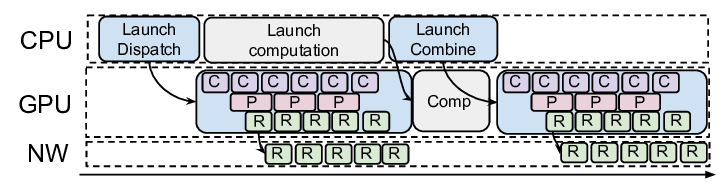
Title: UCCL-EP: Portable Expert-Parallel Communication
ArXiv ID: 2512.19849
Date: 2025-12-22
Authors: ** Ziming Mao†, Yihan Zhang‡, Chihan Cui§, Zhen Huang¶, Kaichao You♣, Zhongjie Chen♡, Zhiying Xu♠, Zhenyu Gu¶, Scott Shenker†⋄, Costin Raiciu★, Yang Zhou‡, Ion Stoica† † University of California, Berkeley ‡ University of California, Davis § University of Wisconsin–Madison ¶ AMD ♣ Independent Researcher ♡ Tsinghua University ♠ Amazon Web Services ⋄ International Computer Science Institute (ICSI) ★ Broadcom & University Politehnica of Bucharest — **
📝 Abstract
Mixture-of-Experts (MoE) workloads rely on expert parallelism (EP) to achieve high GPU efficiency. State-of-the-art EP communication systems such as DeepEP demonstrate strong performance but exhibit poor portability across heterogeneous GPU and NIC platforms. The poor portability is rooted in architecture: GPU-initiated token-level RDMA communication requires tight vertical integration between GPUs and NICs, e.g., GPU writes to NIC driver/MMIO interfaces.
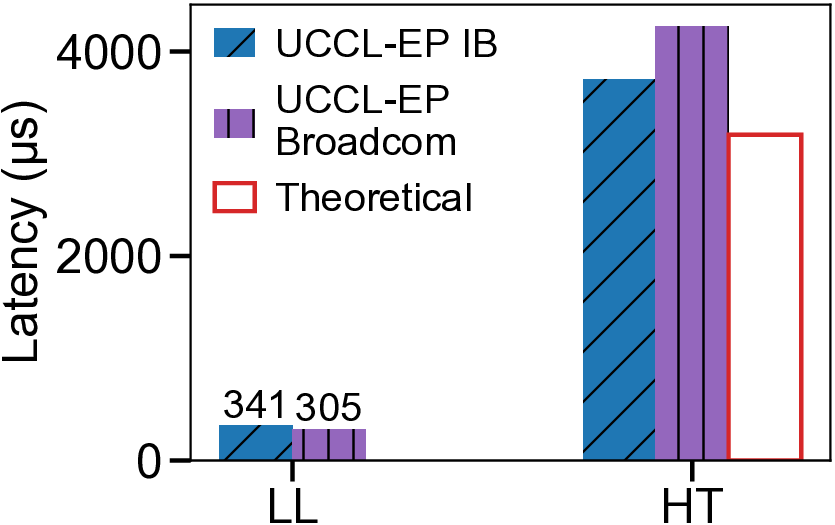
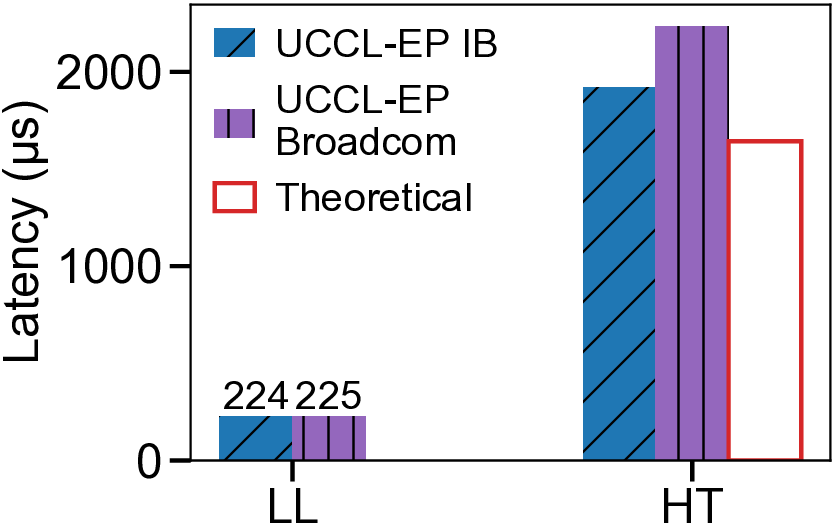
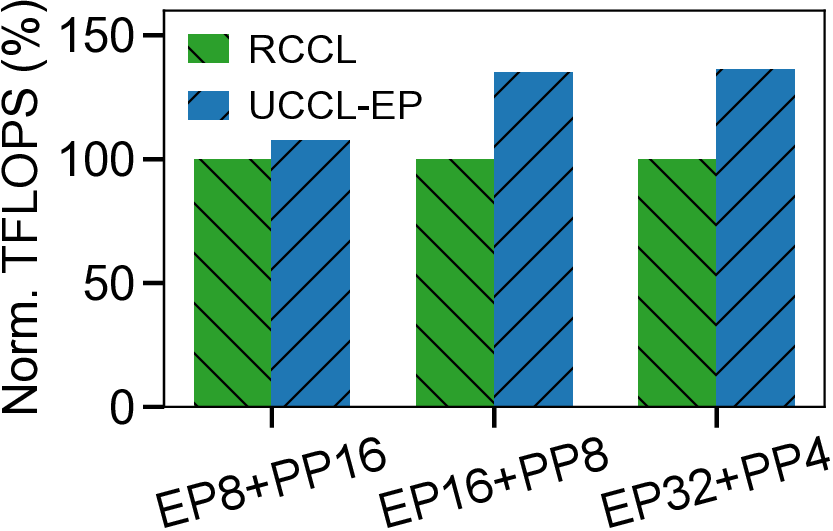
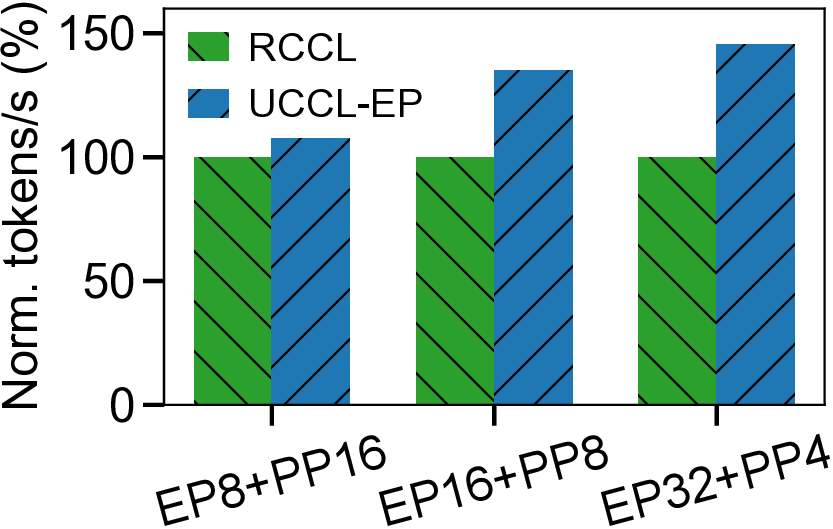
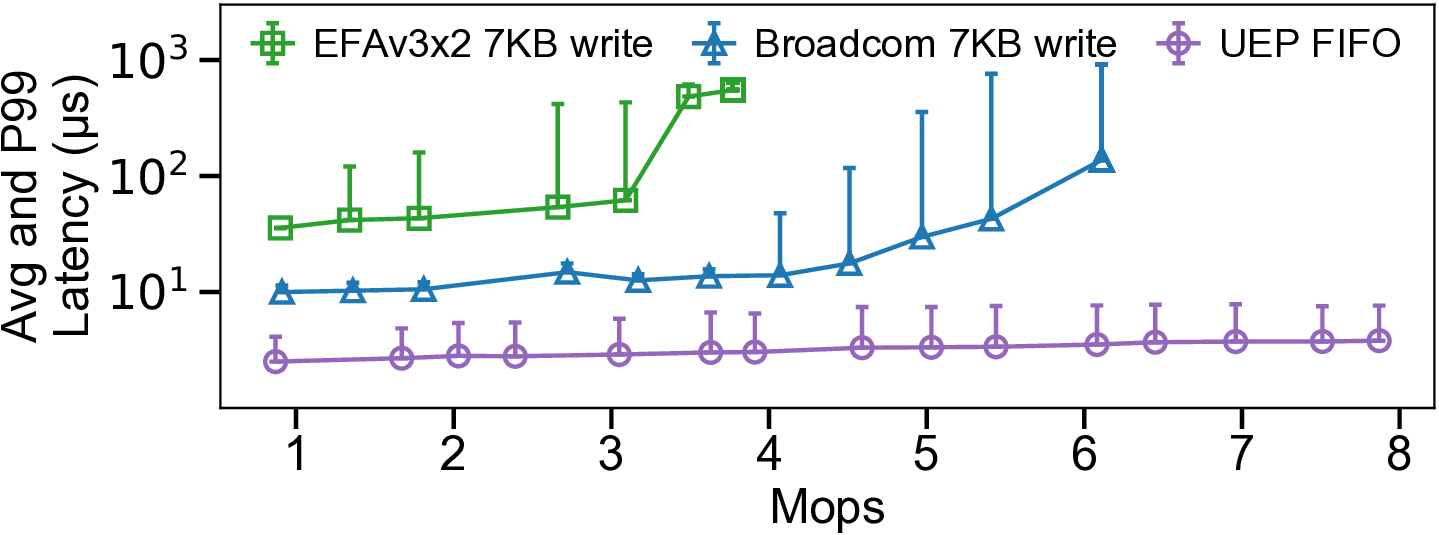
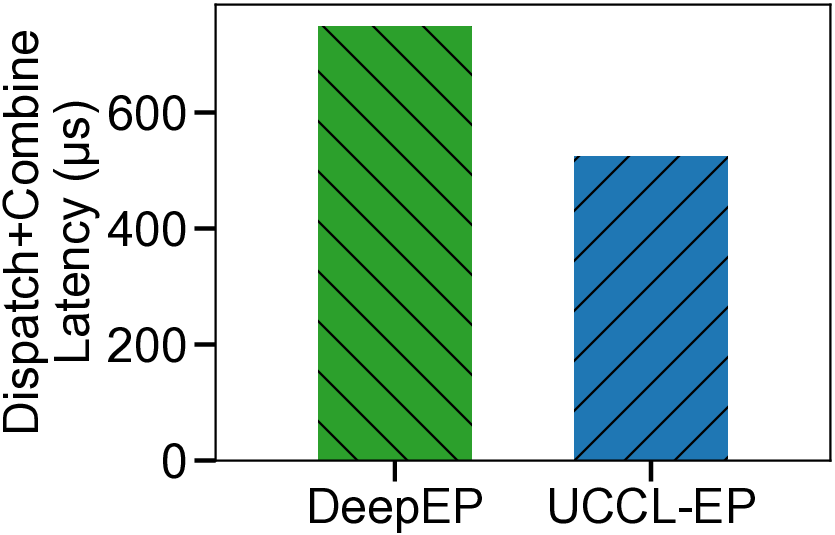
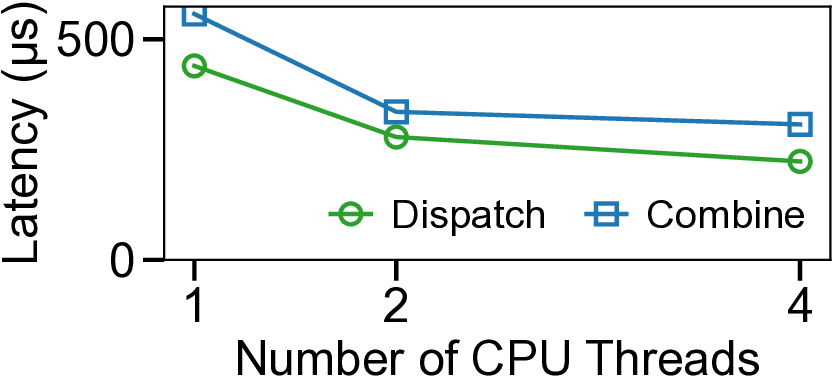
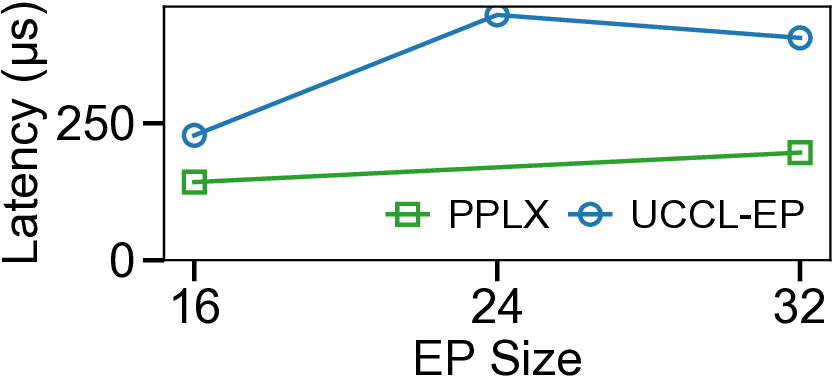
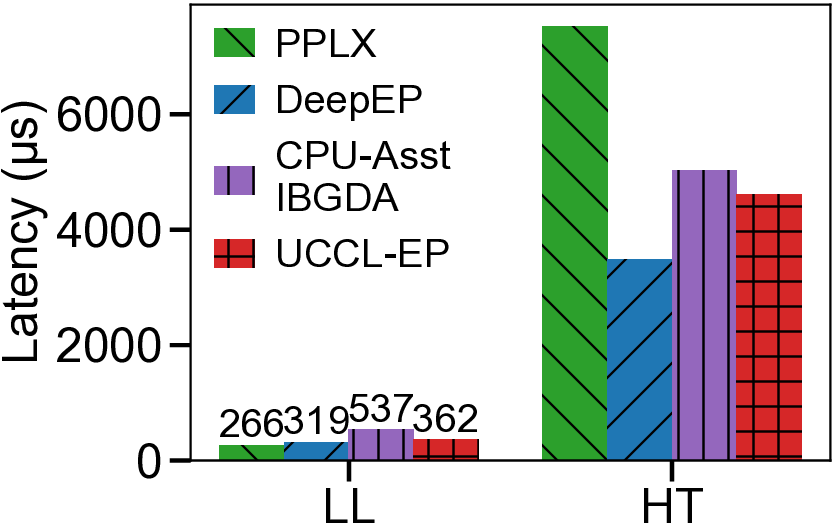
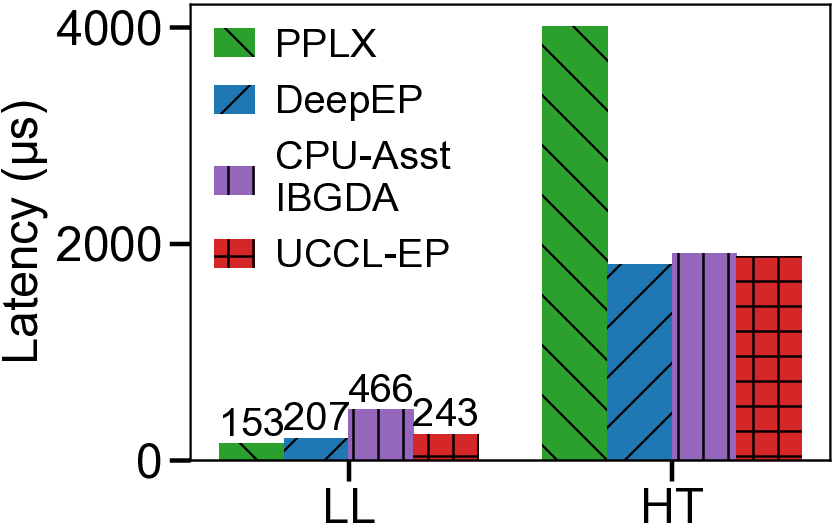
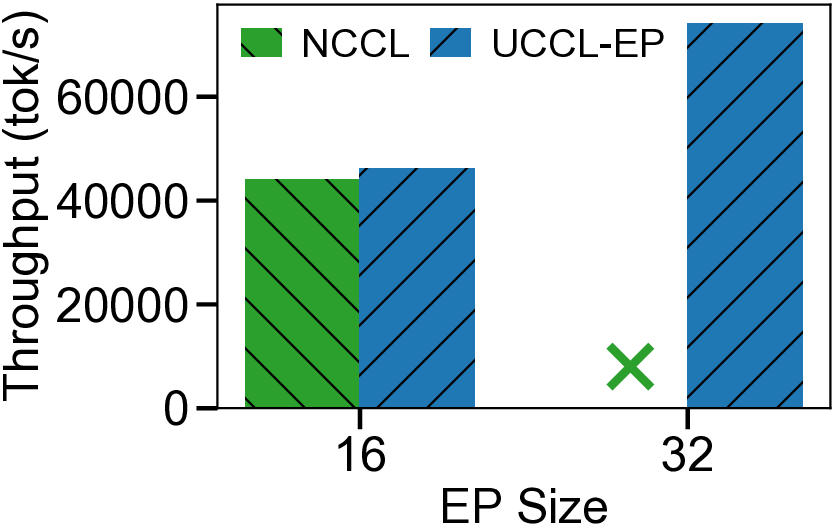
We present UCCL-EP, a portable EP communication system that delivers DeepEP-level performance across heterogeneous GPU and NIC hardware. UCCL-EP replaces GPU-initiated RDMA with a high-throughput GPU-CPU control channel: compact token-routing commands are transferred to multithreaded CPU proxies, which then issue GPUDirect RDMA operations on behalf of GPUs. UCCL-EP further emulates various ordering semantics required by specialized EP communication modes using RDMA immediate data, enabling correctness on NICs that lack such ordering, e.g., AWS EFA. We implement UCCL-EP on NVIDIA and AMD GPUs with EFA and Broadcom NICs. On EFA, it outperforms the best existing EP solution by up to $2.1\times$ for dispatch and combine throughput. On NVIDIA-only platform, UCCL-EP achieves comparable performance to the original DeepEP. UCCL-EP also improves token throughput on SGLang by up to 40% on the NVIDIA+EFA platform, and improves DeepSeek-V3 training throughput over the AMD Primus/Megatron-LM framework by up to 45% on a 16-node AMD+Broadcom platform.
💡 Deep Analysis
📄 Full Content
UCCL-EP: Portable Expert-Parallel Communication
Ziming Mao† Yihan Zhang‡ Chihan Cui§ Zhen Huang¶ Kaichao You♣Zhongjie Chen♡
Zhiying Xu♠
Zhenyu Gu¶ Scott Shenker†⋄Costin Raiciu⋆Yang Zhou‡ Ion Stoica†
†UC Berkeley
‡UC Davis
§UW–Madison
¶AMD
♣Independent Researcher
♡Tsinghua University
♠Amazon Web Services
⋄ICSI
⋆Broadcom & University Politehnica of Bucharest
Abstract
Mixture-of-Experts (MoE) workloads rely on expert paral-
lelism (EP) to achieve high GPU efficiency. State-of-the-art
EP communication systems such as DeepEP demonstrate
strong performance but exhibit poor portability across het-
erogeneous GPU and NIC platforms. The poor portability is
rooted in architecture: GPU-initiated token-level RDMA com-
munication requires tight vertical integration between GPUs
and NICs, e.g., GPU writes to NIC driver/MMIO interfaces.
We present UCCL-EP, a portable EP communication sys-
tem that delivers DeepEP-level performance across hetero-
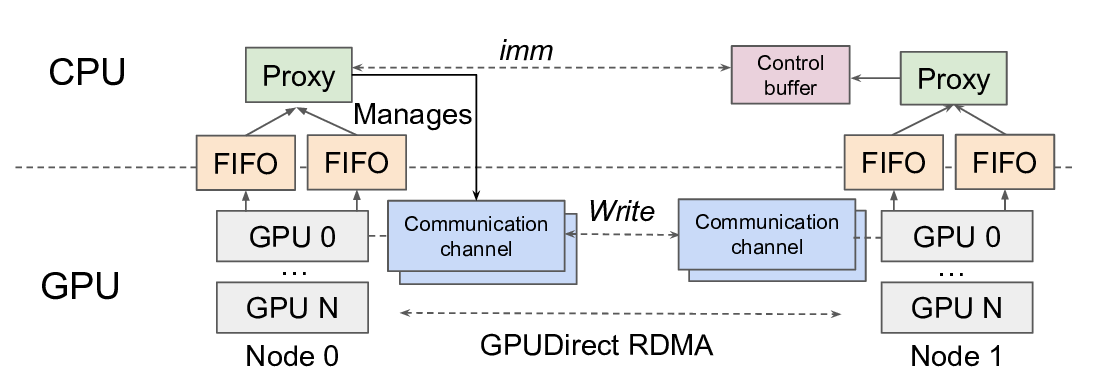
geneous GPU and NIC hardware. UCCL-EP replaces GPU-
initiated RDMA with a high-throughput GPU-CPU control
channel: compact token-routing commands are transferred
to multithreaded CPU proxies, which then issue GPUDirect
RDMA operations on behalf of GPUs. UCCL-EP further
emulates various ordering semantics required by specialized
EP communication modes using RDMA immediate data,
enabling correctness on NICs that lack such ordering, e.g.,
AWS EFA. We implement UCCL-EP on NVIDIA and AMD
GPUs with EFA and Broadcom NICs. On EFA, it outper-
forms the best existing EP solution by up to 2.1× for dis-
patch and combine throughput. On NVIDIA-only platform,
UCCL-EP achieves comparable performance to the origi-
nal DeepEP. UCCL-EP also improves token throughput on
SGLang by up to 40% on the NVIDIA+EFA platform, and
improves DeepSeek-V3 training throughput over the AMD
Primus/Megatron-LM framework by up to 45% on a 16-node
AMD+Broadcom platform.
1
Introduction
State-of-the-art large language models (LLMs), such as
DeepSeek-V3 [13,32], OpenAI gpt-oss [48], Google Gemini-
3 Pro [18], and Meta LLaMA 4 [2], are increasingly based on
the Mixture-of-Experts (MoE) architecture. In a MoE layer, a
gating network running on GPUs selects a small subset of ex-
perts for each token activation, dispatches the token activation
to those experts, and then aggregates their output activations.
Modern MoE models typically instantiate hundreds of experts
that specialize in different input patterns, so that only a few
experts are active for each token. This sparsity allows MoE
models to achieve accuracy comparable to large dense models
♠This work does not relate to the position at Amazon.
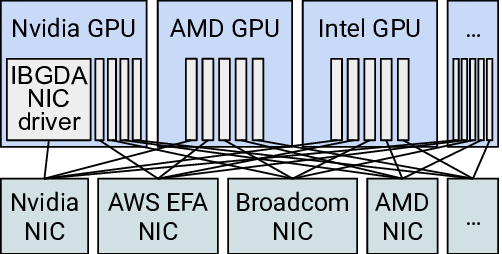
Nvidia
NIC
Nvidia GPU
AWS EFA
NIC
Broadcom
NIC
AMD
NIC
…
AMD GPU
Intel GPU
…
IBGDA
NIC
driver
(a) IBGDA-style.
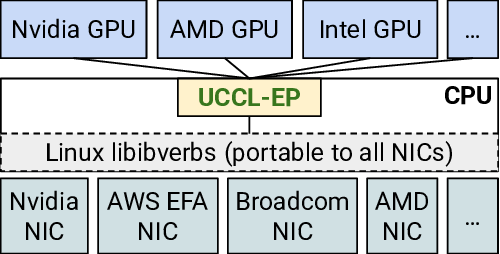
UCCL-EP
Nvidia
NIC
Nvidia GPU
AWS EFA
NIC
Broadcom
NIC
AMD
NIC
…
AMD GPU
Intel GPU
Linux libibverbs (portable to all NICs)
…
CPU
(b) UCCL-EP
Figure 1: Assuming m GPU vendors and n NIC vendors, UCCL-
EP enables O(m) effort, instead of IBGDA’s O(m×n), to support
GPU-initiated token-level communication for expert parallelism.
while using only a fraction of the per-token inference cost,
making them the standard choice for many frontier LLMs.
Training and serving large MoE models require expert
parallelism (EP), which places different experts on different
GPUs and communicates token activations among GPUs in
an all-to-all manner. By sparsely sharding experts on dif-
ferent GPUs, EP leaves enough GPU memory for matrix
multiplication on extremely large batch sizes (e.g., 4096 in
DeepSeek-V3 [32]), thus enabling high GPU resource effi-
ciency. Expert-parallel communication plays a pivotal role in
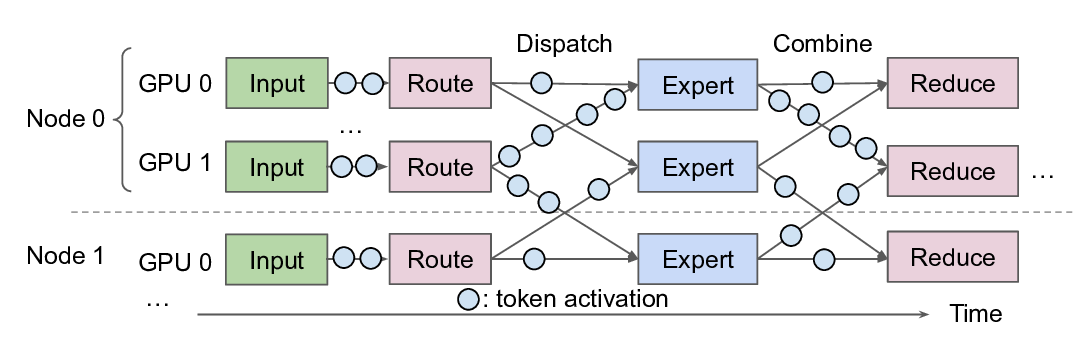
the EP efficiency [32,64], because token activations are small
(e.g., 7KB), dispatch and combine operations are frequent
(e.g., selecting 8 experts per token), and routing destinations
are only determined at runtime in GPUs (§2.1).
GPU-initiated token-level (fine-grained) communication
(§2.2) is an emerging and key communication pattern for
efficient token dispatch and combine at runtime, where
DeepEP [65] by DeepSeek is the most popular communi-
cation system implementing it. Different from CPU-initiated
bulk-transfer (coarse-grained) communication in NCCL/R-
CCL [4,44], DeepEP leverages the advanced NVIDIA IBGDA
(InfiniBand GPUDirect Async) [46] technique that enables
GPUs to directly operate RDMA NICs (network interface
controllers) to write out small activations. Leveraging GPU-
initiated token-level communication, DeepEP implements ef-
ficient GPU-side token deduplication during dispatch (avoid
sending duplicate tokens to experts on the same node) and
hierarchical reduce during combine to achieve superior per-
formance. DeepEP has been widely adopted by various
training and serving frameworks such as Megatron-LM [7],
vLLM [61], and SGLang [60]
Although GPU-initiated token-level communication leads
to high performance, its design unfortunately results in poor
portability. There are two key reasons: GPUs directly issuing