CBA: Communication-Bound-Aware Cross-Domain Resource Assignment for Pipeline-Parallel Distributed LLM Training in Dynamic Multi-DC Optical Networks
📝 Original Info
- Title: CBA: Communication-Bound-Aware Cross-Domain Resource Assignment for Pipeline-Parallel Distributed LLM Training in Dynamic Multi-DC Optical Networks
- ArXiv ID: 2512.20080
- Date: 2025-12-23
- Authors: ** 논문에 저자 정보가 제공되지 않았습니다. **
📝 Abstract
We propose a communication-bound-aware cross-domain resource assignment framework for pipeline-parallel distributed training over multi-datacenter optical networks, which lowers iteration time by 31.25% and reduces 13.20% blocking requests compared to baselines.💡 Deep Analysis
📄 Full Content
However, the high communication latency induces severe GPU idle time (“bubble”) due to poor communication and computation time overlapping in inter-DC PP [5]. The efficiency of PP can be improved by finer-grained computing tasks scheduling and communication resource assignment [5 , 8]. While prior works have explored partitioning and reordering computation tasks [5,9], the resource allocation between pipelined computing tasks communication has been overlooked, resulting in higher GPU idle time and request congestion. Moreover, the inter-DC optical communication struggles to provide a stable connection between PP stages due to the bandwidth constraints, network heterogeneity, and the time-varying optical path availability [4,10]. Therefore, it is extremely challenging to propose an advanced inter-DC networks resource allocation solution under the complex PP workload.
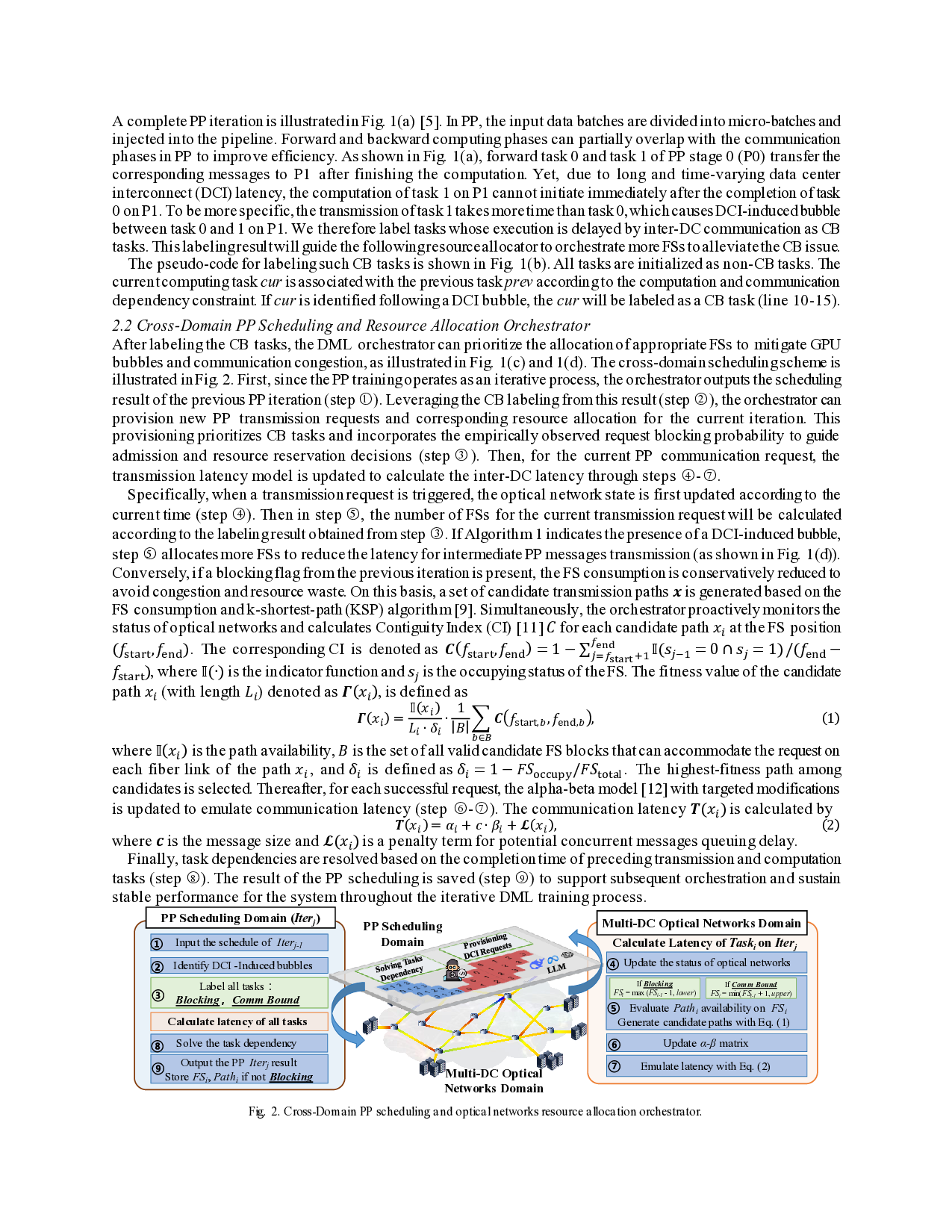
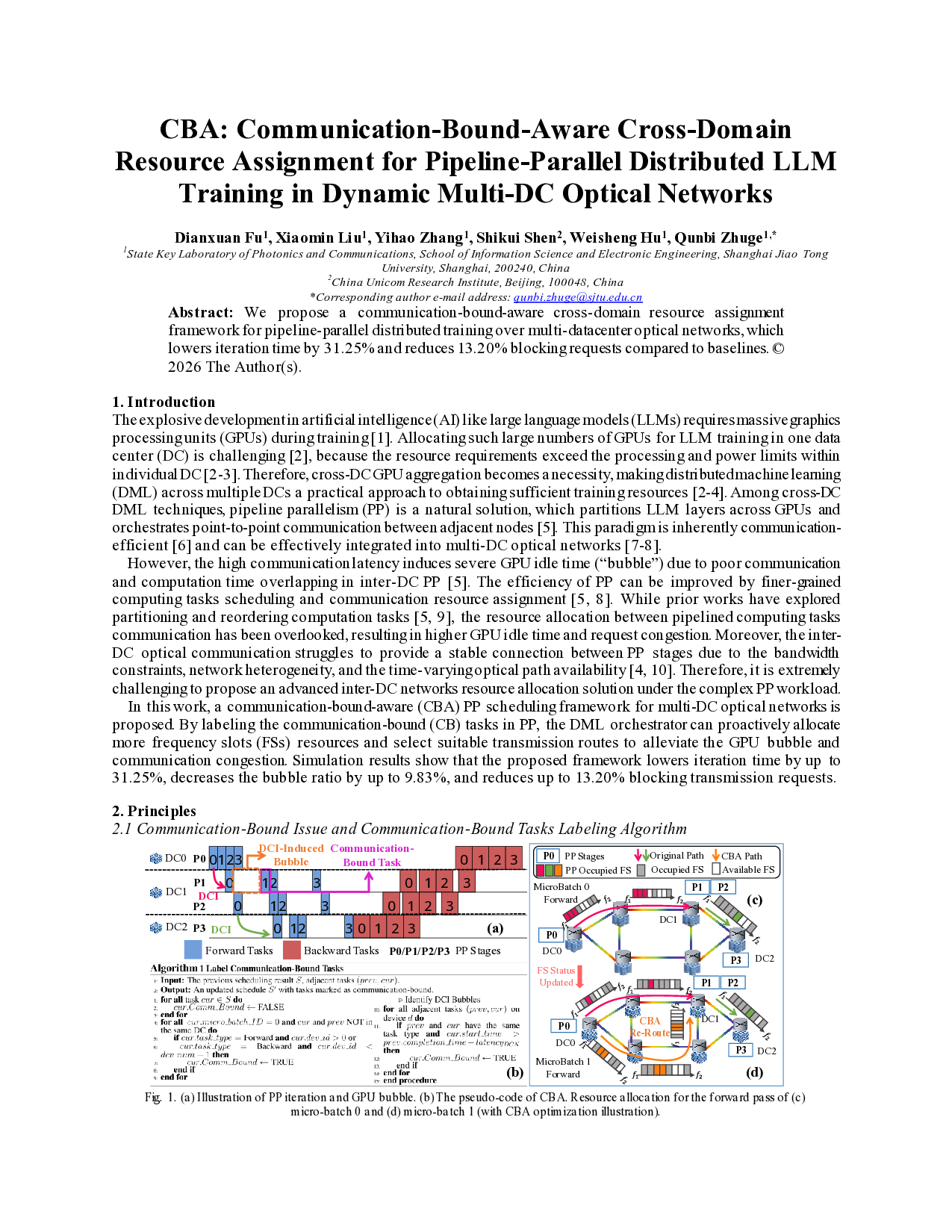
In this work, a communication-bound-aware (CBA) PP scheduling framework for multi-DC optical networks is proposed. By labeling the communication-bound (CB) tasks in PP, the DML orchestrator can proactively allocate more frequency slots (FSs) resources and select suitable transmission routes to alleviate the GPU bubble and communication congestion. Simulation results show that the proposed framework lowers iteration time by up to 31.25%, decreases the bubble ratio by up to 9.83%, and reduces up to 13.20% blocking transmission requests. A complete PP iteration is illustrated in Fig. 1(a) [5]. In PP, the input data batches are divided into micro-batches and injected into the pipeline. Forward and backward computing phases can partially overlap with the communication phases in PP to improve efficiency. As shown in Fig. 1(a), forward task 0 and task 1 of PP stage 0 (P0) transfer the corresponding messages to P1 after finishing the computation. Yet, due to long and time-varying data center interconnect (DCI) latency, the computation of task 1 on P1 cannot initiate immediately after the completion of task 0 on P1. To be more specific, the transmission of task 1 takes more time than task 0, which causes DCI-induced bubble between task 0 and 1 on P1. We therefore label tasks whose execution is delayed by inter-DC communication as CB tasks. This labeling result will guide the following resource allocator to orchestrate more FSs to alleviate the CB issue. The pseudo-code for labeling such CB tasks is shown in Fig. 1(b). All tasks are initialized as non-CB tasks. The current computing task cur is associated with the previous task prev according to the computation and communication dependency constraint. If cur is identified following a DCI bubble, the cur will be labeled as a CB task (line 10-15).
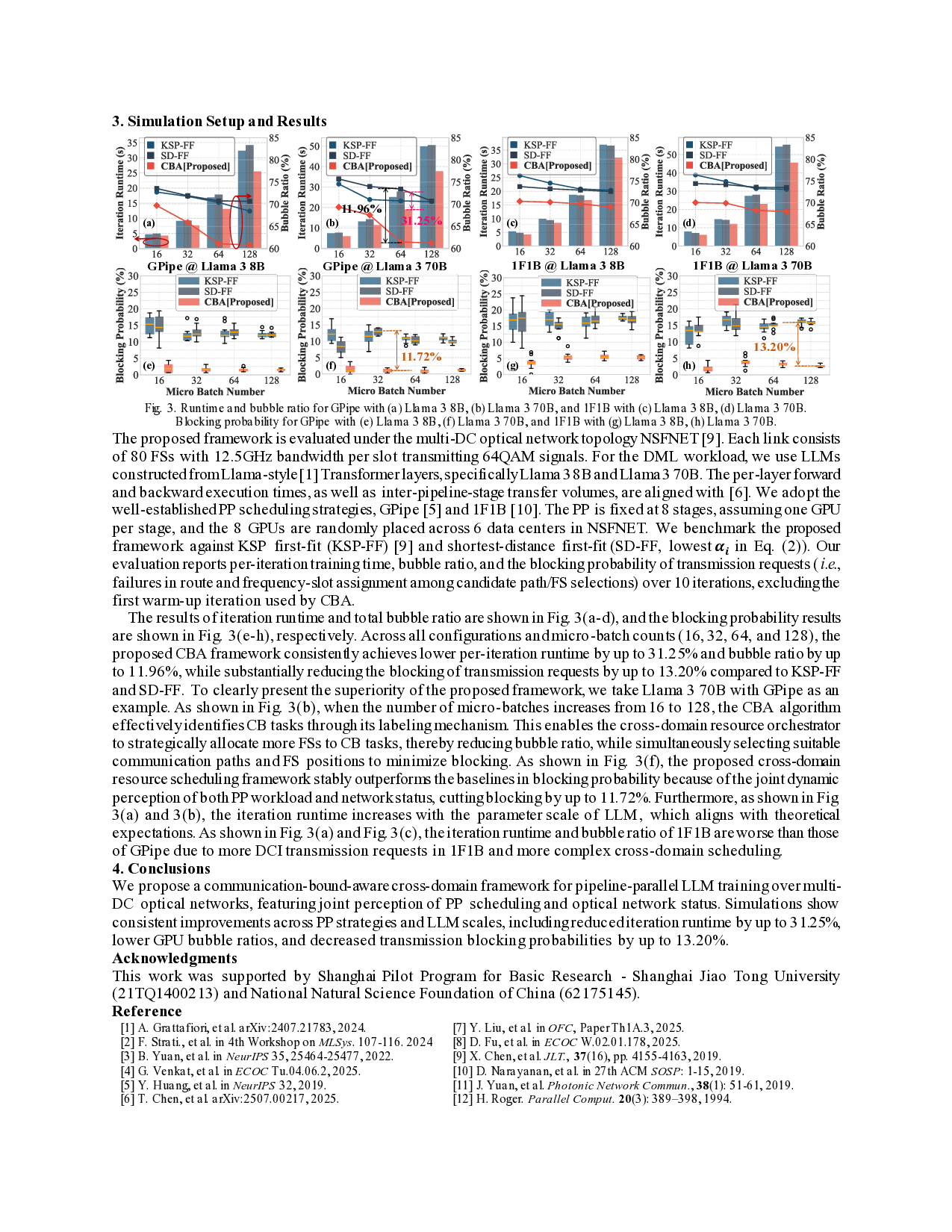
After labeling the CB tasks, the DML orchestrator can prioritize the allocation of appropriate FSs to mitigate GPU bubbles and communication congestion, as illustrated in Fig. 1(c) and 1(d). The cross-domain scheduling scheme is illustrated in Fig. 2. First, since the PP training operates as an iterative process, the orchestrator outputs the scheduling result of the previous PP iteration (step ○ 1 ). Leveraging the CB labeling from this result (step ○ 2 ), the orchestrator can provision new PP transmission requests and corresponding resource allocation for the current iteration. This provisioning prioritizes CB tasks and incorporates the empirically observed request blocking probability to guide admission and resource reservation decisions (step ○ 3 ). Then, for the current PP communication request, the transmission latency model is updated to calculate the inter-DC latency through steps ○ 4 -○ 7 .
Specifically, when a transmission request is triggered, the optical network state is first updated according to the current time (step ○ 4 ). Then in step ○ 5 , the number of FSs for the current transmission request will be calculated according to the labeling result obtained from step ○ 3 . If Algorithm 1 indicates the presence of a DCI-induced bubble, step ○ 5 allocates more FSs to reduce the latency for intermediate PP messages transmission (as shown in Fig. 1(d)). Conversely, if a blocking flag fro
📸 Image Gallery