Full parameter fine tuning is a key technique for adapting large language models (LLMs) to downstream tasks, but it incurs substantial memory overhead due to the need to cache extensive intermediate activations for backpropagation. This bottleneck makes full fine tuning of contemporary large scale LLMs challenging in practice. Existing distributed training frameworks such as DeepSpeed alleviate this issue using techniques like ZeRO and FSDP, which rely on multi GPU memory or CPU offloading, but often require additional hardware resources and reduce training speed. We introduce RevFFN, a memory efficient fine tuning paradigm for mixture of experts (MoE) LLMs. RevFFN employs carefully designed reversible Transformer blocks that allow reconstruction of layer input activations from outputs during backpropagation, eliminating the need to store most intermediate activations in memory. While preserving the expressive capacity of MoE architectures, this approach significantly reduces peak memory consumption for full parameter fine tuning. As a result, RevFFN enables efficient full fine tuning on a single consumer grade or server grade GPU.
In recent years, Large Language Models (LLMs) such as GPT-4 [1], LLaMA [2], and Qwen [3] have achieved revolutionary advancements in Natural Language Processing and multimodal domains. The inherent scalability of the Transformer architecture [4,5] implies that, under similar designs, larger models typically exhibit superior generalization and reasoning capabilities. However, when adapting these models to specific downstream tasks via full fine-tuning, conventional training methods encounter a severe memory bottleneck. The root of this problem lies in the backpropagation-based optimization algorithms central to modern deep learning frameworks. For instance, the widely-used Adam optimizer [6][7][8] requires caching the activations from every layer during the forward pass to compute gradients. The size of these activations scales proportionally with model parameter count and batch size, resulting in a prohibitive memory footprint for LLMs with billions or even hundreds of billions of parameters. To surmount this challenge, researchers have proposed various memory optimization techniques. Memory sharding and offloading, exemplified by DeepSpeed's ZeRO [9] and PyTorch's FSDP, effectively reduce the VRAM pressure on a single GPU by distributing the model across multiple GPUs or offloading them to host DRAM. However, such methods do not decrease the total memory required; instead, they introduce significant inter-device data communication, demanding high bus bandwidth and leading to an reduction in training speed. An alternative approach is Parameter-Efficient Fine-Tuning (PEFT), such as LoRA, which drastically cuts memory usage by training only a small set of adapter parameters, but at the expense of the potential performance gains from a full parameter update. This brings a core challenge to the forefront: can we design a novel Transformer module that, at the cost of a modest increase in computation, fundamentally eliminates the need to store most activations, thereby revolutionizing memory efficiency?
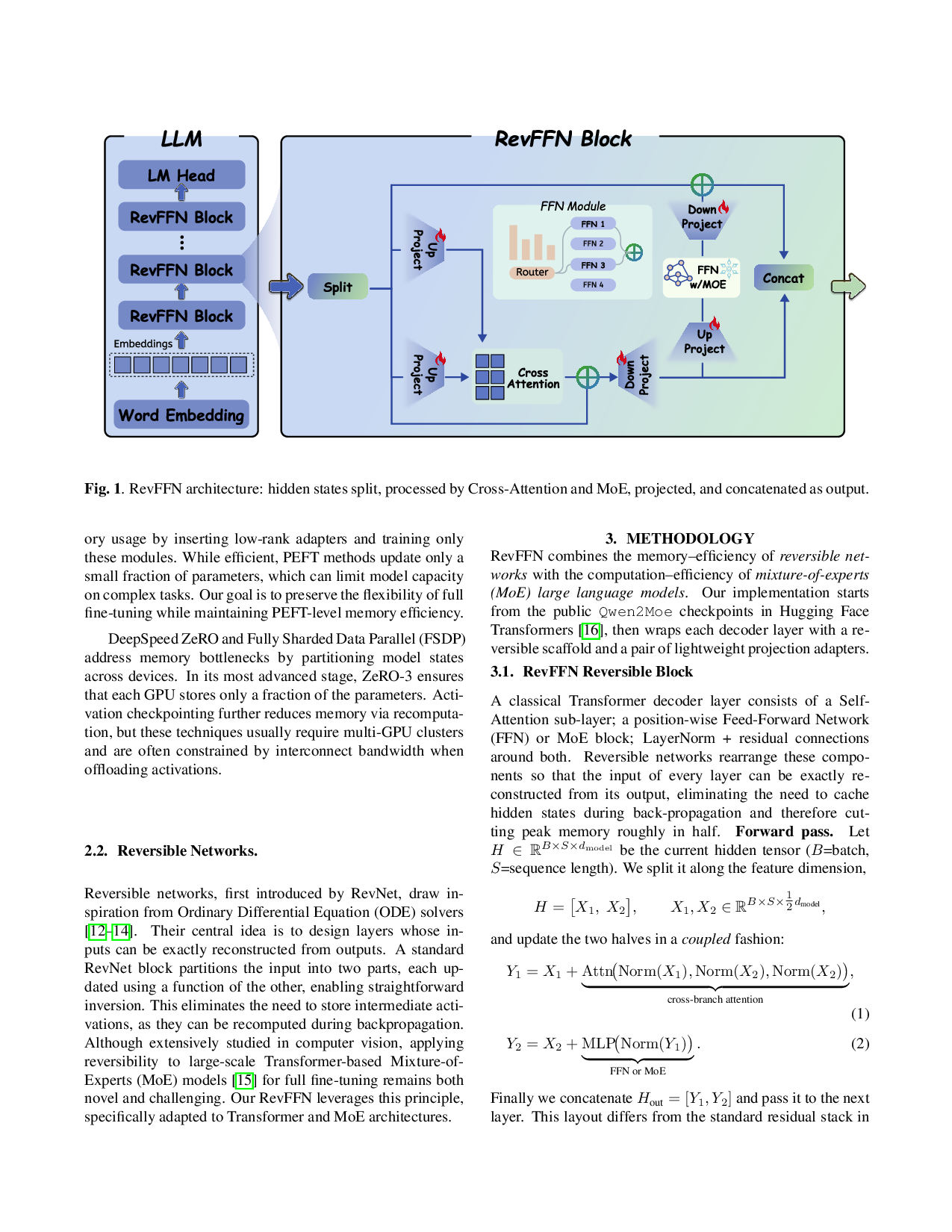
To solve this challenge, we introduce RevFFN, a Transformer block architected on the principles of reversible networks. RevFFN partitions the hidden state of a standard Transformer layer into two streams and processes them through a unique coupled update rule. This design guarantees that the input to the block can be precisely derived from its output, allowing for the dynamic recomputation of activations during the backward pass without prior caching. We implement our method on the Qwen1.5-MoE model, designing learnable projection layers to adapt pre-trained weights while fully preserving the MoE structure. Experiments show that RevFFN enables full-parameter fine-tuning of LLMs on a single GPU with lower memory overhead and better performance than PEFT methods.
LoRA [10] and its variants (e.g., QLoRA [11]) exemplify parameter-efficient fine-tuning (PEFT), achieving low mem- ory usage by inserting low-rank adapters and training only these modules. While efficient, PEFT methods update only a small fraction of parameters, which can limit model capacity on complex tasks. Our goal is to preserve the flexibility of full fine-tuning while maintaining PEFT-level memory efficiency.
DeepSpeed ZeRO and Fully Sharded Data Parallel (FSDP) address memory bottlenecks by partitioning model states across devices. In its most advanced stage, ZeRO-3 ensures that each GPU stores only a fraction of the parameters. Activation checkpointing further reduces memory via recomputation, but these techniques usually require multi-GPU clusters and are often constrained by interconnect bandwidth when offloading activations.
Reversible networks, first introduced by RevNet, draw inspiration from Ordinary Differential Equation (ODE) solvers [12][13][14]. Their central idea is to design layers whose inputs can be exactly reconstructed from outputs. A standard RevNet block partitions the input into two parts, each updated using a function of the other, enabling straightforward inversion. This eliminates the need to store intermediate activations, as they can be recomputed during backpropagation. Although extensively studied in computer vision, applying reversibility to large-scale Transformer-based Mixture-of-Experts (MoE) models [15] for full fine-tuning remains both novel and challenging. Our RevFFN leverages this principle, specifically adapted to Transformer and MoE architectures.
RevFFN combines the memory-efficiency of reversible networks with the computation-efficiency of mixture-of-experts (MoE) large language models. Our implementation starts from the public Qwen2Moe checkpoints in Hugging Face Transformers [16], then wraps each decoder layer with a reversible scaffold and a pair of lightweight projection adapters.
A classical Transformer decoder layer consists of a Self-Attention sub-layer; a position-wise Feed-Forward Network (FFN) or MoE block; LayerNorm + residual connections around both. Reversible networks rearrange these comp
This content is AI-processed based on open access ArXiv data.