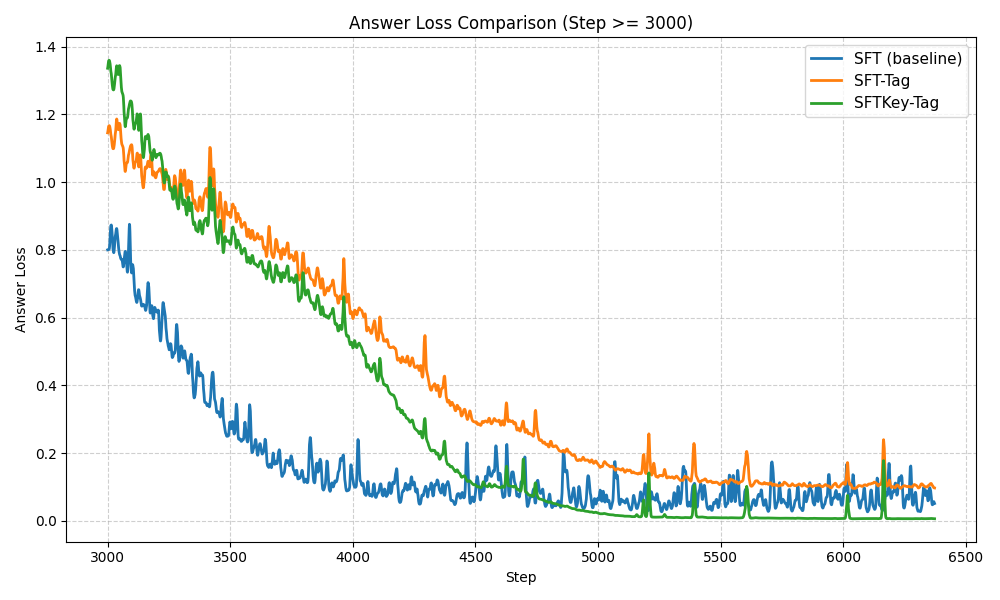
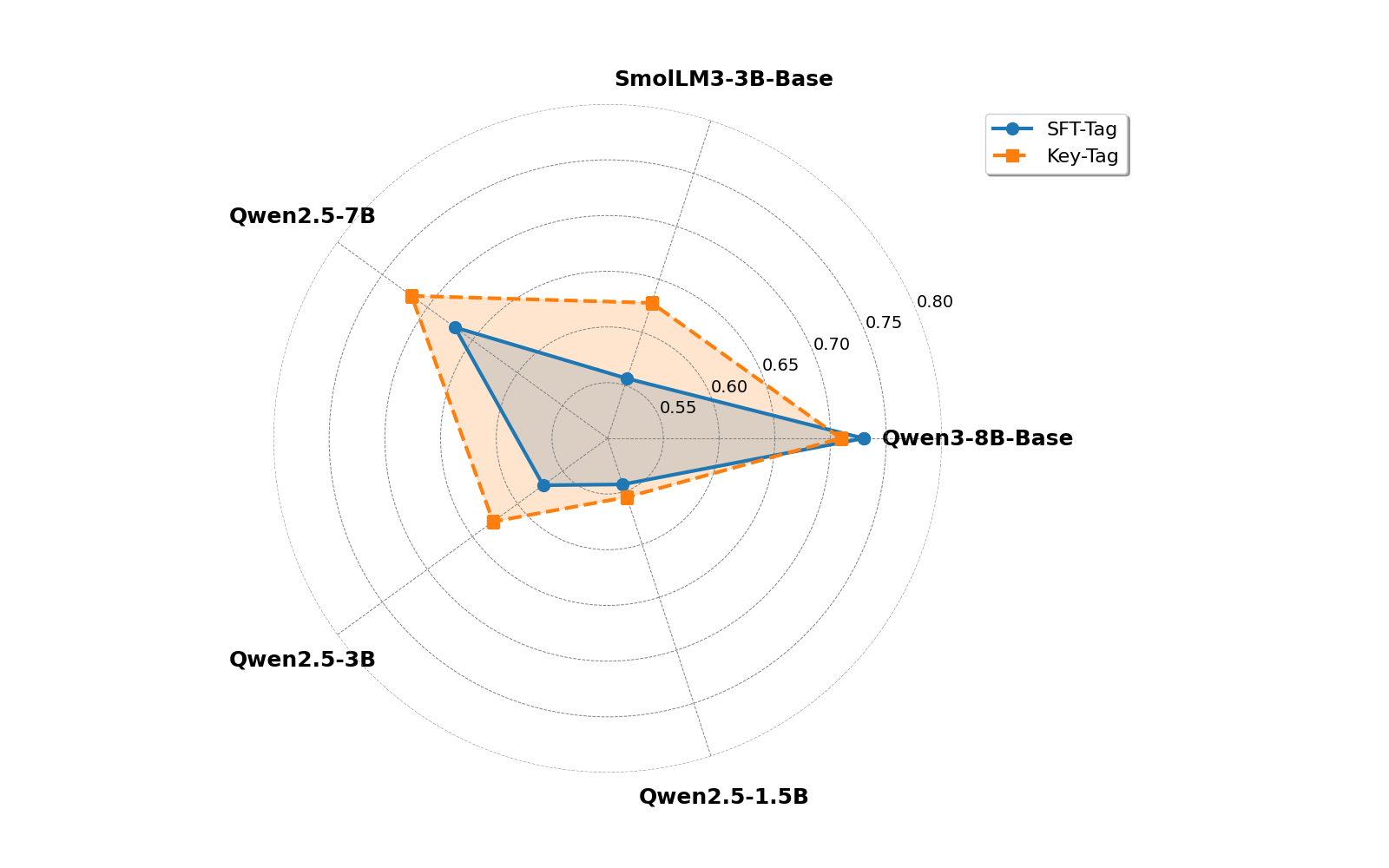
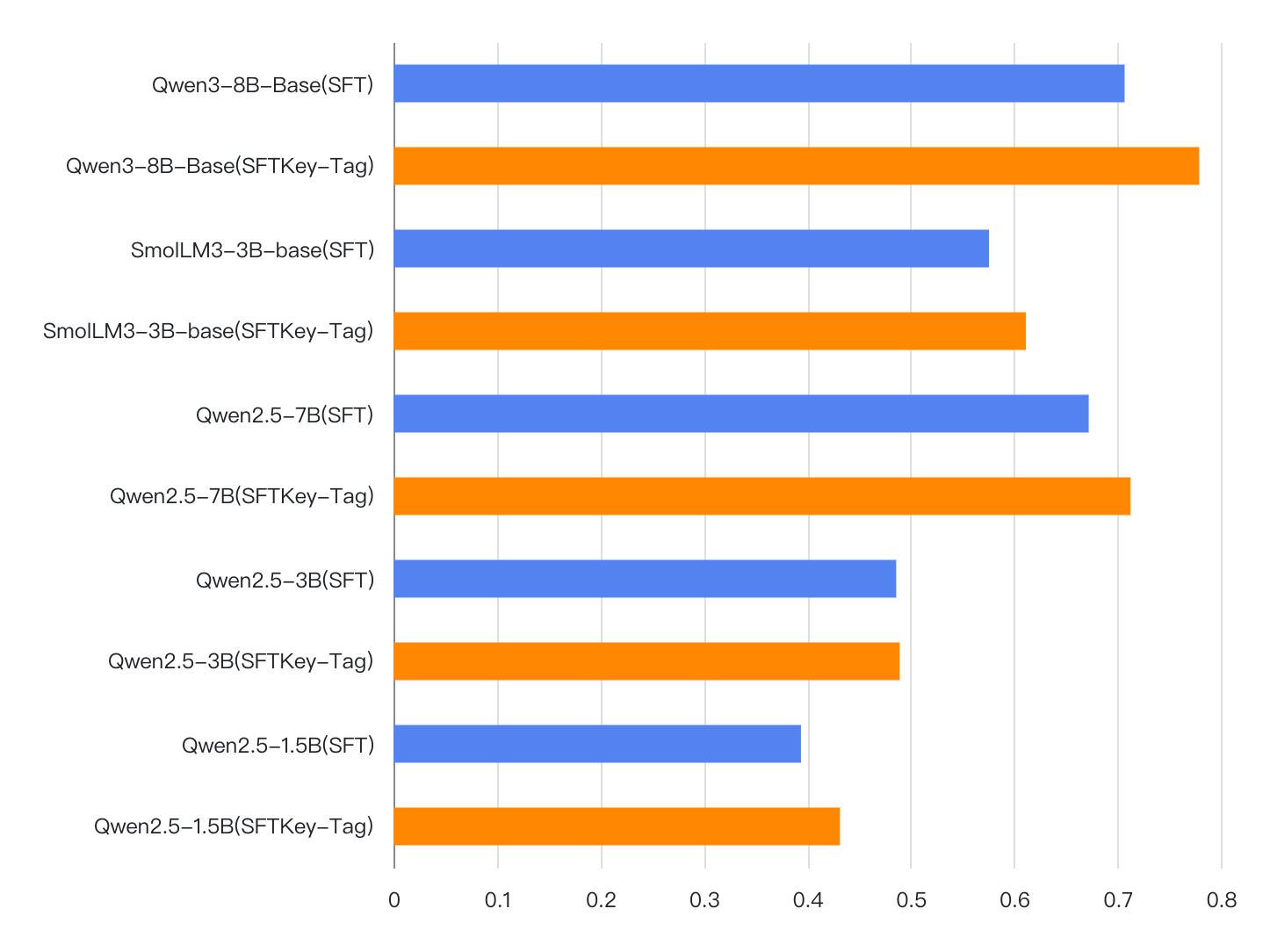
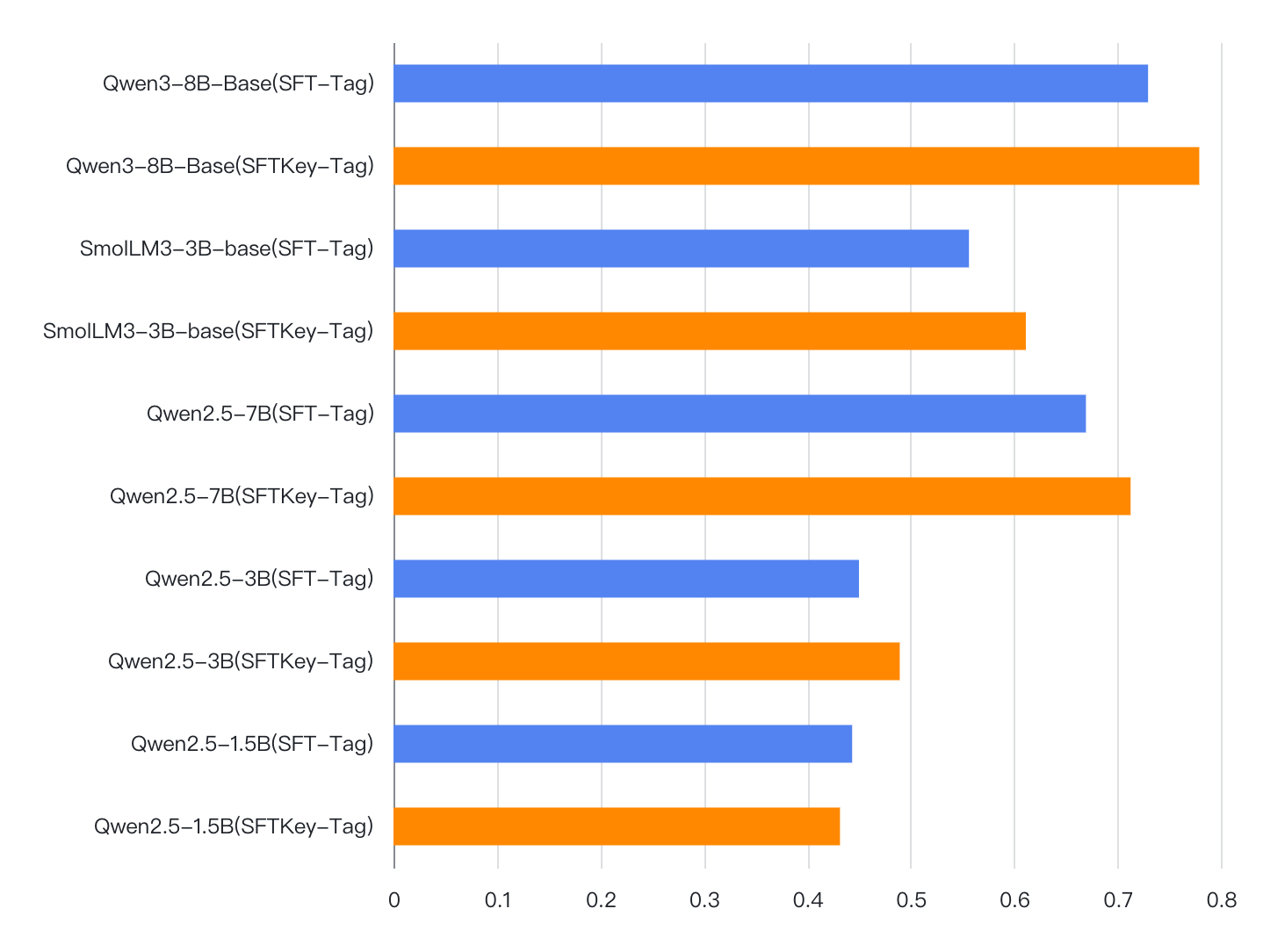
With the rapid advancement of Large Language Models (LLMs), the Chain-of-Thought (CoT) component has become significant for complex reasoning tasks. However, in conventional Supervised Fine-Tuning (SFT), the model could allocate disproportionately more attention to CoT sequences with excessive length. This reduces focus on the much shorter but essential Key portion-the final answer, whose correctness directly determines task success and evaluation quality. To address this limitation, we propose SFTKey, a two-stage training scheme. In the first stage, conventional SFT is applied to ensure proper output format, while in the second stage, only the Key portion is fine-tuned to improve accuracy. Extensive experiments across multiple benchmarks and model families demonstrate that SFTKey achieves an average accuracy improvement exceeding 5\% over conventional SFT, while preserving the ability to generate correct formats. Overall, this study advances LLM fine-tuning by explicitly balancing CoT learning with additional optimization on answer-relevant tokens.
💡 Deep Analysis
📄 Full Content
RETHINKING SUPERVISED FINE-TUNING:
EMPHASIZING KEY ANSWER TOKENS FOR IMPROVED
LLM ACCURACY
Xiaofeng Shi1∗†, Qian Kou1∗, Yuduo Li1,2‡, Hua Zhou1§
1Beijing Academy of Artificial Intelligence (BAAI)
2Beijing Jiaotong University (BJTU)
ABSTRACT
With the rapid advancement of Large Language Models (LLMs), the Chain-of-
Thought (CoT) component has become significant for complex reasoning tasks.
However, in conventional Supervised Fine-Tuning (SFT), the model could allo-
cate disproportionately more attention to CoT sequences with excessive length.
This reduces focus on the much shorter but essential Key portion-the final an-
swer, whose correctness directly determines task success and evaluation quality.
To address this limitation, we propose SFTKey, a two-stage training scheme. In
the first stage, conventional SFT is applied to ensure proper output format, while
in the second stage, only the Key portion is fine-tuned to improve accuracy. Ex-
tensive experiments across multiple benchmarks and model families demonstrate
that SFTKey achieves an average accuracy improvement exceeding 5% over con-
ventional SFT, while preserving the ability to generate correct formats. Overall,
this study advances LLM fine-tuning by explicitly balancing CoT learning with
additional optimization on answer-relevant tokens.
1
INTRODUCTION
Large Language Models (LLMs) with billions of parameters have achieved remarkable performance
across a wide range of complex language tasks (Team, 2025; Guo et al., 2025; OpenAI, 2024). Typ-
ically built on Transformer architectures and trained in unsupervised pretraining followed by Super-
vised Fine-Tuning(SFT) on labeled promptresponse pairs, LLMs are capable of instruction follow-
ing, complex reasoning, and generating desired outputs (Radford et al., 2019; Zhou et al., 2023; Li
et al., 2023). The SFT stage shifts the models objective from next-token prediction towards instruc-
tion following and answer generation, adapting the pretrained model to domain specific knowledge
and scenarios. Studies(Zhou et al., 2023; Kirstain et al., 2021) show that even with relatively small
datasets, SFT can yield substantial performance gains on downstream tasks, strengthening instruc-
tion following ability and output consistency.
In particular, many synthetic datasets generated for SFT consist of carefully curated Chain-of-
Thought (CoT) segments of intermediate reasoning steps followed by a concise final answer(Wei
et al., 2023; Cobbe et al., 2021; Mihaylov et al., 2018). The long CoT reasoning texts bridge the gap
between the question prompt and the final answer, aligning the model’s inference with human-like
cognitive processes and improving its capability of complex reasoning. Conventional paradigm for
SFT treats each token in the target response equally, minimizing the negative log-likelihood over the
entire sequence. This uniform optimization, however, may risk overfitting reasoning tokens while
neglecting the Key portion the final answer segment that ultimately determines task success.
Several recent works study the non-uniform token weighting methods during fine-tuning. For in-
stance, SFT-GO(Kim et al., 2025) groups tokens by importance (e.g. via TFIDF) and optimizes
a worst-group loss so that informative token groups are fully explored. Similarly, the Forgetting
∗Equal contribution.
†Corresponding author. Email: xfshi@baai.ac.cn
‡Work done during internship at BAAI.
§Project leader.
arXiv:2512.21017v1 [cs.CL] 24 Dec 2025
framework(Ghahrizjani et al., 2025) explicitly classifies tokens as positive or negative based on their
utility and then down-weights the less useful tokens during fine-tuning. These approaches affirm
the intuition that not all tokens contribute equally to the model performance. However, they intro-
duce extra hyperparameters or judge models for the token selection, which not only increases the
complexity of the training process but also requires carefully tuning to balance the contribution of
various token groups effectively. Another line of work aims to shorten reasoning chains or compress
inputs to improve efficiency, such as prompt compression (Xia et al., 2025; Jiang et al., 2023) and
longshort chain mixture SFT (Yu et al., 2025). These approaches show that redundant tokens can
be safely removed to improve efficiency without degrading accuracy. Nevertheless, they typically
rely on training or designing an additional rewrite model, which also introduces extra computation
and may face generalization challenges when applied to unseen domains or reasoning styles. There-
fore, there remains a need for a simple, general mechanism to improve the answer accuracy while
preserving its reasoning ability.
In this work, we first propose a new two-stage training scheme called SFTKey. In the first stage,
we apply standard SFT to ensure correct output format. Next, we fine-tune the model only on the
Key tokens to improve accuracy, which represent the final answer. In order to clearly distinguish