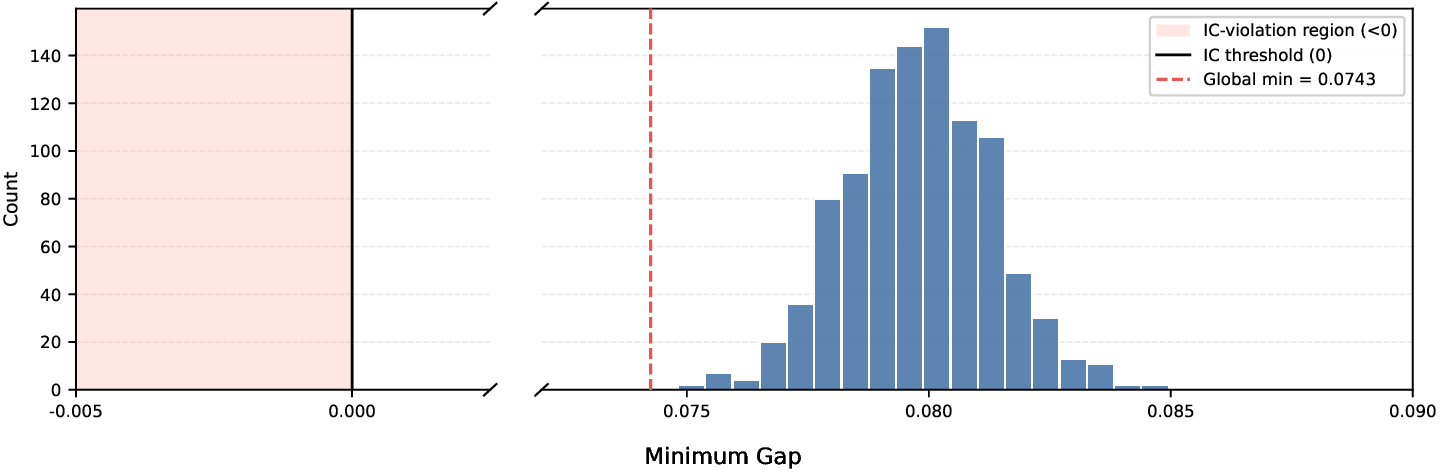
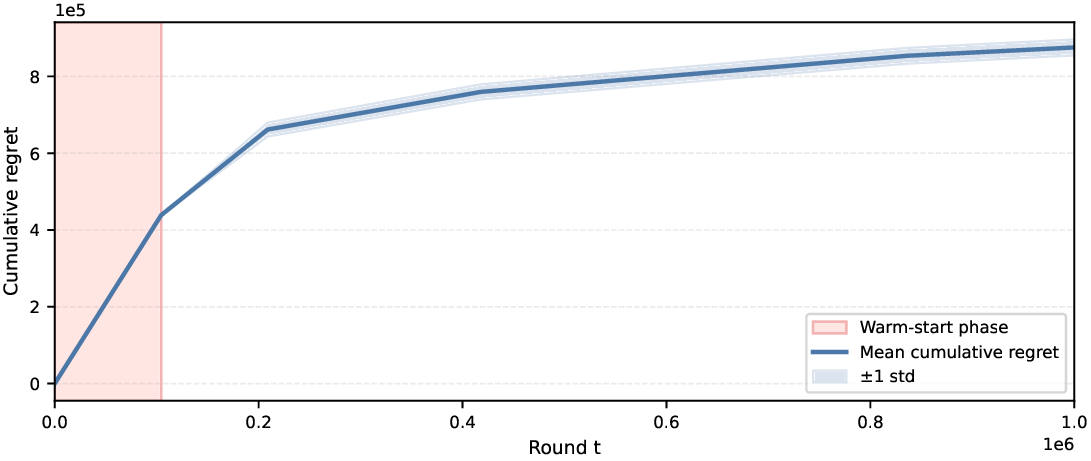
We study a sequential mechanism design problem in which a principal seeks to elicit truthful reports from multiple rational agents while starting with no prior knowledge of agents' beliefs. We introduce Distributionally Robust Adaptive Mechanism (DRAM), a general framework combining insights from both mechanism design and online learning to jointly address truthfulness and cost-optimality. Throughout the sequential game, the mechanism estimates agents' beliefs and iteratively updates a distributionally robust linear program with shrinking ambiguity sets to reduce payments while preserving truthfulness. Our mechanism guarantees truthful reporting with high probability while achieving $\tilde{O}(\sqrt{T})$ cumulative regret, and we establish a matching lower bound showing that no truthful adaptive mechanism can asymptotically do better. The framework generalizes to plug-in estimators, supporting structured priors and delayed feedback. To our knowledge, this is the first adaptive mechanism under general settings that maintains truthfulness and achieves optimal regret when incentive constraints are unknown and must be learned.
The theory of mechanism design studies rules and institutions in various disciplines, ranging from auctions and online advertisements to business contracts and trading rules. The formulation often involves a central principal (system) and one or many rational agents (players), where the principal designs a mechanism to achieve a given objective subject to agents' incentives. A typical component is the common knowledge assumption: certain information about agents is presumed known to the principal and can be exploited to design analytically tractable, often optimal mechanisms. For example, knowledge over bidders' value distributions over the auctioned can be used to design revenue-optimal auctions [Myerson, 1981]. However, the availability of such knowledge is difficult to justify in practice. This observation, originally due to [Wilson, 1985], is now known as Wilson's critique. It proposes that some information is too private to be common knowledge, and such assumptions should be weakened to approximate reality.
In parallel, the theory of online learning studies algorithms that learn and make decisions in unfamiliar environments, aiming to approach the performance of oracles that have full knowledge from the start. The principal typically begins with no knowledge of the environment, and information is acquired through repeated data collection and carefully designed statistical methods. A common assumption is that the environment is unknown but stationary. For example, in the classical multi-armed bandit model [Lattimore and Szepesvári, 2020], each arm’s reward is a stochastic distribution, and the best arm can be discovered via repeated sampling. An alternative is to assume the worst-case scenario from the environment, i.e., fully adversarial feedback. These algorithms have wide applications in recommendation, pricing, scheduling, and more [Lattimore * Author ordering alphabetical. All authors made valuable contributions to the writing, editing, and overall management of the project. Renfei Tan led the project, and is the first to propose the idea of achieving cost-efficient adaptive mechanisms via sequentially accurate distributionally robust mechanisms. He is the main developer of the modeling, algorithm, and corresponding theorems, as well as the main writer of the paper. Zishuo Zhao contributed on discussions, proofreading, and comprehensive review. He proposed the main idea of distributionally robust mechanisms with insights on the synergy between it and online learning. He also helped formulating the examples and wrote the literature review part of peer prediction. Qiushi Han proposed the initial idea of the two-phased (warm-start and adaptive) approach to relax the common knowledge assumptions and contributed to the development of the main algorithm. He led the design and conduct of the numerical experiments in this work. David Simchi-Levi supervised the research and assisted in writing the paper. † Corresponding author. Nature samples an unlabeled image with an unknown ground truth, which is then independently observed by multiple agents. Each agent’s observation (type) is private to herself. The agents then report to the principal and receive rewards in the end. Lying or lazy behavior is possible, since the principal does not know the ground truth or the agents’ observations. One objective is to incentivize truthful behavior via reward mechanisms based on only agents’ reports. and Szepesvári, 2020]. In application, however, they often interact with humans, who are neither stationary nor fully adversarial. In fact, a foundational assumption in economics is that humans are rational [Von Neumann and Morgenstern, 2007].
Therefore, the strength and weaknesses from both fields seems to complement to each one. Mechanism design incentivizes nice behavior from rational agents for proper learning guarantees, and online learning can provide the necessary knowledge for efficient mechanisms. For this reason, the combination of mechanism design and online learning has received increasing attention, most notably in settings such as online contract design [Ho et al., 2014, Zhu et al., 2022] and online auctions [Blum et al., 2004, Cesa-Bianchi et al., 2014]. However, the design of general multi-agent adaptive mechanisms remains an under-explored problem.
In this work, we study the sequential mechanism design problem in which a principal in each round designs reward mechanisms for multiple rational agents, while starting with no prior knowledge of agents’ beliefs. The principal’s objective is three-fold: data quality, truthfulness, and cost-optimality. The principal wants to design a reward mechanism that can obtain the highestquality data from the task, while incentivizing truthful report from agents, and do so in a costminimal way. As a motivating example, consider the image labeling task where the principal assigns raw images to multiple agents for labeling (Figure 1). In each round, each agent makes a private
This content is AI-processed based on open access ArXiv data.