Title: DETACH : Decomposed Spatio-Temporal Alignment for Exocentric Video and Ambient Sensors with Staged Learning
ArXiv ID: 2512.20409
Date: 2025-12-23
Authors: Junho Yoon, Jaemo Jung, Hyunju Kim, Dongman Lee
📝 Abstract
Aligning egocentric video with wearable sensors have shown promise for human action recognition, but face practical limitations in user discomfort, privacy concerns, and scalability. We explore exocentric video with ambient sensors as a non-intrusive, scalable alternative. While prior egocentric-wearable works predominantly adopt Global Alignment by encoding entire sequences into unified representations, this approach fails in exocentric-ambient settings due to two problems: (P1) inability to capture local details such as subtle motions, and (P2) over-reliance on modality-invariant temporal patterns, causing misalignment between actions sharing similar temporal patterns with different spatio-semantic contexts. To resolve these problems, we propose DETACH, a decomposed spatio-temporal framework. This explicit decomposition preserves local details, while our novel sensor-spatial features discovered via online clustering provide semantic grounding for context-aware alignment. To align the decomposed features, our two-stage approach establishes spatial correspondence through mutual supervision, then performs temporal alignment via a spatial-temporal weighted contrastive loss that adaptively handles easy negatives, hard negatives, and false negatives. Comprehensive experiments with downstream tasks on Opportunity++ and HWU-USP datasets demonstrate substantial improvements over adapted egocentric-wearable baselines.
💡 Deep Analysis
📄 Full Content
DETACH : Decomposed Spatio-Temporal Alignment for Exocentric Video and
Ambient Sensors with Staged Learning
Junho Yoon
Jaemo Jung
Hyunju Kim
Dongman Lee
KAIST
{vpdtlrdl, gosfl4760, iplay93, dlee}@kaist.ac.kr
Abstract
Aligning egocentric video with wearable sensors have
shown promise for human action recognition, but face prac-
tical limitations in user discomfort, privacy concerns, and
scalability. We explore exocentric video with ambient sen-
sors as a non-intrusive, scalable alternative. While prior
egocentric-wearable works predominantly adopt Global
Alignment by encoding entire sequences into unified rep-
resentations, this approach fails in exocentric-ambient set-
tings due to two problems: (P1) inability to capture lo-
cal details such as subtle motions, and (P2) over-reliance
on modality-invariant temporal patterns, causing misalign-
ment between actions sharing similar temporal patterns
with different spatio-semantic contexts.
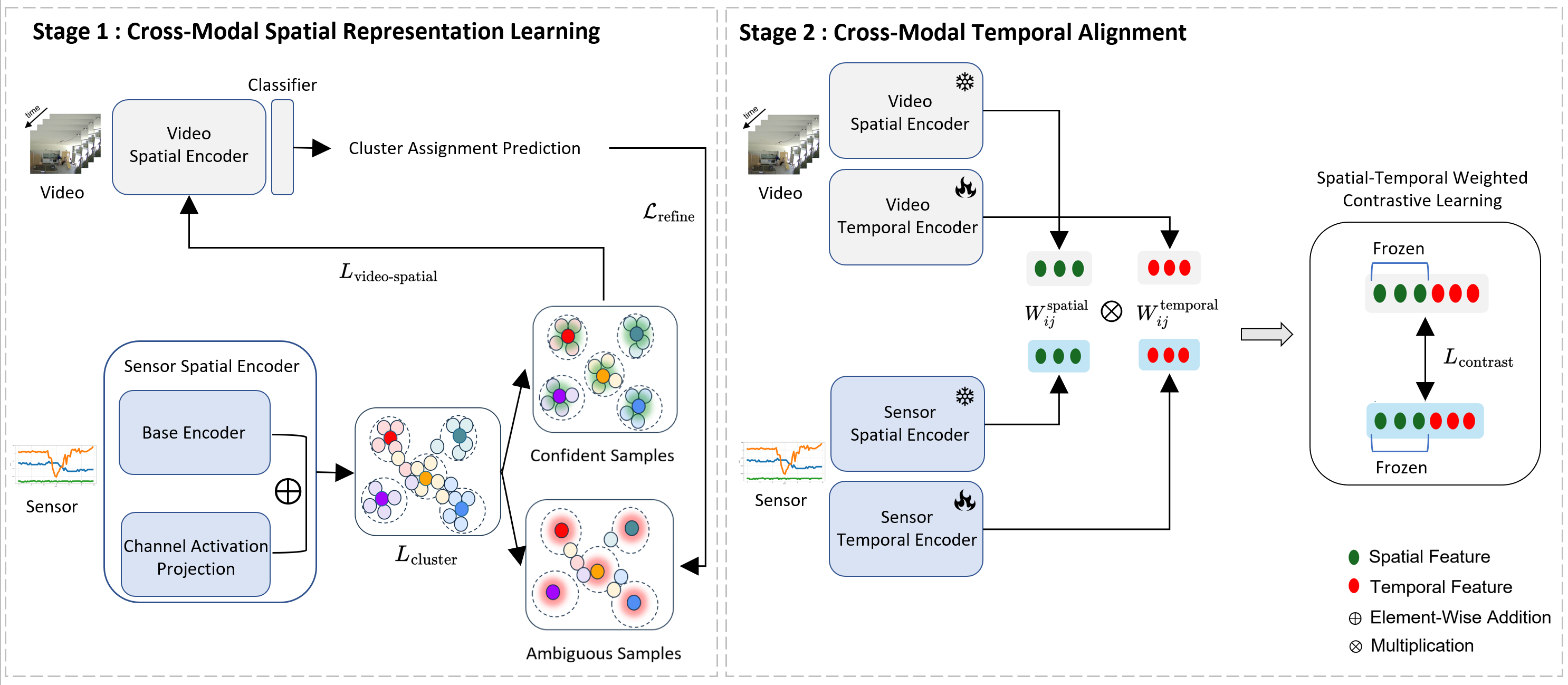
To resolve these
problems, we propose DETACH, a decomposed spatio-
temporal framework. This explicit decomposition preserves
local details, while our novel sensor-spatial features dis-
covered via online clustering provide semantic grounding
for context-aware alignment.
To align the decomposed
features, our two-stage approach establishes spatial cor-
respondence through mutual supervision, then performs
temporal alignment via a spatial-temporal weighted con-
trastive loss that adaptively handles easy negatives, hard
negatives, and false negatives.
Comprehensive experi-
ments with downstream tasks on Opportunity++ and HWU-
USP datasets demonstrate substantial improvements over
adapted egocentric-wearable baselines.
1. Introduction
Human action recognition (HAR) has been extensively
studied using video [26, 31] and sensor modalities [37, 54],
with each offering unique strengths as video provides rich
visual context [23] and sensors offer precise temporal cues
[35]. Recently, multimodal approaches aligning egocentric
video with wearable sensors [8, 11, 32, 57] have demon-
strated promising results in personal action monitoring
by leveraging their complementarity. However, such ap-
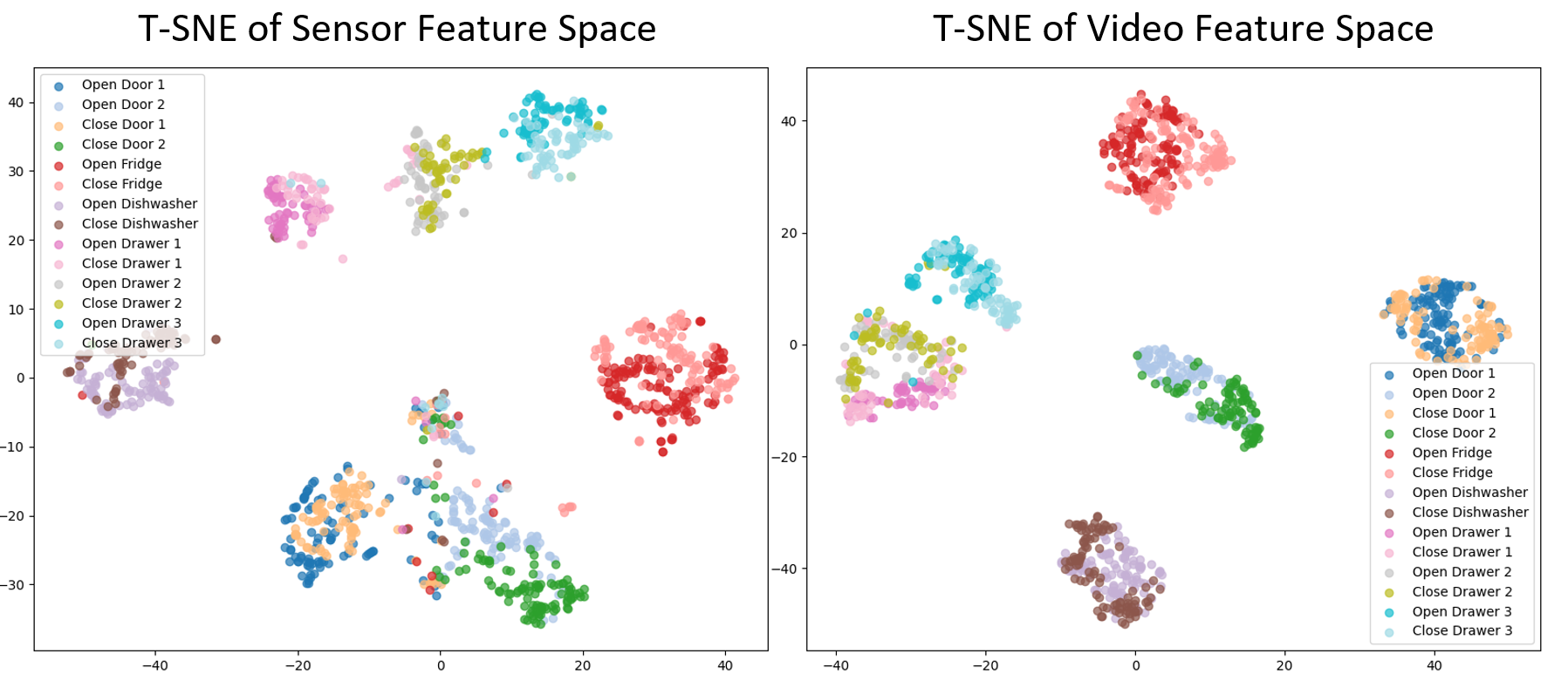
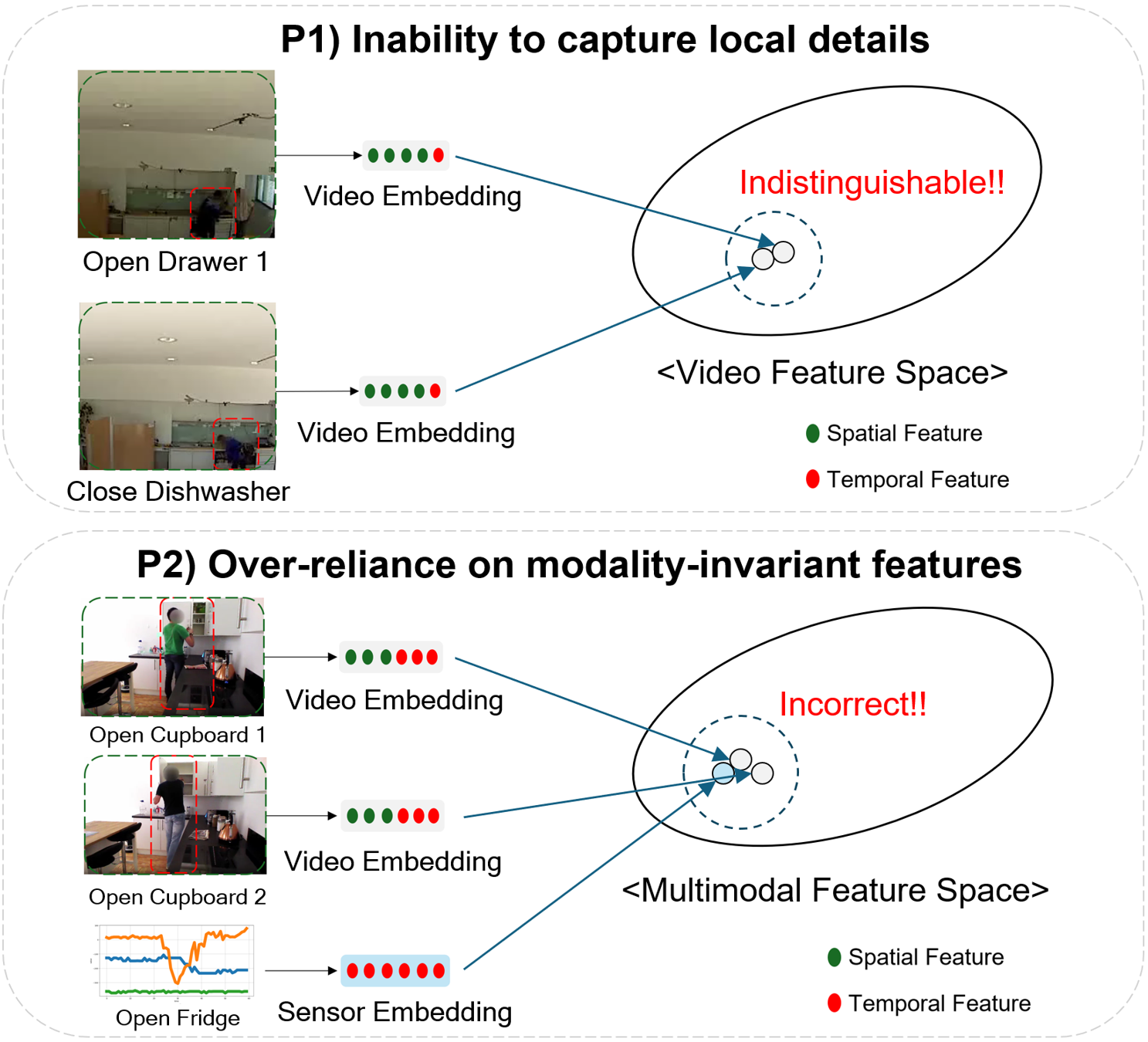
Figure 1. Limitations of Global Alignment-based approaches.
(a) Inability to capture local details: subtle motions become indis-
tinguishable in video feature space. (b) Over-reliance on modality-
invariant features: actions incorrectly aligned due to shared tem-
poral patterns, despite different spatio-semantic contexts.
proaches face practical limitations in real-world deploy-
ment, as they introduce ongoing user burden, expose sensi-
tive personal data, and offer limited scalability across mul-
tiple users [42, 58].
Integrating exocentric video with ambient sensors offers
a promising direction for addressing the limitations. Unlike
egocentric–wearable setups, exocentric–ambient configura-
tions employ statically installed cameras [23] and object-
embedded sensors [34], enabling non-intrusive and scal-
able monitoring [40, 50]. However, despite this potential,
no existing work has explored exocentric–ambient align-
ment, and the Global Alignment strategy commonly used
in the egocentric–wearable domain is unsuitable to this set-
ting. Global Alignment strategy encodes entire video clips
and sensor windows into holistic representations, which are
arXiv:2512.20409v1 [cs.CV] 23 Dec 2025
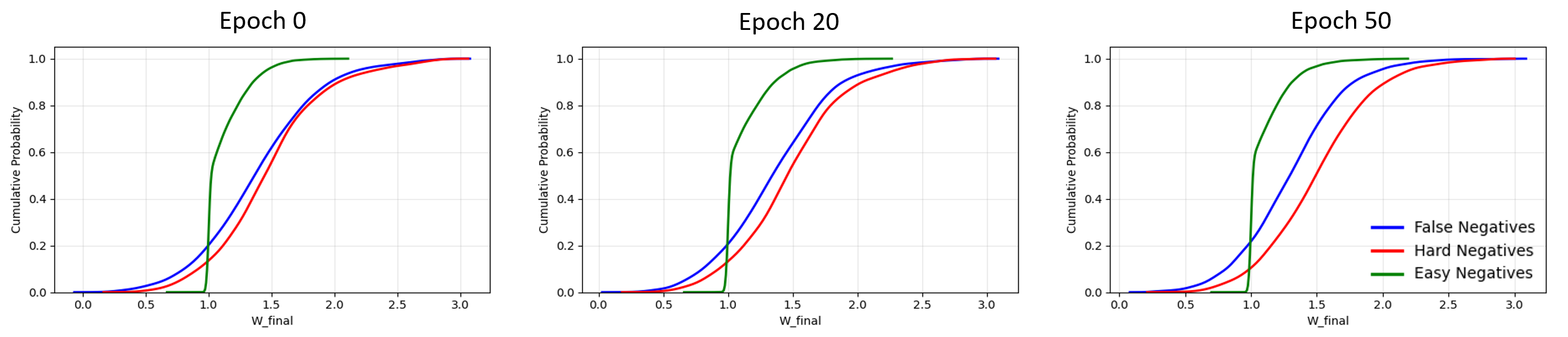
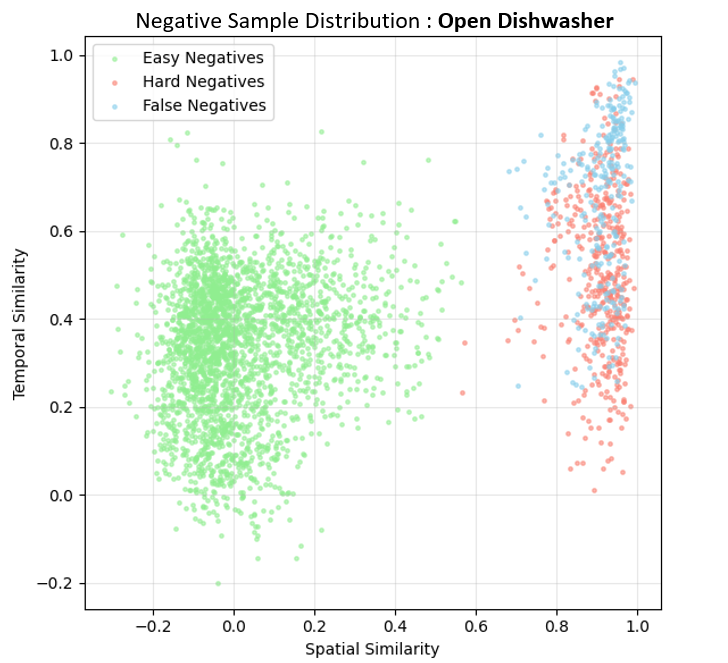
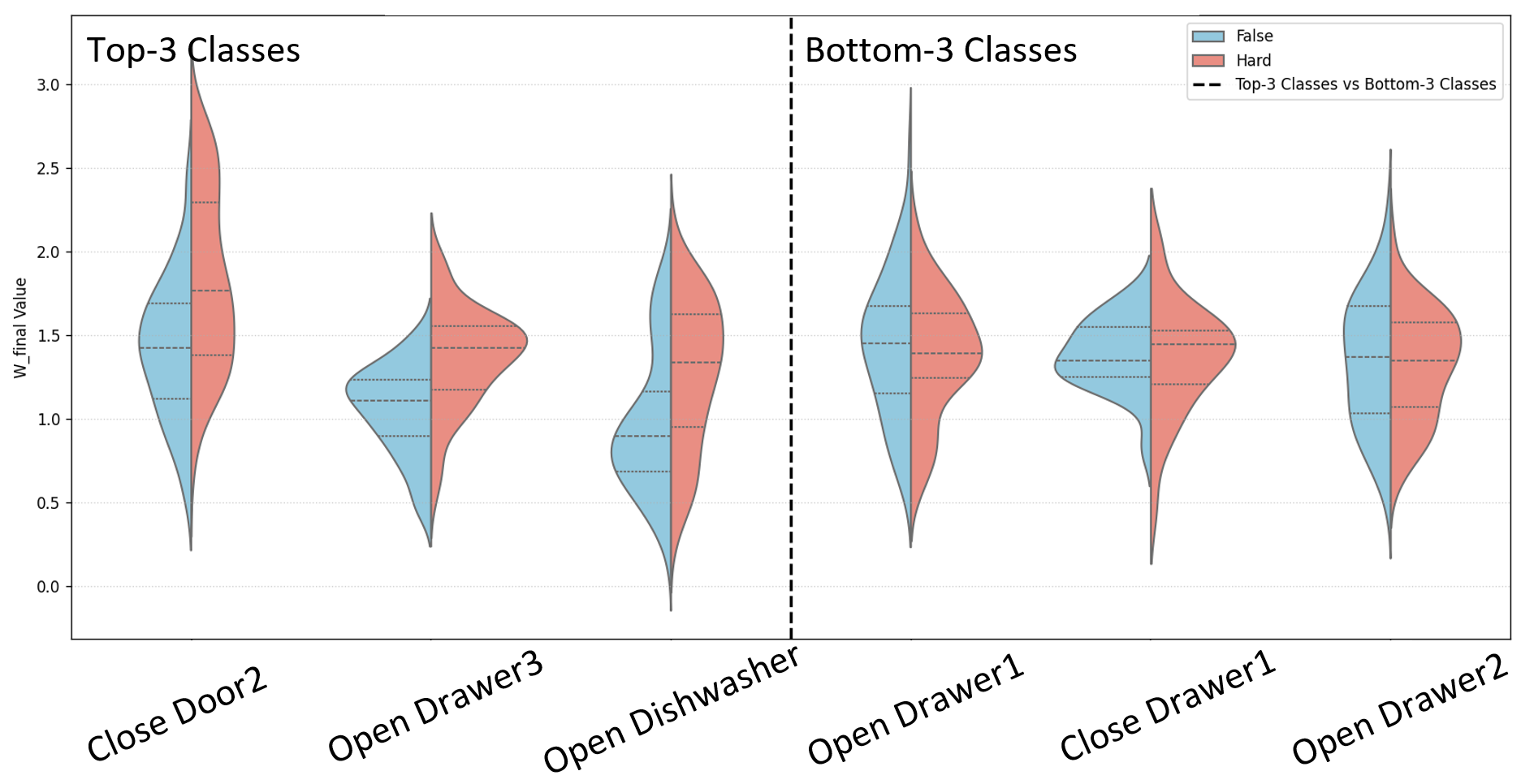
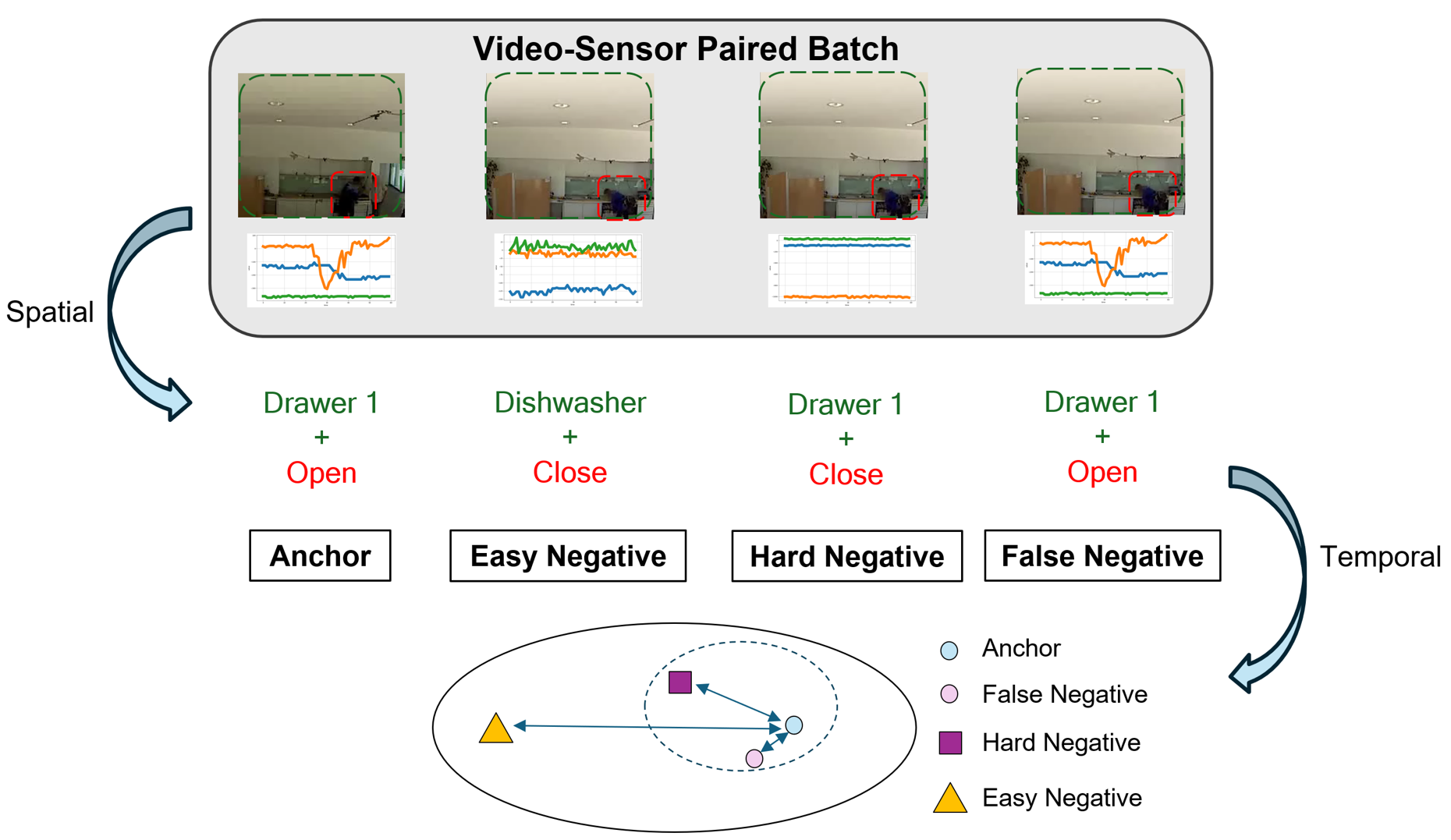
Figure 2. Negative sampling strategy. Hard negatives (same
object, different actions) are prioritized, easy negatives (different
objects, different actions) are down-weighted, and false negatives
(same object, same action) are filtered.
then aligned through contrastive or distillation objectives
[13, 27]. While effective in egocentric–wearable scenarios
where the two modalities exhibit strong cross-modal spatio-
temporal correlations, we argue that the strategy fails to op-
erate effectively in exocentric–ambient environments due to
two fundamental challenges.
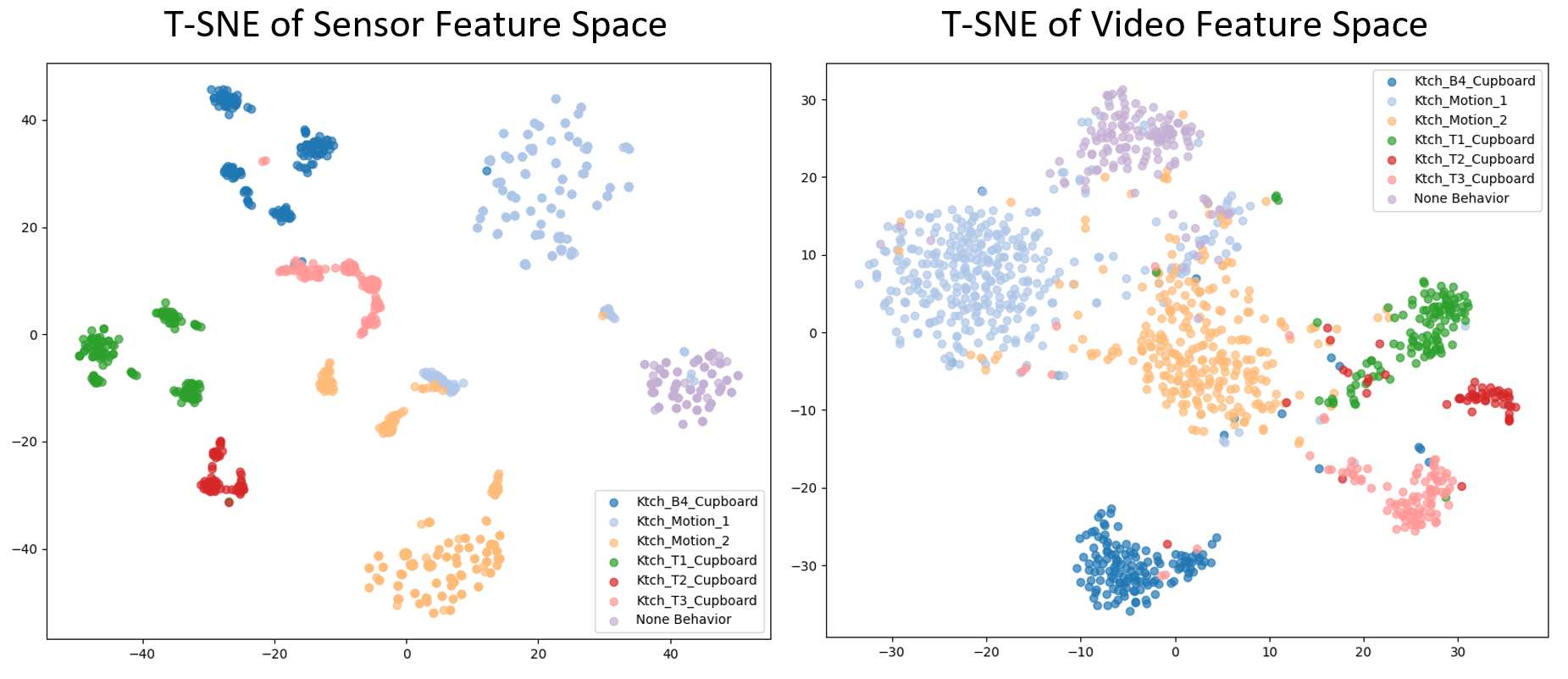
First, global alignment fails to capture fine-grained lo-
cal details [20], specifically subtle motion patterns, in
exocentric-ambient settings. Unlike egocentric video with
salient hand-object interactions [57], exocentric video of-
ten shows minimal visual changes (e.g., a drawer opening
slightly) against static scenes [1, 55]. Compressing the en-
tire video into a single vector dilutes these subtle yet dis-
criminative cues, despite clear ambient sensor signals (Fig.
1(a)).
Second, global alignment with motion-centric sensor en-
coders forces the model to rely solely on temporal patterns,
which are the only modality-invariant feature [20]. This
creates a critical representational mismatch where video
embeddings capture rich spatio-semantic cues (object ap-
pearance, spatial relationships, location), while sensor em-
beddings capture only temporal dynamics. Motion-centric
encoders suit egocentric-wearable setups focused on body
movements [58, 59], but exocentric-ambient settings re-
quire contextual grounding since each sensor is bound to a
specific object or loc