Monte Carlo Tree Search (MCTS) has profoundly influenced reinforcement learning (RL) by integrating planning and learning in tasks requiring long-horizon reasoning, exemplified by the AlphaZero family of algorithms. Central to MCTS is the search strategy, governed by a tree policy based on an upper confidence bound (UCB) applied to trees (UCT). A key factor in the success of AlphaZero is the introduction of a prior term in the UCB1-based tree policy PUCT, which improves exploration efficiency and thus accelerates training. While many alternative UCBs with stronger theoretical guarantees than UCB1 exist, extending them to prior-based UCTs has been challenging, since PUCT was derived empirically rather than from first principles. Recent work retrospectively justified PUCT by framing MCTS as a regularized policy optimization (RPO) problem. Building on this perspective, we introduce Inverse-RPO, a general methodology that systematically derives prior-based UCTs from any prior-free UCB. Applying this method to the variance-aware UCB-V, we obtain two new prior-based tree policies that incorporate variance estimates into the search. Experiments indicate that these variance-aware prior-based UCTs outperform PUCT across multiple benchmarks without incurring additional computational cost. We also provide an extension of the mctx library supporting variance-aware UCTs, showing that the required code changes are minimal and intended to facilitate further research on principled prior-based UCTs. Code: github.com/Max-We/inverse-rpo.
The combination of reinforcement learning (RL) with Monte Carlo Tree Search (MCTS) has led to major advances in artificial intelligence. Starting with Al-phaGo (Silver et al., 2016), and subsequently generalized by AlphaZero (Silver et al., 2018) and MuZero (Schrittwieser et al., 2020), this line of work has achieved superhuman performance across domains requiring long-horizon reasoning and complex decisionmaking. These results underscore the power of integrating learning with search-based planning, and they motivate ongoing efforts to develop more efficient and broadly applicable variants of MCTS and AlphaZerostyle methods.
A central component of MCTS is the tree policy, which balances exploration and exploitation to minimize regret. Before AlphaZero, such policies were derived from upper confidence bounds (UCBs) such as UCB1 (Auer et al.), giving rise to the well-studied family of UCT algorithms, which apply UCBs to tree search. Over time, many variants beyond UCB1 -including UCB-V, Bayesian UCT, and UCB1-Uniform/Power (Audibert et al., 2009;Tesauro et al., 2012;Asai and Wissow, 2024)-have been explored and shown to have a significant effect on the MCTS performance. With the AlphaZero family of algorithms, UCB1 was extended by incorporating a prior term estimated by a neural network, yielding PUCT. This prior-based extension of UCB1 greatly improved search efficiency in both small and large action spaces (Wu et al., 2023) and has since become the de facto standard tree policy. However, extending this prior-based approach to other UCBs has proven difficult. While the authors claim that PUCT is a variant of PUCB (Rosin, 2011), which in itself is an extension of UCB1 with contextual information, a complete proof was never presented. Indeed, the concrete form of PUCT deviates from UCB1 and PUCB by introducing a heuristic decay of the exploration term, and it is generally assumed to have been derived empirically rather than from formal guar-antees1 . We hypothesize that the extension of other UCBs to prior-based UCTs in the context of MCTS, although promising in theory, has been underexplored for that reason.
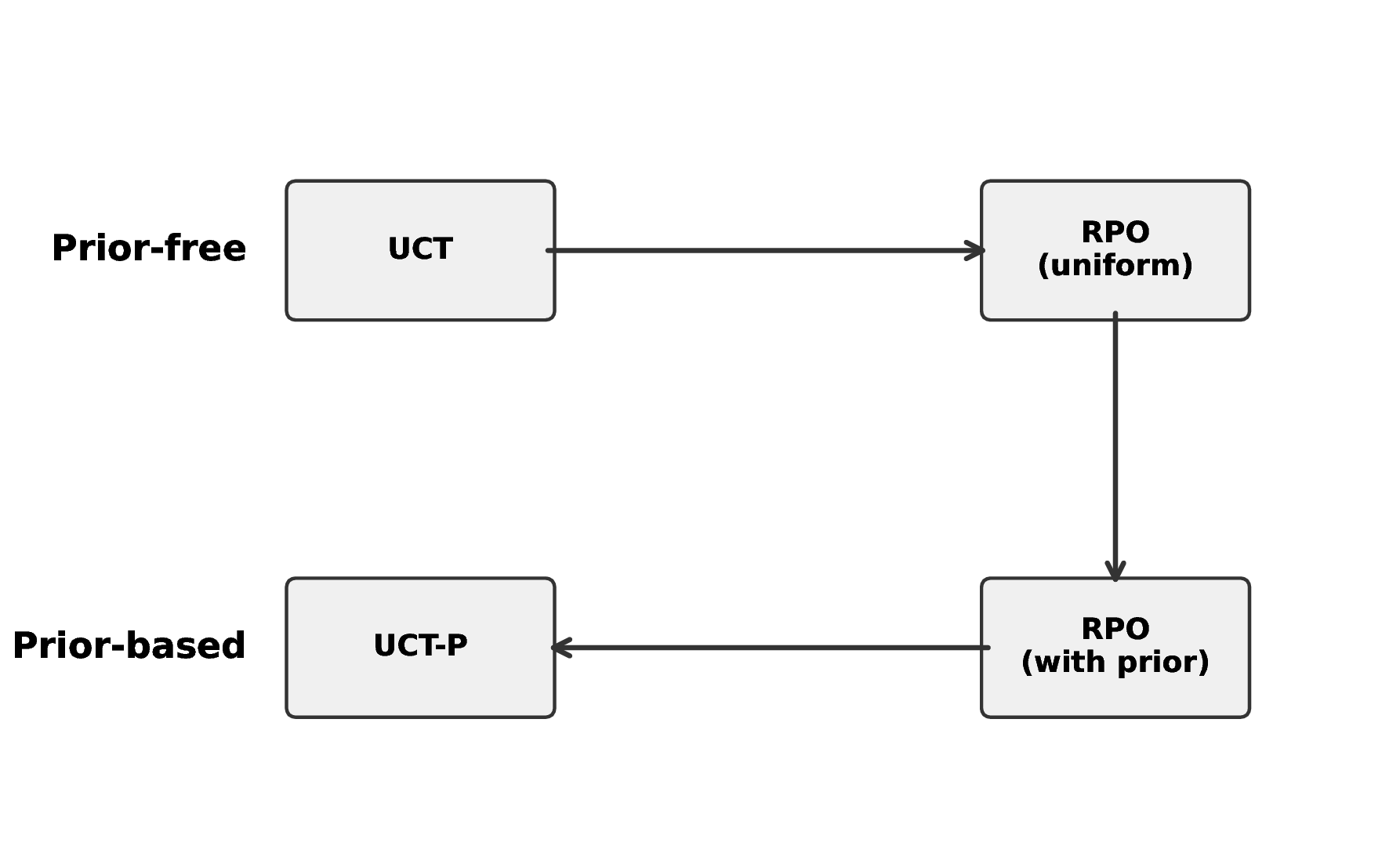
Table 1: Four prior-based UCT rules arranged by base UCB (columns) and heuristic form (rows). The heuristic form of the UCTs is described in Section 2.1. Our contributions are marked with *.
UCB1 UCB-V canonical form UCT-P UCT-V-P* heuristic form PUCT PUCT-V*
Recent work has reinterpreted MCTS as regularized policy optimization (RPO), showing that PUCT can be viewed as tracking the solution to a specific RPO.
Our key insight is that this perspective not only provides an understanding for the form of prior-based UCBs in hindsight, such as previously described for PUCT (Grill et al., 2020), but also the theoretical foundation needed to systematically derive any priorbased UCT directly from prior-free UCBs by expressing them as an RPO. Building on this insight, we continue to study prior-based UCTs beyond PUCT by extending other, potentially stronger, UCB-based policies with prior terms. More concretely, we make the following key contributions:
Inverse-RPO. We introduce Inverse-RPO, a principled, step-by-step method that transforms a UCB into its prior-based counterpart. Unlike prior work that starts from an already prior-based selector such as PUCT (Grill et al., 2020) our method derives a prior-based selector systematically from its prior-free base form (e.g., UCB1 ). While prior work provides the formal framework linking MCTS and UCTs to RPO (Grill et al., 2020), we rearrange and slightly extend this approach into an easy-to-follow methodology, enabling researchers to apply it directly to their UCB of choice in future work.
Variance-Aware Prior-Based UCTs.
To explore prior-based UCTs beyond PUCT, we instantiate Inverse-RPO on the variance-aware UCB-V to obtain two prior-based tree policies (see Table 1): (i) UCT-V-P, a principled RPO-derived variant; and (ii) PUCT-V, an heuristic analogue aligned with the practical form of PUCT. As experimental baselines, we compare these derived tree-policies against PUCT (the de facto choice in the AlphaZero family of algorithms), while also benchmarking against UCT-P ( Grill et al., 2020), which can be viewed as a prior-based UCB1 without the heuristic alterations introduced with PUCT.
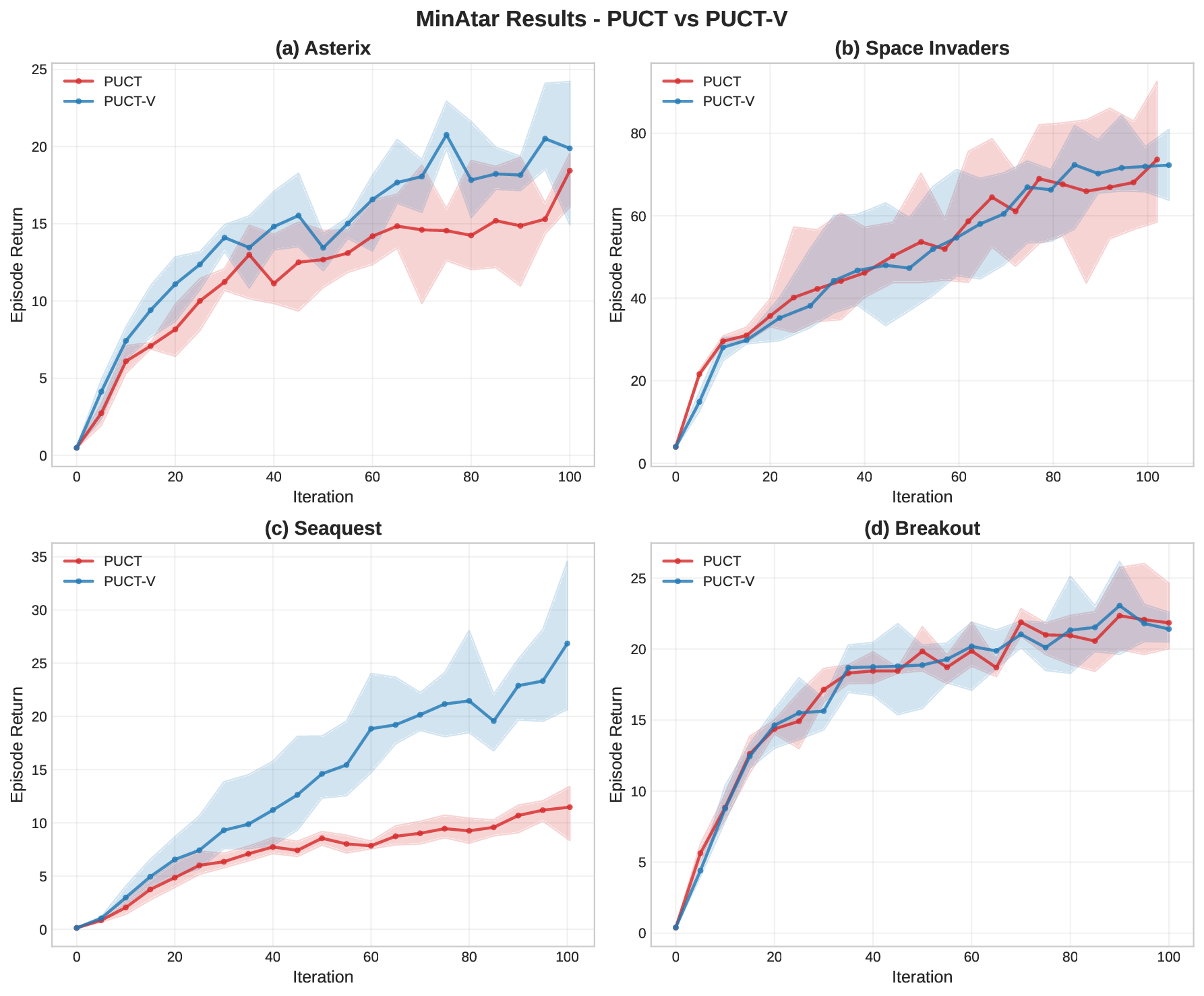
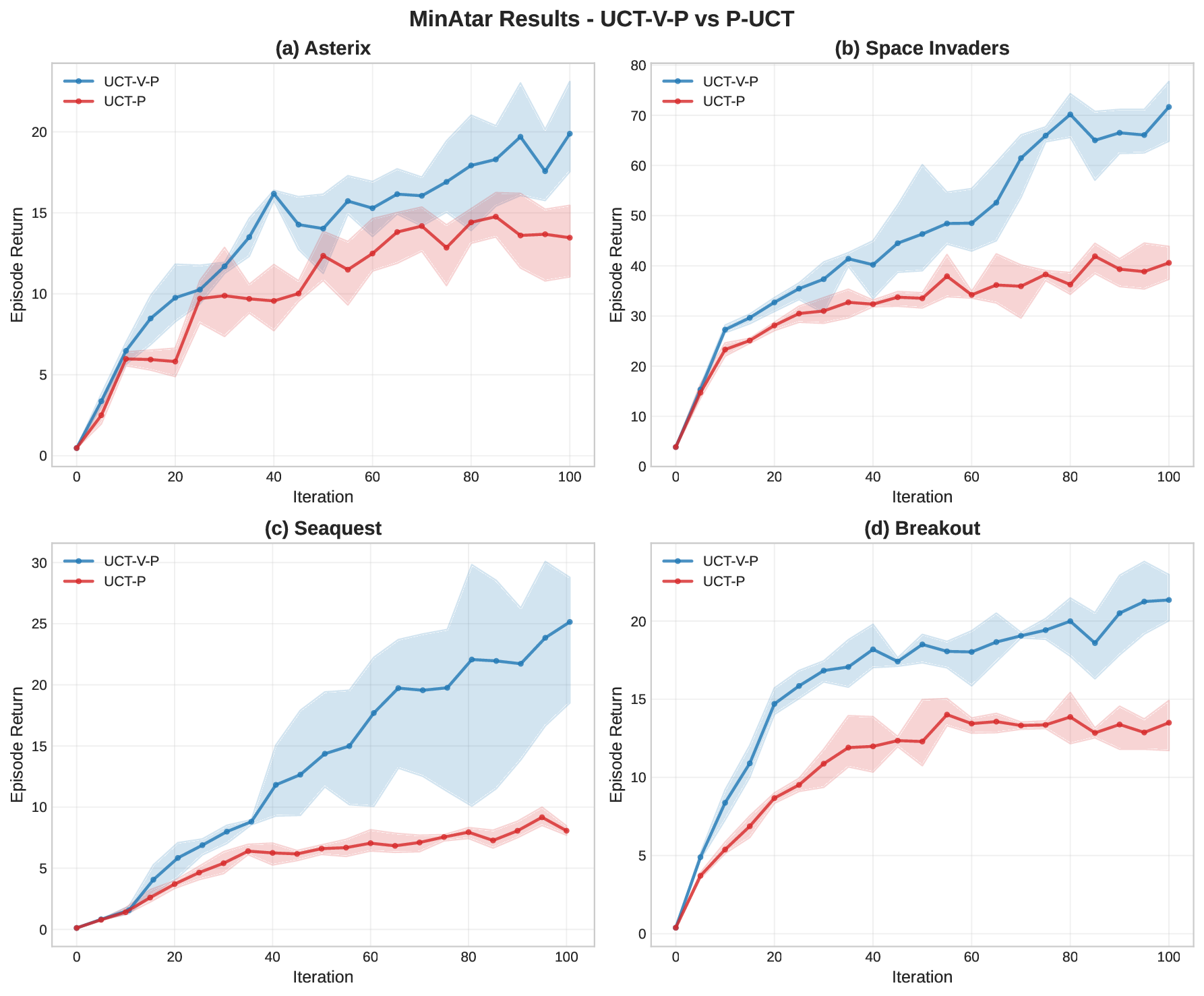
Empirical Validation and Implementation. Across a range of benchmark domains, we show that our variance-aware prior-based UCT-V-P and PUCT-V consistently match or outperform UCT-P and PUCT respectively, indicating that the benefits of replacing UCB1 with stronger UCBs such as UCB-V in MCTS extend naturally to the prior-based MCTS as in the AlphaZero family of algorithms. We further propose an efficient implementation strategy for variance-aware MCTS, demonstrating that the derived UCT-V-P and PUCT-V can be deployed in practice as easily as the commonly used PUCT and at no extra computational overhead.
Before presenting our methodology, we briefly review the key background conce
This content is AI-processed based on open access ArXiv data.