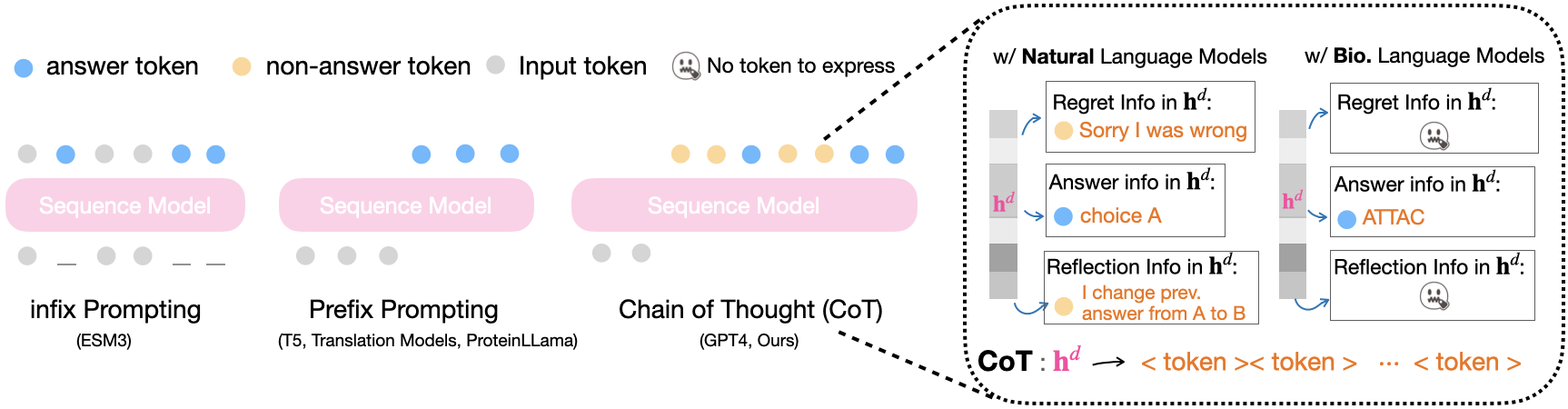
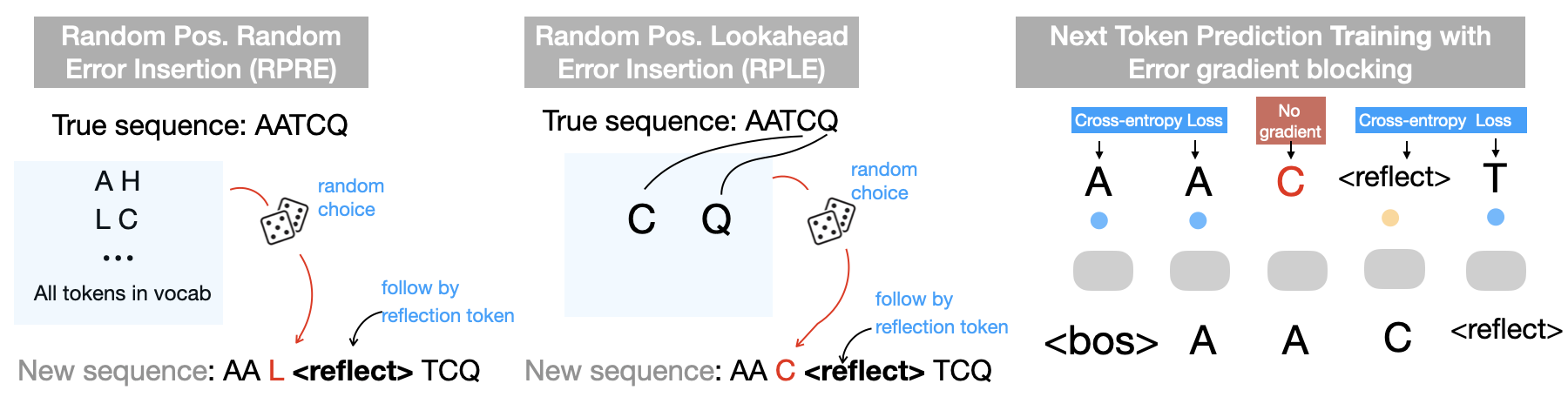
Chain-of-Thought (CoT) prompting has significantly advanced task-solving capabilities in natural language processing with large language models. Unlike standard prompting, CoT encourages the model to generate intermediate reasoning steps, non-answer tokens, that help guide the model toward more accurate final outputs. These intermediate steps enable more complex reasoning processes such as error correction, memory management, future planning, and self-reflection. However, applying CoT to non-natural language domains, such as protein and RNA language models, is not yet possible, primarily due to the limited expressiveness of their token spaces (e.g., amino acid tokens). In this work, we propose and define the concept of language expressiveness: the ability of a given language, using its tokens and grammar, to encode information. We show that the limited expressiveness of protein language severely restricts the applicability of CoT-style reasoning. To overcome this, we introduce reflection pretraining, for the first time in a biological sequence model, which enables the model to engage in intermediate reasoning through the generation of auxiliary "thinking tokens" beyond simple answer tokens. Theoretically, we demonstrate that our augmented token set significantly enhances biological language expressiveness, thereby improving the overall reasoning capacity of the model. Experimentally, our pretraining approach teaches protein models to self-correct and leads to substantial performance gains compared to standard pretraining.
Reflection Pretraining Enables Token-Level
Self-Correction in Biological Sequence Models
Xiang Zhang1,3∗, Jiaqi Wei2,4∗, Yuejin Yang2, Zijie Qiu1,2,
Yuhan Chen2, Zhiqiang Gao2, Muhammad Abdul-Mageed3,
Laks V. S. Lakshmanan3, Wanli Ouyang5, Chenyu You6, Siqi Sun1,2
1Fudan University
2Shanghai Artificial Intelligence Laboratory
3University of British Columbia
4Zhejiang University
5 The Chinese University of Hong Kong
6 Stony Brook University
xzhang23@ualberta.ca, siqisun@fudan.edu.cn
* Equal Contribution
Abstract
Chain of Thought (CoT) prompting has significantly advanced task-solving ca-
pabilities in Natural Language Processing with LLMs. Unlike standard prompt-
ing, CoT encourages the model to generate intermediate reasoning steps—non-
answer tokens—that help guide the model toward more accurate final outputs.
These intermediate steps enable more complex reasoning processes such as error
correction, memory management, future planning, and self-reflection. Under ap-
propriate assumptions, an autoregressive Transformer augmented with natural
language (e.g., English) based CoT can, in theory, achieve Turing completeness,
as demonstrated in prior work. However, applying CoT to non-natural language
domains, such as protein and RNA language models, is not yet possible—primarily
due to the limited expressiveness of their token spaces (e.g., amino acid tokens).
In this work, we propose and define the concept of language expressiveness, the
ability of a given language using its tokens as well as its grammar to encode various
information. We show that the limited expressiveness of protein language severely
restricts the applicability of CoT-style reasoning. To overcome this, we introduce
reflection pretraining—for the first time in a biological sequence model—which
enables the biological model to engage in intermediate reasoning through the gen-
eration of auxiliary “thinking tokens” beyond simple answer tokens. Theoretically,
we demonstrate that our augmented token set significantly enhances the biological
language expressiveness, thereby improving the overall reasoning capacity of the
model. Experimentally, our novel pretraining approach teaches protein models
to self-correct and leads to substantial performance gains compared to standard
pre-training. Finally, we show that reflection training brings unique advantages,
such as improved resistance to overfitting (i.e., counter-memorization) and en-
hanced human steer-ability—enabling users to interfere/interact with the protein
generation—thus bridging the gap between biological language models and human
natural language models. All code, trained model weights, and result outputs
are publicly available on our GitHub repository. Detailed theoretical analysis,
discussions on model expressiveness, extensive experimental results, and related
work section are provided in the Appendix.
1
Introduction
Deep learning [1] has significantly advanced the field of biology, with an increasing number of
neural models being trained to generate and predict biological sequences such as DNA[2–5], RNA [6–
8], and proteins [9–19, 18, 20–26]. However, current biological sequence-generation models are
Preprint.
arXiv:2512.20954v1 [cs.CL] 24 Dec 2025
constrained to produce only answer tokens directly related to specific tasks (e.g., drug design,
de novo sequencing [27–29]). This generation paradigm mirrors conventional natural language
processing models [30], where outputs are limited to final answers without intermediate reasoning
or deliberation.1 Recent work [31–33] has demonstrated that this answer-only generation approach
is suboptimal, both in terms of theoretical expressiveness and empirical performance. While a full
theoretical analysis is provided in the Appendix, the core intuition is straightforward: solving complex
tasks, especially those requiring reasoning, often involves iterative exploration, including trial-and-
error, partial hypotheses, and even initial incorrect outputs before arriving at a final solution. Models
constrained to generate only final answers are fundamentally incapable of performing this kind of
structured, exploratory computation and thus fail to handle complex solution discovery effectively.
Chain-of-Thought (CoT) [31, 34] prompting fundamentally changes how answers are generated in
natural language models. Traditional neural models directly map an input sequence to a sequence of
answer tokens, expressed as: xi : xn ⇒
· · · .
In contrast, CoT introduces interleaved non-answer tokens that enable intermediate reasoning [31]:
xi : xn ⇒ [non-answer1][non-answer2] · · · [non-answerk] .
Although these non-answer tokens are discarded in the final output, they significantly enhance the
model’s capabilities by enabling it to store intermediate memory, perform iterative computation,
correct earlier errors, and reason across multiple steps.
This augmentation enables natural language (e.g. English) models toThis content is AI-processed based on open access ArXiv data.