Human infants, with only a few hundred hours of speech exposure, acquire basic units of new languages, highlighting a striking efficiency gap compared to the data-hungry self-supervised speech models. To address this gap, this paper introduces SpidR-Adapt for rapid adaptation to new languages using minimal unlabeled data. We cast such low-resource speech representation learning as a meta-learning problem and construct a multi-task adaptive pre-training (MAdaPT) protocol which formulates the adaptation process as a bi-level optimization framework. To enable scalable meta-training under this framework, we propose a novel heuristic solution, first-order bi-level optimization (FOBLO), avoiding heavy computation costs. Finally, we stabilize meta-training by using a robust initialization through interleaved supervision which alternates self-supervised and supervised objectives. Empirically, SpidR-Adapt achieves rapid gains in phonemic discriminability (ABX) and spoken language modeling (sWUGGY, sBLIMP, tSC), improving over in-domain language models after training on less than 1h of target-language audio, over $100\times$ more data-efficient than standard training. These findings highlight a practical, architecture-agnostic path toward biologically inspired, data-efficient representations. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr-adapt.
Human infants demonstrate a remarkable capacity for language acquisition: at under 6-months of age, they begin distinguishing phonemic contrasts and rapidly internalize the structure of their native language (Werker and Tees, 1984;Kuhl, 2004;Eimas et al., 1971), all from continuous auditory input and with only 100 to 500 hours of speech exposure (Bergelson et al., 2019;Cychosz et al., 2021).
In contrast, current self-supervised learning (SSL) models such as HuBERT (Hsu et al., 2021) and WavLM (Chen et al., 2022) require thousands of hours of training data to learn meaningful linguistic representations, and even then, their learned units are brittle-sensitive to acoustic and contextual variability (Gat et al., 2023;Hallap et al., 2023). When used as the basis for spoken language models (SLMs), these representations lead to limited language modeling performance compared to textbased systems (Hassid et al., 2023;Lakhotia et al., 2021) and far worse than the learning trajectories of human infants (Bergelson and Swingley, 2012).
A key reason for this discrepancy lies in inductive biases-infants begin with strong predispositions for speech perception, such as sensitivity to phones, rhythmic regularities, and speakerinvariance (Werner, 2007;Kuhl, 2004). These biases constrain learning to plausible linguistic structures, enabling rapid generalization from sparse input. By contrast, most machine learning systems are initialized from random weights and rely solely on statistical regularities of massive datasets. Without built-in inductive priors, they fail to discover linguistic abstractions of new languages efficiently.
To move toward the inductive efficiency of human learners, we propose a fast-adaptive selfsupervised framework for speech representation learning including three broad components:
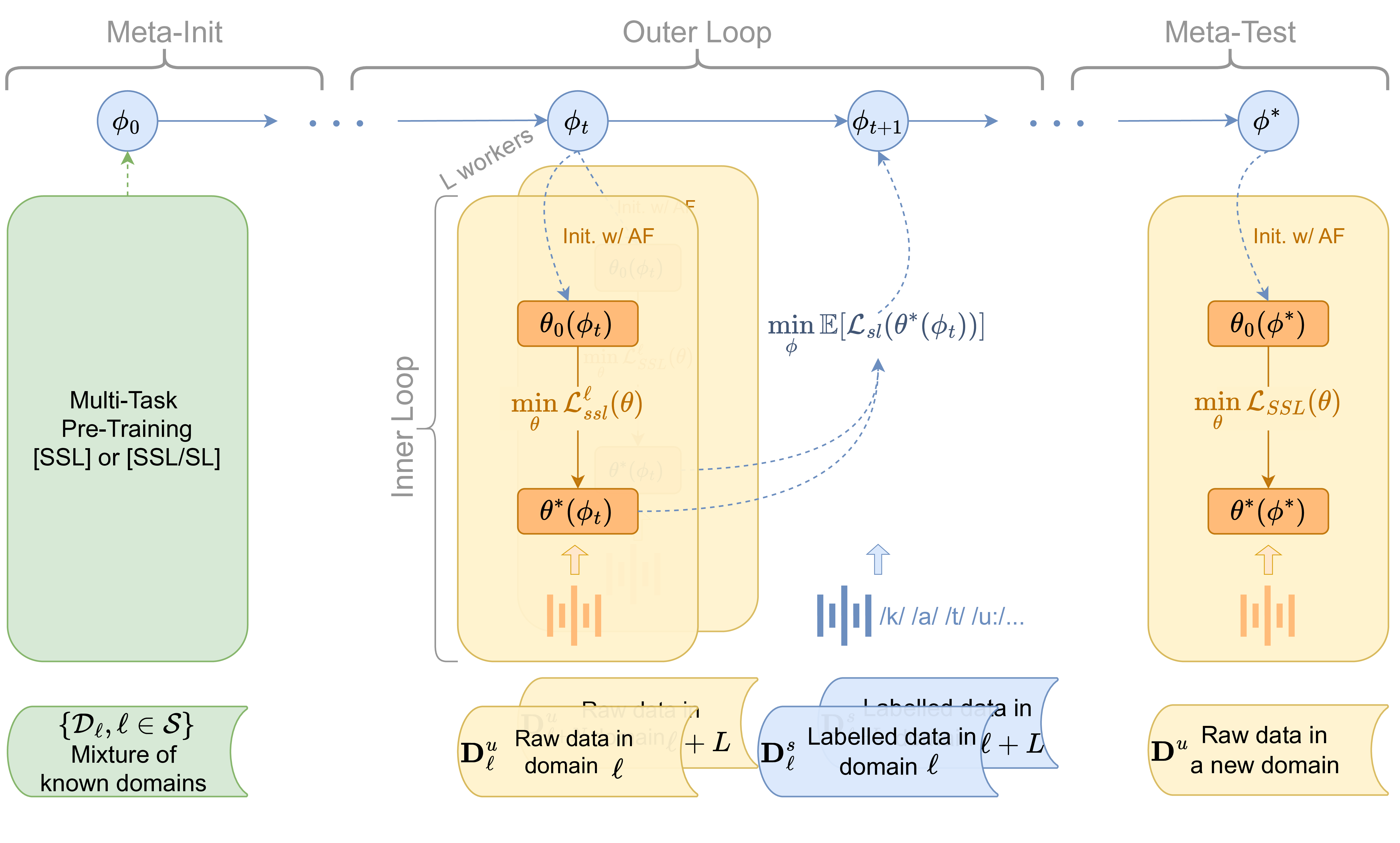
• Multi-task Adaptive Pre-training (MAdaPT), a novel protocol that frames model learning as a bi-level optimization problem. The model is meta-optimized across several data-scarce adaptation episodes, each simulating a “lifetime” of low-resource language learning. Intuitively, this episodic design draws inspiration from evolutionary processes, with a second-order optimization occurring at an outer, population-like level that shapes the model’s inductive biases over generations. To further encourage cross-lingual abstraction, we introduce controlled active forgetting between episodes, resetting key model components to simulate the onset of a new “lifetime,” thereby promoting robust, transferable representations.
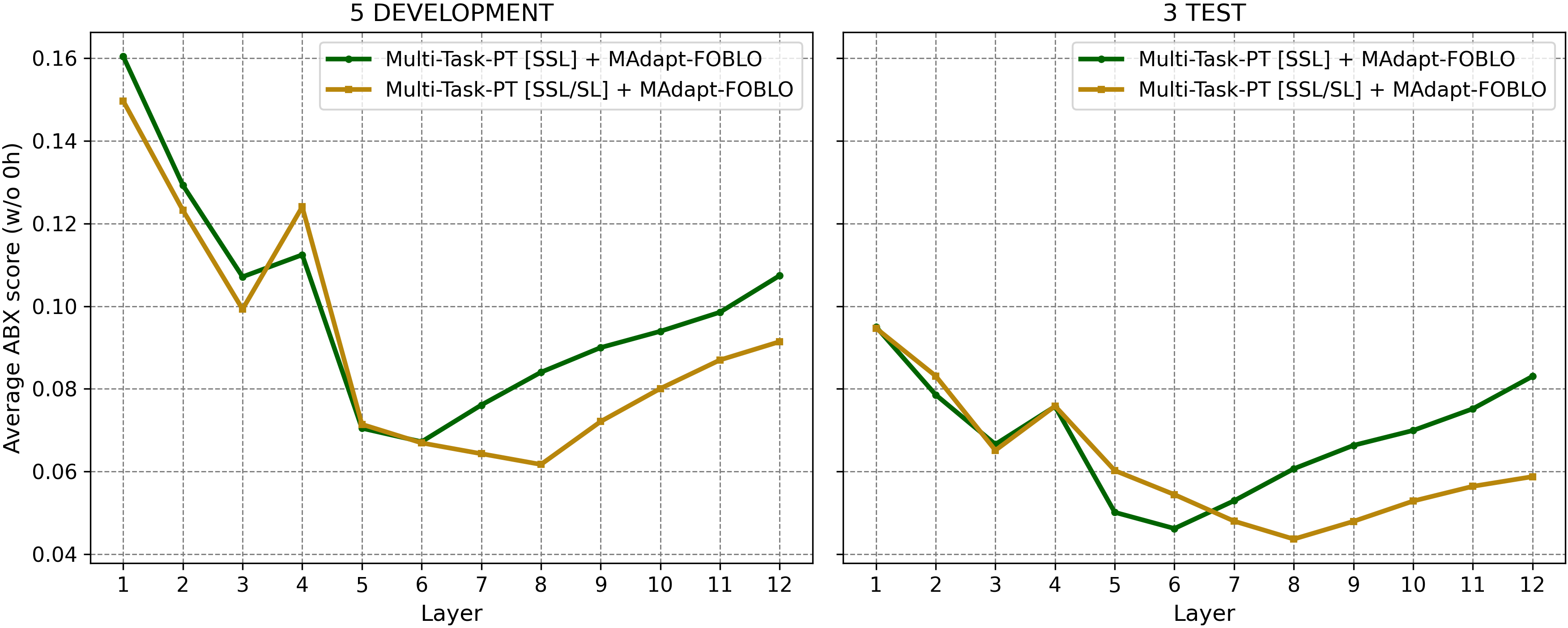
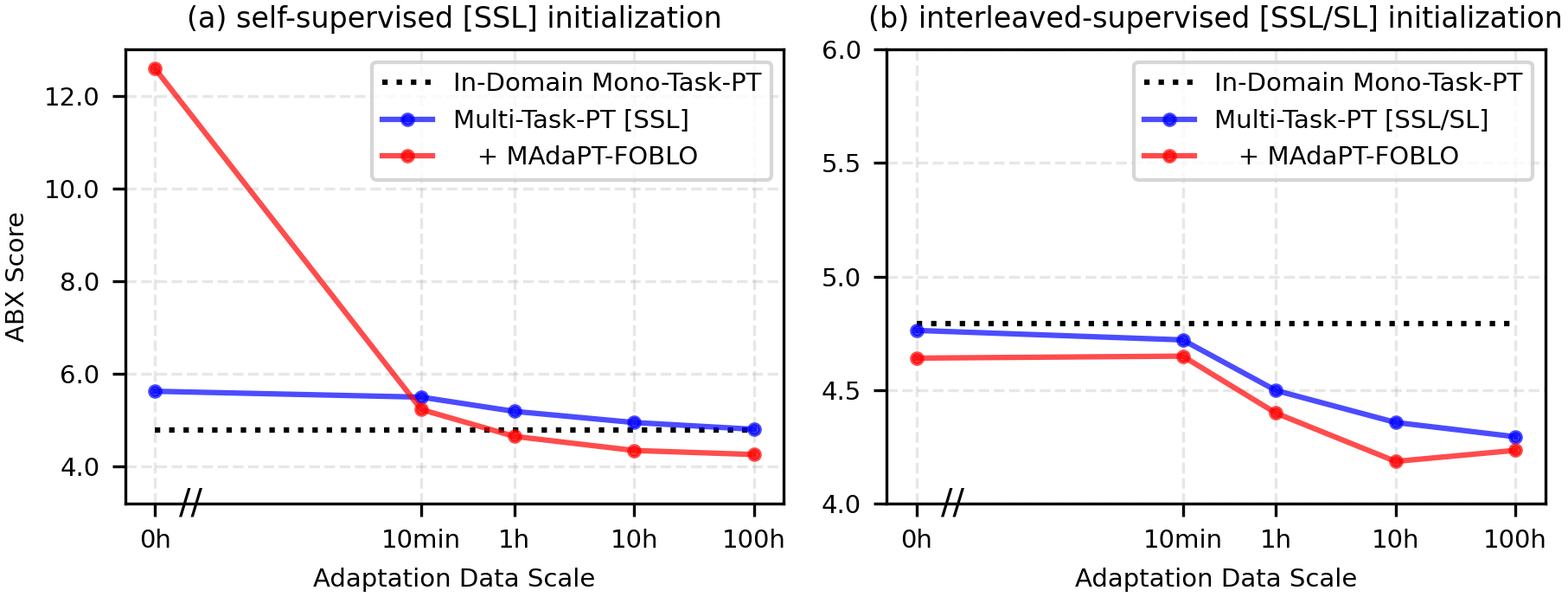
• First Order Bi-level Optimization (FOBLO), a meta-optimization heuristic that efficiently solves the second-order bi-level problem posed by MAdaPT. It trains the model to learn from unlabeled, under-resourced data in the inner-loop, with the outer-loop calibrating meta-parameters through feedback from a gold-standard labeled set. • Interleaved supervision, which incorporates self-supervised training with occasional phoneme supervised steps, yielding an initialization that imitates human-robustness to contextual-and acoustic-variations of speech while being label-efficient. Together, these mechanisms produce a model that achieves performance comparable to SSL systems trained on 6,000 hours of language data, despite seeing only 10 minutes to 100 hours of data in the target language. We further demonstrate that the resulting fast-adaptive model learns speech representations of an unseen language significantly faster than standard multi-task training.
We build on SpidR (Poli et al., 2025b), a speech SSL model that achieves state-of-the-art (SOTA) performance on phonemic discrimination and SLM metrics with efficient training. Our framework extends SpidR with the above fast-adaptive components, yielding SpidR-Adapt. Although our current implementation of MAdaPT-FOBLO uses SpidR as the backbone and focuses on speech representation, our framework is architecture-agnostic and broadly applicable to self-supervised models.
Our results demonstrate a step toward biologically inspired, data-efficient speech representation learning. Our paper makes three broad contributions: (1) Methodologically, we introduce MAdaPT, a general meta-training protocol that structures training as a series of episodes, each mirroring the low-resource language adaptation scenario.
The approach naturally formulates the adaptation process as a bi-level optimization problem. (2) Technically, we propose FOBLO, a novel heuristic solution to the bi-level optimization challenge formulated by MAdaPT. Additionally, we introduce interleaved supervision as a complementary strategy to build stronger model initializations for meta-training. (3) Empirically, we conduct comprehensive experiments, including comparisons with alternative meta-learning heuristics (Reptile), demonstrating that the combination of MAdaPT and FOBLO consistently achieves superior performance, on par with in-domain language training.
2 Related Works 2.1 Self-supervised learning Self-
This content is AI-processed based on open access ArXiv data.