Fail Fast, Win Big: Rethinking the Drafting Strategy in Speculative Decoding via Diffusion LLMs
Reading time: 5 minute
...
📝 Original Info
Title: Fail Fast, Win Big: Rethinking the Drafting Strategy in Speculative Decoding via Diffusion LLMs
ArXiv ID: 2512.20573
Date: 2025-12-23
Authors: ** Rui Pan¹, Zhuofu Chen¹, Hongyi Liu², Arvind Krishnamurthy³⁴, Ravi Netravali¹ ¹프린스턴 대학교, ²라이스 대학교, ³구글, ⁴워싱턴 대학교 **
📝 Abstract
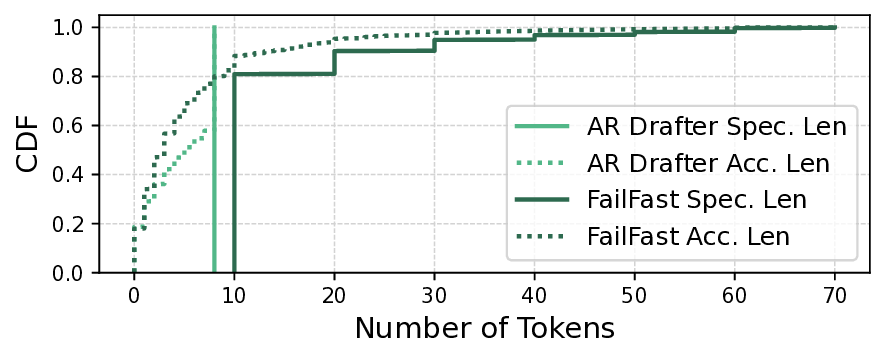
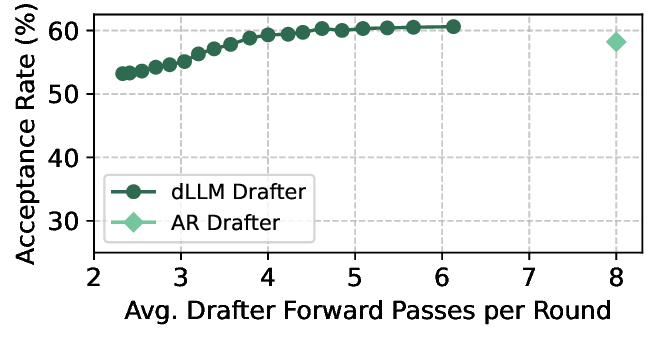
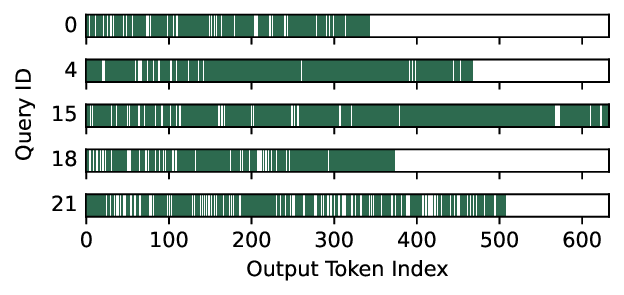
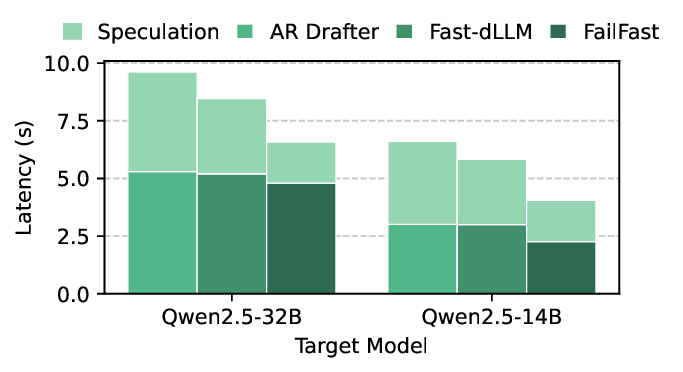
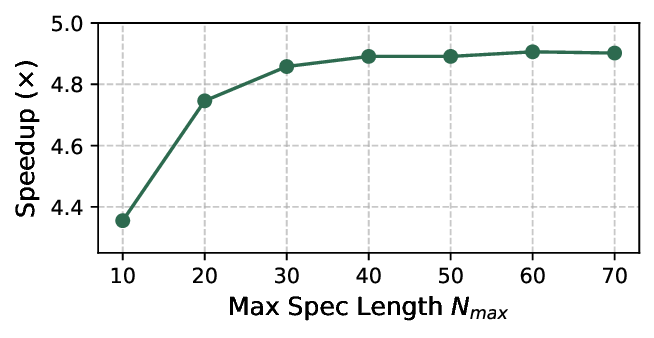
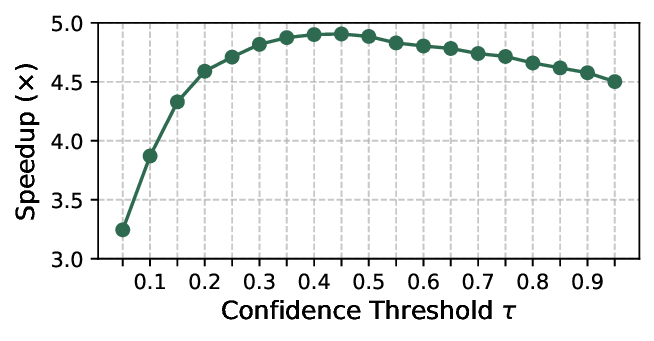
Diffusion Large Language Models (dLLMs) offer fast, parallel token generation, but their standalone use is plagued by an inherent efficiency-quality tradeoff. We show that, if carefully applied, the attributes of dLLMs can actually be a strength for drafters in speculative decoding with autoregressive (AR) verifiers. Our core insight is that dLLM's speed from parallel decoding drastically lowers the risk of costly rejections, providing a practical mechanism to effectively realize the (elusive) lengthy drafts that lead to large speedups with speculative decoding. We present FailFast, a dLLM-based speculative decoding framework that realizes this approach by dynamically adapting its speculation length. It "fails fast" by spending minimal compute in hard-to-speculate regions to shrink speculation latency and "wins big" by aggressively extending draft lengths in easier regions to reduce verification latency (in many cases, speculating and accepting 70 tokens at a time!). Without any fine-tuning, FailFast delivers lossless acceleration of AR LLMs and achieves up to 4.9$\times$ speedup over vanilla decoding, 1.7$\times$ over the best naive dLLM drafter, and 1.7$\times$ over EAGLE-3 across diverse models and workloads. We open-source FailFast at https://github.com/ruipeterpan/failfast.
💡 Deep Analysis
📄 Full Content
Fail Fast, Win Big: Rethinking the Drafting Strategy in Speculative Decoding via
Diffusion LLMs
Rui Pan 1 * Zhuofu Chen 1 Hongyi Liu 2 Arvind Krishnamurthy 3 4 Ravi Netravali 1
Abstract
Diffusion Large Language Models (dLLMs) of-
fer fast, parallel token generation, but their stan-
dalone use is plagued by an inherent efficiency-
quality tradeoff. We show that, if carefully ap-
plied, the attributes of dLLMs can actually be
a strength for drafters in speculative decoding
with autoregressive (AR) verifiers. Our core in-
sight is that dLLM’s speed from parallel decoding
drastically lowers the risk of costly rejections,
providing a practical mechanism to effectively
realize the (elusive) lengthy drafts that lead to
large speedups with speculative decoding. We
present FailFast, a dLLM-based speculative de-
coding framework that realizes this approach by
dynamically adapting its speculation length. It
“fails fast” by spending minimal compute in hard-
to-speculate regions to shrink speculation latency
and “wins big” by aggressively extending draft
lengths in easier regions to reduce verification
latency (in many cases, speculating and accept-
ing 70 tokens at a time!).
Without any fine-
tuning, FailFast delivers lossless acceleration of
AR LLMs and achieves up to 4.9× speedup over
vanilla decoding, 1.7× over the best naive dLLM
drafter, and 1.7× over EAGLE-3 across diverse
models and workloads. We open-source FailFast
at https://github.com/ruipeterpan
/failfast.
1. Introduction
A new wave of Diffusion Large Language Models
(dLLMs) (Khanna et al., 2025; Song et al., 2025; gem,
2025; Bie et al., 2025; Wu et al., 2025b) has emerged
as a compelling alternative to the standard autoregressive
paradigm in large language models. Unlike autoregressive
(AR) LLMs, which are constrained to generating tokens
*Work partially done during internship at Google. 1Princeton
University 2Rice University 3Google 4University of Washington.
Correspondence to: Rui Pan .
Preprint. January 29, 2026.
one by one from left to right, dLLMs possess the unique
capability to predict and unmask multiple tokens at arbitrary
positions simultaneously. Crucially, this decoding process
is highly customizable: the model’s unmasking strategy de-
termines exactly which and how many tokens are unmasked
during each denoising step (a model forward pass). As such,
dLLMs are highly attractive for low-latency inference.
Yet despite their speed, parallel generation imposes a funda-
mental limit on modeling accuracy. This limitation stems
from the conditional independence assumption required for
simultaneous sampling of multiple tokens; by treating to-
kens generated within the same step as independent of one
another, the decoding process inevitably ignores crucial mu-
tual dependencies (Wu et al., 2025b; Kang et al., 2025).
Consequently, a direct tension emerges between efficiency
and quality. Improving the generation speed (i.e., using
fewer forward passes) necessitates unmasking a larger num-
ber of tokens per step, which exacerbates the risk of quality
degradation. Conversely, maximizing quality forces the
sampling procedure to adopt a strict left-to-right, one-token-
per-step order that essentially falls back to the speed of
autoregressive generation.
While existing work strives to alleviate the stark compute-
accuracy tradeoff of dLLMs as standalone generators (Kang
et al., 2025; Bie et al., 2025; Qian et al., 2026), this work
instead focuses on motivating and realizing a scenario in
which we argue that dLLMs are intrinsically beneficial: as
draft models in speculative decoding (Leviathan et al., 2023)
with autoregressive target models. Our proposal extends be-
yond a simple drop-in replacement of dLLMs as drafters in
existing speculative decoding strategies to reap their latency
benefits – indeed, we later show how this can forgo substan-
tial benefits they bring. Instead, our approach is rooted in
two key observations that challenge the status quo for both
speculative decoding design and considerations around the
limitations of dLLMs.
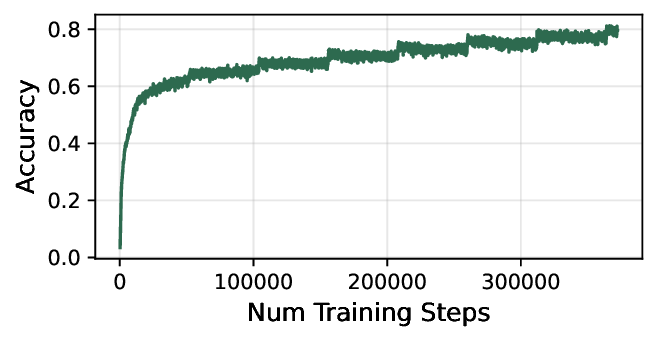
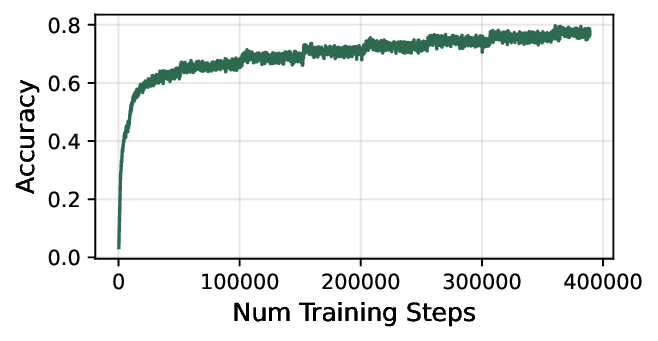
First, dLLMs can generate long drafts quickly. In AR
LLM inference, the decoding latency scales with the num-
ber of output tokens (i.e., the number of model forward
passes) (Yan et al., 2024; Agrawal et al., 2024), whereas
dLLMs can unmask multiple tokens in each forward pass,
so the latency is instead linear to the number of model
1
arXiv:2512.20573v3 [cs.LG] 28 Jan 2026
Fail Fast, Win Big: Rethinking the Drafting Strategy in Speculative Decoding via Diffusion LLMs
I1
In
I1
…
In
I1
…
In
I1
…
In
O1
…
O1
O2
O1
O2
O10
…
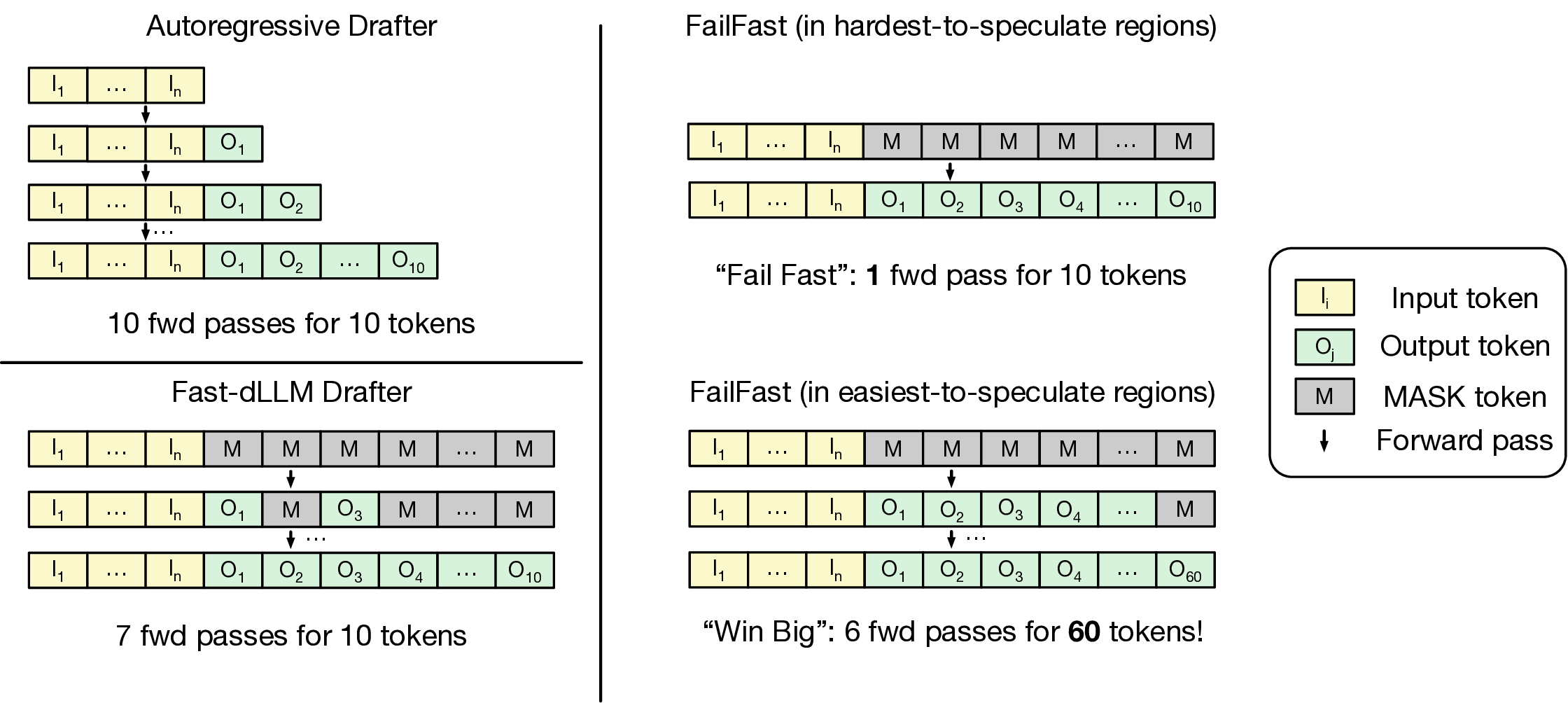
Autoregressive Drafter
10 fwd passes for 10 tokens
…
I1
…
In
M
…
Fast-dLLM Drafter
M
M
M
M
I1
…
In
O1
…
M
O3
M
M
I1
…
In
…
O1
O2
O10
O3
O4
7 fwd passes for 10 tokens
…
FailFast (in hardest-to-speculate regions)
I1
…
In
M
…
M
M
M
M
I1
…
In
…
O1
O2
O10
O3
O4
“Fail Fast”: 1 fwd pass for 10 tokens
FailFast (in easiest-to-speculate regions)
“Win Big”: 6 fwd passes for 60 tokens!
I1
…
In
M
…