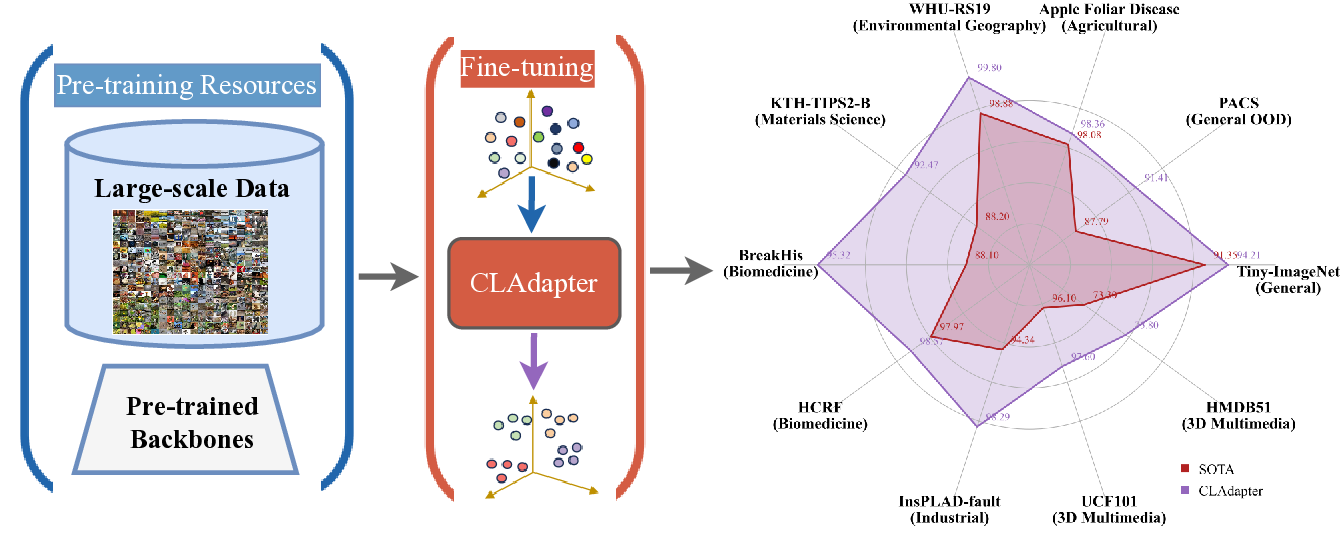
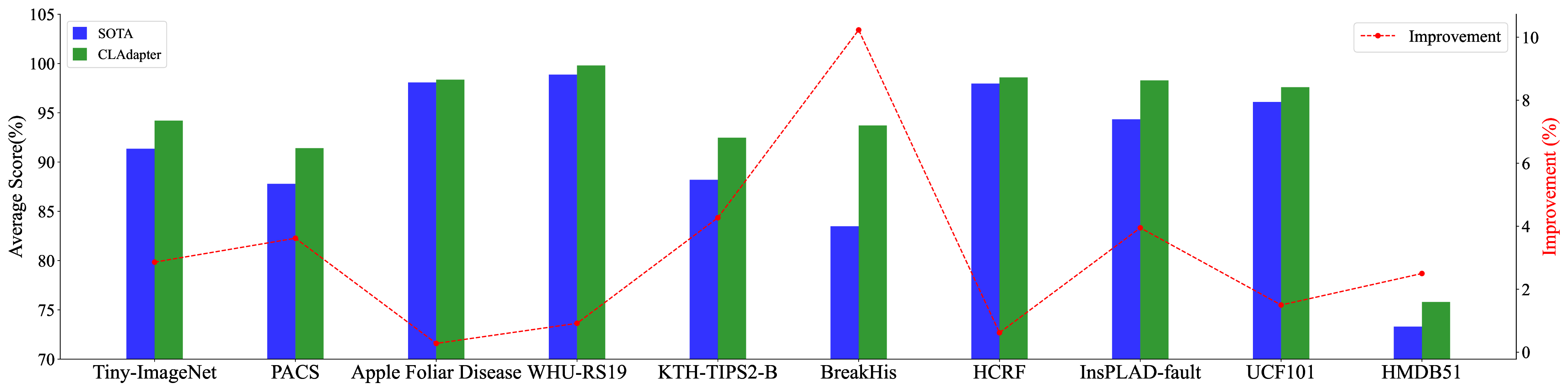
In the big data era, the computer vision field benefits from large-scale datasets such as LAION-2B, LAION-400M, and ImageNet-21K, Kinetics, on which popular models like the ViT and ConvNeXt series have been pre-trained, acquiring substantial knowledge. However, numerous downstream tasks in specialized and data-limited scientific domains continue to pose significant challenges. In this paper, we propose a novel Cluster Attention Adapter (CLAdapter), which refines and adapts the rich representations learned from large-scale data to various data-limited downstream tasks. Specifically, CLAdapter introduces attention mechanisms and cluster centers to personalize the enhancement of transformed features through distribution correlation and transformation matrices. This enables models fine-tuned with CLAdapter to learn distinct representations tailored to different feature sets, facilitating the models' adaptation from rich pre-trained features to various downstream scenarios effectively. In addition, CLAdapter's unified interface design allows for seamless integration with multiple model architectures, including CNNs and Transformers, in both 2D and 3D contexts. Through extensive experiments on 10 datasets spanning domains such as generic, multimedia, biological, medical, industrial, agricultural, environmental, geographical, materials science, out-of-distribution (OOD), and 3D analysis, CLAdapter achieves state-of-the-art performance across diverse data-limited scientific domains, demonstrating its effectiveness in unleashing the potential of foundation vision models via adaptive transfer. Code is available at https://github.com/qklee-lz/CLAdapter.
With the rapid advancement in artificial intelligence, deep learning-based computer vision algorithms have emerged as a dominant force [42,85,47]. These algorithms are inherently data-driven, capitalizing on substantial datasets to refine their task-specific performance. The digital age's ever-growing data trove has ushered in large-scale datasets, such as ImageNet-21K [58], LAION-400M [62], and LAION-2B [61], which aim to bolster algorithmic generalization and accuracy through data diversity and volume [25,44,10]. Despite these advancements, domain-specific challenges and data scarcity remain significant hurdles in scientific visual downstream tasks, where specialized data is often limited, heterogeneous, or expensive to acquire [11,72,79]. Therefore, developing methods that effectively harness the potential of large-scale pre-trained models to enable robust adaptation in data-limited scientific domains constitutes a critical and promising research direction.
Transfer learning through methods like linear probing and full fine-tuning is an essential approach for enhancing performance on downstream tasks [77]. This works well when transferring under normal-sized dataset pre-trained models to in-distribution (ID) downstream tasks. However, transfer-39th Conference on Neural Information Processing Systems (NeurIPS 2025).
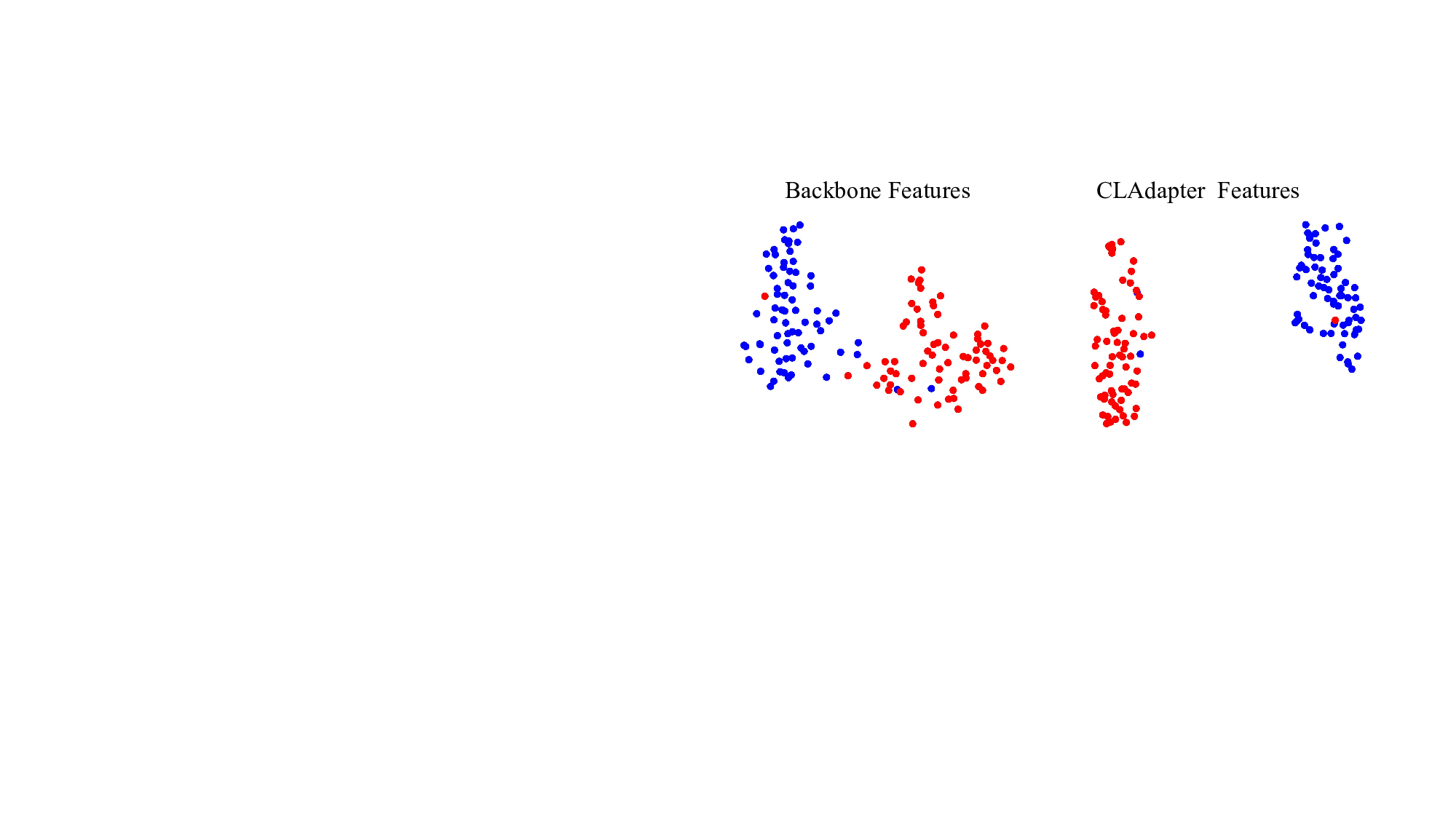
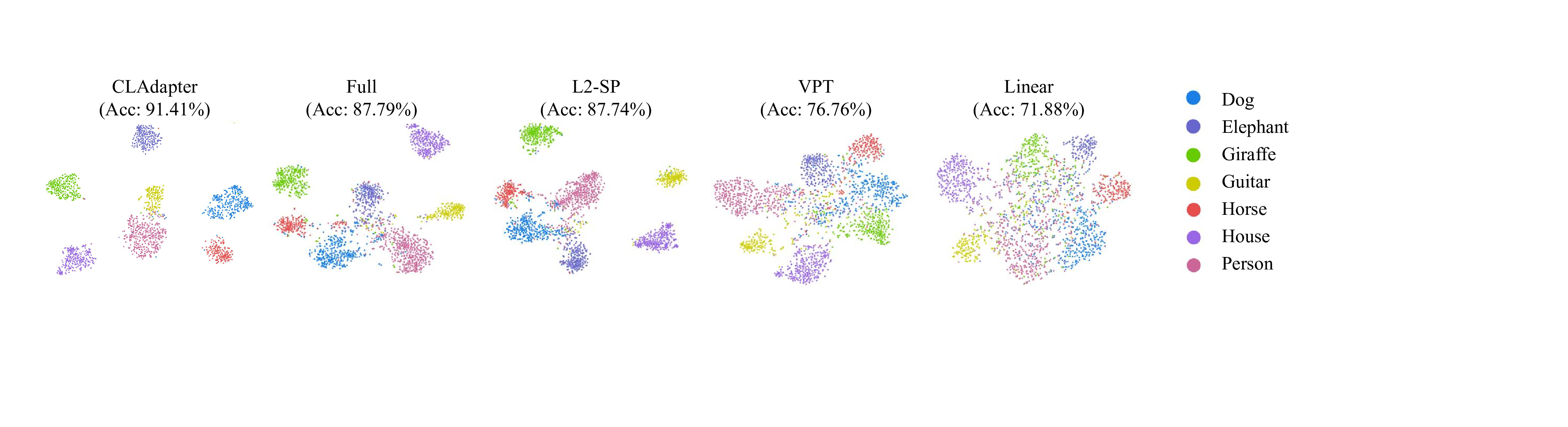
ring adapted knowledge from rich but complex large-scale upstream pretraining poses significant challenges in the current era of large datasets [61,10]. Furthermore, the scientific domains downstream tasks often involve out-of-distribution (OOD) scenarios [4], domain specificity [27], and data limitations [68], intensifying the fine-tuning challenge. L2-SP fine-tuning [26] introduced L2 regularization to preserve the insights of pre-trained weights during task adaptation, although they may lack robustness in OOD contexts. Visual Prompt Tuning (VPT) [34] augmented the input space with task-specific learnable prompts. However, VPT is primarily designed for Vision Transformer (ViT) [70] and lacks the ability to provide stable cross-domain feature transferability. OLOR [30] designed the fine-tuning optimizer from the perspective of pre-trained weights to improve stability, but it lacks task-specific self-adaptability, particularly under the diverse conditions of downstream scientific tasks. In this paper, we propose a novel Cluster Attention Adapter (CLAdapter), which refines and adapts the rich representations learned from large-scale data to diverse data-limited scientific downstream tasks (as illustrated in Figure 1). Specifically, CLAdapter introduces attention mechanisms and cluster centers to enable customized feature enhancement through distribution-aware correlation and transformation matrices. This facilitates the generation of task-adaptive representations, supporting a smooth transition from abundant pre-trained features to diverse downstream scenarios. Benefiting from our unified interface design, CLAdapter can seamlessly integrate with mainstream architectures, including CNNs, Transformers, and their 3D versions. In addition, a Staged Fine-Tuning (SFT) strategy is presented to collaborate with CLAdapter to further enhance the fine-tuning performance. Through extensive experiments conducted on 10 datasets spanning domains such as generic, multimedia, biological, medical, Industrial, agricultural, environmental, geographical, materials science, out-of-distribution (OOD), and 3D analysis, CLAdapter demonstrates its universal applicability and state-of-the-art performance. These results underscore the importance of effective knowledge transfer in the big data era and advance the reliable and efficient deployment of computer vision foundation models across scientific and industrial domains.
The contributions of this paper are summarized as follows:
1 ⃝ Adaptive Representation Transfer. We propose a novel CLAdapter that leverages large-scale pre-trained knowledge to enhance performance on a variety of data-limited downstream tasks.
⃝ Flexible Adaptation Framework. We design a unified interface and a staged fine-tuning (SFT) strategy, enabling CLAdapter to integrate seamlessly with mainstream pre-trained models and establish an efficient fine-tuning paradigm.
⃝ AI4Science Broad Evaluation. We conduct comprehensive experiments on 10 datasets across diverse domains, including multiple scientific fields where data is limited and heterogeneous.
CLAdapter consistently achieves state-of-the-art performance, demonstrating its potential as a generalizable solution for AI-driven scientific applications.
2 Related Work
With the rapid development of computer vision technology, a large number of large-scale datasets [58,62] and pre-trained models [56,57,5,25,19] have been proposed, providing a rich feature library for downstream tasks. Pre-training on large-scale datasets can encode rich semantic information, which is useful in solving limited data tasks, domain generalization, and zero-shot l
This content is AI-processed based on open access ArXiv data.