.22625v1 [cs.AI] 27 Dec 2025
The Wisdom of Deliberating AI Crowds
tive in improving LLM performance on math and
logic tasks (Du et al., 2024; Liang et al., 2024). In
this study, we test whether this finding extends to
LLM-based forecasting systems and improves their
accuracy.
Study Objective
We investigate whether a deliberation-like process
of sharing forecast estimates and reasoning across
multiple LLM instances (“deliberation” hereafter)
improves forecast accuracy, compared to simply ag-
gregating independent forecasts.
The hypothesis was tested under conditions that
varied along two dimensions: a) model diversity
(homogeneous vs. diverse), and b) information dis-
tribution (shared vs. distributed). The resulting
four scenarios correspond to distinct deployment
scenarios of LLM forecasting systems.
Methods
Overview
We used 202 resolved binary questions from the
Metaculus Q2 2025 AI tournament.
Groups of
three LLMs forecasted each question in two rounds.
LLMs first generated independent forecasts, then
were shown their peers’ forecasts and reasoning be-
fore making updated forecasts (“deliberation”). We
tested four scenarios crossing model diversity (di-
verse vs. homogeneous) with information distribu-
tion (distributed vs. shared). Accuracy was mea-
sured using Log Loss on the median group forecast.
Within each scenario, we used paired t-tests to com-
pare independent vs. deliberative forecasts.
Materials: Questions, Information, and
LLMs
Forecasting Questions
We used all 202 resolved binary questions from
the Metaculus Q2 2025 AI Forecasting Bench-
mark (Metaculus, 2025a). All questions ha