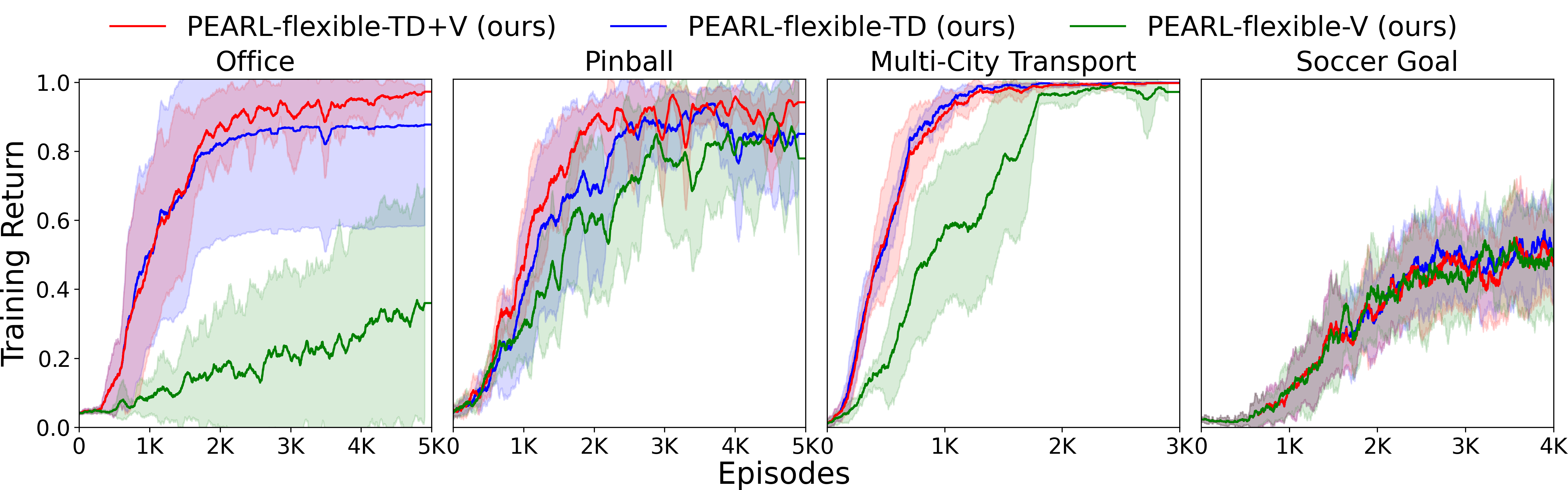
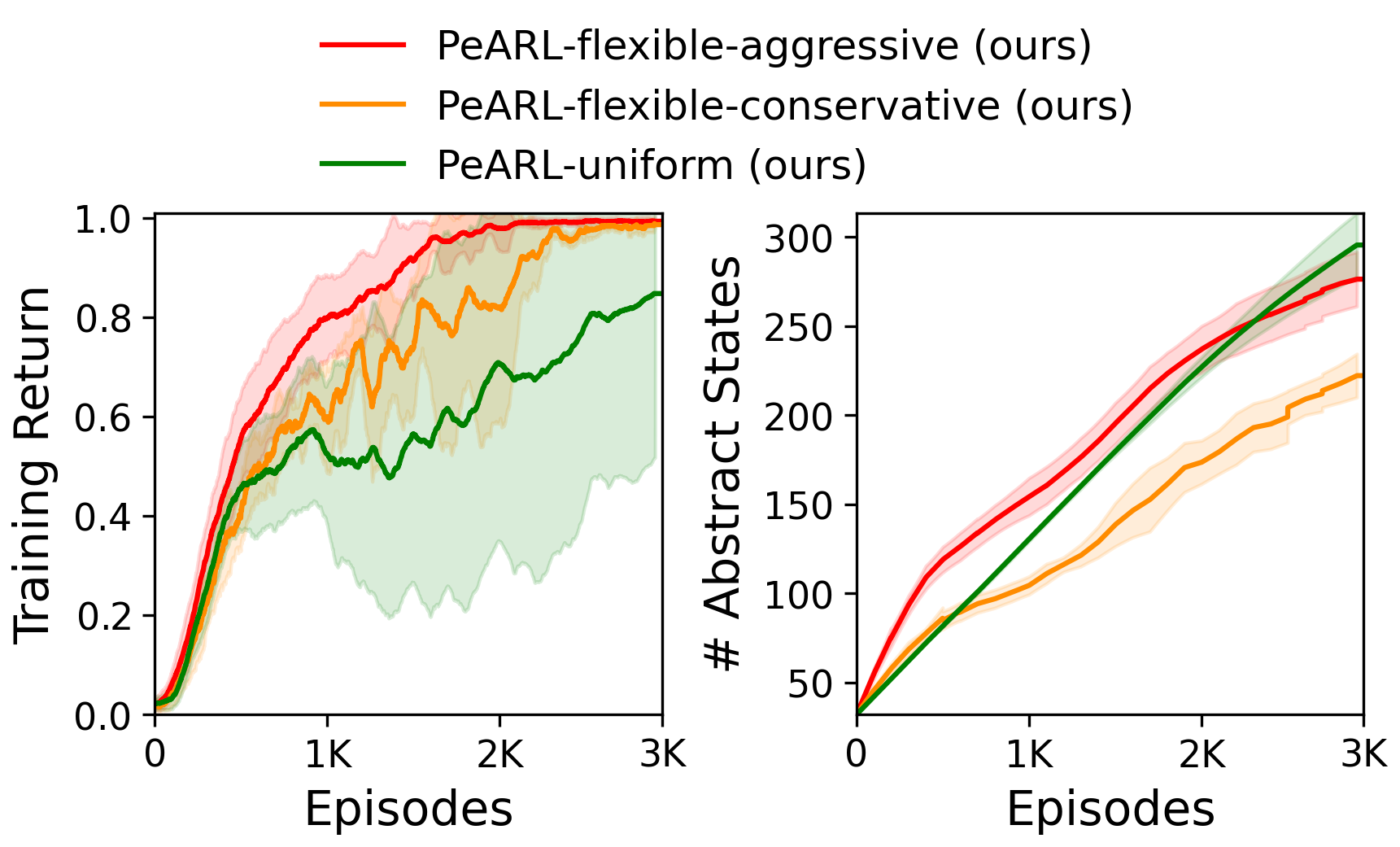
📝 Original Info Title: Context-Sensitive Abstractions for Reinforcement Learning with Parameterized ActionsArXiv ID: 2512.20831Date: 2025-12-23Authors: Rashmeet Kaur Nayyar, Naman Shah, Siddharth Srivastava📝 Abstract Real-world sequential decision-making often involves parameterized action spaces that require both, decisions regarding discrete actions and decisions about continuous action parameters governing how an action is executed. Existing approaches exhibit severe limitations in this setting -- planning methods demand hand-crafted action models, and standard reinforcement learning (RL) algorithms are designed for either discrete or continuous actions but not both, and the few RL methods that handle parameterized actions typically rely on domain-specific engineering and fail to exploit the latent structure of these spaces. This paper extends the scope of RL algorithms to long-horizon, sparse-reward settings with parameterized actions by enabling agents to autonomously learn both state and action abstractions online. We introduce algorithms that progressively refine these abstractions during learning, increasing fine-grained detail in the critical regions of the state-action space where greater resolution improves performance. Across several continuous-state, parameterized-action domains, our abstraction-driven approach enables TD($λ$) to achieve markedly higher sample efficiency than state-of-the-art baselines.
💡 Deep Analysis
📄 Full Content Context-Sensitive Abstractions for
Reinforcement Learning with Parameterized Actions
Rashmeet Kaur Nayyar*1, Naman Shah*1,2, and Siddharth Srivastava1
1Arizona State University, Tempe, AZ, USA
2 Brown Unviersity, Providence, RI, USA
{rmnayyar, shah.naman, siddharths}@asu.edu
Abstract
Real-world sequential decision-making often involves param-
eterized action spaces that require both, decisions regarding
discrete actions and decisions about continuous action pa-
rameters governing how an action is executed. Existing ap-
proaches exhibit severe limitations in this setting—planning
methods demand hand-crafted action models, and standard
reinforcement learning (RL) algorithms are designed for ei-
ther discrete or continuous actions but not both, and the
few RL methods that handle parameterized actions typi-
cally rely on domain-specific engineering and fail to exploit
the latent structure of these spaces. This paper extends the
scope of RL algorithms to long-horizon, sparse-reward set-
tings with parameterized actions by enabling agents to au-
tonomously learn both state and action abstractions online.
We introduce algorithms that progressively refine these ab-
stractions during learning, increasing fine-grained detail in
the critical regions of the state–action space where greater
resolution improves performance. Across several continuous-
state, parameterized-action domains, our abstraction-driven
approach enables TD(λ) to achieve markedly higher sample
efficiency than state-of-the-art baselines.
Code — https://github.com/AAIR-lab/PEARL.git
Extended version —
https://aair-lab.github.io/Publications/nss-aaai26.pdf
1
Introduction
Reinforcement learning (RL) has delivered strong results
across a diverse range of decision-making tasks, from dis-
crete action settings like Atari games (Mnih et al. 2015) to
continuous control scenarios such as robotic manipulation
(Schulman et al. 2017). Yet most leading RL approaches
(Schulman et al. 2017; Haarnoja et al. 2018; Schrittwieser
et al. 2020; Hansen, Su, and Wang 2024) are designed for
either discrete or continuous action spaces—not both. Many
real-world problems violate this dichotomy. In autonomous
driving, for example, the agent must choose among qual-
itatively distinct actions (accelerate, brake, turn), each en-
dowed with discrete or continuous parameters such as brak-
ing force or steering angle. Such actions—known as param-
*These authors contributed equally.
Copyright © 2026, Association for the Advancement of Artificial
Intelligence (www.aaai.org). All rights reserved.
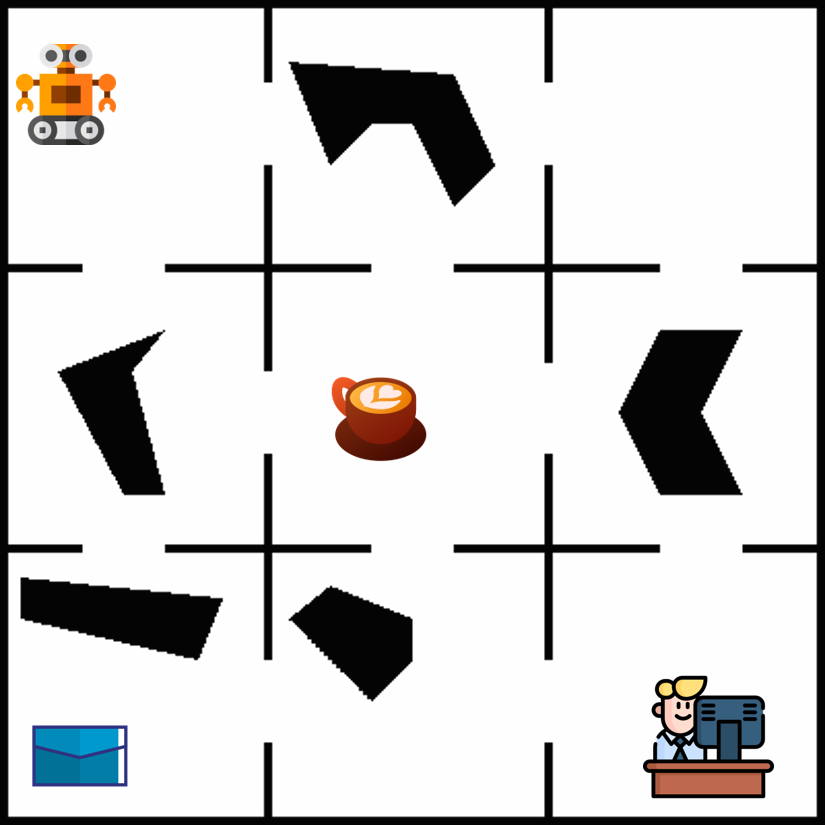
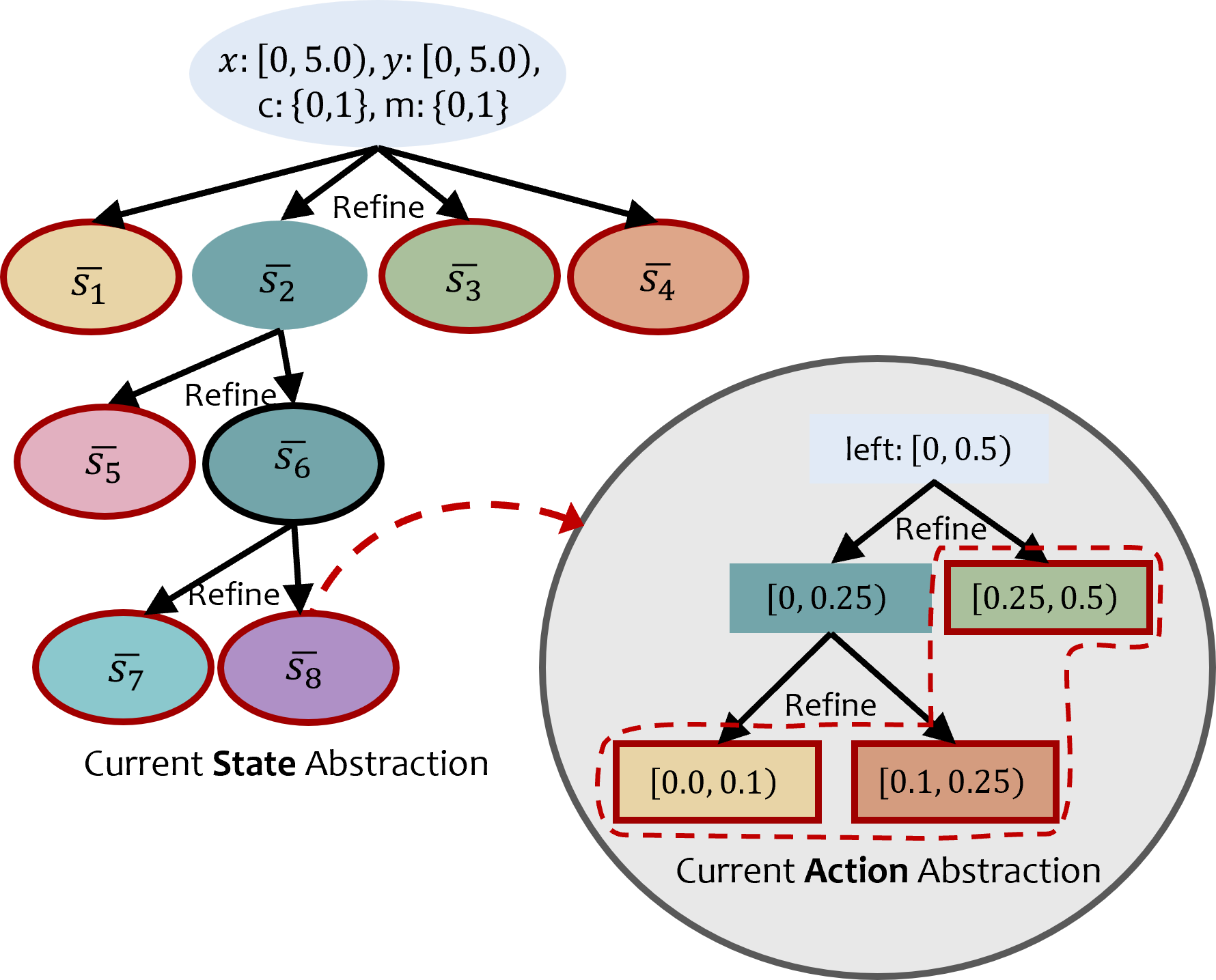
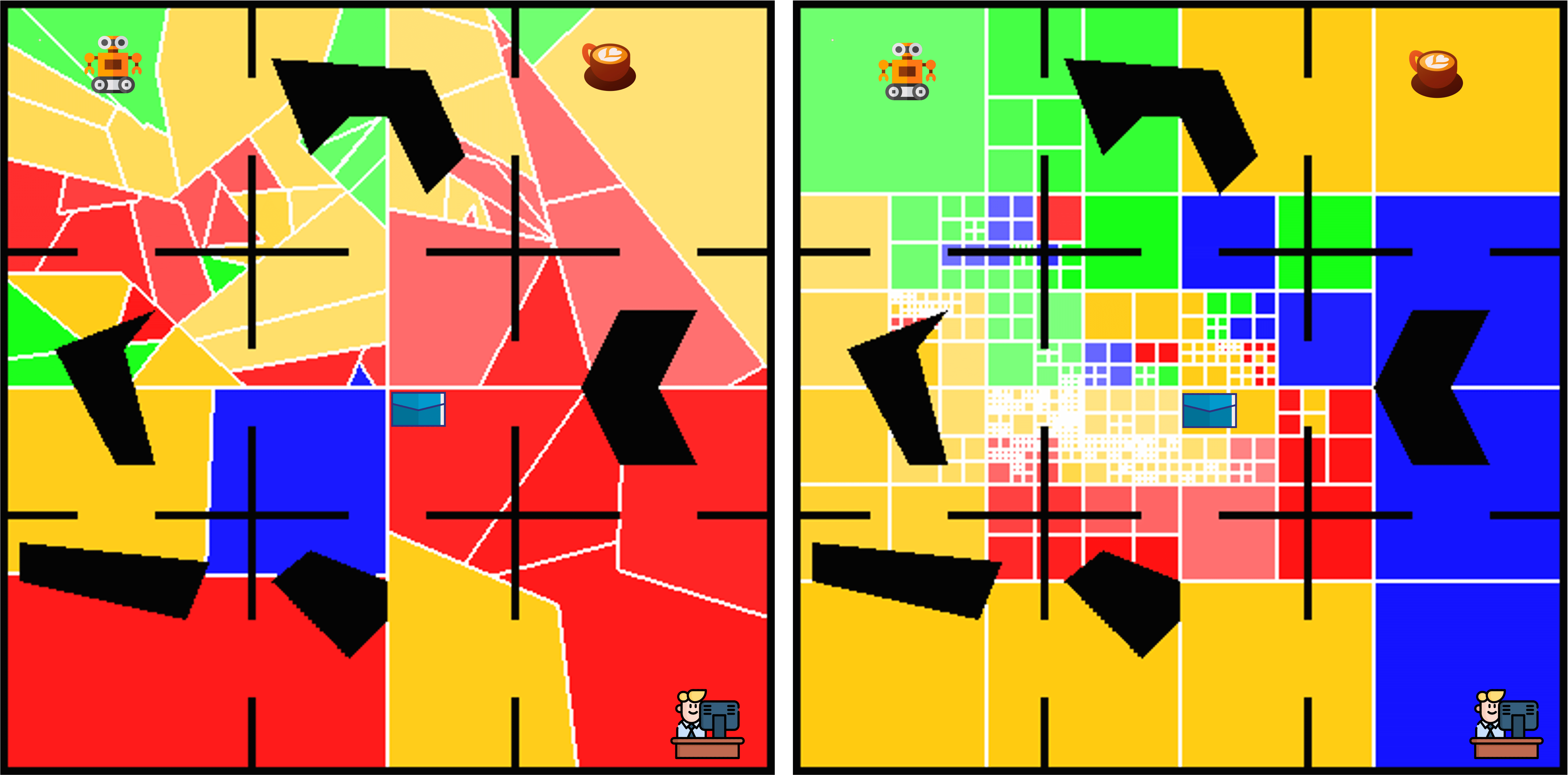
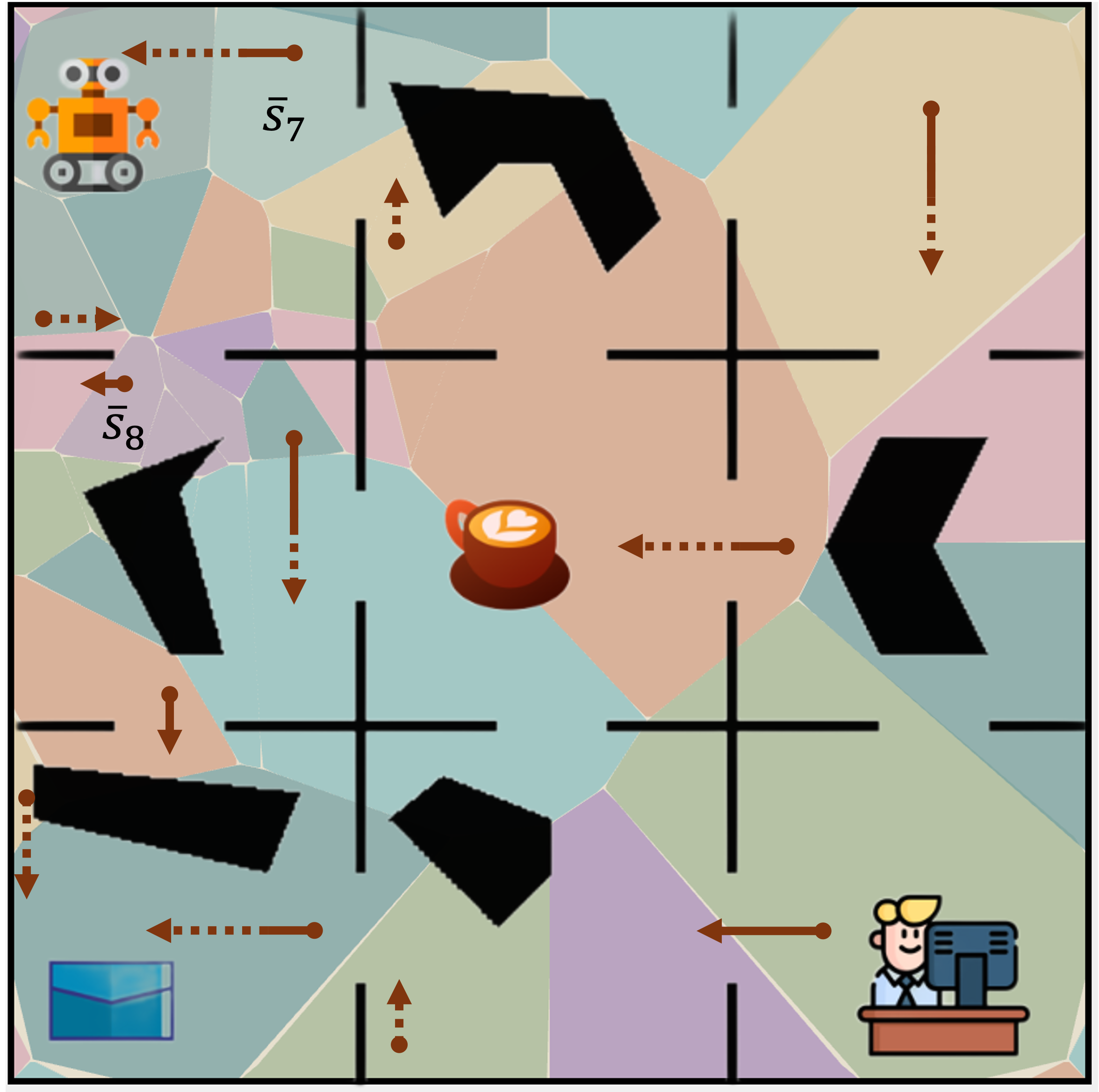
Figure 1: In a continuous version of the office domain, the
agent needs to learn policies for delivering multiple items.
Polygonal cells illustrate learned state abstractions, and ar-
rows illustrate learned policies with abstract actions param-
eterized by parameter intervals. Each arrow corresponds to
an interval [a, b) of possible movement values: the solid seg-
ment indicates the lower bound a, and the dotted segment
indicates the interval width b−a. Narrower dotted segments
denote higher precision in the learned action parameters.
eterized actions—require choosing not only the action but
also determine its (real-valued) parameters before execution.
While recent methods have made progress in addressing
parameterized actions (Xiong et al. 2018; Bester, James, and
Konidaris 2019; Li et al. 2022), they largely ignore utilizing
the underlying structure inherent in parameterized-action
spaces. In navigation tasks, for instance, an agent should
adjust movement parameters with high precision near ob-
stacles but can act with much coarser control in open areas.
Existing approaches also often rely on carefully engineered
dense rewards and environment-specific initializations to fa-
cilitate learning or benefit from relatively short “effective
horizons” to remain tractable (Laidlaw, Russell, and Dragan
2023). A detailed discussion of related work is in Sec. 5.
This paper aims to extend the scope and sample efficiency
of RL paradigms to relatively under-studied yet challenging
arXiv:2512.20831v1 [cs.AI] 23 Dec 2025
class of problems that feature long horizons, sparse rewards,
and parameterized actions. We introduce the first known ap-
proach called PEARL that automatically discovers structure
in parameterized-action problems in the form of conditional
abstractions of their state spaces and action spaces. As an il-
lustration, Fig. 1 shows flexible abstraction of the state space
and how the policy may require a different extent of action
abstraction in different states in the OfficeWorld domain: in
the tightly constrained region s8, navigation demands high-
precision in action parameters, whereas the more open space
of s7 tolerates far coarser abstraction. This contrast high-
lights why abstractions must capture this variation in the
required precision of action parameters across different re-
gions of the state space.
Given an input problem in the RL setting where a state
is expressed using discrete
📸 Image Gallery
Reference This content is AI-processed based on open access ArXiv data.