📝 Original Info Title: NVIDIA Nemotron 3: Efficient and Open IntelligenceArXiv ID: 2512.20856Date: 2025-12-24Authors: ** NVIDIA 연구팀 (구체적인 저자 명단은 논문 원문에 명시되어 있지 않음) **📝 Abstract We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
💡 Deep Analysis
📄 Full Content 2025-12-25
NVIDIA Nemotron 3: Efficient and Open
Intelligence
NVIDIA
Abstract
We introduce the Nemotron 3 family of models—Nano, Super, and Ultra. These models deliver strong
agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts
hybrid Mamba–Transformer architecture to provide best-in-class throughput and context lengths of
up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a
novel approach that improves model quality. The two larger models also include MTP layers for faster
text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement
learning enabling reasoning, multi-step tool use, and support granular reasoning budget control.
Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely
cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads
such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and
reasoning performance. Nano is released together with its technical report and this white paper,
while Super and Ultra will follow in the coming months. We will openly release the model weights,
pre- and post-training software, recipes, and all data for which we hold redistribution rights.
1. Introduction
We announce NVIDIA Nemotron 3, the most efficient family of open models with leading accuracy
for agentic AI applications. The Nemotron 3 family of models use a Mixture-of-Experts hybrid
Mamba-Transformer architecture that pushes the accuracy-to-inference-throughput frontier (§2.1).
State-of-the-art accuracy and high inference throughput enable developers to build and scale up
complex multi-agent environments. Further, the Nemotron 3 family of models support a context
length of up to 1M tokens which helps accelerate tasks that require long contexts like long slices of
code, large conversation histories, and extensive documents for RAG pipelines (§2.5). Nemotron
3 models support inference-time reasoning budget control (S2.7) and are trained using a diverse
set of RL environments. The diverse set of environments help Nemotron 3 models achieve superior
accuracy across a broad range of tasks like competitive coding, competition math, and agentic tool
use (§2.6).
In addition to the above, Nemotron 3 Super and Ultra are trained with NVFP4 (§2.4). Super and
Ultra utilize LatentMoE, a novel approach that helps gain accuracy without sacrificing inference
throughput or latency (§2.2). We also incorporate MTP layers in the two larger models to improve
the efficiency of long-form text generation workloads (Gloeckle et al., 2024). Additionally, training
with MTP provides modest improvements in model quality (DeepSeek-AI, 2025b) (§2.3).
The Nemotron 3 family of models are open and transparent. We will release all the model weights,
over 10 trillion tokens of datasets, and training recipes.
In the following section, we discuss the key technologies used to build Nemotron 3.
© 2025 NVIDIA. All rights reserved.
arXiv:2512.20856v1 [cs.CL] 24 Dec 2025
NVIDIA Nemotron 3: Efficient and Open Intelligence
Nemotron-3-Nano-30B-A3B
MoE
Mamba-2
Mamba-2
MoE
Mamba-2
Attention
MoE
Mamba-2
MoE
x5
x3
Mamba-2
Attention
MoE
x1
Mamba-2
MoE
x4
Figure 1 | Nemotron 3 models (e.g., Nemotron Nano 3) leverage a hybrid Mamba-Transformer MoE
architecture consisting predominantly of interleaved Mamba-2 and MoE layers, with a select few self
attention layers.
Arena-Hard-v2-Avg
(Chat)
AIME25
(Math)
IFBench
(Inst. Following)
2-Bench
(Tool Use)
SWE-Bench
(Coding)
LCB v6
(Coding)
RULER @ 1M
(Long Ctx)
ISL/OSL
8k/16k
0
20
40
60
80
100
Accuracy (%)
67.7
89.1
99.2
71.5
49.0
38.8
68.2
86.3
57.8
85.0
51.0
47.7
22.0
66.0
77.5
48.5
91.7
98.7
65.0
47.5
34.0
61.0
N/A
+tools:
Accuracy
Throughput
Nemotron-3-Nano-30B-A3B
Qwen3-30B-A3B-Thinking-2507
GPT-OSS-20B-A4B
0
1
2
3
4
5
6
7
8
Relative Throughput (Output tokens/s/GPU)
3.3
1.0
1.5
Figure 2 | The hybrid Mamba-Transformer MoE architecture used by Nemotron 3 models can
achieve state-of-the-art accuracy on leading reasoning benchmarks and ultra-long-context tasks while
providing throughput improvements over similarly sized Transformer MoEs. For details, please see
the Nemotron Nano 3 technical report.
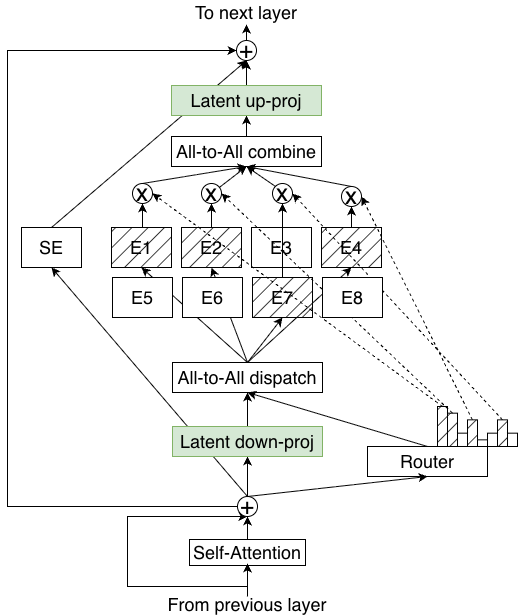
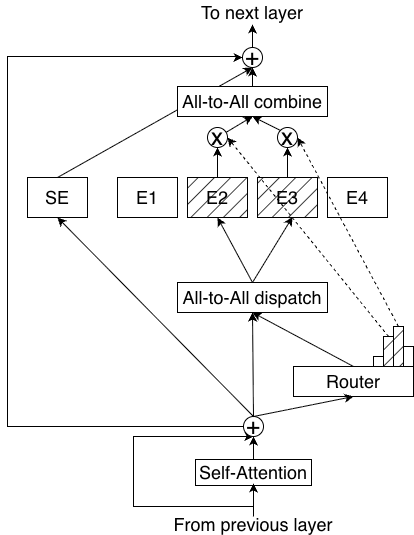
2. Features and Technologies
2.1. Hybrid MoE
The Nemotron 3 family of models utilize a hybrid Mamba-Transformer MoE architecture. This
architecture is chosen with inference efficiency in mind, particularly for reasoning workloads, but
also provides better or on-par accuracy compared to standard Transformers (Waleffe et al., 2024;
NVIDIA, 2025b,a).
Specifically, rather than interleaving mixture-of-expert (MoE) layers with
expensive self-attention layers—which need to attend over a linearly increasing KV Cache during
generation—Nemotron 3 models predominantly interleave MoE layers with cheaper Mamba-2
layers (Dao & Gu, 2024)—which require storing only a constant state during generation. Only a
📸 Image Gallery
Reference This content is AI-processed based on open access ArXiv data.