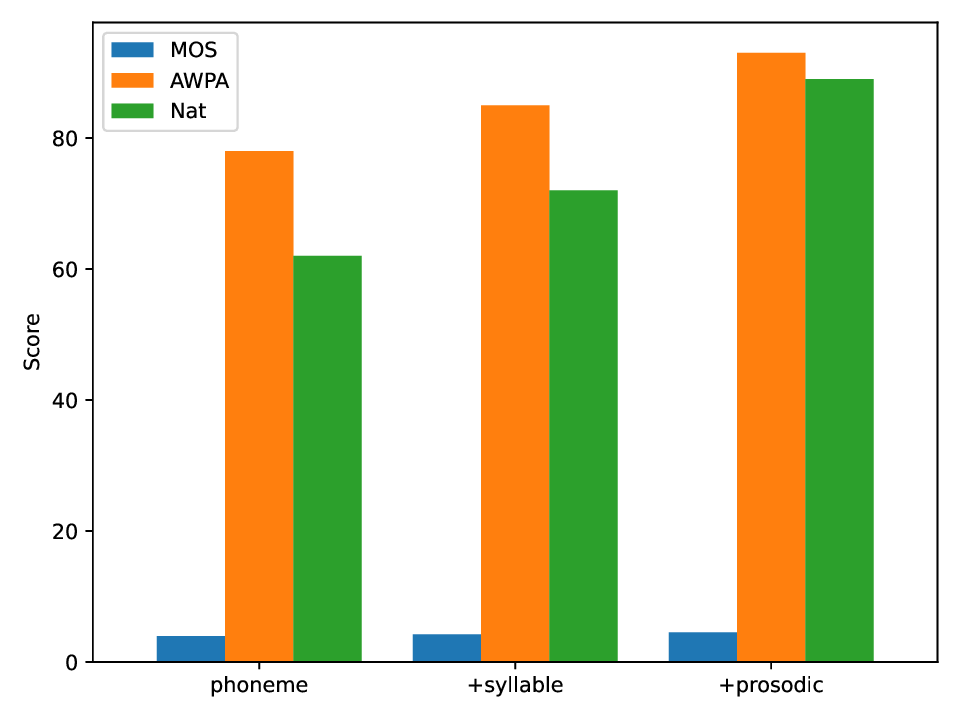
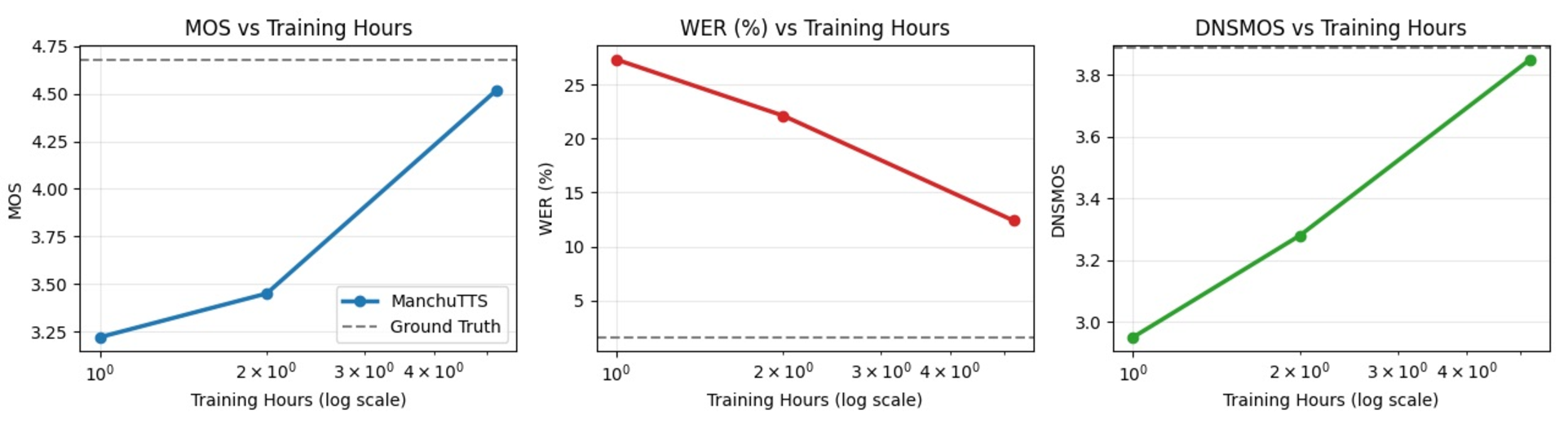
As an endangered language, Manchu presents unique challenges for speech synthesis, including severe data scarcity and strong phonological agglutination. This paper proposes ManchuTTS(Manchu Text to Speech), a novel approach tailored to Manchu's linguistic characteristics. To handle agglutination, this method designs a three-tier text representation (phoneme, syllable, prosodic) and a cross-modal hierarchical attention mechanism for multi-granular alignment. The synthesis model integrates deep convolutional networks with a flow-matching Transformer, enabling efficient, non-autoregressive generation. This method further introduce a hierarchical contrastive loss to guide structured acoustic-linguistic correspondence. To address low-resource constraints, This method construct the first Manchu TTS dataset and employ a data augmentation strategy. Experiments demonstrate that ManchuTTS attains a MOS of 4.52 using a 5.2-hour training subset derived from our full 6.24-hour annotated corpus, outperforming all baseline models by a notable margin. Ablations confirm hierarchical guidance improves agglutinative word pronunciation accuracy (AWPA) by 31% and prosodic naturalness by 27%.
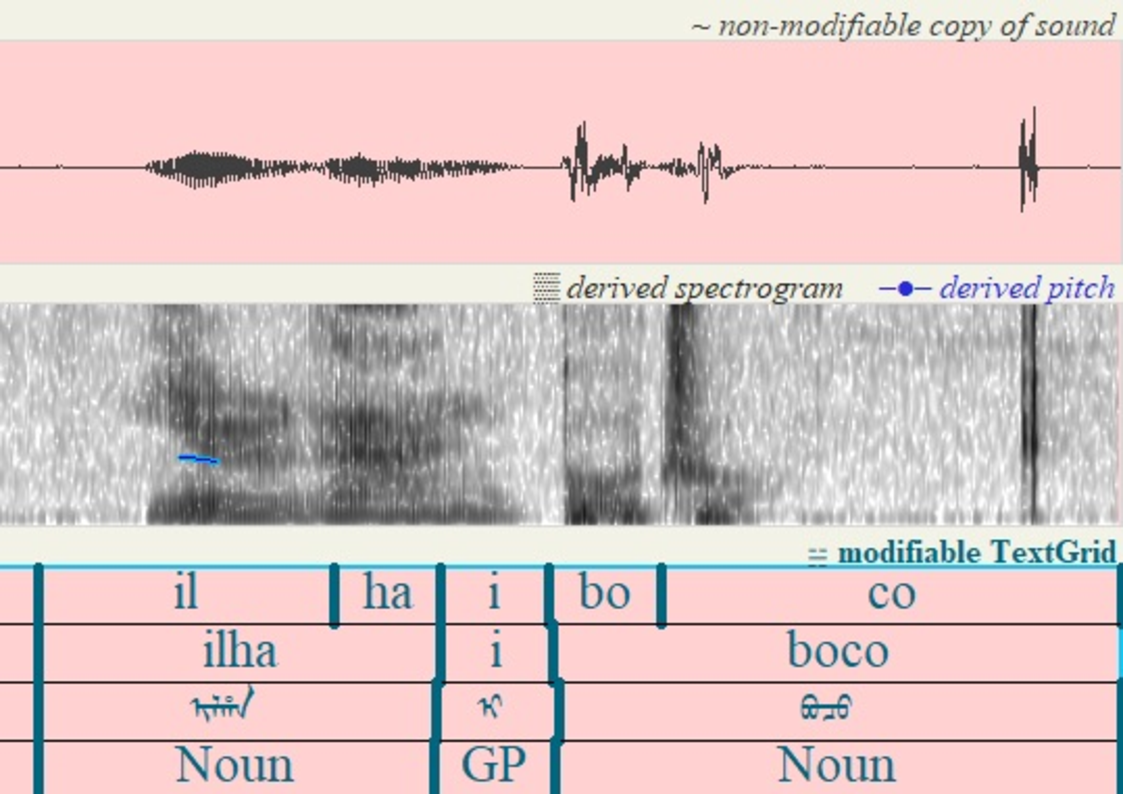
Research on speech synthesis [1] for common languages is relatively mature, but Manchu, a UNESCO "critically endangered" language, faces severe challenges due to data scarcity and complex phonological characteristics. As the official language of China's Qing Dynasty, Manchu has left behind a vast number of historical archives awaiting translation, as shown in Fig. 1. However, with fewer than 100 fluent speakers globally today, most documents remain uninterpreted, significantly hindering historical research.
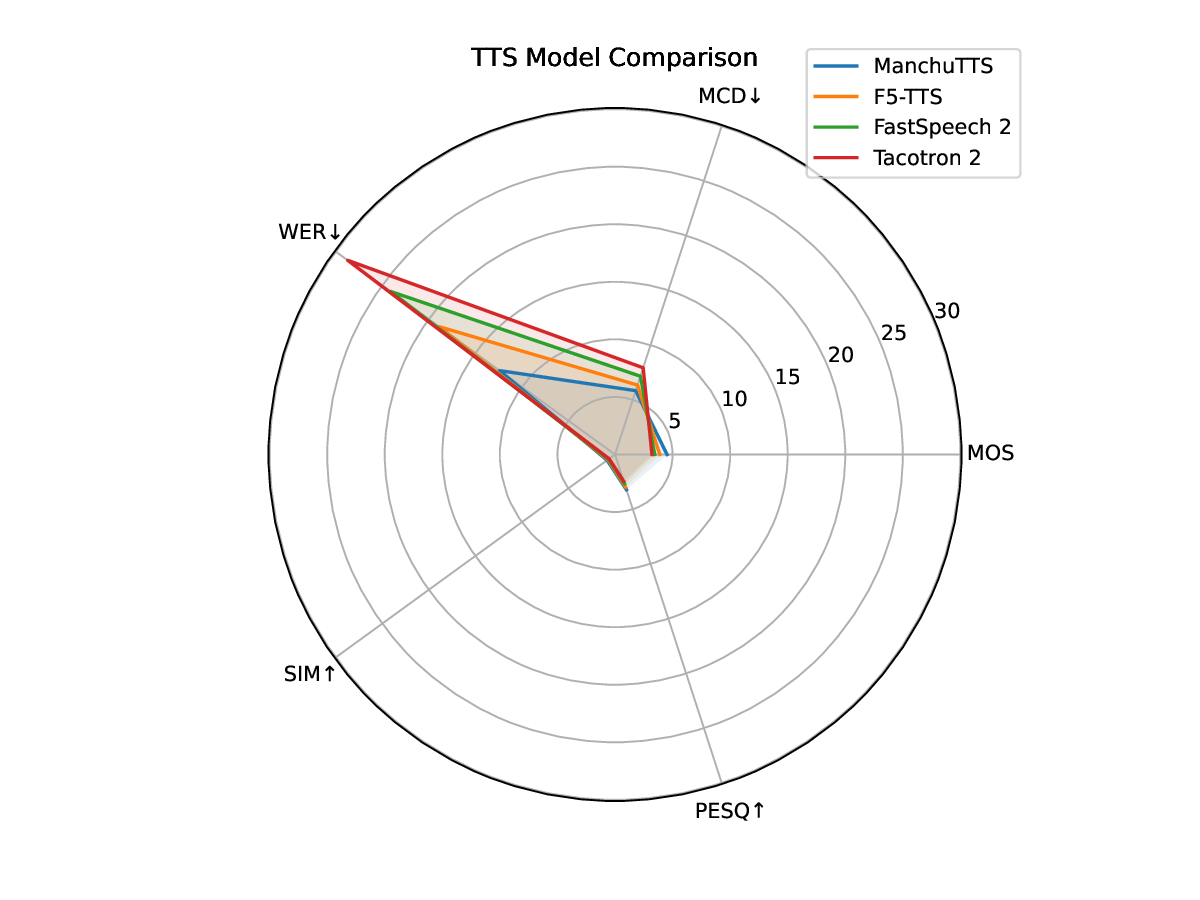
Manchu speech synthesis [2] faces dual challenges from severe data scarcity and complex linguistic characteristics [3], [4]. As an agglutinative language, its phonological patterns like vowel harmony are difficult for conventional TTS models to capture accurately. While methods such as LRSpeech [5] offer promising directions for low-resource synthesis, they assume a minimum data threshold unavailable for truly endangered languages. Existing approaches, including flow-based models like F5-TTS [6] and ReFlow-TTS [7]-lack design for Annotation example of Manchu speech using the Praat tool. agglutinative morphological complexity. Technically, explicit alignment methods show high error rates (25%-35%) in lowresource settings, duration predictors produce rigid rhythms, and non-autoregressive architectures struggle with nuanced prosodic variations. This creates a dual challenge: overcoming both data scarcity and the alignment demands of agglutinative phonology.
To address data scarcity and agglutinative complexity, this paper propose ManchuTTS, a framework integrating hierarchical linguistic guidance with conditional flow matching [8]. Unlike standard flow-based TTS, the method condition the flow vector field on three-tier linguistic features c = {c phon , c syll , c pros } . The model employs cross-modal attention for multi-granular alignment and efficient non-autoregressive generation via conditional differential equations. Key contributions include: a hierarchical guidance mechanism for agglutinative languages; an end-to-end system based on conditional flow matching; and the first public Manchu TTS dataset with validation. Experimental results show ManchuTTS achieves a MOS of 4.52 with only 5.2 hours training data, surpassing all baselines. Ablations validate the hierarchical design, improving agglutinative word accuracy by 31% and prosodic naturalness by 27%. The main contributions of this work are as follows:
• This paper propose a hierarchical text feature guidance framework tailored for Manchu speech synthesis, effectively addressing its agglutinative characteristics. • This paper develop an end-to-end speech synthesis system based on hierarchical conditional flow matching, enabling high-quality synthesis with minimal data requirements.
• This paper construct the first publicly available Manchu speech synthesis dataset and demonstrate the effectiveness of this approach through comprehensive experiments. This work provides both a practical solution for Manchu speech synthesis and a methodological framework that can be extended to other endangered languages, contributing to the preservation and accessibility of linguistic heritage through technological innovation.
Theoretical Framework. This method establishes an implicit mapping from reference speech V ref and text T ref to target speech for T tgt , forming a ternary speech-text-acoustic relationship. To handle Manchu’s agglutinative nature, the input text is decomposed into three hierarchical linguistic units. c phon is phoneme-level features. c syll is syllable/word-structure features. c pros is prosodic features. These are integrated into a conditional flow matching framework to guide the speech generation process. Conditional Flow Matching. This model the transformation from noise x 0 to target speech x 1 via a linear interpolation path:
where x 0 ∼ N (0, I) and x 1 is the target mel-spectrogram.
The corresponding vector field that drives this transformation is:
The goal is to learn a parameterized model v t (x t | c; θ) that approximates u t . The training objective is:
Here, c = {c phon , c syll , c pros } represents the multi-level linguistic conditions. At inference, this method start from Gaussian noise and solve the ODE defined by v t to generate speech that aligns with the input text. To handle Manchu’s complex agglutinative morphology, this work proposes a three-stage mechanism (phoneme-syllableprosody). Fig. 2 illustrates the multi-layer Praat annotations for an agglutinative sentence, validated by linguists. The complete synthesis pipeline of ManchuTTS is presented in Fig. 3.
This paper proposes a three-layer cross-modal attention architecture for progressive alignment between textual features F t and acoustic features F a . Following a “self-attention → interaction → self-attention” paradigm, it enables stepwise cross-modal alignment.
Layer 1: Intra-modal Self-Attention First, both textual and acoustic features undergo intra-mod
This content is AI-processed based on open access ArXiv data.