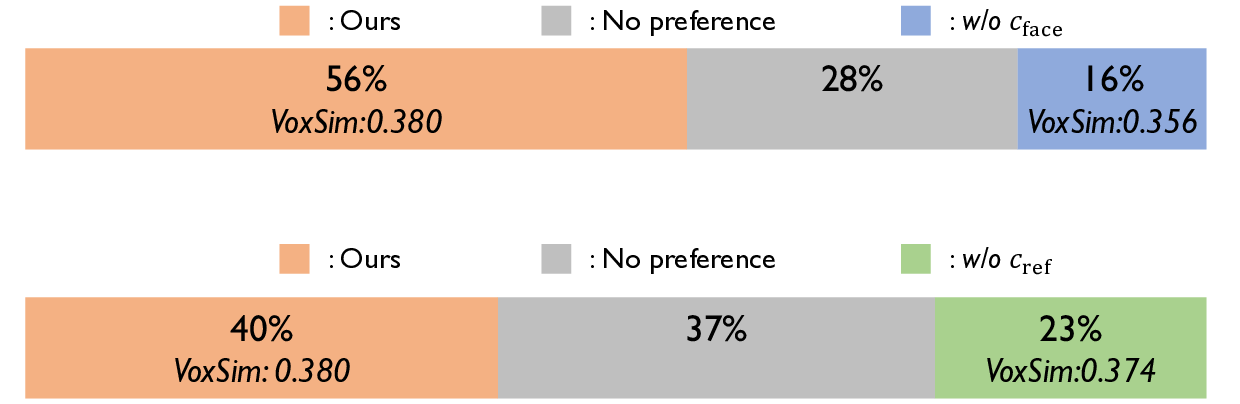Authors: ** - Ji‑Hoon Kim¹²* - Junseok Ahn¹* - Doyeop Kwak¹ - Joon Son Chung¹ - Shinji Watanabe² ¹ Korea Advanced Institute of Science and Technology (KAIST) ² Carnegie Mellon University *동등 기여 **
📝 Abstract
The objective of this paper is to jointly synthesize interactive videos and conversational speech from text and reference images. With the ultimate goal of building human-like conversational systems, recent studies have explored talking or listening head generation as well as conversational speech generation. However, these works are typically studied in isolation, overlooking the multimodal nature of human conversation, which involves tightly coupled audio-visual interactions. In this paper, we introduce TAVID, a unified framework that generates both interactive faces and conversational speech in a synchronized manner. TAVID integrates face and speech generation pipelines through two cross-modal mappers (i.e., a motion mapper and a speaker mapper), which enable bidirectional exchange of complementary information between the audio and visual modalities. We evaluate our system across four dimensions: talking face realism, listening head responsiveness, dyadic interaction fluency, and speech quality. Extensive experiments demonstrate the effectiveness of our approach across all these aspects.
💡 Deep Analysis
📄 Full Content
TAVID: Text-Driven Audio-Visual Interactive Dialogue Generation
Ji-Hoon Kim1,2∗
Junseok Ahn1∗
Doyeop Kwak1
Joon Son Chung1
Shinji Watanabe2
1Korea Advanced Institute of Science and Technology
2Carnegie Mellon University
{jh.kim, junseok.ahn}@kaist.ac.kr
Text dialogue
Reference images
Audio-Visual
Dialogue
Generation
Dyadic Interaction
A: Hi. How are you?
B: Pretty good.
A: How can I help you?
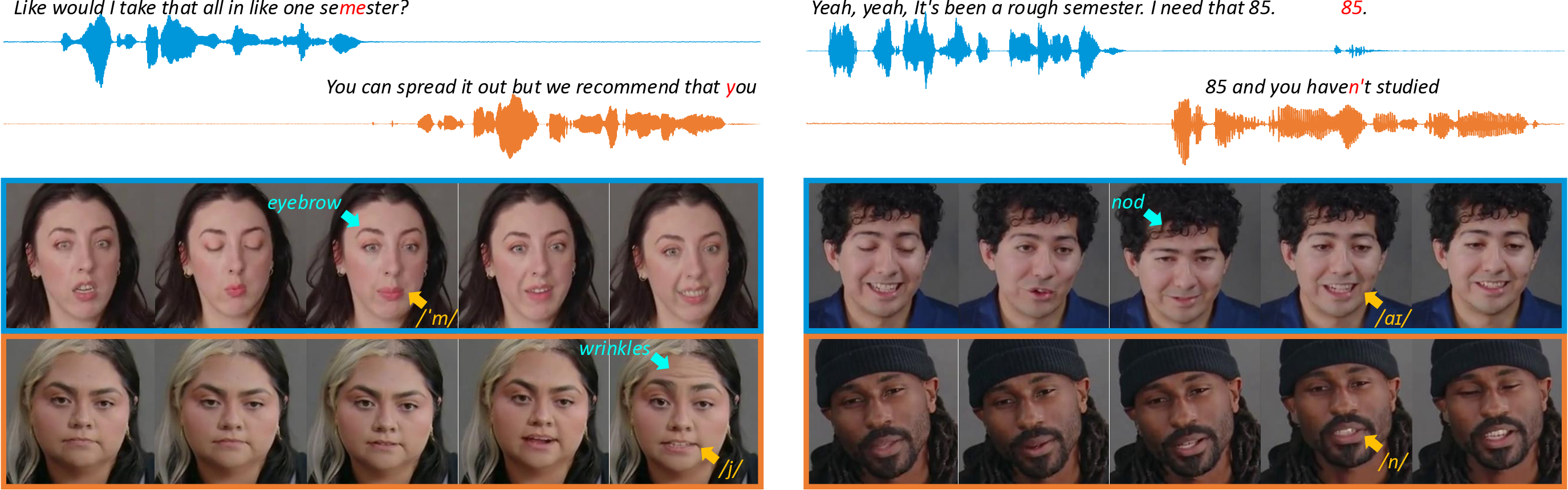
Figure 1. Overview of TAVID framework. Given a text dialogue and reference images, TAVID simultaneously produces interactive videos
and conversational speech with natural turn-taking, accurate synchronization and expressive facial dynamics.
Abstract
The objective of this paper is to jointly synthesize interactive
videos and conversational speech from text and reference
images. With the ultimate goal of building human-like con-
versational systems, recent studies have explored talking or
listening head generation as well as conversational speech
generation. However, these works are typically studied in
isolation, overlooking the multimodal nature of human con-
versation, which involves tightly coupled audio-visual in-
teractions. In this paper, we introduce TAVID, a unified
framework that generates both interactive faces and con-
versational speech in a synchronized manner. TAVID in-
tegrates face and speech generation pipelines through two
cross-modal mappers (i.e., a motion mapper and a speaker
mapper), which enable bidirectional exchange of comple-
mentary information between the audio and visual modali-
ties. We evaluate our system across four dimensions: talk-
ing face realism, listening head responsiveness, dyadic in-
teraction fluency, and speech quality. Extensive experiments
demonstrate the effectiveness of our approach across all
these aspects.
∗Equal contribution.
Project Page: https://mm.kaist.ac.kr/projects/TAVID
1. Introduction
Have you ever imagined having a natural conversation with
an AI? Indeed, there have been numerous efforts to build
systems capable of fluent communication, reflecting grow-
ing demand in areas such as AI tutoring, virtual compan-
ionship, and social robotics. However, such systems have
predominantly been limited to a single modality, such as
text [24, 56, 72] or speech [18, 55, 67]. In contrast, hu-
man communication is inherently multimodal, combining
linguistic content with vocal and visual cues that enrich nu-
ance, emotion, and intent [49]. Therefore, to create truly
immersive and realistic interactions between human and AI,
it is crucial to integrate information across multiple modal-
ities, rather than relying on text or speech alone.
With the ultimate goal of building human-like conversa-
tional agents, prior work has largely been fragmented into
independent lines of research, including talking head gen-
eration and listening head generation. Talking head gen-
eration focuses on synthesizing a speaker’s lip and head
motions driven by an audio [31, 60, 71] or a text sig-
nal [8, 22, 32]. In parallel, listening head generation aims
to produce a listener’s facial feedback in response to the
speaker’s acoustic and visual behaviors [47, 53, 63, 78]. Al-
though these two tasks have succeeded in animating natural
arXiv:2512.20296v1 [cs.CV] 23 Dec 2025
faces, they focus solely on one-sided communication, over-
looking the dyadic nature of human conversation.
To model dyadic communication, recent studies have ex-
plored interactive head generation. Early works [66, 68, 79]
rely on manually defined role switchers to alternate be-
tween speaking and listening states, which often lead to un-
natural transitions. To address this issue, INFP [81] pro-
poses an interactive motion guider that automatically deter-
mines the state using dyadic motion representations driven
by dual-track audio. Recently, ARIG [25] further improves
interaction realism and generation quality by incorporat-
ing long-range contextual cues from both audio and vi-
sual modalities. Despite these advances towards conversa-
tional agents, existing methods rely on pre-recorded audio
to produce facial videos, making them incapable of creat-
ing a new speech content. Although a common workaround
is to construct cascaded systems integrating text-to-speech
(TTS) networks, this approach inevitably suffers from er-
ror accumulation and additional speaker modeling such as
acoustic prompting [32, 70].
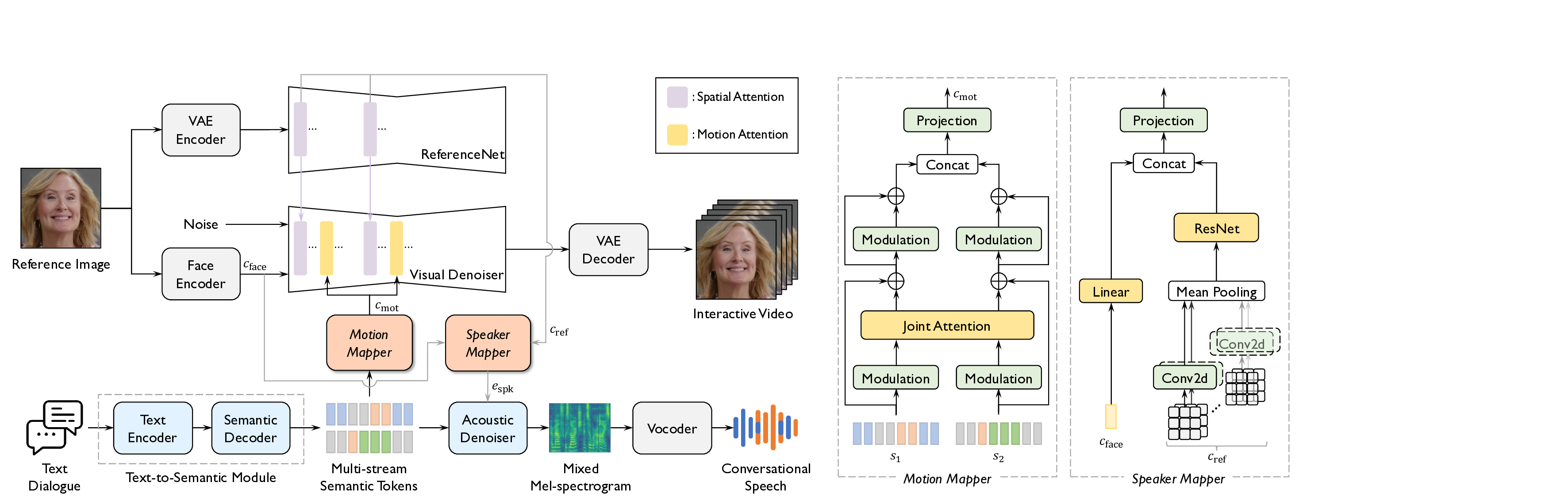
In this paper, we propose TAVID, a unified framework
for Text-driven Audio-Visual Interactive Dialogue genera-
tion. As illustrated in Fig. 1, TAVID jointly generates con-
versational speech and interactive videos from a text dia-
logue and reference images, enabling flexible content cre-
ation and automatic speaker modeling. To this end, TAVID
integrates video and speech generation pipelines with two
cross-modal mappers–the Motion Mapper and the Speaker
Mapper–which capture mutually complementary informa-
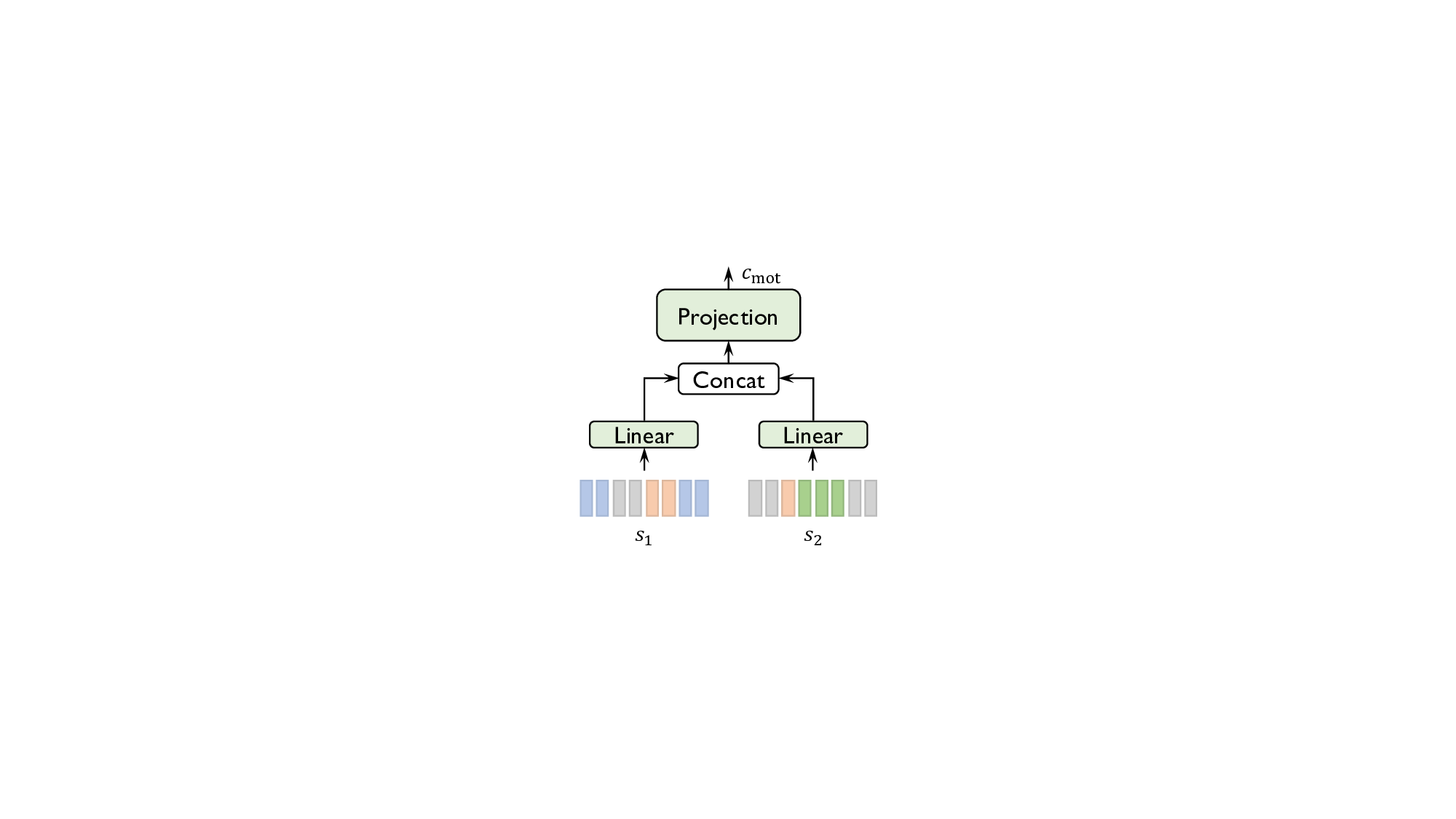
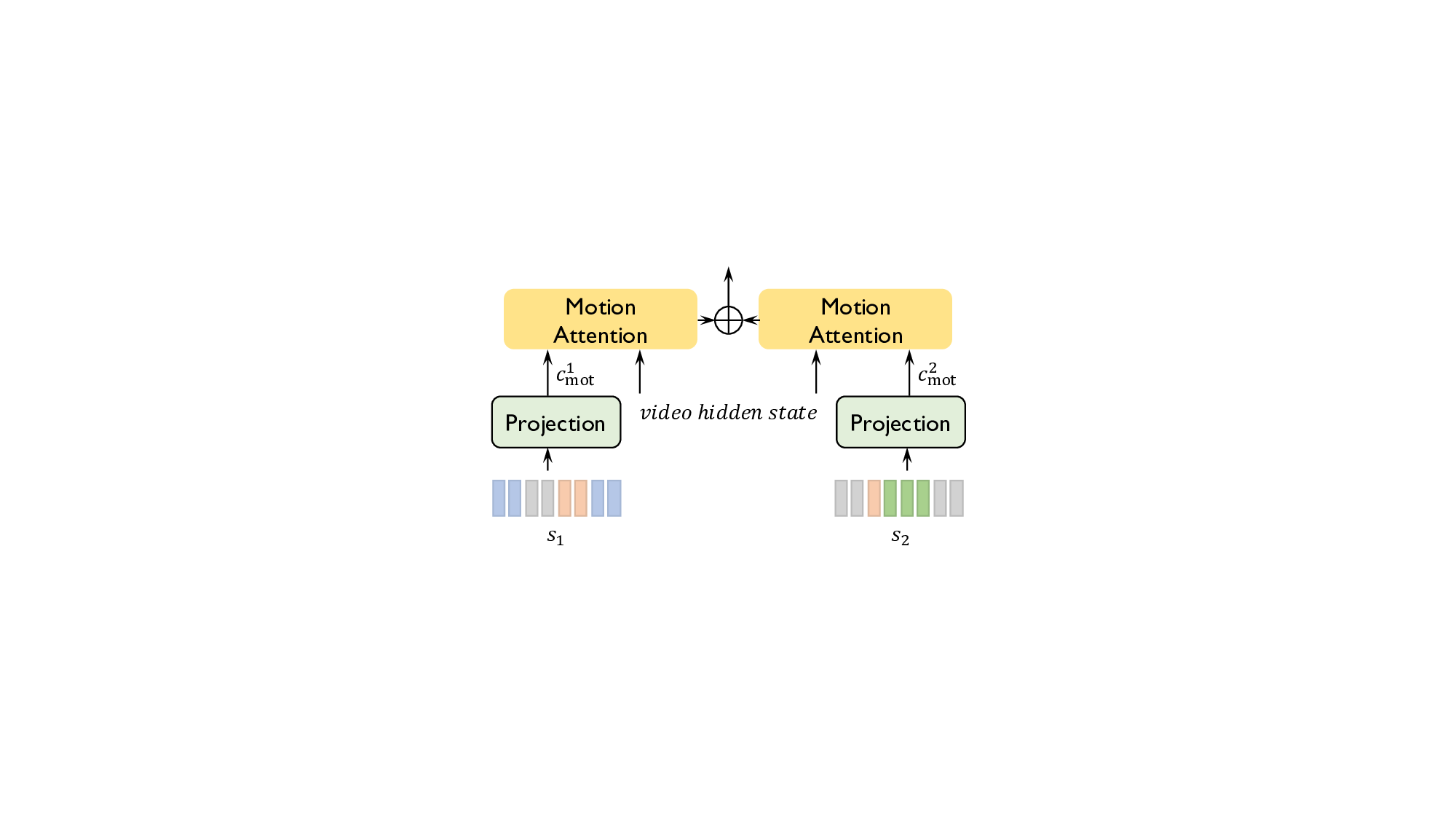
tion across the two streams. The Motion Mapper converts
text dialogues into dyadic motion features that dynamically
alternate