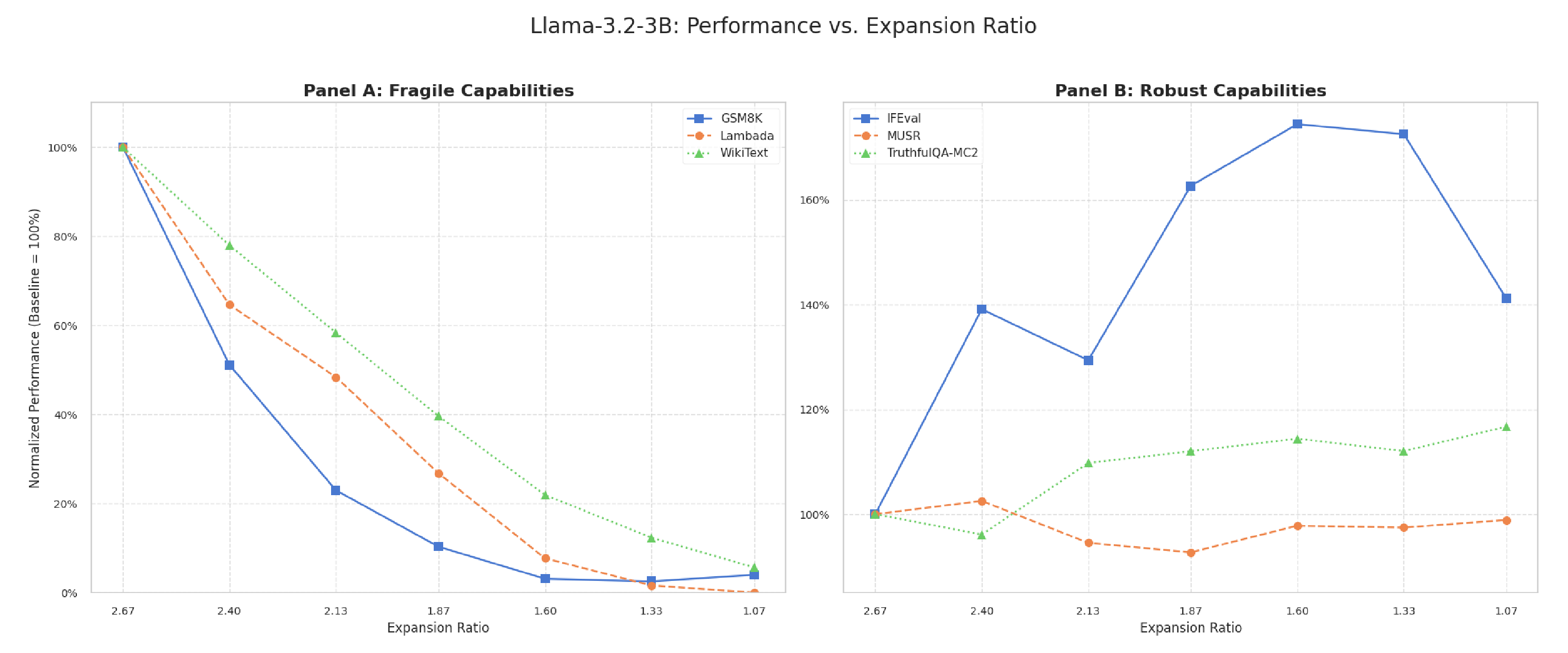
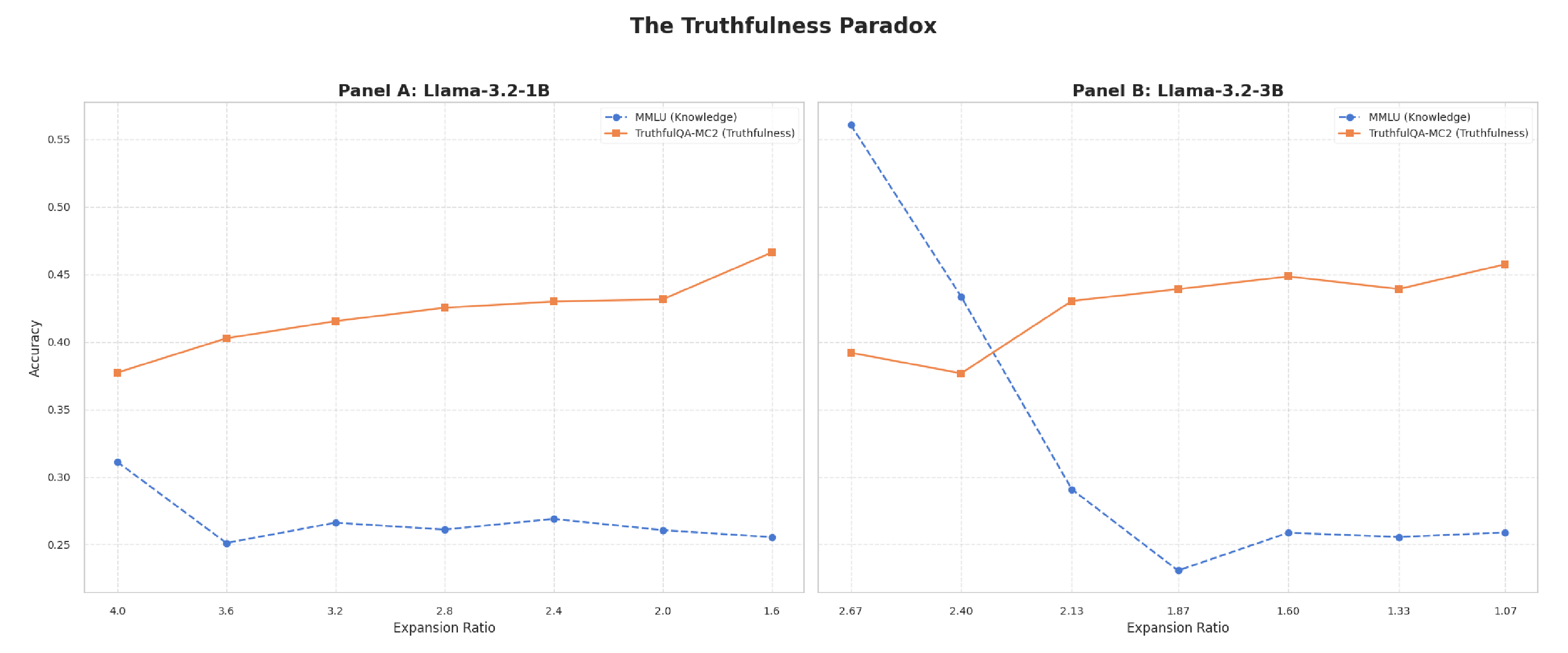
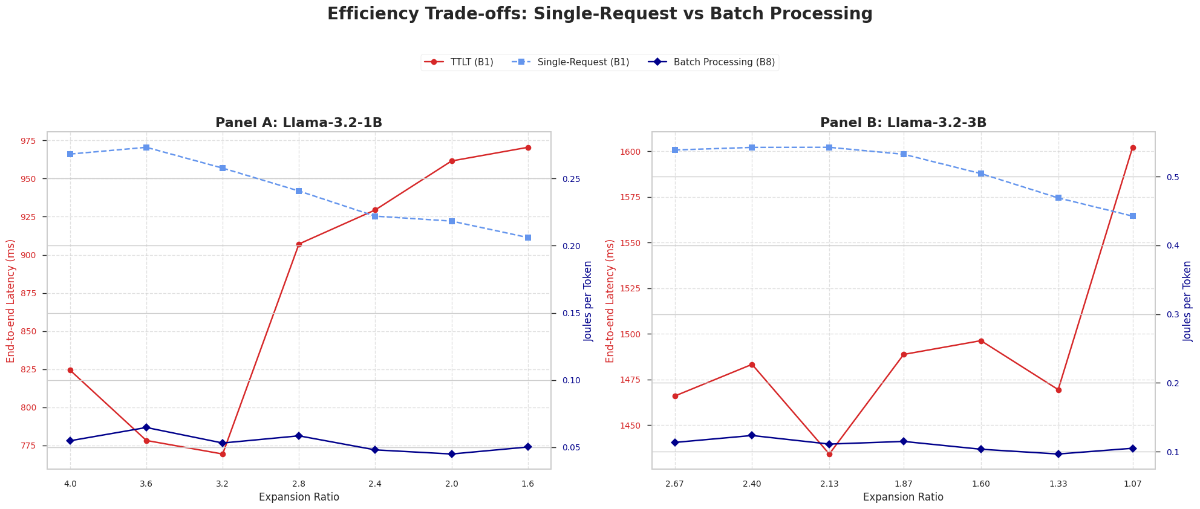
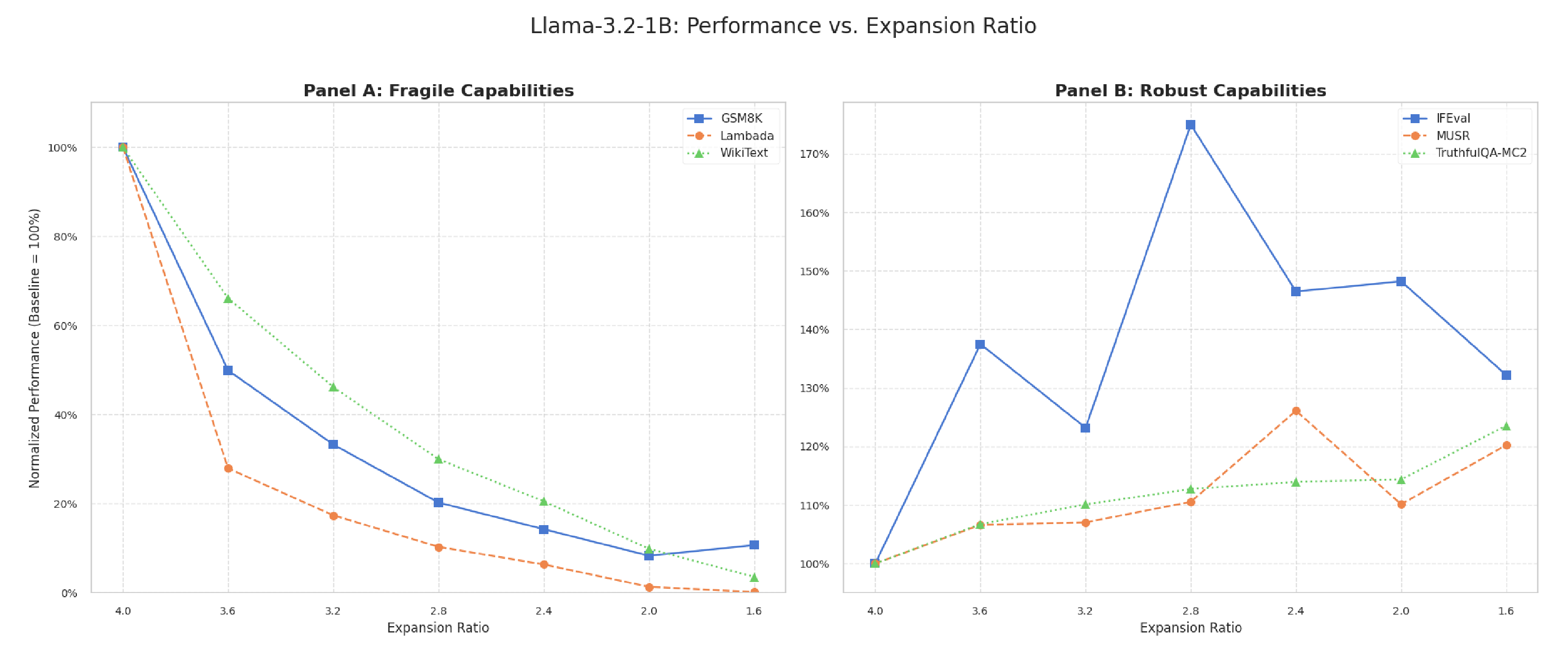
Structured width pruning of GLU-MLP layers, guided by the Maximum Absolute Weight (MAW) criterion, reveals a systematic dichotomy in how reducing the expansion ratio affects different model capabilities. While performance on tasks relying on parametric knowledge (e.g., MMLU, GSM8K) and perplexity metrics degrades predictably, instruction-following capabilities improve substantially (+46% to +75% in IFEval for Llama-3.2-1B and 3B models), and multi-step reasoning remains robust (MUSR). This pattern challenges the prevailing assumption that pruning induces uniform degradation. We evaluated seven expansion ratio configurations using comprehensive benchmarks assessing factual knowledge, mathematical reasoning, language comprehension, instruction-following, and truthfulness. Our analysis identifies the expansion ratio as a critical architectural parameter that selectively modulates cognitive capabilities, rather than merely serving as a compression metric. We provide the first systematic characterization of this selective preservation phenomenon. Notably, we document a robust inverse correlation (r = -0.864, p = 0.012 in Llama-3B) between factual knowledge capacity (MMLU) and truthfulness metrics (TruthfulQA-MC2): as knowledge degrades, the model's ability to discriminate misconceptions improves consistently. This connects two previously distinct research areas, demonstrating that MAW-guided width pruning acts as a selective filter, reducing parametric knowledge while preserving or enhancing behavioral alignment. Additionally, we quantify context-dependent efficiency trade-offs: pruned configurations achieve up to 23% reduction in energy consumption (J/token) but incur penalties in single-request latency, whereas batch processing workloads benefit uniformly.
This study investigates the impact of structured width pruning on GLU-MLP layers Guo et al. (2024), using Llama-3.2 models as case studies. We analyze how the expansion ratio-a key architectural parameterserves not only as a compression mechanism but also as an intervention that selectively modulates cognitive capabilities Sharma et al. (2023).
Building on a prior empirical observation Martra (2024a) that identified a 140% expansion ratio as a performance equilibrium point, this work provides the first systematic characterization of the underlying mechanisms. We document two core findings: (1) a “Capability Dichotomy,” where MAW pruning degrades parametrized knowledge while preserving or improving instruction-following, and (2) a “Truthfulness Paradox”-an inverse correlation (r = -0.864) between factual knowledge and misconception discrimination.
Section 1.1 motivates the need for efficient models, Section 1.2 contextualizes width pruning within LLM optimization techniques, Section 1.3 details our contributions, and Section 1.4 previews key results.
Large language models have demonstrated unprecedented capabilities across a wide range of tasks Zhao et al. (2025), but their increasing size incurs significant computational and energy costs during both training and inference. Models with tens or hundreds of billions of parameters require specialized infrastructure and consume substantial resources, which limits their accessibility and sustainability Muralidharan et al. (2024).
Reducing the computational footprint of LLMs is no longer merely an academic goal but a practical necessity to democratize access, enable deployment on resource-constrained devices (e.g., edge devices), and ensure long-term economic and environmental viability. This urgent need for efficiency has spurred research into techniques for improving the efficiency of large language model-based solutions Sun et al. (2024).
Among these techniques, structured pruning-the systematic removal of neural components-has emerged as a particularly promising approach, traditionally viewed as a compression method Muralidharan et al. (2024); Xia et al. (2024). However, applying width pruning to GLU layers introduces a fundamental architectural question: Does capacity reduction uniformly degrade all cognitive functions, or can it induce selective changes?. In this study, we use pruning not only as a compression tool but also as an analytical lens to explore this question, systematically examining how variations in the expansion ratio reshape the model’s capability profile.
Structured pruning is one of several strategies employed by the research community for model optimization. It complements two other primary approaches: quantization, which reduces the numerical precision of model weights (e.g., from 16-bit to 4-bit representation), and knowledge distillation, which trains a smaller “student” model to replicate the behavior of a larger “teacher” model Muralidharan et al. (2024).
Unlike quantization and distillation-methods that operate at the representation and training levels, respectively-structured pruning directly modifies the model’s architecture by removing entire components. This approach permanently reduces the parameter count Sun et al. (2024); Xia et al. (2024), enabling both the elimination of inherent structural redundancies in pre-trained models and the adaptation of generalpurpose models to task-specific deployments. By prioritizing the most relevant capabilities for a given use case, pruning can optimize models for efficiency without sacrificing critical functionality Reda et al. (2025).
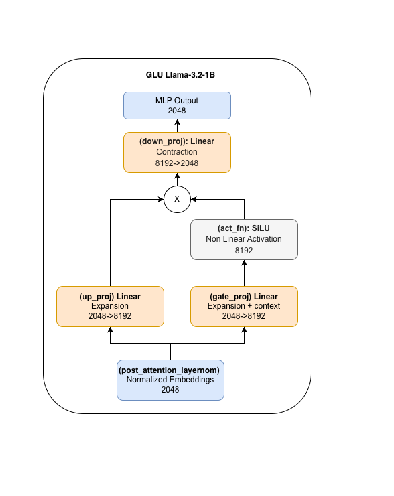
Structured pruning techniques are broadly categorized into depth pruning (removing entire layers) and width pruning (reducing layer dimensions) Kim et al. (2024); Muralidharan et al. (2024). While depth pruning represents an aggressive and coarse-grained intervention, width pruning offers finer-grained control, enabling precise, “surgical” modifications to the model’s behavior at the neuronal level Sharma et al. (2023); Wei et al. (2024). This study focuses on the systematic application of width pruning to adjust the intermediate dimension of MLP layers, thereby altering the expansion ratio-a fundamental yet understudied architectural parameter whose impact on model capabilities remains poorly understood.
This work presents a systematic analysis of the impact of width pruning on GLU architectures, using Llama-3.2-1B and 3B models as case studies. Specifically, we examine how variations in the expansion ratio differentially affect cognitive capabilities in language models. Our main contributions are as follows:
• Dichotomy of capabilities under the MAW criterion: We demonstrate that width pruning guided by the Maximum Absolute Weight (MAW) criterion affects different task types in fundamentally distinct ways. While capabilities reliant on parametrized knowledge-such as performance on MMLU, GSM8K, and perplexity-degrade predictably with reductions in t
This content is AI-processed based on open access ArXiv data.