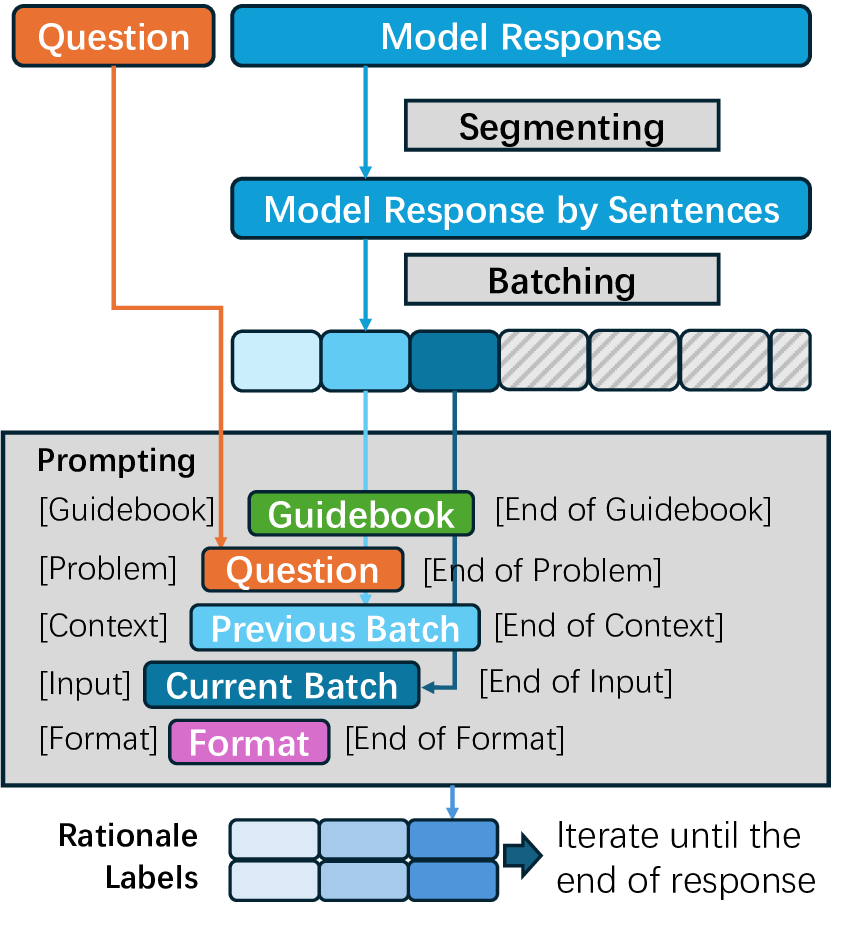
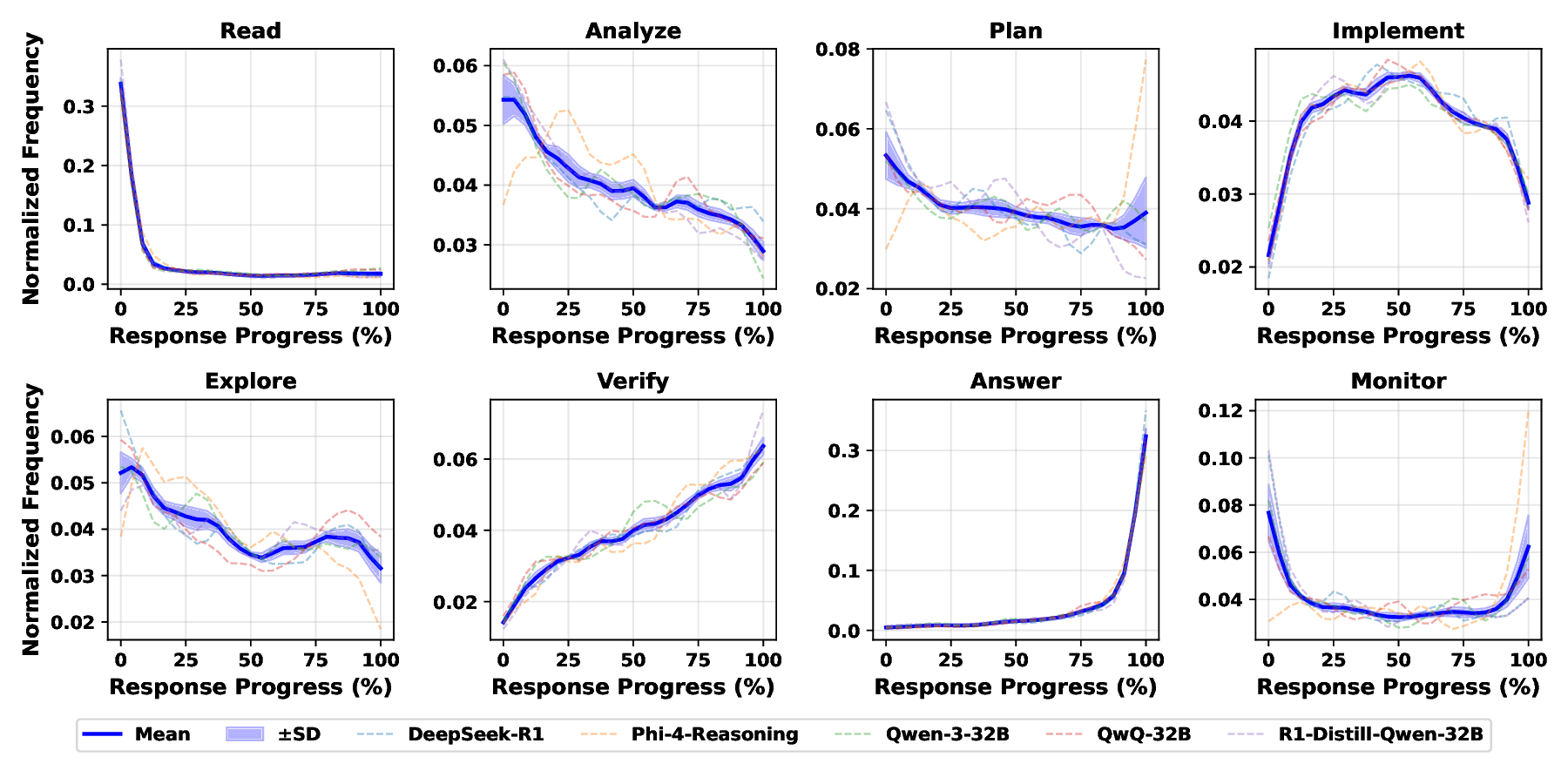
Large language models increasingly expose reasoning traces, yet their underlying cognitive structure and steps remain difficult to identify and analyze beyond surface-level statistics. We adopt Schoenfeld's Episode Theory as an inductive, intermediate-scale lens and introduce ThinkARM (Anatomy of Reasoning in Models), a scalable framework that explicitly abstracts reasoning traces into functional reasoning steps such as Analysis, Explore, Implement, Verify, etc. When applied to mathematical problem solving by diverse models, this abstraction reveals reproducible thinking dynamics and structural differences between reasoning and non-reasoning models, which are not apparent from token-level views. We further present two diagnostic case studies showing that exploration functions as a critical branching step associated with correctness, and that efficiency-oriented methods selectively suppress evaluative feedback steps rather than uniformly shortening responses. Together, our results demonstrate that episode-level representations make reasoning steps explicit, enabling systematic analysis of how reasoning is structured, stabilized, and altered in modern language models.
💡 Deep Analysis
📄 Full Content
Schoenfeld’s Anatomy of Mathematical Reasoning by Language Models
Ming Li*, Chenrui Fan*, Yize Cheng*, Soheil Feizi, Tianyi Zhou
University of Maryland, College Park
{minglii,cfan42,yzcheng,sfeizi}@umd.edu, tianyi.david.zhou@gmail.com
Project: https://github.com/MingLiiii/ThinkARM
Abstract
Large language models increasingly expose
reasoning traces, yet their underlying cogni-
tive structure and steps remain difficult to iden-
tify and analyze beyond surface-level statis-
tics. We adopt Schoenfeld’s Episode Theory as
an inductive, intermediate-scale lens and intro-
duce ThinkARM (Anatomy of Reasoning in
Models), a scalable framework that explicitly
abstracts reasoning traces into functional
reasoning steps such as Analysis, Explore, Im-
plement, Verify, etc. When applied to math-
ematical problem solving by diverse models,
this abstraction reveals reproducible thinking
dynamics and structural differences between
reasoning and non-reasoning models, which
are not apparent from token-level views. We
further present two diagnostic case studies
showing that exploration functions as a criti-
cal branching step associated with correctness,
and that efficiency-oriented methods selectively
suppress evaluative feedback steps rather than
uniformly shortening responses. Together, our
results demonstrate that episode-level represen-
tations make reasoning steps explicit, enabling
systematic analysis of how reasoning is struc-
tured, stabilized, and altered in modern lan-
guage models.
1
Introduction
Large language models (LLMs) have demonstrated
remarkable performance on complex reasoning
tasks (OpenAI, 2024c; Marjanovi´c et al., 2025;
Comanici et al., 2025; Qwen Team, 2025a), partic-
ularly when generating explicit chains of thought
(CoT) (Wei et al., 2023). Consequently, evaluation
of reasoning models has predominantly focused on
outcome-oriented metrics such as accuracy, solu-
tion length, or aggregate token counts (Lightman
et al., 2023; Jiang et al., 2025a). While these mea-
sures are effective for comparing final performance,
they provide limited insight into how these models
*Co-First Authors.
organize their reasoning traces and how different
reasoning behaviors emerge across models.
It is still unclear which parts of a generated chain-
of-thought correspond to problem understanding,
exploration, execution, or verification, making it
difficult to interpret model behavior beyond sur-
face statistics. This opacity is particularly salient
when studying “overthinking” (Chen et al., 2025b;
Fan et al., 2025; Kumar et al., 2025), where longer
or more elaborate reasoning does not necessarily
translate into improved correctness (Feng et al.,
2025b), yet the underlying thinking dynamics and
structure are hard to characterize systematically.
Various reasoning behaviors that are often dis-
cussed conceptually, e.g., abstract planning versus
concrete execution, open-ended exploration versus
evaluative checking, lack rigorous formulation and
quantitative comparison across models.
To better interpret such reasoning traces, a nat-
ural question is whether they contain meaning-
ful structure at an intermediate level of abstrac-
tion beyond individual tokens. Motivated by prior
work (Li et al., 2025c) that introduced Schoenfeld’s
Episode Theory (Schoenfeld, 1985) as a framework
for characterizing problem-solving behaviors, we
adopt episode-level representations as an inductive
lens for analyzing LLM reasoning traces. Episode
Theory conceptualizes problem solving in terms
of functional episodes, thereby providing an in-
terpretable intermediate-scale representation that
bridges low-level token statistics and high-level
reasoning intents. A condensed example is shown
in Figure 1.
While earlier work (Li et al., 2025c) first lever-
aged this theory to reasoning models, their scope
is limited to one model and one dataset. Thus, it
remains unclear whether such an episode-level ab-
straction can reveal systematic, reproducible struc-
ture in LLM reasoning at scale. In this work, we
build upon this foundation and extend episode-level
annotation to a broader, comparative setting, us-
1
arXiv:2512.19995v1 [cs.CL] 23 Dec 2025
Let 𝑓𝑟= ∑
!
"!
#$$%
"&#
= !
#! +
!
'! + ⋯+
!
#$$%! .
Find ∑
𝑓(𝑘)
(
)&#
1. Read
2. Analyze
3. Plan
4. Implement
5. Explore
6. Verify
7. Answer
8. Monitor
Question:
Categories:
❶
❶
❶
❽
❸
❸
❷
❷
❷
❷
❷
❺
❻
❻
❻
❼
❼
❹
❽
❸
Figure 1: A condensed example of a reasoning trace that is annotated in our framework. Each sentence in response
is tagged with one of the eight episode categories.
ing it to examine what principal patterns emerge
when diverse reasoning traces are viewed through
a theory-grounded abstraction. Our study is orga-
nized around three research questions. RQ1: Do
reasoning traces exhibit consistent linguistic and
dynamic structure when viewed through episode-
level representations? RQ2: How do reasoning
dynamics differ across models and reasoning styles,
as indicated by episode sequencing and transition
patterns