Title: A-QCF-Net: An Adaptive Quaternion Cross-Fusion Network for Multimodal Liver Tumor Segmentation from Unpaired Datasets
ArXiv ID: 2512.21760
Date: 2025-12-25
Authors: ** - Arunkumar Va (University College of Engineering, Bharathidasan Institute of Technology Campus, Anna University, Tiruchirappalli, Tamilnadu, India) - V. M. Firosb (National Institute of Technology, Tiruchirappalli, Tamil Nadu, India) - S. Senthilkumara (National Institute of Technology, Tiruchirappalli, Tamil Nadu, India) - G. R. Gangadharanb (National Institute of Technology, Tiruchirappalli, Tamil Nadu, India) — **
📝 Abstract
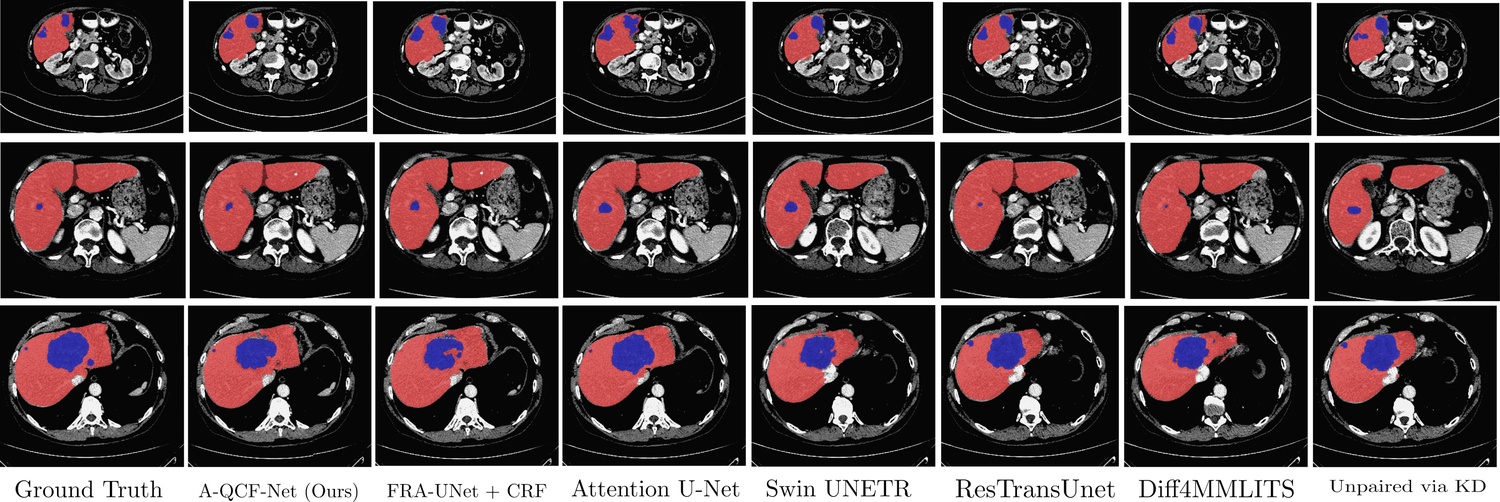
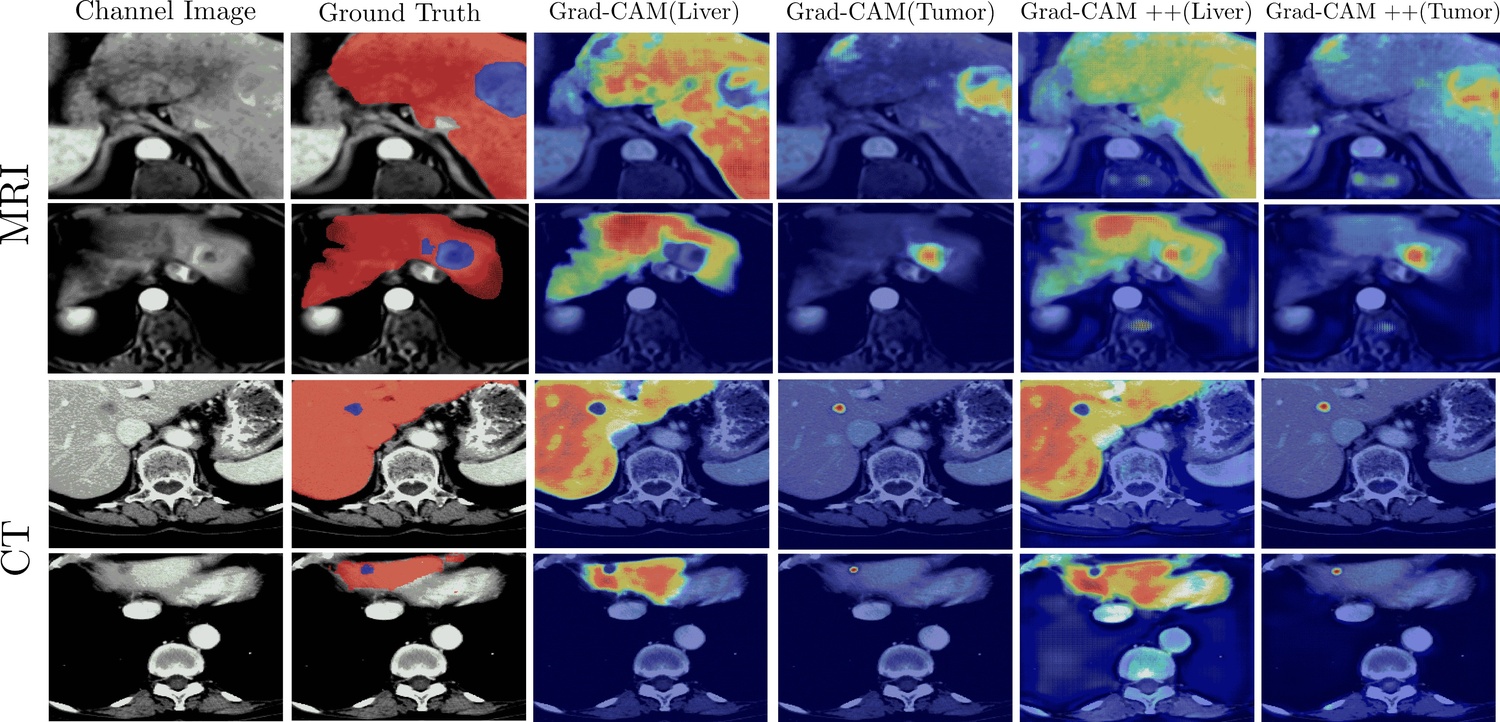
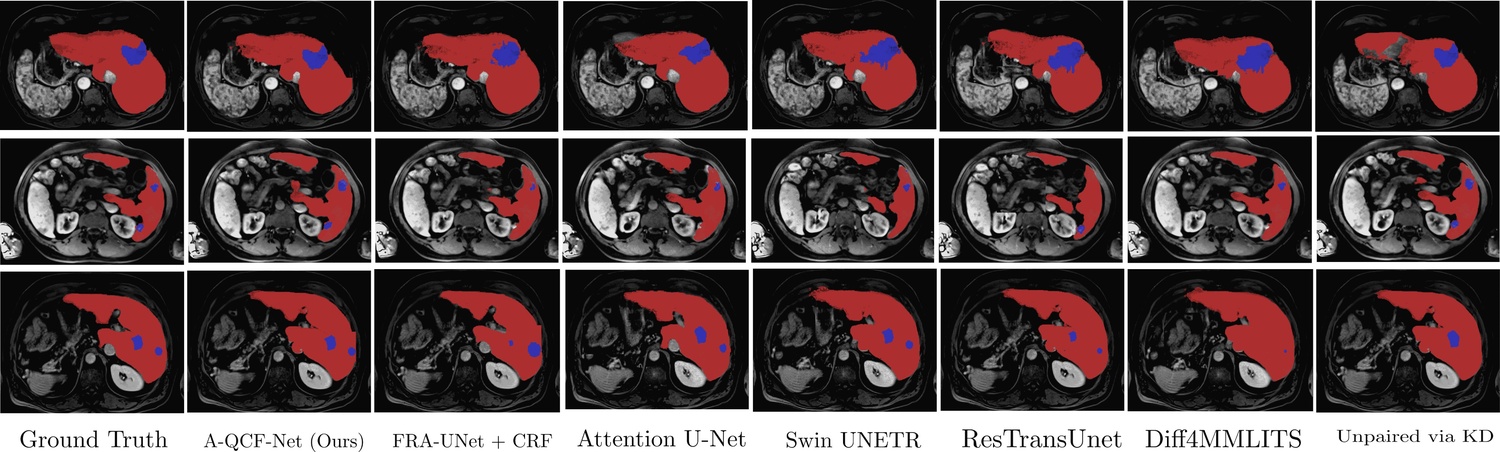
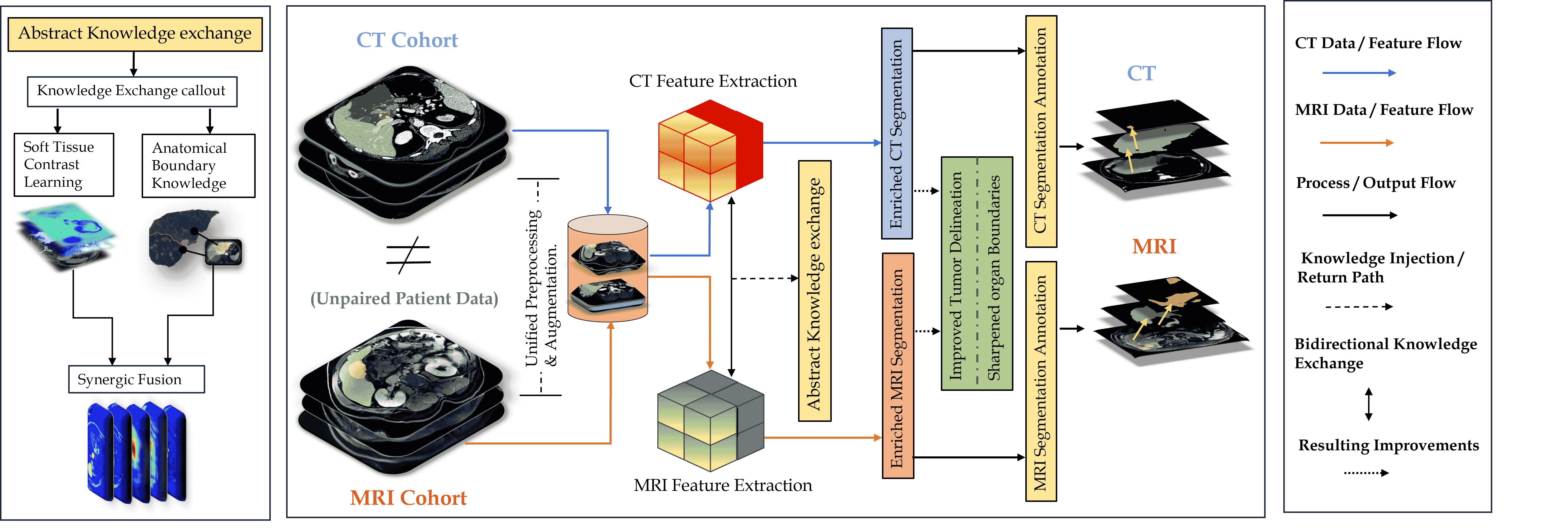
Multimodal medical imaging provides complementary information that is crucial for accurate delineation of pathology, but the development of deep learning models is limited by the scarcity of large datasets in which different modalities are paired and spatially aligned. This paper addresses this fundamental limitation by proposing an Adaptive Quaternion Cross-Fusion Network (A-QCF-Net) that learns a single unified segmentation model from completely separate and unpaired CT and MRI cohorts. The architecture exploits the parameter efficiency and expressive power of Quaternion Neural Networks to construct a shared feature space. At its core is the Adaptive Quaternion Cross-Fusion (A-QCF) block, a data driven attention module that enables bidirectional knowledge transfer between the two streams. By learning to modulate the flow of information dynamically, the A-QCF block allows the network to exchange abstract modality specific expertise, such as the sharp anatomical boundary information available in CT and the subtle soft tissue contrast provided by MRI. This mutual exchange regularizes and enriches the feature representations of both streams. We validate the framework by jointly training a single model on the unpaired LiTS (CT) and ATLAS (MRI) datasets. The jointly trained model achieves Tumor Dice scores of 76.7% on CT and 78.3% on MRI, significantly exceeding the strong unimodal nnU-Net baseline by margins of 5.4% and 4.7% respectively. Furthermore, comprehensive explainability analysis using Grad-CAM and Grad-CAM++ confirms that the model correctly focuses on relevant pathological structures, ensuring the learned representations are clinically meaningful. This provides a robust and clinically viable paradigm for unlocking the large unpaired imaging archives that are common in healthcare.
💡 Deep Analysis
📄 Full Content
A-QCF-Net: An Adaptive Quaternion Cross-Fusion Network
for Multimodal Liver Tumor Segmentation from Unpaired
Datasets
Arunkumar Va, V. M. Firosb, S. Senthilkumara, G. R. Gangadharanb,
aUniversity College of Engineering, Bharathidasan Institute of Technology Campus, Anna
University, Tiruchirappalli, Tamilnadu, 620 024, India
bNational Institute of Technology, Tiruchirappalli, Tamil Nadu, 620015, India
Abstract
Multimodal medical imaging provides complementary information that is crucial for ac-
curate delineation of pathology, but the development of deep learning models is limited by
the scarcity of large datasets in which different modalities are paired and spatially aligned.
This paper addresses this fundamental limitation by proposing an Adaptive Quaternion
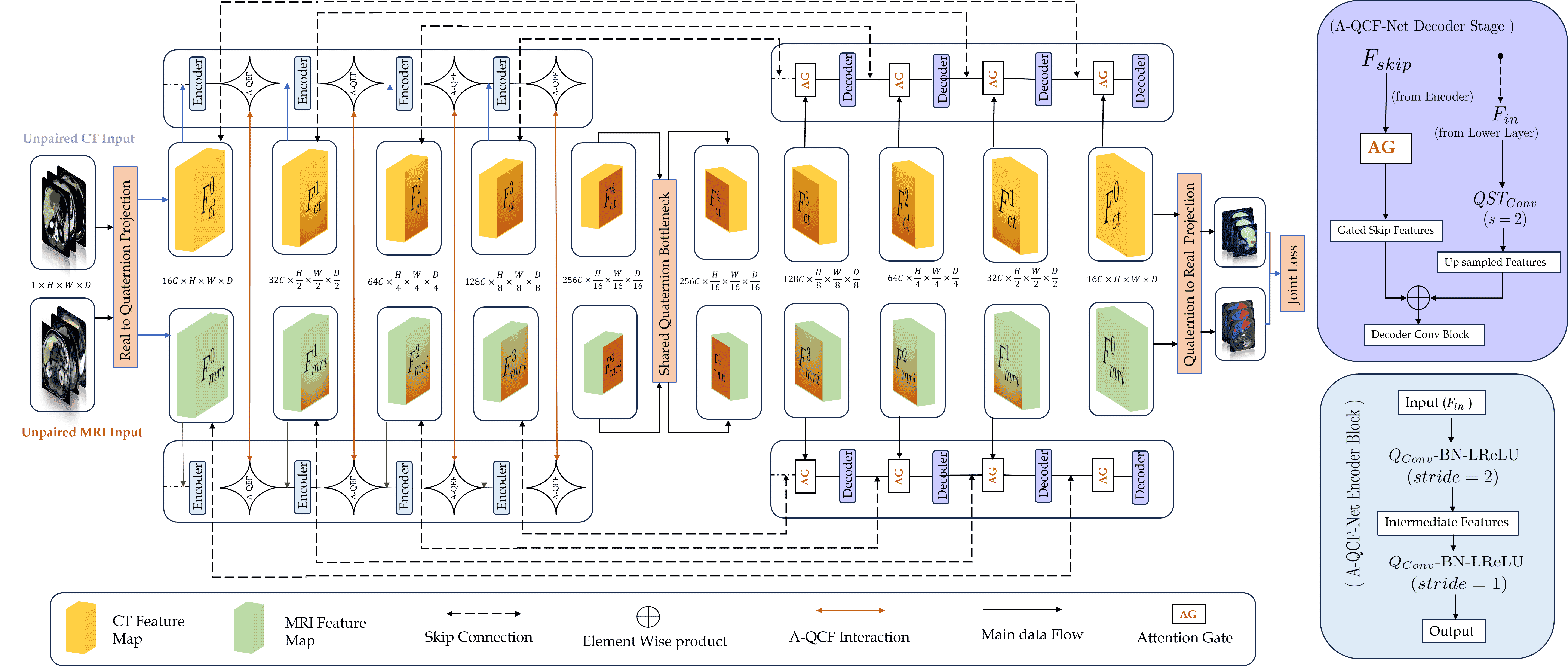
Cross-Fusion Network (A-QCF-Net) that learns a single unified segmentation model from
completely separate and unpaired CT and MRI cohorts. The architecture exploits the
parameter efficiency and expressive power of Quaternion Neural Networks to construct
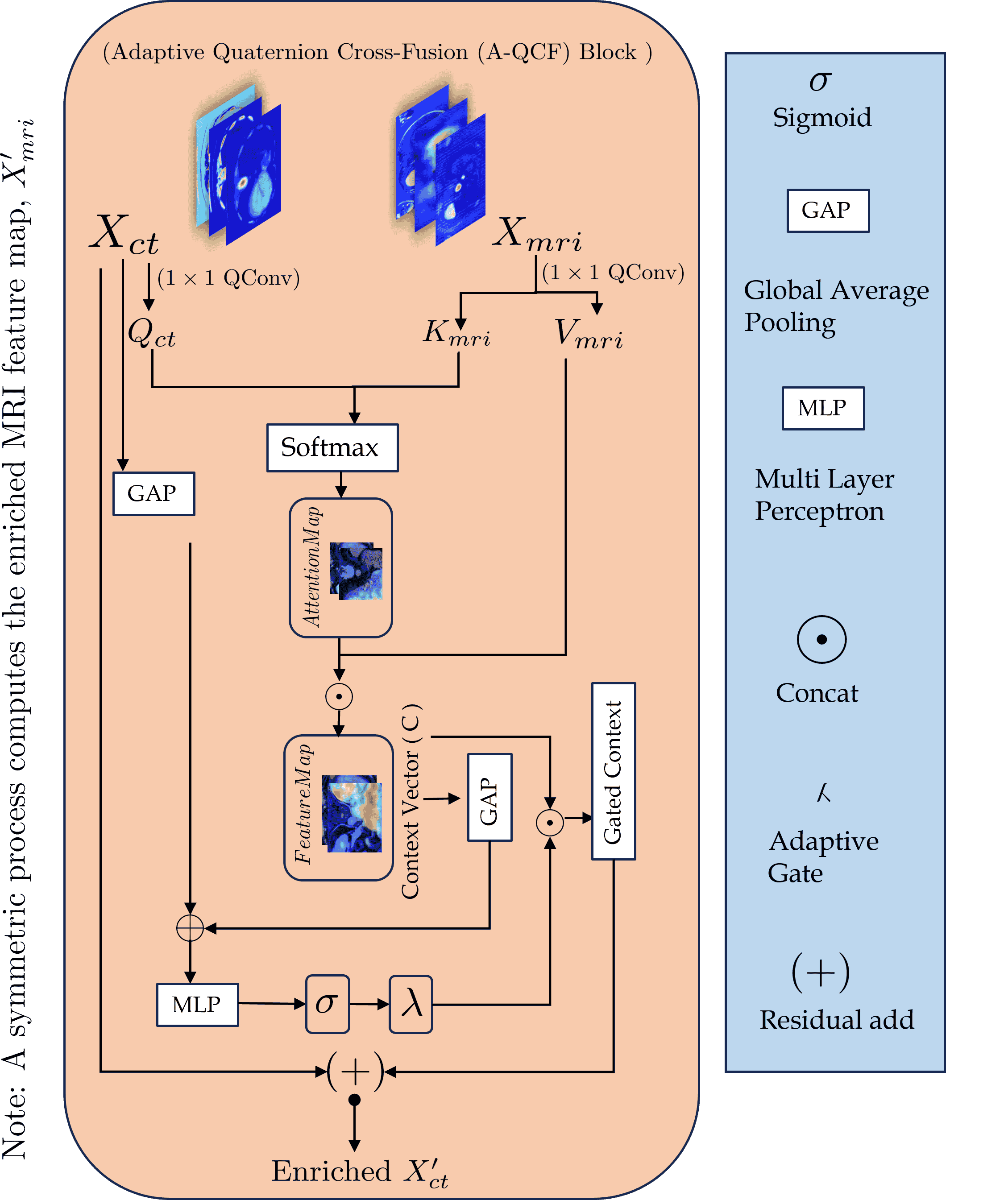
a shared feature space. At its core is the Adaptive Quaternion Cross-Fusion (A-QCF)
block, a data driven attention module that enables bidirectional knowledge transfer be-
tween the two streams. By learning to modulate the flow of information dynamically, the
A-QCF block allows the network to exchange abstract modality specific expertise, such
as the sharp anatomical boundary information available in CT and the subtle soft tissue
contrast provided by MRI. This mutual exchange regularizes and enriches the feature
representations of both streams. We validate the framework by jointly training a sin-
gle model on the unpaired LiTS (CT) and ATLAS (MRI) datasets. The jointly trained
model achieves Tumor Dice scores of 76.7% on CT and 78.3% on MRI, significantly ex-
ceeding the strong unimodal nnU-Net baseline by margins of 5.4% and 4.7% respectively.
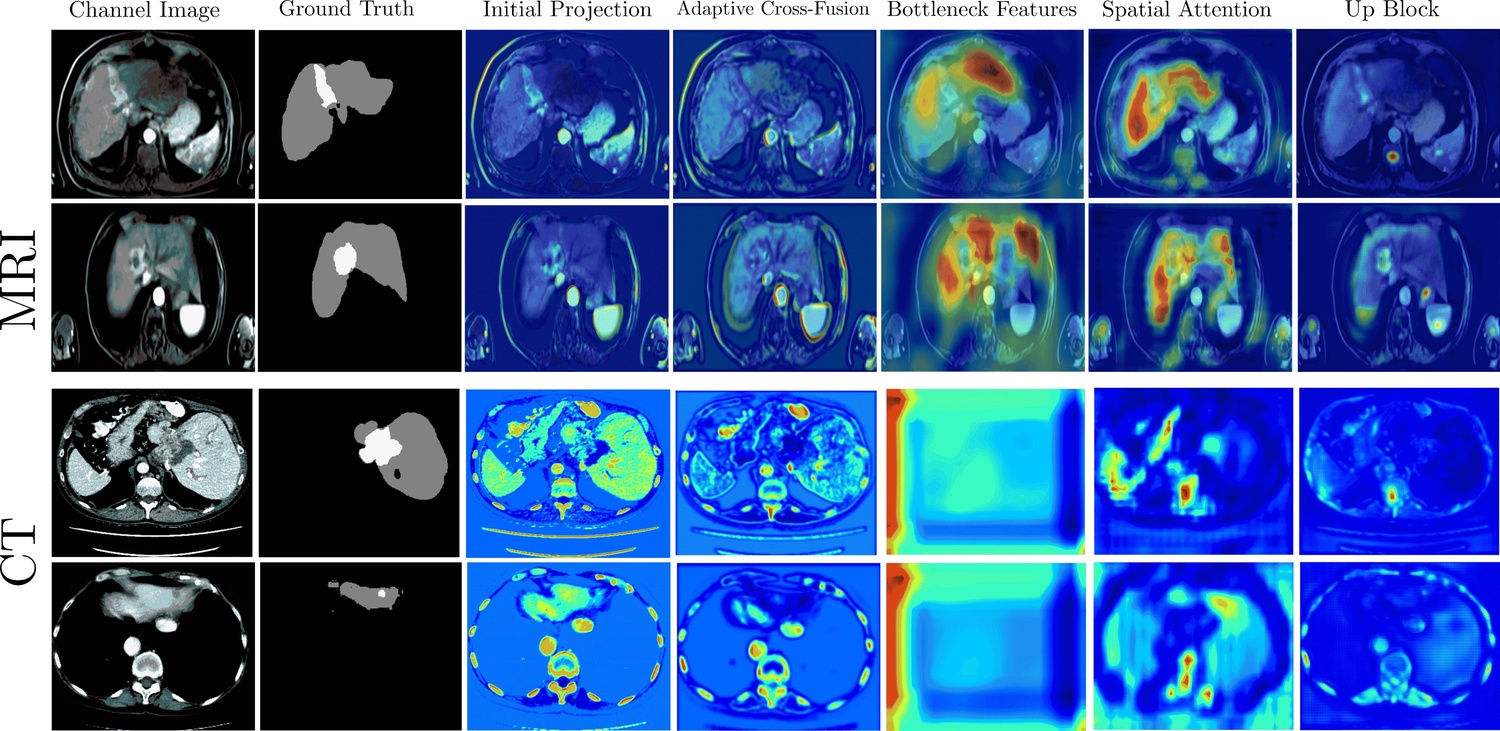
Furthermore, comprehensive explainability analysis using Grad-CAM and Grad-CAM++
confirms that the model correctly focuses on relevant pathological structures, ensuring
the learned representations are clinically meaningful. This provides a robust and clini-
cally viable paradigm for unlocking the large unpaired imaging archives that are common
in healthcare.
Keywords:
Cross-Attention, Deep Learning, Explainable AI, Grad-CAM, Medical
Image Segmentation, Multimodal Learning, Quaternion Neural Networks, Unpaired
Data
1. Introduction
Multimodal medical imaging, exemplified by Computed Tomography (CT) and Mag-
netic Resonance Imaging (MRI), provides complementary views that are clinically im-
portant for the diagnosis and delineation of complex pathologies such as liver tumors.
In the setting of hepatic malignancy, no single imaging modality captures all clinically
relevant information. Computed Tomography, with its submillimeter resolution, offers
excellent anatomical detail and is often preferred for visualizing sharp organ boundaries
arXiv:2512.21760v1 [cs.CV] 25 Dec 2025
and vascular structures (Heimann et al., 2009). However, its ability to distinguish subtle
variations in soft tissue, for example differentiating a necrotic tumor core from a viable
margin or identifying small isodense lesions, is limited. Magnetic Resonance Imaging, in
contrast, excels at soft tissue contrast and can reveal tumor textures and margins that are
often inconspicuous on CT (Gross et al., 2024). Different MRI sequences emphasize dis-
tinct biophysical properties, which supports more nuanced lesion characterization. MRI
is therefore superior for detecting small satellite lesions and for assessing tumor infiltra-
tion into the surrounding parenchyma. These properties suggest that a model capable of
integrating the structural clarity of CT with the textural sensitivity of MRI could reach
a level of precision and robustness that is not achievable with either modality alone. This
clinical motivation creates a clear need for advanced multimodal AI systems.
Most existing attempts to exploit unpaired cohorts follow an indirect strategy. They
first synthesize a missing modality, for example, CT to MRI or MRI to CT, and then
train a segmentation network on the generated images. Such a two stage pipeline ties the
final segmentation accuracy to the fidelity of the synthesis model and introduces the risk
that synthesis artifacts will propagate into the predicted masks. In this work, we follow
a more direct strategy: we learn segmentation from unpaired cohorts without generating
synthetic images, by encouraging the network to share modality invariant semantics at
the feature level during joint training. This removes the surrogate synthesis objective
and aligns optimization with the end segmentation task.
Despite the clear clinical motivation for multimodal learning, the dominant deep learn-
ing paradigm for multimodal fusion is severely constrained by data availability. Most cur-
rent methods assume access to large collections of paired and spatially aligned datasets,
in which individual patients